A local CS reading group
Paper Cup, a reading group for computer science papers recently started, based about 30 minutes from me I decided to go along to the first meeting to see what it was like.
The paper under discussion was: Dynamo: Amazon’s Highly Available Key-value Store. I don’t know much about databases and and have never written code that uses a key-store, but since the event was hosted by guys at ebay/PayPal I figured there would be somebody in the room who knew what they were talking about.
The idea behind a paper reading group is that everybody agrees to read a paper before the meeting, then turns up at the meeting and discusses it.
The list of authors takes up three lines and their affiliation is simply listed as Amazon.com. As a subject matter outsider who probably reads several hundred papers a year my overall impression was that this paper was relatively information free and was more or less a puff-piece for Amazon. On the other hand it currently has 1,562 citations, a lot more than would be expected for a puff-piece paper published in 2007. I was obviously missing something.
Around 10 people showed up, with a handful sounding very knowledgeable and one person working on a new ‘Dynamo like’ implementation. Several replies to my question of what was so good about this paper, that appeared relatively content free to me, gave the reason that they were inspired by it. Wow, very few scientific papers ever inspire anybody.
The group worked its way through the paper and I tried to nod intelligently at the right time. This is one of those papers that requires lots of reading between the lines, an activity that requires lots of background knowledge and hands-on experience (as an outsider I was only reading the surface text).
I asked if one of the reasons this paper was considered to be important was because it described a commercial implementation rather than a research project. Any design team is much more likely to use techniques outlined in a paper describing a working commercial system than techniques operating in some toy academic environment (papers on Cassandra were appearing at about the same time). I’m not sure the relatively young attendees understood the importance of this point.
The take-away interesting snippet of information: Dynamo gives preference to performance over consistency, if a customer’s shopping basket key-value store becomes inconsistent then information on items added to the basket take precedence over items deleted from the basket (a sensible choice for a retailer such as Amazon).
If you live near west London and are interested in discussing CS paper do join the Paper Cup meetup group, the more the merrier.
I made a mistake, please don’t shoot me
The major difference between commercial/academic written software is the handling of user mistakes, or to be more exact what is considered to be a user mistake. In the commercial world the emphasis is on keeping the customer happy, which translates into trying hard to gracefully handle any ‘mistake’ the user makes. Academic software is generally written to solve a research problem and is often very unforgiving of users failing to keep to the undocumented straight and narrow; given the context this unforgiving behavior is understandable, but sometimes such software is released to an unsuspecting world.
The R archive of contributed packages, CRAN, is a good example of the academic approach to writing software. I am an active user of many packages in this archive and its contributors have my heart-felt thanks. But on a regular basis I make a mistake when calling a function in one of these packages, get shot in the foot and am not best pleased.
What makes the situation worse is that my mistakes are often so trivial and easy to fix (by both me or the package authors). My most common ‘mistake’ is passing an argument whose type is not handled by the function, e.g., passing a data-frame to diag (why do I have to convert the argument using as.matrix, when diag could spot my mistake and do the conversion for me instead of returning some horrible mess).
Commercial software can also be unforgiving of user mistakes; in fact early versions of a lot of commercial software is just as unfriendly as academic software. The difference is that the commercial managers will make it their business to ensure that developers fix the code to make it user friendly. Competition ensures that those who don’t listen to their users go out of business.
Updating code to gracefully handle user mistakes is often a chore and many developers hate having to do it, managers are needed to prod developers into doing the work. The only purpose for more than half of the code in a commercial product may be to handle user mistakes and the percentage can approach 90%.
A lot of Open Source software has significant commercial backing, e.g., Linux, Apache, Firefox and gcc/llvm, which means it is somebody’s job to make sure customer complaints are addressed.
What the R development team needs is more commercial backing (it appears to have very little, but I may be wrong). Then somebody can be hired to go through the popular packages to make then mistake friendly, feed the changes back to the original author and generally educate package developers about bullet proofing their code.
Amount of end-user usage of code in Firefox
How much end-user usage does the code in Firefox receive over time?
Short answer: The available data is very sparse and lots of hand waving is needed to concoct something.
The longer answer is below as another draft section from my book Empirical software engineering with R. As always, comments and pointers to more data welcome. R code and data here.
Suggestions for alternative methods of calculation also welcome.
Amount of end-user usage of code in Firefox
Source code that is never executed will not have any faults reported against it while code that is very frequently executed is more likely to have a fault reported against it than less frequently executed code.
The Firefox browser has been the subject of several fault related studies. The study by Massacci, Neuhaus and Nguyen is of interest here because it provides the information needed to attempt to build a fault model that takes account of the total amount of usage that code experiences from all end-users of a program. The data used by the study applies to 899 Mozilla Firefox-related Security Advisories (MFSA, a particular kind of fault), noting the earliest and latest versions of Firefox that exhibits each fault; six major releases (i.e., versions 1.0, 1.5, 2.0, 3.0, 3.5 and 3.6) were analysed; the amount of code in each version that originated in earlier versions was measured (see plot below).
Massacci et al make their raw data available under an agreement that does not permit your author to directly distribute it to readers;; the raw data for the following analysis was reverse engineered from the Massacci et al paper; or obtained from other sources.
The following analysis is an attempt to build a model of amount of Firefox code usage, by end-users, over time, i.e., number of lines of Firefox source code being executed per unit time summed over all end-users at a given moment in time. The intent is to couple this model with fault data, looking for a relationship of the form: an X% change in usage results in a Y% change in reported faults.
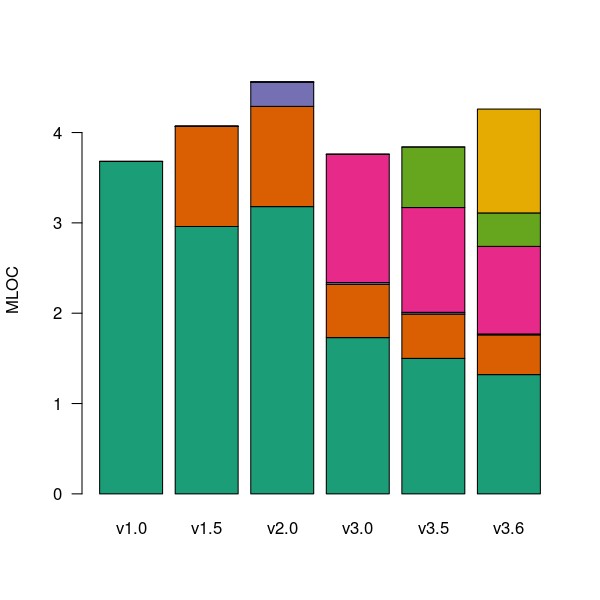
Figure 1. Amount of source (millions of lines) in each version, broken down by the version in which it first appears. Data from Massacci, Neuhaus and Nguyen <book Massacci_11>.
As expected, a large amount of code from previous versions appears in later versions.
Since we are interested in the relationship between end-user code usage and faults (MFSAs in this case) we are only interested in versions of Firefox that are actively maintained by Mozilla. Every version has a first official release date and an end-of-support date beyond which no faults reported against it are fixed; any usage of a version after the end-of-support date is not of interest in this analysis.
How many people are using each version of Firefox at any time?
A number of websites list information on Firefox market share over time (as a percentage of all browsers measured), but only two known to your author break this information down by Firefox version. Massacci et al used url[netmarketshare.com] for Firefox version market share (data going back to November 2007), but your author found it easier to obtain information from url[www.w3schools.com] (data going back to May 2007). The W3schools data is obtained from the log of visitors to their site, which will obviously be subject to fluctuations (of unknown magnitude).
For the period November 2004 to April 2007 the market share of each Firefox version was estimated as follows:
- total Firefox market share was based on that listed by url[marketshare.hitslink.com]
- during the period when only version 1.0 was available, its market share was assumed to be the total Firefox market share,
- the market share for versions 1.5 and 2.0 was assumed to follow the trend of growth and decline seen in later releases for which data is available. Numbers were concocted that followed the version trend and summed to the known total market share.
The plot below shows the market share of the six versions of Firefox between official release and end-of-support. Estimated values appear to the left of the vertical red line, values from measurements to the right. It can be seen that at its end-of-support date version 2.0 still had a significant market share.
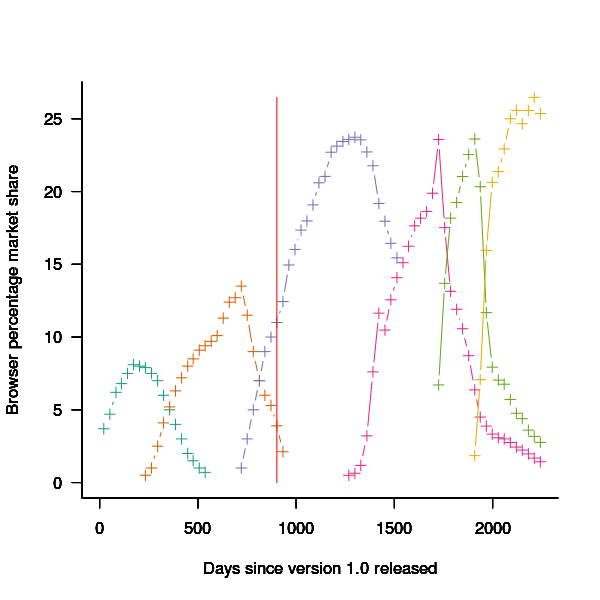
Figure 2. Market share of Firefox versions between official release and end-of-support. Data from url[www.w3schools.com].
The International Telecommunications Union publishers an estimate of the number of people per 100 head of population with Internet access for each year between 2003 and 2011 <book ITU_12>; the data is broken down by developed/developing countries and also by major world regions. Assuming that everybody who users the Internet uses a browser, this information can be combined with market share and human population data to estimate the number of Firefox users.
The ITU do not provide much information about how the usage figure is calculated or even which month of the year it applies to (since we are interested in change over time, knowing the month is not important and the start of the year is assumed). As the figure below shows the estimate over the period of interest can be accurately modeled by a straight line. A linear model was fitted to the data to predict usage between published estimates; over the period of interest the rate of growth in the Developed world has been almost twice as great as the rate in the whole world.
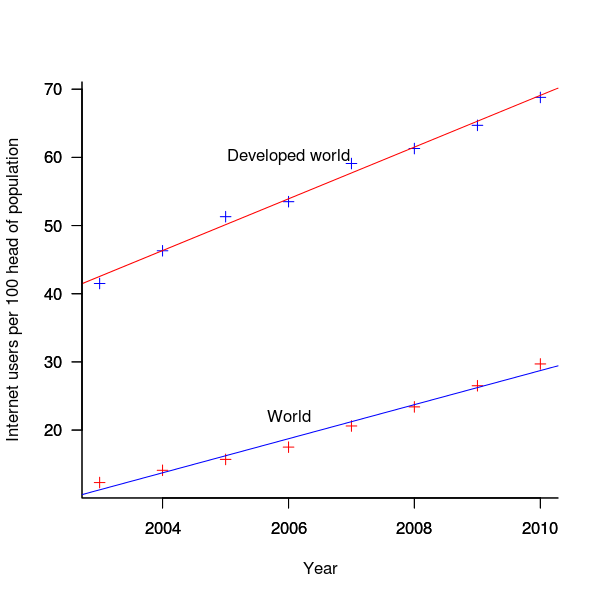
Figure 3. Number of people with Internet access per 100 head of population in the developed world and the whole world. Data from ITU <book <ITU_12>.
We are interested in relative change in total user population, and this can be obtained by multiplying the per-head of population value by the change in population (a 0.8% yearly growth is assumed for the developed world).
Possible significant factors for why the formula  might not accurately reflect the probability of a MFSA being reported include:
might not accurately reflect the probability of a MFSA being reported include:
- the characteristics of people who started using the Internet in 2004 may be different from those who first started in 2010:
- there will be variation in the amount of time people spend browsing, does the distribution of time usage differ between early and late adopters?
- some people are more likely than others to report a fault (e.g., my mum is a late adopter and extremely unlikely to report a fault, whereas I might report a fault),
- there may be significant regional differences, e.g., European users vs. Chinese users. These differences include the Internet sites visited (the behavior of Firefox will depend on the content of the web page visited) and may affect their propensity to report a problem (e.g., do the cultural stereotypes of Chinese acceptance of authority mean they are unlikely to report a fault while those noisy Americans complain about everything?)
The end-user usage for code originally written for a particular version, at a point in time, is calculated as follows:
- number of lines of code originally written for a particular version that is contained within the code used to build a later version, or that particular version; call this the build version,
- times the market share of the build version,
- times the number of Internet users of the build version (users in the Developed world was used).
The plot below is an example using the source code originally written for Firefox version 1.0. The green points are the code usage for version 1.0 code executing in Firefox build version 1.0, the orange points the code usage for version 1.0 code executing in build version 1.5 and so on to the yellow points which is the code usage for version 1.0 code executing in build version 3.6. The black points are the sum over all build versions.
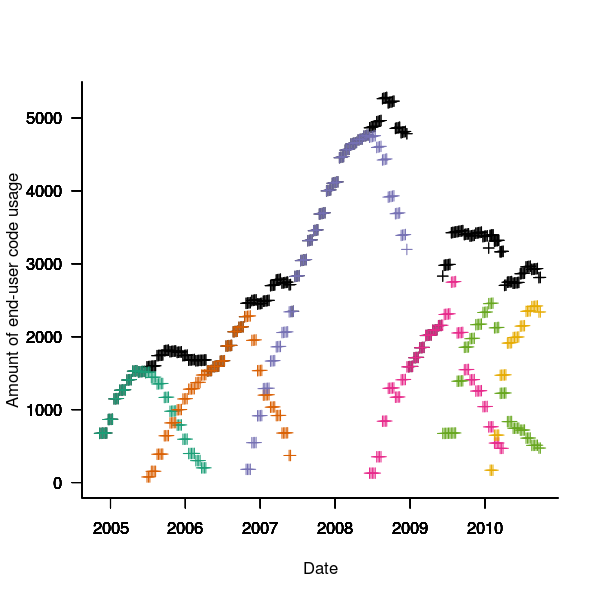
Figure 4. Amount of end-user usage of code originally written for Firefox version 1.0 by various other versions.
Much of the overall growth comes from growth in Internet usage, and in the early years there is also substantial growth in browser market share.
An analysis that attempts to connect Firefox usage with reported MFSAs will appear shortly (it would be surprising if fault report rate scaled linearly with end-user usage).
Unique bytes in a sliding window as a file content signature
I was at a workshop a few months ago where a speaker pointed out a useful technique for spotting whether a file contains compressed data, e.g., a virus hidden in a script by compressing it to look like a jumble of numbers. Compressed data contains a uniform distribution of byte values (after all, compression is achieved by reducing apparent information content), your mileage may vary between compression techniques. The thought struck me that it would only take a minute to knock up an R script to check out this claim (my use of R is starting to branch out into solving certain kinds of general coding problems) and here it is:
window_width=256 # if this is less than 256 divisor has to change in call to plot
plot_unique=function(filename)
{
t=readBin(filename, what="raw", n=1e7)
# Sliding the window over every point is too much overhead
cnt_points=seq(1, length(t)-window_width, 5)
u=sapply(cnt_points, function(X) length(unique(t[X:(X+window_width)])))
plot(u/256, type="l", xlab="Offset", ylab="Fraction Unique", las=1)
return(u)
}
dummy=plot_unique("http://shape-of-code.com/2013/05/17/preferential-attachment-applied-to-frequency-of-accessing-a-variable/")
dummy=plot_unique("http://www.shape-of-code.com/R_code/requirements.tgz") |
The unique bytes per window (256 bytes wide) of a HTML file has a mean around 15% (sd 2):
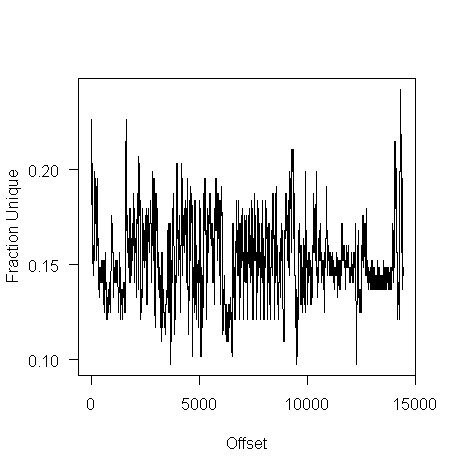
while for a tgz file the mean is 61% (sd 2.9):
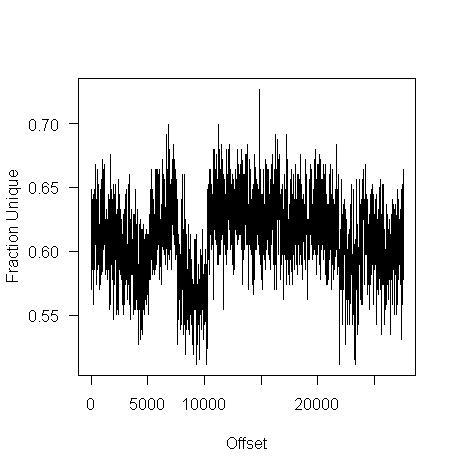
I don’t have any scripts containing a virus, but I do have a pdf containing lots of figures (are viruses hidden in pieces all all together?):
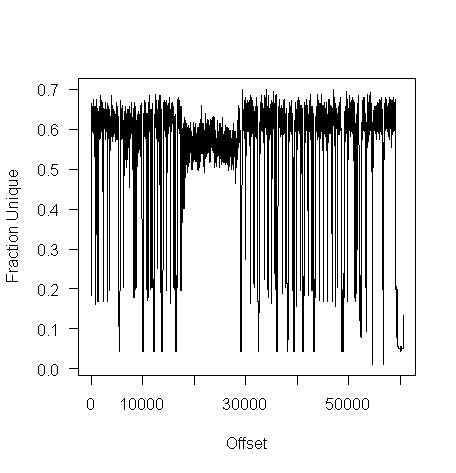
Do let me know if you find any interesting ‘unique byte’ signatures for file contents.
Free range software developers: Are they cost effective?
I have just been reading an eye-opening article by Ramin Shokrizade about the techniques that online game designers use to extract money from players. Playing computer games and writing software have a great deal in common, two important characteristics they both share are being immersive and very enjoyable.
Reward Removal
From the article: “The technique involves giving the player some really huge reward, that makes them really happy, and then threatening to take it away if they do not spend.” Hmm, this sounds familiar. Beginner programmers are very resistant to deleting any code they have written, whereas more experienced developers are much less resistant to deleting code but they often put up a fight if an attempt is made to remove a feature they are responsible for creating.
“The longer you allow the player to have the reward before you take it away, the more powerful is the effect.” Wot! Remove this feature? What if somebody somewhere is using it?
“… uses the same technique at the end of each dungeon again in the form of an inventory cap. The player is given a number of “eggs” as rewards, the contents of which have to be held in inventory. If your small inventory space is exceeded, again those eggs are taken from you unless you spend to increase your inventory space.” Why are there no researchers with this kind of penetrating insight investigating how to make software engineering more cost effective? We continue to suffer from the programming is logic by other means world view, promulgated by the failed mathematicians that populate so many computing departments.
Premium Currencies
“To maximize the efficacy of a coercive monetization model, you must use a premium currency, …” [a premium currency is in-game money that is disconnected from real wold money]. The lesson here is that if you want software developers to make decisions relating to real world events you need to provide a direct and transparent connection to the real world. Hide the connection under layers of abstraction or vague metrics and developers can be easily fooled into making poor decisions.
Skill Games vs. Money Games
“A game of skill … ability to make sound decisions primarily determines … success. A money game … ability to spend money is the primary determinant of … success. Consumers far prefer skill games to money games, …. A key skill in deploying a coercive monetization model is to disguise your money game as a skill game.”
I think most developers consider their job to be one of making skillful decisions rather than one of making money for their employer, rationalizing that these skillful decisions result in their employer making money. Hmm, how much time do developers spend in skillful activity for what appear to outsiders as obscure coding issues; skillful activity is enjoyable while doing what makes most money for one’s employer can result in having to do lots of really dull and boring tasks. I cannot help but think that skill here is playing the role of a premium currency.
The big difference between playing a game and writing software is that in most cases a game has a well defined ending, a path exists to get there and players know when they get there. One of the reasons that managing software developers is like herding cats is that the ‘end’ is often very fuzzy and ill-defined. This does not mean that factory farming techniques are not applicable to software development, just that we have not yet figured out which techniques work.
Empirical SE groups doing interesting work, 2013 version
Various people have asked me about who is currently doing interesting work in empirical software engineering and the following is an attempt to help answer this question. Interestingness is very subjective, in my case it is based on whether I think the work can contribute something towards my book on empirical software engineering.
To keep this list manageable I am restricting myself to groups of researchers (a group is two or more people) and giving priority to those who make their data publicly available.
Some background for those with no experience of academic research. Over a period of 4-5 years a group can go from having published nothing on a research topic to publishing some very interesting stuff to not publishing anything on the topic. Reasons for this include funding appearing/disappearing, the arrival/departure of very productive people (departure may be to other jobs or moving from research into management), or the researcher loosing interest and moving onto other things. A year from now any of the following groups may be disbanded or moved on to other research areas.
The conferences to check out are: Mining Software Repositories, Source Code Analysis and Manipulation, perhaps 1 in 2.5 of CREST Open Workshop and International Conference on Software Maintenance.
General sources of raw data include: promisedata and FLOSSmole is a firehose of bytes.
Who is the biggest group of researchers? In my mind it is the Canadians (to be exact the groups at Queen’s and Waterloo and the Ptidel project), now the empirical group at Microsoft would probably point out that they are not separated by several hundred miles and all work for the same company; this may be true but looking from Europe the Canadians look real close to each other on a map and all share a domain name ending in ca. In practice members of all three groups write papers together and spend time visiting/interning with each other. Given how rapidly things change I am not going to bother calculating an accurate number 1 for today.
Around the world (where there is no group page to link to I have used an individual’s page):
UK (theory in groups, practice by individuals; Brunel would warrant a link if they put some effort into maintaining a web presence and made their data available for download; come on guys)
USA (Devanbu, Grechanik, Kemerer, Menzies, SEMERU + TODO; Binkley for identifier semantics)
Some researchers leave a group to set up their own group and I know that some people in the above lists have done this. I wish them luck. If their group starts publishing interesting stuff they will be on any future version of this list.
Sitting here typing away I have probably missed out some obvious candidates. Pointers to obvious omissions welcome (remember this is about groups not individuals).
Survey of instruction selection
A well written survey of compiler instruction selection has just become available, the first major survey of this topic in 30 years! The academic outlook of the author is given away by the evaluation “…the technique appears to have had very limited impact as the citation count for the paper is low.” and coverage for the last 10 years does tend to thin out (but that could fill another 100 pages). Whatever your interest in compilers this survey is well worth a read.
Anybody reading a compiler book could be forgiven for thinking that instruction set selection was a minor issue; Gabriel Hjort Blindell counted 160 pages devoted to the topic out of 4,600 pages in seven well known compiler books. In a production compiler it is the parsing and semantics that consume 3% of the code with optimization and code generation making up the other 97%.
A 100 page survey of register allocation is also overdue (20 pages is a bit short).
Instruction set selection is one quarter of code generation, another quarter being register allocation and the remaining half being how these two are woven together (Hjort Blindell lists instruction scheduling as a third component and we could all argue for hours about whether this is another optimization, something that is spread over instruction selection/register allocation or a distinct component).
For a given choice of registers there are algorithms that will select the optimal code and for a given sequence of code there are algorithms that will select the optimal registers to use. Papers covering the optimal selection of both registers and instructions are thin on the ground; this is something of a black art that is picked up by building a production compiler.
Apps in Space Hackathon
I went along to the Satellite Applications hackathon last weekend. As a teenager I was very much into space flight and with this event being only 30 miles away how could I not attend. Around 25 or so hackers turned up, supported by seven or so knowledgeable and motivated people from the organizers/sponsors. Excellent food+drink, including sending out for Indian/Chinese for dinner. The one important item in short supply was example data to experiment with; the organizers are aware of this and plan to have a lot more data available at the next event.
The rationale for the event is to encourage the creation of business activities in the UK around the increasing amount of data beamed to Earth from satellites. At the moment a satellite image costs something like £100 if its in the back catalog and £10,000 if you want them to take one just for you; the price of images in the back catalog is about to plummet (new satellites coming on stream) and a company is being set up to act as a one stop shop+good user interface for pics (at the moment customers have to talk to a variety of suppliers to find see what’s available). I was excited to hear that I could have my own satellite launched for £100,000, the catch being that they are a bit more expensive to build.
Making use of satellite data requires other data plus support software. Many of the projects people decided to work on needed access to mapping data, e.g., which road is closest to this latitude/longitude. Open Streetmap is the obvious source of mapping data, the UK’s Ordinance Survey have also made some data freely available for public/commercial use. The current problem with this data is the lack of support libraries designed to handle satellite related queries (e.g., return nearest road, town, etc), the existing APIs are good for creating mapping images and dealing with routing.
Support for very large images is one area where existing tools are going to need an upgrade; by very large I mean single image files measured in gigabytes. I did not manage to view any gigabyte image files on my laptop (with 4G of ram), even after going for a coffee and sitting talking to somebody waiting for it to cool before drinking it, still a black rectangle. If the price of satellite images plummets and are easy to buy online, then I can imagine them becoming a discretionary item that people buy for a bit of fun and will then want to view using the devices they already own; telling them that this is not sensible is the wrong answer, the customer is always right and it has to be made to work.
One area where there is good software tool support is working out where satellites will appear in the sky; this is really an astronomical application and there are lots of astronomical tools out there. The Python crowd will be happy to know that scientific-grade astronomy routines are available in Pyephem.
For the most part the hacks created are bullet points of ideas and things to do. The team working on calculating the satellite beam likely to have the strongest signal at a given point on the Earth’s surface made a lot more progress than anybody else. This is because they had an existing Python library to use and ‘only’ needed to apply the trigonometry that we all learn in school.
Some suggestions for the organizers:
- put lightening talks on existing technologies and some of their uses on the agenda (the brief presentation given on SAR was eye opening),
- make some good example data public, i.e., downloadable for all to use. This is the only way to get lots of library support written,
- create cut-down datasets that are usable on laptops. At a Hackathon people can only productively use what they know well and requiring them to use something unfamiliar, such as a virtual machine, is a major road block,
- allow external users to take part, why limit your potential customer base to what can be fitted into a medium size room?
Hiring experts is cheaper in the long run
The SAMATE (Software Assurance Metrics And Tool Evaluation) group at the US National Institute of Standards and Technology recently started hosting a new version of test suites for checking how good a job C/C++/Java static analysis tools do at detecting vulnerabilities in source code. The suites were contributed by the NSA‘s Center for Assured Software.
Other test suites hosted by SAMATE contain a handful of tests and have obviously been hand written, one for each kind of vulnerability. These kind of tests are useful for finding out whether a tool detects a given problem or not. In practice problems occur within a source code context (e.g., control flow path) and a tool’s ability to detect problems in a wide range of contexts is a crucial quality factor. The NSA’s report on the methodology used looked good and with the C/C++ suite containing 61,387 tests it was obviously worth investigating.
Summary: Not a developer friendly test suite that some tools will probably fail to process because it exceeds one of their internal limits. Contains lots of minor language infringements that could generate many unintended (and correct) warnings.
Recommendation: There are people in the US who know how to write C/C++ test suites, go hire some of them (since this is US government money there are probably rules that say it has to go to US companies).
I’m guessing that this test suite was written by people with a high security clearance and a better than average knowledge of C/C++. For this kind of work details matter and people with detailed knowledge are required.
Another recommendation: Pay compiler vendors to add checks to their compilers. The GCC people get virtually no funding to do front end work (nearly all funding comes from vendors wanting backend support). How much easier it would be for developers to check their code if they just had to toggle a compiler flag; installing another tool introduces huge compatibility and work flow issues.
I had this conversation with a guy from GCHQ last week (the UK equivalent of the NSA) who are in the process of spending £5 million over the next 3 years on funding research projects. I suspect a lot of this is because they want to attract bright young things to work for them (student sponsorship appears to be connected with the need to pass a vetting process), plus universities are always pointing out how more research can help (they are hardly likely to point out that research on many of the techniques used in practice was done donkey’s years ago).
Some details
Having over 379,000 lines in the main function is not a good idea. The functions used to test each vulnerability should be grouped into a hierarchy; main calling functions that implement say the top 20 categories of vulnerability, each of these functions containing calls to the next level down and so on. This approach makes it easy for the developer to switch in/out subsets of the tests and also makes it more likely that the tool will not hit some internal limit on function size.
The following log string is good in theory but has a couple of practical problems:
printLine("Calling CWE114_Process_Control__w32_char_connect_socket_03_good();"); CWE114_Process_Control__w32_char_connect_socket_03_good(); |
C89 (the stated version of the C Standard being targeted) only requires identifiers to be significant to 32 characters, so differences in the 63rd character might be a problem. From the readability point of view it is a pain to have to check for values embedded that far into a string.
Again the overheads associated with storing so many strings of that length might cause problems for some tools, even good ones that might be doing string content scanning and checking.
The following is a recurring pattern of usage and has undefined behavior that is independent of the vulnerability being checked for. The lifetime of the variable shortBuffer terminates at the curly brace, }, and who knows what might happen if its address is accessed thereafter.
data = NULL; { /* FLAW: Point data to a short */ short shortBuffer = 8; data = &shortBuffer; } CWE843_Type_Confusion__short_68_badData = data; |
A high quality tool would report the above problem, which occurs in several tests classified as GOOD, and so appear to be failing (i.e., generating a warning when none should be generated).
The tests contain a wide variety of minor nits like this that the higher quality tools are likely to flag.
Data cleaning: The next step in empirical software engineering
Over the last 10 years software engineering researchers have gone from a state of data famine to being deluged with data. Until recently these researchers have been acting like children at a birthday party, rushing around unwrapping all the presents to see what is inside and quickly moving onto the next one. A good example of this are those papers purporting to have found a power law relationship between two constructs by simply plotting the data using log axis and drawing a straight line through the data; hey look, a power law, isn’t that interesting? Hopefully, these days, reviewers are starting to wise up and insist that any claims of a power law be checked.
Data cleaning is a very important topic that unfortunately appears to be missing from many researchers’ approach to data analysis. The quality of a model built from data is only as good as the quality of the data used to build it. Anybody who is interested in building models that connect to the real world of software engineering, rather than just getting another paper published, has to consider the messiness that gets added to data by the software developers who are intimately involved in the processes that generated the artifacts (e.g., source code, bug reports).
I have jut been reading a paper containing some unsettling numbers (It’s not a Bug, it’s a Feature: On the Data Quality of Bug Databases). A manual classification of over 7,000 issues reported against various large Java applications found that 42.6% of the issues were misclassified (e.g., a fault report was actually a request for enhancement), resulting in a change of status of 39% of the files once thought to contain a fault to not actually containing a fault (any fault prediction models built assuming the data in the fault database was correct now belong in the waste bin).
What really caught my eye about this research was the 725 hours (90 working days) invested by the researchers doing the manual classification (one person + independent checking by another). Anybody can extracts counts of this that and the other from the many repositories now freely available, generate fancy looking plots from them and add in some technobabble to create a paper. Real researchers invest lots of their time figuring out what is really going on.
These numbers are a wakeup call for all software engineering researchers. The data you are using needs to be thoroughly checked and be prepared to invest a lot of time doing it.
Recent Comments