Altruistic innovation and the study of software economics
Recently, I have been reading rather a lot of papers that are ostensibly about the economics of markets where applications, licensed under an open source license, are readily available. I say ostensibly, because the authors have some very odd ideas about the activities of those involved in the production of open source.
Perhaps I am overly cynical, but I don’t think altruism is the primary motivation for developers writing open source. Yes, there is an altruistic component, but I would list enjoyment as the primary driver; developers enjoy solving problems that involve the production of software. On the commercial side, companies are involved with open source because of naked self-interest, e.g., commoditizing software that complements their products.
It may surprise you to learn that academic papers, written by economists, tend to be knee-deep in differential equations. As a physics/electronics undergraduate I got to spend lots of time studying various differential equations (each relating to some aspect of the workings of the Universe). Since graduating, I have rarely encountered them; that is, until I started reading economics papers (or at least trying to).
Using differential equations to model problems in economics sounds like a good idea, after all they have been used to do a really good job of modeling how the universe works. But the universe is governed by a few simple principles (or at least the bit we have access to is), and there is lots of experimental data about its behavior. Economic issues don’t appear to be governed by a few simple principles, and there is relatively little experimental data available.
Writing down a differential equation is easy, figuring out an analytic solution can be extremely difficult; the Navier-Stokes equations were written down 200-years ago, and we are still awaiting a general solution (solutions for a variety of special cases are known).
To keep their differential equations solvable, economists make lots of simplifying assumptions. Having obtained a solution to their equations, there is little or no evidence to compare it against. I cannot speak for economics in general, but those working on the economics of software are completely disconnected from reality.
What factors, other than altruism, do academic economists think are of major importance in open source? No, not constantly reinventing the wheel-barrow, but constantly innovating. Of course, everybody likes to think they are doing something new, but in practice it has probably been done before. Innovation is part of the business zeitgeist and academic economists are claiming to see it everywhere (and it does exist in their differential equations).
The economics of Linux vs. Microsoft Windows is a common comparison, i.e., open vs. close source; I have not seen any mention of other open source operating systems. How might an economic analysis of different open source operating systems be framed? How about: “An economic analysis of the relative enjoyment derived from writing an operating system, Linux vs BSD”? Or the joy of writing an editor, which must be lots of fun, given how many have text editors are available.
I have added the topics, altruism and innovation to my list of indicators of poor quality, used to judge whether its worth spending more than 10 seconds reading a paper.
Regression line fitted to noisy data? Ask to see confidence intervals
A little knowledge can be a dangerous thing. For instance, knowing how to fit a regression line to a set of points, but not knowing how to figure out whether the fitted line makes any sense. Fitting a regression line is trivial, with most modern data analysis packages; it’s difficult to find data that any of them fail to fit to a straight line (even randomly selected points usually contain enough bias on one direction, to enable the fitting algorithm to converge).
Two techniques for checking the goodness-of-fit, of a regression line, are plotting confidence intervals and listing the p-value. The confidence interval approach is a great way to visualize the goodness-of-fit, with the added advantage of not needing any technical knowledge. The p-value approach is great for blinding people with science, and a necessary technicality when dealing with multidimensional data (unless you happen to have a Tardis).
In 2016, the Nationwide Mutual Insurance Company won the IEEE Computer Society/Software Engineering Institute Watts S. Humphrey Software Process Achievement (SPA) Award, and there is a technical report, which reads like an infomercial, on the benefits Nationwide achieved from using SEI’s software improvement process. Thanks to Edward Weller for the link.
Figure 6 of the informercial technical report caught my eye. The fitted regression line shows delivered productivity going up over time, but the data looks very noisy. How good a fit is that regression line?
Thanks to WebPlotDigitizer, I quickly extracted the data (I’m a regular user, and WebPlotDigitizer just keeps getting better).
Below is the data plotted to look like Figure 6, with the fitted regression line in pink (code+data). The original did not include tick marks on the axis. For the x-axis I assumed each point was at a fixed 2-month interval (matching the axis labels), and for the y-axis I picked the point just below the zero to measure length (so my measurements may be off by a constant multiplier close to one; multiplying values by a constant will not have any influence on calculating goodness-of-fit).
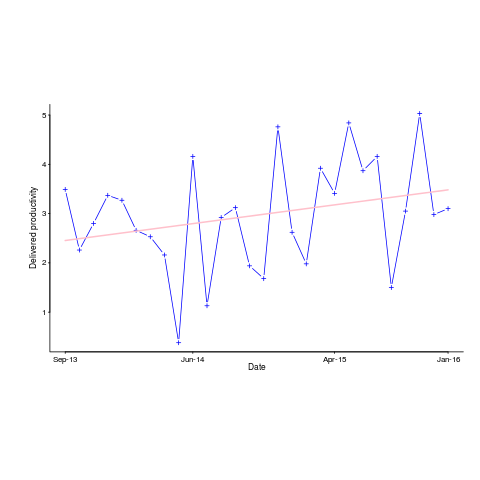
The p-value for the fitted line is 0.15; gee-wiz, you say. Plotting with confidence intervals (in red; the usual 95%) makes the situation clear:
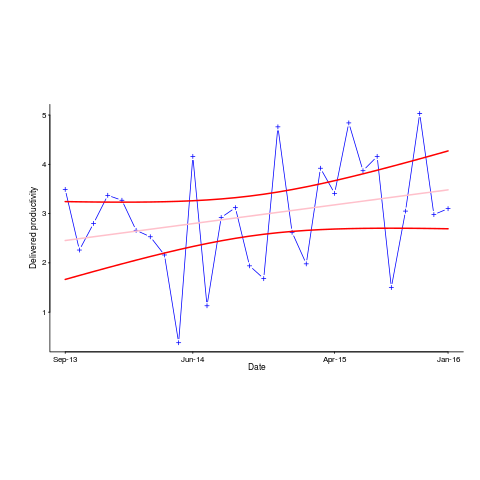
Ok, so the fitted model is fairly meaningless from a technical perspective; the line might actually go down, rather than up (there is too much noise in the data to tell). Think of the actual line likely appearing somewhere in the curved red tube.
Do Nationwide, IEEE or SEI care? The IEEE need a company to award the prize to, SEI want to promote their services, and Nationwide want to convince the rest of the world that their IT services are getting better.
Is there a company out there who feels hard done-by, because they did not receive the award? Perhaps there is, but are their numbers any better than Nationwide’s?
How much influence did the numbers in Figure 6 have on the award decision? Perhaps not a lot, the other plots look like they would tell a similar tail of wide confidence intervals on any fitted lines (readers might like to try their hand drawing confidence intervals for Figure 9). Perhaps Nationwide was the only company considered.
Who are the losers here? Other companies who decide to spend lots of money adopting the SEI software process? If evidence was available, perhaps something concrete could be figured out.
Polished human cognitive characteristics chapter
It has been just over two years since I release the first draft of the Human cognitive characteristics chapter of my evidence-based software engineering book. As new material was discovered, it got added where it seemed to belong (at the time), no effort was invested in maintaining any degree of coherence.
The plan was to find enough material to paint a coherence picture of the impact of human cognitive characteristics on software engineering. In practice, finishing the book in a reasonable time-frame requires that I stop looking for new material (assuming it exists), and go with what is currently available. There are a few datasets that have been promised, and having these would help fill some holes in the later sections.
The material has been reorganized into what is essentially a pass over what I think are the major issues, discussed via studies for which I have data (the rule of requiring data for a topic to be discussed, gets bent out of shape the most in this chapter), presented in almost a bullet point-like style. At least there are plenty of figures for people to look at, and they are in color.
I think the material will convince readers that human cognition is a crucial topic in software development; download the draft pdf.
Model building by cognitive psychologists is starting to become popular, with probabilistic languages, such as JAGS and Stan, becoming widely used. I was hoping to build models like this for software engineering tasks, but it would have taken too much time, and will have to wait until the book is done.
As always, if you know of any interesting software engineering data, please let me know.
Next, the cognitive capitalism chapter.
Modular vs. monolithic programs: a big performance difference
For a long time now I have been telling people that no experiment has found a situation where the treatment (e.g., use of a technique or tool) produces a performance difference that is larger than the performance difference between the subjects.
The usual results are that differences between people is the source of the largest performance difference, successive runs are the next largest (i.e., people get better with practice), and the smallest performance difference occurs between using/not using the technique or tool.
This is rather disheartening news.
While rummaging through a pile of books I had not looked at in many years, I (re)discovered the paper “An empirical study of the effects of modularity on program modifiability” by Korson and Vaishnavi, in “Empirical Studies of Programmers” (the first one in the series). It’s based on Korson’s 1988 PhD thesis, with the same title.
There were four experiments, involving seven people from industry and nine students, each involving modifying a 900(ish)-line program in some way. There were two versions of each program, they differed in that one was written in a modular form, while the other was monolithic. Subjects were permuted between various combinations of program version/problem, but all problems were solved in the same order.
The performance data (time to complete the task) was published in the paper, so I fitted various regressions models to it (code+data). There is enough information in the data to separate out the effects of modular/monolithic, kind of problem and subject differences. Because all subjects solved problems in the same order, it is not possible to extract the impact of learning on performance.
The modular/monolithic performance difference was around twice as large as the difference between subjects (removing two very poorly performing subjects reduces the difference to 1.5). I’m going to have to change my slides.
Would the performance difference have been so large if all the subjects had been experienced developers? There is not a lot of well written modular code out there, and so experienced developers get lots of practice with spaghetti code. But, even if the performance difference is of the same order as the difference between developers, that is still a very worthwhile difference.
Now there are lots of ways to write a program in modular form, and we don’t know what kind of job Korson did in creating, or locating, his modular programs.
There are also lots of ways of writing a monolithic program, some of them might be easy to modify, others a tangled mess. Were these programs intentionally written as spaghetti code, or was some effort put into making them easy to modify?
The good news from the Korson study is that there appears to be a technique that delivers larger performance improvements than the difference between people (replication needed). We can quibble over how modular a modular program needs to be, and how spaghetti-like a monolithic program has to be.
Evidence-based election campaigning
I was at a hackathon on evidence-based election campaigning yesterday, organized by Campaign Lab.
My previous experience with political oriented hackathons was a Lib Dem hackathon; the event was only advertised to party members and I got to attend because a fellow hackathon-goer (who is a member) invited me along. We spent the afternoon trying to figure out how to extract information on who turned up to vote, from photocopies of lists of people eligible to vote marked up by the people who hand out ballot papers.
I have also been to a few hackathons where the task was to gather and analyze information about forthcoming, or recent, elections. There did not seem to be a lot of information publicly available, and I had assumed that the organization, and spending power, of the UK’s two main parties (i.e., Conservative and Labour) meant that they did have data.
No, the main UK political parties don’t have lots of data, in fact they don’t have very much at all, and make hardly any use of what they do have.
I had a really interesting chat with Campaign Lab’s Morgan McSweeney, about political campaigning, and how they have not been evidence-based. There were lots of similarities with evidence-based software engineering, e.g., a few events (such the Nixon vs. Kennedy and Bill Clinton elections) created campaigning templates that everybody else now follows. James Moulding drew diagrams showing Labour organization and Conservative non-organization (which looked like a Dalek) and Hannah O’Rourke spoiled us with various kinds of biscuits.
An essential component of evidence-based campaigning is detailed knowledge of the outcome, such as: how many votes did each candidate get? Based on past hackathon experience, I thought this data was only available for recent elections, but Morgan showed me that Wikipedia had constituency level results going back many years. Here was a hackathon task; collect together constituency level results, going back decades, in one file.
Following the Wikipedia citations led me to Richard Kimber’s website, which had detailed results at the constituency level going back to 1945. The catch was that there was a separate file for each constituency; I emailed Richard, asking for a file containing everything (Richard promptly replied, the only files were the ones on the website).
Pivot.
The following plot was created using some of the data made available during a hackathon at the Office of National Statistics (sometime in 2015). We (Pavel+others and me) did not make much use of this plot at the time, but it always struck me as interesting. I showed it to the people at this hackathon, who sounded interested. The plot shows the life-expectancy for people living in a constituency where Conservative(blue)/Labour(red) candidate won the 2015 general election by a given percentage margin, over the second-placed candidate.
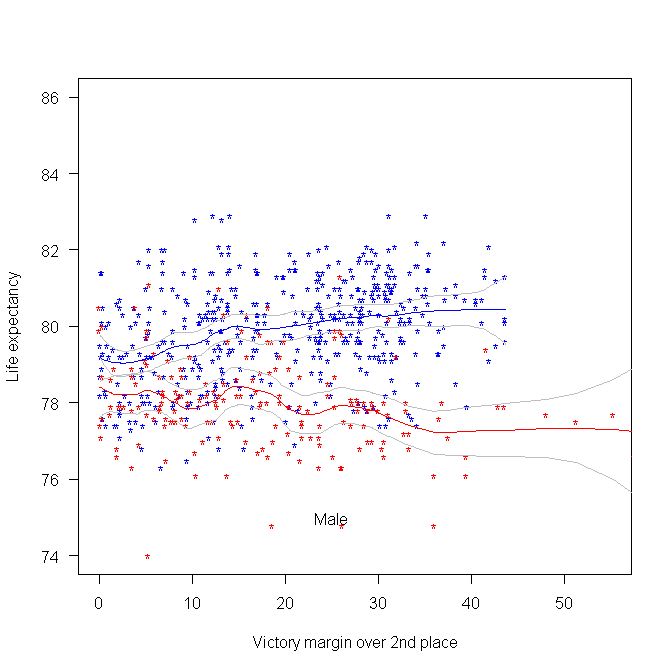
Rather than scrape the election data (added to my TODO list), I decided to recreate the plot and tidy up the associated analysis code; it’s now available via the CampaignLab Github repo
My interpretation of the difference in life-expectancy is that the Labour strongholds are in regions where there is (or once was) lots of heavy industry and mining; the kind of jobs where people don’t live long after retiring.
Offer of free analysis of your software engineering data
Since the start of this year, I have been telling people that I willing to analyze their software engineering data for free, provided they are willing to make the data public; I also offer to anonymize the data for them, as part of the free service. Alternatively you could read this book, and do the analysis yourself.
What will you get out of me analyzing your data?
My aim is to find patterns of behavior that will be useful to you. What is useful to you? You have to be the judge of that. It is possible that I will not find anything useful, or perhaps any patterns at all; this does not happen very often. Over the last year I have found (what I think are useful) patterns in several hundred datasets, with one dataset that I am still scratching my head over it.
Data analysis is a two-way conversation. I find some patterns, and we chat about them, hopefully you will say one of them is useful, or point me in a related direction, or even a completely new direction; the process is iterative.
The requirement that an anonymized form of the data be made public is likely to significantly reduce the offers I receive.
There is another requirement that I don’t say much about: the data has to be interesting.
What makes software engineering data interesting, or at least interesting to me?
There has to be lots of it. How much is lots?
Well, that depends on the kind of data. Many kinds of measurements of source code are generally available by the truck load. Measurements relating to human involvement in software development are harder to come by, but becoming more common.
If somebody has a few thousand measurements of some development related software activity, I am very interested. However, depending on the topic, I might even be interested in a couple of dozen measurements.
Some measurements are very rare, and I would settle for as few as two measurements. For instance, multiple implementations of the same set of requirements provides information on system development variability; I was interested in five measurements of the lines of source in five distinct Pascal compilers for the same machine.
Effort estimation data used to be rare; published papers sometimes used to include a table containing the estimate/actual data, which was once gold-dust. These days I would probably only be interested if there were a few hundred estimates, but it would depend on what was being estimated.
If you have some software engineering data that you think I might be interested in, please email to tell me something about the data (and perhaps what you would like to know about it). I’m always open to a chat.
If we both agree that it’s worth looking at your data (I will ask you to confirm that you have the rights to make it public), then you send me the data and off we go.
Modeling visual studio C++ compile times
Last week I spotted an interesting article on the compile-time performance of C++ compilers running under Microsoft Windows. The author had obviously put a lot of work into gathering the data, and had taken care to have multiple runs to reduce the impact of random effects (128 runs to be exact); but, as if often the case, the analysis of the data was lackluster. I posted a comment asking for the data, and a link was posted the next day 🙂
The compilers benchmarked were: Visual Studio 2015, Visual Studio 2017 and clang 7.0.1; the compilers were configured to target: C++20, C++17, C++14, C++11, C++03, or C++98. The source code used was 100 system headers.
If we are interested in understanding the contribution of each component to overall compile-time, the obvious fist regression model to build is:

where:  are the different headers,
are the different headers,  the different compilers and
the different compilers and  the different target languages. There might be some interaction between variables, so something more complicated was tried first; the final fitted model was (code+data):
the different target languages. There might be some interaction between variables, so something more complicated was tried first; the final fitted model was (code+data):

where  is a constant (the
is a constant (the Intercept in R’s summary output). The following is a list of normalised numbers to plug into the equation (clang is the default compiler and C++03 the default language, and so do not appear in the list, the : symbol represents the multiplication; only a few of the 100 headers are listed, details are available):
Estimate Std. Error t value Pr(>|t|) (Intercept) headerany 1.000000000 0.051100398 headerarray headerassert.h 0.522336397 -0.654056185 ... headerwctype.h headerwindows.h -0.648095154 1.304270250 compilerVS15 compilerVS17 -0.185795534 -0.114590143 languagec++11 languagec++14 0.032930014 0.156363433 languagec++17 languagec++20 0.192301727 0.184274629 languagec++98 compilerVS15:languagec++11 0.001149643 -0.058735591 compilerVS17:languagec++11 compilerVS15:languagec++14 -0.038582437 -0.183708714 compilerVS17:languagec++14 compilerVS15:languagec++17 -0.164031495 NA compilerVS17:languagec++17 compilerVS15:languagec++20 -0.181591418 NA compilerVS17:languagec++20 compilerVS15:languagec++98 -0.193587045 0.062414667 compilerVS17:languagec++98 0.014558295 |
As an example, the (normalised) time to compile wchar.h using VS15 with languagec++11 is:
1-0.514807638-0.183862162+0.033951731-0.059720131
Each component adds/substracts to/from the normalised mean.
Building this model didn’t take long. While waiting for the kettle to boil, I suddenly realised that an additive model was probably inappropriate for this problem; oops. Surely the contribution of each component was multiplicative, i.e., components have a percentage impact to performance.
A quick change to the form of the fitted model:
 = k+header_x+compiler_y+language_z+compiler_y*language_z")
Taking the exponential of both side, the fitted equation becomes:

The numbers, after taking the exponent, are:
(Intercept) headerany 9.724619e+08 1.051756e+00 ... headerwctype.h headerwindows.h 3.138361e-01 2.288970e+00 compilerVS15 compilerVS17 7.286951e-01 7.772886e-01 languagec++11 languagec++14 1.011743e+00 1.049049e+00 languagec++17 languagec++20 1.067557e+00 1.056677e+00 languagec++98 compilerVS15:languagec++11 1.003249e+00 9.735327e-01 compilerVS17:languagec++11 compilerVS15:languagec++14 9.880285e-01 9.351416e-01 compilerVS17:languagec++14 compilerVS15:languagec++17 9.501834e-01 NA compilerVS17:languagec++17 compilerVS15:languagec++20 9.480678e-01 NA compilerVS17:languagec++20 compilerVS15:languagec++98 9.402461e-01 1.058305e+00 compilerVS17:languagec++98 1.001267e+00 |
Taking the same example as above: wchar.h using VS15 with c++11. The compile-time (in cpu clock cycles) is:
9.724619e+08*3.138361e-01*7.286951e-01*1.011743e+00*9.735327e-01
Now each component causes a percentage change in the (mean) base value.
Both of these model explain over 90% of the variance in the data, but this is hardly surprising given they include so much detail.
In reality compile-time is driven by some combination of additive and multiplicative factors. Building a combined additive and multiplicative model is going to be like wrestling an octopus, and is left as an exercise for the reader 🙂
Given a choice between these two models, I think the multiplicative model is probably closest to reality.
Teaching basic data analysis to programmers: summer internship
Software engineering is one of the topics in this year’s summer internships being sponsored by R-Studio. The spec says: “Data Science Training for Software Engineers – Develop course materials to teach basic data analysis to programmers using software engineering problems and data sets.”
It’s good to see interest in data analysis of software engineering data start to gain traction.
What topics might basic data analysis for programmers include? I have written about statistical techniques that I think are useful in software engineering, but I don’t think this list would be regarded as basic. Techniques that are think are basic are:
- a picture is worth a thousand words, so obviously visualization is a major topic,
- building regression models is good for helping to understand what is going on.
Anything else? Well, I don’t know.
An alternative approach to teaching basic data analysis is to give examples of the kind of useful things it can be used to do. Software developers are fast learners, and given the motivation have the skills needed to find and learn techniques that they think are of use. In a basic course, I would put the emphasis on motivating developers to think that data analysis can help them do a better job.
I would NOT, repeat, not, include any material on machine learning. Software engineering data sets tend to be too small to obtain reliable results from machine learning, and I don’t want to encourage clueless button pushers.
What are the desirable skills in the summer intern? I would say that being able to write readable material is the most important, with statistical knowledge ranked second; the level of software engineering knowledge is unimportant. Data analysis tends to follow the same pattern whatever the subject; so it’s important to get somebody who knows about data analysis.
A social science major is the obvious demographic for this intern (they do lots of data analysis); the last people to consider are students majoring in a computing subject.
Choosing between two reasonably fitting probability distributions
I sometimes go fishing for a probability distribution to fit some software engineering data I have. Why would I want to spend time fishing for a probability distribution?
Data comes from events that are driven by one or more processes. Researchers have studied the underlying patterns present in many processes and in some cases have been able to calculate which probability distribution matches the pattern of data that it generates. This approach starts with the characteristics of the processes and derives a probability distribution. Often I don’t really know anything about the characteristics of the processes that generated the data I am looking at (but I can often make what I like to think are intelligent guesses). If I can match the data with a probability distribution, I can use what is known about processes that generate this distribution to get some ideas about the kinds of processes that could have generated my data.
Around nine-months ago, I learned about the Conway–Maxwell–Poisson distribution (or COM-Poisson). This looked as-if it might find some use in fitting software engineering data, and I added it to my list of distributions to keep in mind. I saw that the R package COMPoissonReg supports the fitting of COM-Poisson distributions.
This week I came across one of the papers, about COM-Poisson, that I was reading nine-months ago, and decided to give it a go with some count-data I had.
The Poisson distribution involves count-data, i.e., non-negative integers. Lots of count-data samples are well described by a Poisson distribution, and it is one of the basic distributions supported by statistical packages. Processes described by a Poisson distribution are memory-less, in that the probability of an event occurring are independent of when previous events occurred. When there is a connection between events, the Poisson distribution is not such a good fit (depending on the strength of the connection between events).
While a process that generates count-data may not meet the requirements needed to be exactly described by a Poisson distribution, the behavior may be close enough to give good-enough results. R supports a quasipoisson distribution to help handle the ‘near-misses’.
Sometimes count-data has a distribution that looks nothing like a Poisson. The Negative-binomial distribution is the obvious next choice to try (this can be viewed as a combination of different Poisson distributions; another combination is the Poisson inverse gaussian distribution).
The plot below (from a paper analyzing usage of record data structures in Racket; Tobias Pape kindly sent me the data) shows the number of Racket structure types that contain a given number of fields (red pluses), along with lines showing fitted Negative binomial and COM-Poisson distributions (code+data):
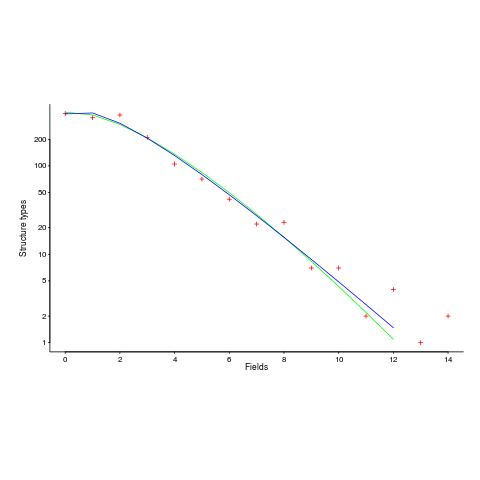
I’m interested in understanding the processes that are generating the data, and having two distributions do such a reasonable job of fitting the data has given me more possible distinct explanations for what is going on than I wanted (if I were interested in prediction, then either distribution looks like it would do a good-enough job).
What are the characteristics of the processes that generate data having each of the distributions?
- A Negative binomial can be viewed as a combination of Poisson distributions (the combination having a Gamma distribution). We could create a story around multiple processes being responsible for the pattern seen, with each of these processes having the impact of a Poisson distribution. Sounds plausible.
- A COM-Poisson distribution can be viewed as a Poisson distribution which is length dependent. We could create a story around the probability of a field being added to a structure type being dependent on the number of existing fields it contains. Sounds plausible (it’s a slightly different idea from preferential attachment).
When fitting a distribution to data, I usually go with the ‘brand-name’ distributions (i.e., the one with most name recognition, provided it matches well enough; brand names are an easier sell then the less well known names).
The Negative binomial distribution is the brand-name here. I had not heard of the COM-Poisson distribution until nine-months ago.
Perhaps the authors of the Racket analysis paper will come up with a theory that prefers one of these distributions, or even suggests another one.
Readers of my evidence-based software engineering book need to be aware of my brand-name preference in some of the data fitting that occurs.
Wanted: 99 effort estimation datasets
Every now and again, I stumble upon a really interesting dataset. Previously, when this happened I wrote an extensive blog post; but the SiP dataset was just too big and too detailed, it called out for a more expansive treatment.
How big is the SiP effort estimation dataset? It contains 10,100 unique task estimates, from ten years of commercial development using Agile. That’s around two orders of magnitude larger than other, current, public effort datasets.
How detailed is the SiP effort estimation dataset? It contains the (anonymized) identity of the 22 developers making the estimates, for one of 20 project codes, dates, plus various associated items. Other effort estimation datasets usually just contain values for estimated effort and actual effort.
Data analysis is a conversation between the person doing the analysis and the person(s) with knowledge of the application domain from which the data came. The aim is to discover information that is of practical use to the people working in the application domain.
I suggested to Stephen Cullum (the person I got talking to at a workshop, a director of Software in Partnership Ltd, and supplier of data) that we write a paper having the form of a conversation about the data; he bravely agreed.
The result is now available: A conversation around the analysis of the SiP effort estimation dataset.
What next?
I’m looking forward to seeing what other people do with the SiP dataset. There are surely other patterns waiting to be discovered, and what about building a simulation model based on the charcteristics of this data?
Turning software engineering into an evidence-based disciple requires a lot more data; I plan to go looking for more large datasets.
Software engineering researchers are a remarkable unambitious bunch of people. The SiP dataset should be viewed as the first of 100 such datasets. With 100 datasets we can start to draw general, believable conclusions about the processes involved in software effort estimation.
Readers, today is the day you start asking managers to make any software engineering data they have publicly available. Yes, it can be anonymized (I am willing to do that for people who are looking to release data). Yes, ‘old’ data is useful (data from the 1980s could have an interesting story to tell; SiP runs from 2004-2014). Yes, I will analyze any interesting data that is made public for free.
Ask, and you shall receive.
Recent Comments