Archive
Performing a non-local return in R
In most languages return is a statement, but in R it is a function (in fact R does not really have statements, it only has expressions). This function-like behavior of return is useful for figuring out the order in which operations are performed, e.g., the value returned by return(1)+return(2) tells us that binary operators are evaluated left to right.
R also supports lazy evaluation, operands are only evaluated when their value is required. The question of when a value might be required is a very complicated rabbit hole. In R’s case arguments to function calls are lazy and in the following code:
ret_a_b=function(a, b) { if (runif(1, -1, 1) < 0) a else b } helpless=function() { ret_a_b(return(3), return(4)) return(99) } |
a call to helpless results in either 3 or 4 being returned.
This ability to perform non-local returns is just what is needed to implement exception handling recovery, i.e., jumping out of some nested function to a call potentially much higher up in the call tree, without passing back up through the intervening function called, when something goes wrong.
Having to pass the return-blob to every function called would be a pain, using a global variable would make life much simpler and less error prone. Simply assigning to a global variable will not work because the value being assigned is evaluated (it does not have to be, but R chooses to not to be lazy here). My first attempt to get what I needed into a global variable involved delayedAssign, but that did not work out. The second attempt made use of the environment created by a nested function definition, as follows:
# Create an environment containing a return that can be evaluated later. set_up=function(the_ret) { ret_holder=function() { the_ret } return(ret_holder) } # For simplicity this is not nested in some complicated way do_stuff=function() { # if (something_gone_wrong) get_out_of_jail() return("done") } get_out_of_jail=0 # Out friendly global variable control_func=function(a) { # Set up what will get called get_out_of_jail <<- set_up(return(a)) # do some work do_stuff() return(0) } control_func(11) |
and has the desired effect 🙂
Prompt Parking near Buckingham Palace
I was at the Urban Data Hack at the weekend run by Data Science London (doing their usual excellent job of feeding and watering us). Team Prompt Parking (me, Manoj, Lusine and Bob {of team Outlier fame}) created an App (try it) that gives drivers directions to the closest locations, in Westminster, most likely to have an empty parking space, taking into account preferences for space actually being available, distance to drive and probability of experiencing vehicle/personal crime close to the parking bay.
The default starting location is the official London residence of the Queen, which is in Westminster (most of the data came from Westminster City Council), and can be changed by entering latitude/longitude at the top of the page; in practice it would use the current location reported by the phone gps.
How does the App work? Based on your current location, day of week and time of day, it obtains data on ‘close’ parking bays (precomputed data; see below), applies the user preferences to the bay data to obtained a weighted preference for each bay, picks the four bay locations with the highest weight and feeds these locations into Google maps to draw the route.
The precomputed data included (code and data):
- mean number of empty parking spaces within every 15 minute window of a given day of the week (the week was assumed to be the only parking related cycle). The parking dataset included every parking transaction in Westminster between April 2013 to January 2014; the 861 megabyte file containing 6,967,793 transactions was boiled down to 49M using
awkto split the data up, one file per parking location, making it practical to run anRscript on each file to do the averaging (we also calculated a standard deviation which never got integrated into the weighting), - likelihood of crime against vehicles and people. The crime data included a lat/long and the ‘influence’ of each recorded crime (i.e., the likelihood of another crime being committed nearby) was assumed to have a gaussian distribution having a mean of 200 meters (chosen by a couple of white guys staring at the ceiling). The crime data was monthly and sparse (good for citizens but bad for data analysis) and ended up being amalgamated to an overall number per parking location per year (i.e., the gaussians for each crime ‘influence’ were summed over the area of Westminster),
- the distance, along streets (not flying crows), to every parking bay was calculated from 50 ‘red spots’ (these spots were chosen to be well distributed over major routes within Westminster). The App takes the user’s location and calculates the closest red spot to use for parking bay distance information.
- the data included parking cost information but we did not get around to including that in the App
The hack had prizes for various categories. Team Prompt Parking received 1st Prize for Urban Data Integration, which surprised me as I thought we were the best in some of the other categories. My heart sank when I saw the Team DeTile App (the team’s Italian accent may have thrown my spelling) which combined crime data with a property company’s API to produce a flat (apartment in the US) finder recommender running on a phone; they deserved to win the Best App category.
Team Prompt Parking did not consider how money might be made from the App; our submission report included crowd pleasing concepts such as reducing CO2 emissions and accident rates by reducing driving time to find an empty parking space. Having drivers look at ads displayed in the App would probably increase accidents.
A more promising money making App, using this data, would target traffic wardens; the data shows a higher empty bay rate than that experienced by the central London drivers I spoke to at the weekend (some obvious human biases spring to mind here). There is an opportunity here for a startup to offer traffic wardens routes tailored to maximize the number of parking tickets per hour; the company would take a percentage of the warden’s earnings.
The main lesson learned was not to create large databases in the cloud during a short hack. While one database containing all the data is a good idea in theory, in a 24 hour hackathon there is not a lot of time to iterate when database creation goes wrong (which everybodies did, several times). It is better to do as much as possible on local laptops (I split the 860M data file into smaller chunks using a local awk script rather than load it into a cloudy sql database that I then had to access remotely).
We had a separate database for each dataset, making it quick to iterate changes to each dataset and not creating dependencies that held up testing using the other datasets.
Adverts during compilation; the future for gcc and llvm?
Many of the larger open source projects have most of their manpower supplied by commercial companies. Companies pay developers to work on open source projects because it is in their interest to do so. The current level of funding will not last forever and some open source projects will either have to significantly slim down their operations or find other revenue streams.
For the last few years (and probably the next few) Mozilla obtained most of its funding from Google through a licensing agreement (Google is the default search engine in the search box). No company wants to be dependent on a single source for a large chunk of its income and Mozilla is no exception. But where are the review streams for open source companies? Training and consulting are the obvious choices for technical products, but web browsers are supposed to user friendly, not technical. Another option is advertising and Mozilla has indicated an intent to go down this path.
How are open source compilers funded? A lot of the work on gcc used to be done by the folk at Code Sourcery, which is not owned by Mentor Graphics, and I was told their income primarily came from companies interested in ports to new processors and platforms. I have no idea how the gcc group is funded inside Mentor Graphics, but the long term prognosis does not look good; there is a long history of large tech companies buying compiler outfits and closing them down some years later (because the income they produce is not worth the hassle). The LLVM project, I’m told, gets most of its funding from Apple and one of my predictions for 2009 was that this funding would go away and LLVM would die; ok I was wrong about the year, but eventually Apple will stop funding this project.
Advertising is a possible revenue stream for compiler vendors; compilers could show adverts while compiling. Anybody who has used a commercial compiler will be familiar with the copyright notices that appear at the start of every compilation, so having a text message appear at the start of every compile is not new. Advertising could take the form of product placement “This version of gcc is brought to you by Wizzo Wash” or display material downloaded during compilation.
Adverts during compilation are not going to be popular with developers. One solution is to offer a subscription service for an ads free version of the compiler. It will certainly be necessary to make it much more difficult to build the compiler from source.
This form of revenue generation will have to be sold to developers; a group not known for its willingness to pay for tools (new tool vendors quickly learn to sell to management and ignore developers) combined with compiler writers not being known for having any selling ability.
Honking the horn for go faster memory (over go faster cpus)
I have been doing some analysis of computer performance, as measured by the results of the SPEC 2006 int benchmark (i.e, no floating point). As the following plot shows, computers are continuing to get faster (code and data):
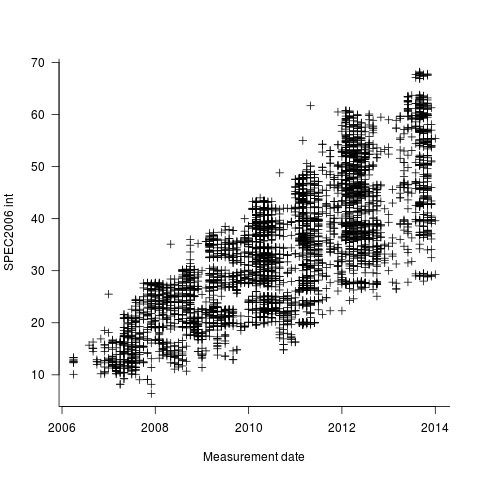
I think the widening spread of results might have a lot to do with companies slowly migrating to the newer benchmark, increasing the range of test cases; there mus also be an element of an increasing range of computer performance on offer from vendors now we have reached the good-enough point.
In the last century the increase in performance was strongly correlated with increasing cpu clock speed. As the following plot shows, this century is different (in years to come the first few years, where this correlation quickly died out, will be treated as a round-off error); performance is more likely to be higher at a higher clock rate, but far from guaranteed:
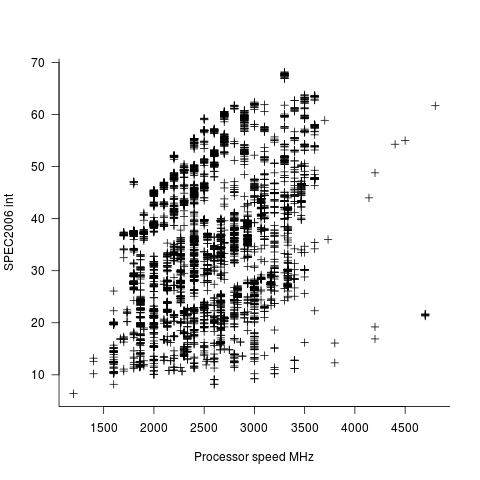
One of the reasons for this change is that, for many tasks, cpus are now seriously performance limited by memory bandwidth, and so these days a lot of the performance improvement is coming from faster memory (yes, it is really about shifting more bytes per clock tick, but a common faster/slower vocabulary keeps things simpler). The following plot uses PC2 (blue) and PC3 (red) module numbers:
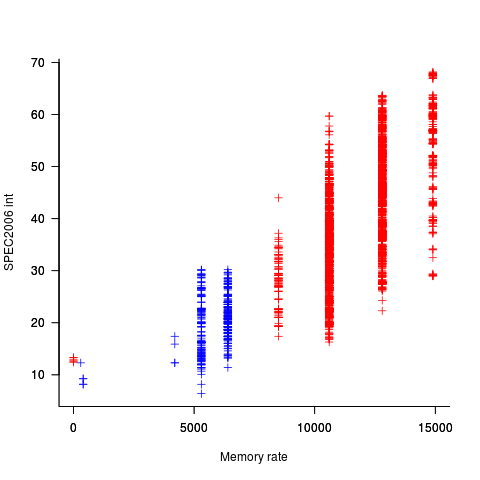
Making use of go faster memory is not as straight-forward as using a go faster cpu. Memory chip configuration includes more tuning options than cpus, which just need a faster clock. That spread in performance, for a given memory rate can probably be traced to use of different options and of course cpu caches play an important part in improving performance. The SPEC results do contain lots of descriptive details about cache characteristics, but extracting it will be fiddly and analysing this kind of stuff always makes my head hurt.
The computer buying public have learned that higher clock rate is better. Unfortunately they still think this applies to cpus when they should now be asking about memory speed. When I ask people about the speed of memory in their computer I am usually told how many gigabytes it has, or get the same kind of look I used to get many years ago when asking about cpu speed.
Tool for tuning the use of floating-point types
A common problem when writing code that performs floating-point arithmetic is figuring out which of the available three (usually) possible floating-point types to use (e.g., float, double or long double). Some language ‘solve’ this problem by only having one possibility (e.g., R) and some implementations of languages that offer three types use the same representation for all of them (e.g., 32 bits).
The type float often represents the least precision/range of values but occupies the smallest amount of storage and operations on it have traditionally been the fastest, type long double often represents the greatest precision/range of values but occupies the most storage and operations on it are generally the slowest. Applying the Goldilocks principle the type double is very often selected.
Anyone who has worked with floating-point values will be familiar with some of the ways they can bite very hard. Once a function that uses floating-point types is written the general advice is to leave it alone.
Precimonious is an interesting new tool that searches for possible performance/accuracy trade-offs; it randomly selects a floating-point declaration, changes the type used, executes the resulting program and compares the output against that produced by the original program. Users of the tool specify the maximum error (difference in output values) they are willing to accept and Precimonious searches for a combination of changes to the floating-point types contained within a program that result in a faster program that does not exceed this maximum error.
The performance improvements cited in the paper (which includes the doyen of floating-point in its long list of authors) cluster around zero and worthwhile double figure percentage (max 41.7%); sometimes no improvements were found until the maximum error was reduced from  to
to  .
.
Perhaps a combination of Precimonious and a tool that attempts to improve accuracy is the next step 🙂
There is resistance to using search based methods to fix faults. Perhaps tools like Precimonious will help developers get used to the idea of search assisted software development.
I wonder how long it will be before we see commentary in bug reports such as the following:
- that combination of values was not in the Precimonious test set,
- Precimonious cannot find a sufficiently optimized program within the desired error tolerance for that rarely seen combination of values. Won’t fix.
Changes in the API/non-API method call ratio with program size
Amount of code is the fundamental metric of software engineering. How do things change as the amount of code changes and often just as interestingly what does not change with code size?
Most languages include some kind of base library functionality. Languages such as Java and C++ not only include a very large library but also a huge, widely used, collection of third-party libraries.
Let’s count every method call in lots of Java programs and for each program divide these calls into two groups, calls to methods in well-known libraries (call these the API methods) and all other method calls (i.e., calls to methods written by the developers who wrote each of the programs measured; call these the non-API methods).
I would expect the ratio of API to non-API method calls to be independent of program size.
Yes, the number of possible different API calls is fixed while the number of possible non-API calls increases with program size, but I don’t see why a changing ratio of unique calls should change the ratio of total calls.
Yes, larger programs are likely to contain more architectural stuff whose code is more likely to contain calls to non-API methods, but the percentage of architectural code is very small and unlikely to have much impact on the overall numbers.
The authors of the paper: Large-scale, AST-based API-usage analysis of open-source Java projects made their data available and so I got to check out my thinking 🙂
The plot below shows everything going to plan until around 10,000 method calls (about 50,000 lines of code). Why that sudden kink in the line (code and data)?
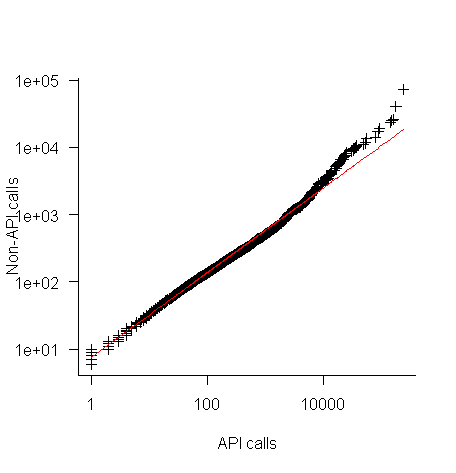
One possibility is that once a program gets to a size of around 50,000 lines the developers decide to invest in one or more wrapper packages which create a purpose built interface to an API (programs often have their own requirements and needs that existing an existing API interface does not quite meet); this would cause API calls to decrease and non-API calls to increase. If this pattern of usage occurred there would be a permanent change in the API/non-API ratio, and in practice the ratio change appears to be temporary.
I’m a bit stumped by this behavior. Suggestions on possible mechanisms welcome.
I wish I had the time to investigate, but I have a book to finish.
A prediction for 2014
When I first started writing this blog I used to make prediction for the coming year. After a couple of years I stopped doing this, the world of computer languages changes very slowly, i.e., I was mostly proved wrong.
I recently realised that Facebook had not yet launched their own general programming language; such an event must be a sure fire prediction for 2014.
Stop trying to argue that the world does not need a new programming language. The reason companies launch their own language is self image (in the way Hollywood superstars launch their own perfumes and fashion lines).
Back in the day IBM launched PL/1, we had Ada from the US DOD, C# and F# from Microsoft, Google has Go and Mozilla has Rust.
Facebook has a software platform and I’m sure they feel something is missing. It must really gall their engineers to hear people from Google, Mozilla and even that old fogy Microsoft talking about ‘their’ language.
New languages are easy to invent, PhD students do it all the time. Implementing them is also cheap, a good engineer can put together a compiler and interpreter in about a year; these days, thanks to LLVM, the cost of building a machine code generator for a new language has dropped significantly (GCC is still intimidating). Libraries, where a large percentage of the work used to go, can be copied from a multitude of places (not a problem if everything is open sourced, which new language implementations tend to be these days).
One end of year tit-bit is that Google now seem to be taking Dart more seriously than just techy swagger.
Converting graphs in pdf files to csv format
Looking at a graph displayed as part of a pdf document is so tantalizing; I want that data as a csv!
One way to get the data is to email the author(s) and ask for it. I do this regularly and sometimes get the apologetic reply that the data is confidential. But I can see the data! Yes, but we only got permission to distribute the paper. I understand their position and would give the same reply myself; when given access to a company’s confidential data, explicit permission is often given about what can and cannot be made public with lists of numbers being on the cannot list.
The Portable Document Format was designed to be device independent, which means it contains a description of what to display rather than a bit-map of pixels (ok, it can contain a bit-map of pixels (e.g., a photograph) but this rather defeats the purpose of using pdf). It ought to be possible to automatically extract the data points from a graph and doing this has been on my list of things to do for a while.
I was mooching around the internals of a pdf last night when I spotted the line: /Producer (R 2.8.1); the authors had used R to generate the graphs and I could look at the R source code to figure out what was going on :-). I suspected that each line of the form: /F1 1 Tf 1 Tr 6.21 0 0 6.21 135.35 423.79 Tm (l) Tj 0 Tr was a description of a circle on the page and the function PDF_Circle in the file src/library/grDevices/src/devPS.c told me what the numbers meant; I was in business!
I also managed to match up other lines in the pdf file to the output produced by the functions PDF_Line and PDFSimpleText; it looked like the circles were followed by the axis tick marks and the label on each tick mark. Could things get any easier?
In suck-it-and-see projects like this it is best to use very familiar tools, this allows cognition to be focused on the task at hand. For me this meant using awk to match lines in pdf files and print out the required information.
Running the pdf through an awk script produced what looked like sensible x/y coordinates for circles on the page, the stop/start end-points of lines and text labels with their x/y coordinates. Now I needed to map the page x/y coordinates to within graph coordinate points.
After the circle coordinates in the output from the script were a series of descriptions of very short lines which looked like axis tick marks to me, especially since they were followed by coordinates of numbers that matched what appeared in the pdf graphs. This information is all that is needed to map from page coordinates to within graph coordinates. The graph I was interested in (figure 6) used logarithmic axis, so things were made a bit complicated by the need to perform a log transform.
Running the output (after some cut and pasting to removed stuff associated with other graphs in the pdf) from the first script through another awk script produced a csv file that could be fed into R’s plot to produce a graph that looked just like the original!
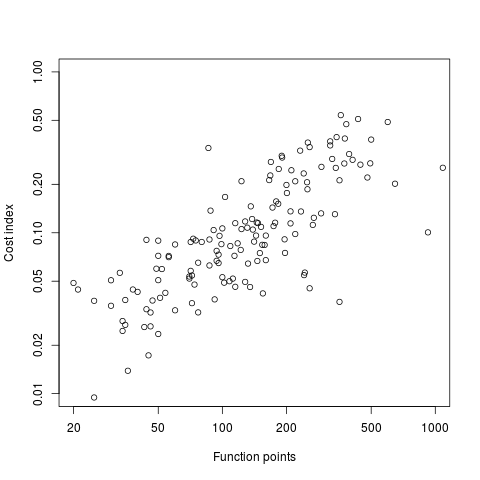
I would say it is possible to extract the data points from any graph, generated using R producing pdf or ps, contained within a pdf file.
The current scripts are very specific to the figure I was interested in, this is more to do with my rough and ready approach to solving the problem which makes assumptions about that is in the data; a more sophisticated version could handle common variations on the theme and with a bit of elbow grease point-and-click might be made to work.
It is probably also possible to extract data points in graphs produced by other tools, ‘all’ that is needed is information on the encoding used.
Extracting data from graphs generated to an image format such as png or jpg are going to need image processing software such as that used to extract data from images of tables.
Variable naming based on lengths of existing variable names
Over the years I have spent a lot of time studying variable names and I sometimes encounter significant disbelief when explaining the more unusual developer variable name selection algorithms.
The following explanation from Rasmus Lerdorf, of PHP fame, provides a useful citable source for a variant on a common theme (i.e., name length).
“… Back when PHP had less than 100 functions and the function hashing mechanism was strlen(). In order to get a nice hash distribution of function names across the various function name lengths names were picked specifically to make them fit into a specific length bucket. This was circa late 1994 when PHP was a tool just for my own personal use and I wasn’t too worried about not being able to remember the few function names.”
Pointers to other admissions of youthful folly welcome.
Recent Comments