Search Results
McCabe’s cyclomatic complexity and accounting fraud
The paper in which McCabe proposed what has become known as McCabe’s cyclomatic complexity did not contain any references to source code measurements, it was a pure ego and bluster paper.
Fast forward 10 years and cyclomatic complexity, complexity metric, McCabe’s complexity…permutations of the three words+metrics… has become one of the two major magical omens of code quality/safety/reliability (Halstead’s is the other).
It’s not hard to show that McCabe’s complexity is a rather weak measure of program complexity (it’s about as useful as counting lines of code).
Just as it is possible to reduce the number of lines of code in a function (by putting all the code on one line), it’s possible to restructure existing code to reduce the value of McCabe’s complexity (which is measured for individual functions).
The value of McCabe’s complexity for the following function is 5 16, i.e., and there are 16 possible paths through the function:
int main(void) { if (W) a(); else b(); if (X) c(); else d(); if (Y) e(); else f(); if (Z) g(); else h(); } |
each if…else contains two paths and there are four in series, giving  paths.
paths.
Restructuring the code, as below, removes the multiplication of paths caused by the sequence of if…else:
void a_b(void) {if (W) a(); else b();} void c_d(void) {if (X) c(); else d();} void e_f(void) {if (Y) e(); else f();} void g_h(void) {if (Z) g(); else h();} int main(void) { a_b(); c_d(); e_f(); g_h(); } |
reducing main‘s McCabe complexity to 1 and the four new functions each have a McCabe complexity of two.
Where has the ‘missing’ complexity gone? It now ‘exists’ in the relationship between the functions, a relationship that is not included in the McCabe complexity calculation.
The number of paths that can be traversed, by a call to main, has not changed (but the McCabe method for counting them now produces a different answer)
Various recommended practice documents suggest McCabe’s complexity as one of the metrics to consider (but don’t suggest any upper limit), while others go as far as to claim that it’s bad practice for functions to have a McCabe’s complexity above some value (e.g., 10) or that “Cyclomatic complexity may be considered a broad measure of soundness and confidence for a program“.
Consultants in the code quality/safety/security business need something to complain about, that is not too hard or expensive for the client to fix.
If a consultant suggested that you reduced the number of lines in a function by joining existing lines, to bring the count under some recommended limit, would you take them seriously?
What about, if a consultant highlighted a function that had an allegedly high McCabe’s complexity? Should what they say be taken seriously, or are they essentially encouraging developers to commit the software equivalent of accounting fraud?
Halstead & McCabe metrics: The wisdom of the ancients
Study after study finds that the predictive power of both the Halstead metric and the McCabe cyclomatic complexity metric is no better than counting lines of code, for the characteristics of interest. Why do people continue to use and cite the Halstead and McCabe metrics?
My experience, talking to people, is that many believe these metrics have greater predictive power than lines of code. Sometimes I explain the situation, other times I move on.
Those who are aware of the facts often continue to use these metrics. Why do they do this?
Given the lack of alternative metrics that are more effective than lines of code, for the claimed uses of Halstead/McCabe, following the herd is the easy option (I regularly point this out to people, after explaining that Halstead/McCabe don’t do what is claimed on the tin). Tools are available to calculate the metrics; the manual effort is clicking buttons or running a command.
Why were the Halstead/McCabe metrics ‘successful’, in that they are the ones people cite/use today?
Both were formulated in the mid-1970s, when the discussion around measuring software started in earnest, so they had some first-mover advantage (within a few years they were both being suggested for use by US Military). Individuals promoted their ideas: Maurice Halstead was a senior professor, with colleagues and lots of graduate students, who advertised the metric via their publications; Thomas McCabe was working for the NSA when his famous paper was published, and went on to form a company working in the area of source code analysis.
The Halstead/McCabe metrics can both be calculated by processing the source one line at a time (just count decision points for McCabe, no need for the pretentious graph theory stuff). In the 1970s, computer memory was often measured in kilobytes, which made it difficult to implement complicated metrics that required keeping dependency information in memory.
Metrics based on the subroutine/function/procedure/method as the measured unit of source code had an implementation and usage advantage over metrics based on larger units of code.
In the 1990s, object-oriented programming, in the form of C++ and then Java, took off. The common view, by those caught up in the times, was that object-oriented software was so different from what went before that it needed its own metrics.
The 1991 paper: Towards a Metrics Suite for Object Oriented Design, by Chidamber and Kemerer, introduced the six CK metrics (as they become known; 1992 update). The nearest this paper comes to citing the Halstead/McCabe work is to say: “Some early work has recognized the shortcomings of existing metrics and the need for new metrics especially designed for OO.” The paper followed in the footsteps of the earlier work in not providing any evidence for the claims made (the update contains histograms of metric values from a C++ project and a Smalltalk project).
The 1996 paper: Evaluating the Impact of Object-Oriented Design on Software Quality, by Abreu and Melo, introduced the MOOD metrics (Metrics for Object-Oriented Design).
At the end of 2022 the total citation counts returned by Google Scholar were: McCabe 8,670, Halstead 4,900, CK 8,160, and MOOD 354.
The plot below shows the number of new citations returned by Google Scholar, each year, for the respective metrics papers (or book for Halstead; code+data):
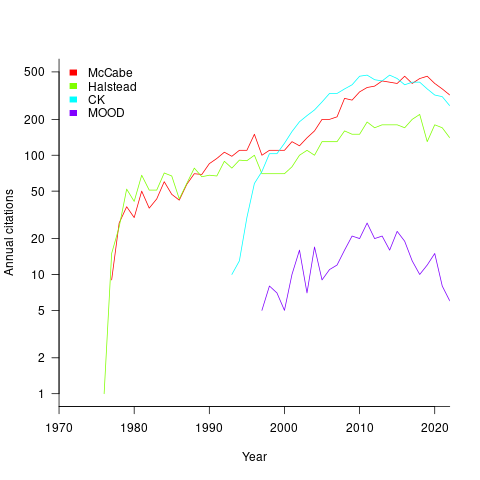
The ongoing growth in annual rate of citation probably has more to do with the growth in the number of software papers published each year, rather than these metric papers being cited by an expanding number of research fields.
Do authors tend to cite one or the other of Halstead/McCabe, or both?
Using Google Scholar’s ‘search within’ option to find the subset of papers that included a string matching the title of a paper: 46% of the Halstead citations include a citation of the McCabe paper, and 25% of the McCabe citations include a citation of the Halstead paper.
The Inciteful’s paper network (with citation counts: Halstead 1,052 and McCabe 4,970) found 657 papers citing both (62% of the Halstead total, 12% of the McCabe).
It’s not possible to make use of the OpenCitations API because it is DOI based, and the Halstead citation is a book.
Who are the famous academics in software engineering?
Who are today’s ‘famous’ academics in software engineering?
Famous as in, you can mention their name when chatting with general software developers, and expect those present to have heard of them, or you have heard their names dropped into a conversation, say, at least 3+ times this year (I’m excluding academics who are famous within one specific niche of software engineering). Academic, as in, works in an institution of secondary or tertiary higher learning.
When I started out in industry, the works of Knuth and Dijkstra were cited (not always accurately), people would talk about Ted Codd’s latest position on how best to structure a database. Tony Hoare later became known through his books, and Leslie Lamport for distributed systems and perhaps LaTeX. In very large niches, William Kahan for numerical analysis, and Barbara Liskov for the Liskov substitution principle.
Anyone suggesting Kernighan and Ritchie, of C and Unix fame, is overlooking the fact they worked in an industrial research lab.
A book series continues to maintain Knuth’s fame, while Dijkstra kept himself in the news by being a source of controversial quotes for industry journalists, and for kicking off the Go-To statement considered harmful debate (the latter is likely the reason that anybody has heard of him today). Has Kahan escaped his niche, even though use of floating-point arithmetic is now perhaps even more niche than it used to be?
How might academics become famous?
Widely used algorithms/metrics/techniques named after a person generates a kind of anonymous name recognition. For instance, Halstead complexity metric and McCabe’s cyclomatic complexity metric, and from the 1990s Shor’s algorithm.
Some people achieve fame through their association with a language. Academic name/language pairs include: McCarthy/Lisp, Wirth/Pascal, Stroustrup/C++ (worked in industry, university, industry, university), Peyton Jones/Haskell (university, industrial research, industry), Leroy/OCaml, Meyer/Eiffel.
An influential book, or widely read blog can generate a kind of fame.
Many academics have written an ‘algorithms’ book, and readers may have fond memories of the particular book they used as an undergraduate. Barry Boehm wrote “Software Engineering Economics”, but is more likely to be known for the model he spent his life promoting, i.e., the COCOMO model.
Fred Brooks, author of one of the most famous books in software engineering The Mythical Man Month, was not an academic worked in industry and then academia.
I have always been surprised by how many Turing award winners I have never heard of, or while recognizing a name am completely unfamiliar with their work. I am less surprised by my failure to recognise around half the names in the Wikipedia category software engineering researchers.
A few people are known because of the widespread use of their software (Linus Torvalds has never been an academic). Richard Stallman, employed as an academic, originally became famous as the author of the GNU version of emacs and gcc; the fame from the Free Software Foundation came after copyleft took off.
Are there academics who have become ‘famous’ in software engineering this century? I’m not in a position to answer this because I don’t read introductory software books, and generally avoid bike-shed discussions.
Does the resurgence of interest in AI mean that Judea Pearl’s fame is no longer niche?
I do read recent academic papers, and the only person on the list of most frequently cited authors in my evidence-based software engineering book with any claim to fame, researches cognitive neuroscience, i.e., Stanislas Dehaene.
Is software engineering a field where it is possible for a person, academic or otherwise, to become famous?
If there are fame worthy discoveries waiting to be made, or fame worthy software engineering book waiting to be written, how likely is it that the people responsible will be academics? A lot of the advances in software engineering have been made and continue to be made by those working in industry.
Suggestions relating to (in)famous academics welcome.
Complex software makes economic sense
Economic incentives motivate complexity as the common case for software systems.
When building or maintaining existing software, often the quickest/cheapest approach is to focus on the features/functionality being added, ignoring the existing code as much as possible. Yes, the new code may have some impact on the behavior of the existing code, and as new features/functionality are added it becomes harder and harder to predict the impact of the new code on the behavior of the existing code; in particular, is the existing behavior unchanged.
Software is said to have an attribute known as complexity; what is complexity? Many definitions have been proposed, and it’s not unusual for people to use multiple definitions in a discussion. The widely used measures of software complexity all involve counting various attributes of the source code contained within individual functions/methods (e.g., McCabe cyclomatic complexity, and Halstead); they are all highly correlated with lines of code. For the purpose of this post, the technical details of a definition are glossed over.
Complexity is often given as the reason that software is difficult to understand; difficult in the sense that lots of effort is required to figure out what is going on. Other causes of complexity, such as the domain problem being solved, or the design of the system, usually go unmentioned.
The fact that complexity, as a cause of requiring more effort to understand, has economic benefits is rarely mentioned, e.g., the effort needed to actively use a codebase is a barrier to entry which allows those already familiar with the code to charge higher prices or increases the demand for training courses.
One technique for reducing the complexity of a system is to redesign/rework its implementation, from a system/major component perspective; known as refactoring in the software world.
What benefit is expected to be obtained by investing in refactoring? The expected benefit of investing in redesign/rework is that a reduction in the complexity of a system will reduce the subsequent costs incurred, when adding new features/functionality.
What conditions need to be met to make it worthwhile making an investment,  , to reduce the complexity,
, to reduce the complexity,  , of a software system?
, of a software system?
Let’s assume that complexity increases the cost of adding a feature by some multiple (greater than one). The total cost of adding  features is:
features is:

where:  is the system complexity when feature
is the system complexity when feature  is added, and
is added, and  is the cost of adding this feature if no complexity is present.
is the cost of adding this feature if no complexity is present.
 ,
,  , …
, … 
where:  is the base complexity before adding any new features.
is the base complexity before adding any new features.
Let’s assume that an investment, , is made to reduce the complexity from  (with
(with  ) to
) to  , where
, where  is the reduction in the complexity achieved. The minimum condition for this investment to be worthwhile is that:
is the reduction in the complexity achieved. The minimum condition for this investment to be worthwhile is that:
 or
or 
where:  is the total cost of adding new features to the source code after the investment, and
is the total cost of adding new features to the source code after the investment, and  is the total cost of adding the same new features to the source code as it existed immediately prior to the investment.
is the total cost of adding the same new features to the source code as it existed immediately prior to the investment.
Resetting the feature count back to  , we have:
, we have:
*F_1+(C_B+C_N+C_2)*F_2+...+(C_B+C_N+C_m)*F_m")
and
*F_1+(C_B+C_N-C_R+C_2)*F_2+...+(C_B+C_N-C_R+C_m)*F_m")
and the above condition becomes:
-(C_B+C_N-C_R+C_1))*F_1+...+((C_B+C_N+C_m)-(C_B+C_N-C_R+C_m))*F_m")


The decision on whether to invest in refactoring boils down to estimating the reduction in complexity likely to be achieved (as measured by effort), and the expected cost of future additions to the system.
Software systems eventually stop being used. If it looks like the software will continue to be used for years to come (software that is actively used will have users who want new features), it may be cost-effective to refactor the code to returning it to a less complex state; rinse and repeat for as long as it appears cost-effective.
Investing in software that is unlikely to be modified again is a waste of money (unless the code is intended to be admired in a book or course notes).
Foundations for Evidence-Based Policymaking Act of 2017
The Foundations for Evidence-Based Policymaking Act of 2017 was enacted by the US Congress on 21st December.
A variety of US Federal agencies are responsible for ensuring the safety of US citizens, in some cases this safety is dependent on the behavior of software. The FDA is responsible for medical device safety and the FAA publishes various software safety handbooks relating to aviation (the Department of transportation has a wider remit).
Where do people go to learn about the evidence for software related issues?
The book: Evidence-based software engineering: based on the publicly available evidence sounds like a good place to start.
Quickly skimming this (currently draft) book shows that no public evidence is available on lots of issues. Oops.
Another issue is the evidence pointing to some suggested practices being at best useless and sometimes fraudulent, e.g., McCabe’s cyclomatic complexity metric.
The initial impact of evidence-based policymaking will be companies pushing back against pointless government requirements, in particular requirements that cost money to implement. In some cases this is a good, e.g., no more charades about software being more testable because its code has a low McCable complexity.
In the slightly longer term, people are going to have to get serious about collecting and analyzing software related evidence.
The Open, Public, Electronic, and Necessary Government Data Act or the OPEN Government Data Act (which is about to become law) will be a big help in obtaining evidence. I think there is a lot of software related data sitting on disks and tapes, waiting to be analysed (NASA appears to have loads to data that they have down almost nothing with, including not making it publicly available).
Interesting times ahead.
Machine learning in SE research is a bigger train wreck than I imagined
I am at the CREST Workshop on Predictive Modelling for Software Engineering this week.
Magne Jørgensen, who virtually single handed continues to move software cost estimation research forward, kicked-off proceedings. Unfortunately he is not a natural speaker and I think most people did not follow the points he was trying to get over; don’t panic, read his papers.
In the afternoon I learned that use of machine learning in software engineering research is a bigger train wreck that I had realised.
Machine learning is great for situations where you have data from an application domain that you don’t know anything about. Lets say you want to do fault prediction but don’t have any practical experience of software engineering (because you are an academic who does not write much code), what do you do? Well you could take some source code measurements (usually on a per-file basis, which is a joke given that many of the metrics often used only have meaning on a per-function basis, e.g., Halstead and cyclomatic complexity) and information on the number of faults reported in each of these files and throw it all into a machine learner to figure the patterns and build a predictor (e.g., to predict which files are most likely to contain faults).
There are various ways of measuring the accuracy of the predictions made by a model and there is a growing industry of researchers devoted to publishing papers showing that their model does a better job at prediction than anything else that has been published (yes, they really do argue over a percent or two; use of confidence bounds is too technical for them and would kill their goose).
I long ago learned to ignore papers on machine learning in software engineering. Yes, sooner or later somebody will do something interesting and I will miss it, but will have retained my sanity.
Today I learned that many researchers have been using machine learning “out of the box”, that is using whatever default settings the code uses by default. How did I learn this? Well, one of the speakers talked about using R’s carat package to tune the options available in many machine learners to build models with improved predictive performance. Some slides showed that the performance of carat tuned models were often substantially better than the non-carat tuned model and many people in the room were aghast; “If true, this means that all existing papers [based on machine learning] are dead” (because somebody will now come along and build a better model using carat; cannot recall whether “dead” or some other term was used, but you get the idea), “I use the defaults because of concerns about breaking the code by using inappropriate options” (obviously somebody untroubled by knowledge of how machine learning works).
I think that use of machine learning, for the purpose of prediction (using it to build models to improve understanding is ok), in software engineering research should be banned. Of course there are too many clueless researchers who need the crutch of machine learning to generate results that can be included in papers that stand some chance of being published.
Clustering source code within functions
The question of how best to cluster source code into functions is a perennial debate that has been ongoing since functions were first created.
Beginner programmers are told that clustering code into functions is good, for a variety of reasons (none of the claims are backed up by experimental evidence). Structuring code based on clustering the implementation of a single feature is a common recommendation; this rationale can be applied at both the function/method and file/class level.
The idea of an optimal function length (measured in statements) continues to appeal to developers/researchers, but lacks supporting evidence (despite a cottage industry of research papers). The observation that most reported fault appear in short functions is a consequence of most of a program’s code appearing in short functions.
I have had to deal with code that has not been clustered into functions. When microcomputers took off, some businessmen taught themselves to code, wrote software for their line of work and started selling it. If the software was a success, more functionality was needed, and the businessman (never encountered a woman doing this) struggled to keep on top of things. A common theme was a few thousand lines of unstructured code in one function in a single file (keeping everything in one file is also a trait of highly focus developers).
Adding structural bureaucracy (e.g., functions and multiple files) reduced the effort needed to maintain and enhance the code.
The problem with ‘born flat’ source is that the code for unrelated functionality is often intermixed, and global variables are freely used to communicate state. I have seen the same problems in structured function code, but instances are nowhere near as pervasive.
When implementing the same program, do different developers create functions implementing essentially the same functionality?
I am aware of two datasets relating to this question: 1) when implementing the same small specification (average length program 46.3 lines), a surprising number of variants (6,301) are created, 2) an experiment that asked developers to reintroduce functions into ‘flattened’ code.
The experiment (Alexey Braver’s MSc thesis) took an existing Python program, ‘flattened’ it by inlining functions (parameters were replaced by the corresponding call arguments), and asked subjects to “… partition it into functions in order to achieve what you consider to be a good design.”
The 23 rows in the plot below show the start/end (green/brown delimited by blue lines) of each function created by the 23 subjects; red shows code not within a function, and right axis is percentage of each subjects’ code contained in functions. Blue line shows original (currently plotted incorrectly; patched original code+data):
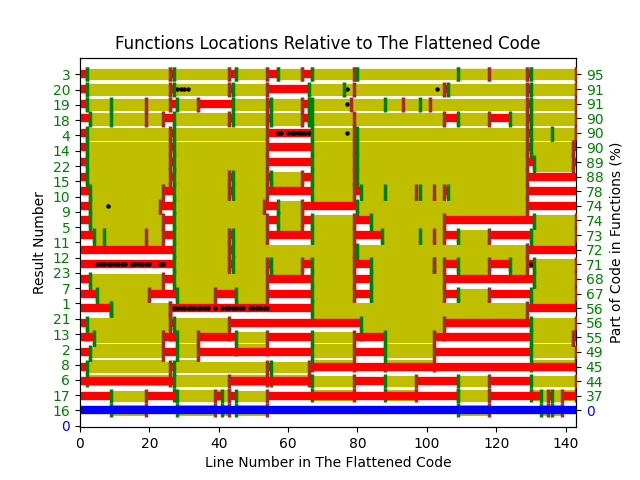
There are many possible reasons for the high level of agreement between subjects, including: 1) the particular example chosen, 2) the code was already well-structured, 3) subjects were explicitly asked to create functions, 4) the iterative process of discovering code that needs to be written did not occur, 5) no incentive to leave existing working code as-is.
Given that most source has a short and lonely existence, is too much time being spent bike-shedding function contents?
Given how often lower level design time happens at code implementation time, perhaps discussion of function contents ought to be viewed as more about thinking how things fit together and interact, than about each function in isolation.
Analyzing each function in isolation can create perverse incentives.
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
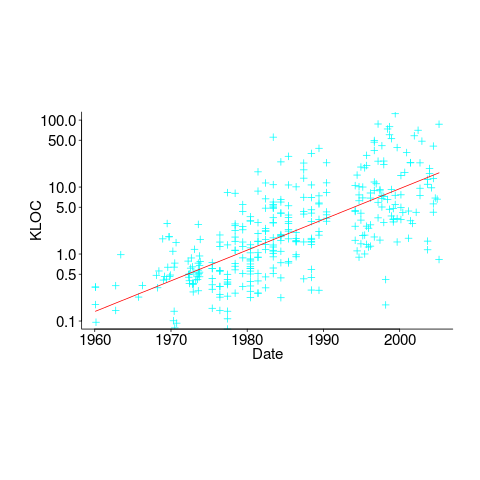
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
The wisdom of the ancients
The software engineering ancients are people like Halstead and McCabe, along with less well known ancients (because they don’t name anything after them) such as Boehm for cost estimation, Lehman for software evolution, and Brooks because of a book; these ancients date from before 1980.
Why is the wisdom of these ancients still venerated (i.e., people treat them as being true), despite the evidence that they are very inaccurate (apart from Brooks)?
People hate a belief vacuum, they want to believe things.
The correlation between Halstead’s and McCabe’s metrics, and various software characteristics is no better than counting lines of code, but using a fancy formula feels more sophisticated and everybody else uses them, and we don’t have anything more accurate.
That last point is the killer, in many (most?) cases we don’t have any metrics that perform better than counting lines of code (other than taking the log of the number of lines of code).
Something similar happened in astronomy. Placing the Earth at the center of the solar system results in inaccurate predictions of where the planets are going to be in the sky; adding epicycles to the model helps to reduce the error. Until Newton came along with a model that produced very accurate results, people stuck with what they knew.
The continued visibility of COCOMO is a good example of how academic advertising (i.e., publishing papers) can keep an idea alive. Despite being more sophisticated, the Putnam model is not nearly as well known; Putnam formed a consulting company to promote this model, and so advertised to a different market.
Both COCOMO and Putnam have lines of code as an integral component of their models, and there is huge variability in the number of lines written by different people to implement the same functionality.
People tend not to talk about Lehman’s quantitative work on software evolution (tiny data set, and the fitted equation is very different from what is seen today). However, Lehman stated enough laws, and changed them often enough, that it’s possible to find something in there that relates to today’s view of software evolution.
Brooks’ book “The Mythical Man-Month” deals with project progress and manpower; what he says is timeless. The problem is that while lots of people seem happy to cite him, very few people seem to have read the book (which is a shame).
There is a book coming out this year that provides lots of evidence that the ancient wisdom is wrong or at best harmless, but it does not contain more accurate models to replace what currently exists 🙁
The dark-age of software engineering research: some evidence
Looking back, the 1970s appear to be a golden age of software engineering research, with the following decades being the dark ages (i.e., vanity research promoted by ego and bluster), from which we are slowly emerging (a rough timeline).
Lots of evidence-based software engineering research was done in the 1970s, relative to the number of papers published, and I have previously written about the quantity of research done at Rome and the rise of ego and bluster after its fall (Air Force officers studying for a Master’s degree publish as much software engineering data as software engineering academics combined during the 1970s and the next two decades).
What is the evidence for a software engineering research dark ages, starting in the 1980s?
One indicator is the extent to which ancient books are still venerated, and the wisdom of the ancients is still regularly cited.
I claim that my evidence-based software engineering book contains all the useful publicly available software engineering data. The plot below shows the number of papers cited (green) and data available (red), per year; with fitted exponential regression models, and a piecewise regression fit to the data (blue) (code+data).
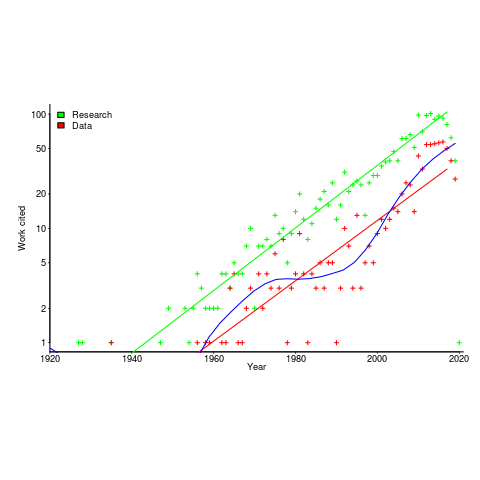
The citations+date include works that are not written by people involved in software engineering research, e.g., psychology, economics and ecology. For the time being I’m assuming that these non-software engineering researchers contribute a fixed percentage per year (the BibTeX file is available if anybody wants to do the break-down)
The two straight line fits are roughly parallel, and show an exponential growth over the years.
The piecewise regression (blue, loess was used) shows that the rate of growth in research data leveled-off in the late 1970s and only started to pick up again in the 1990s.
The dip in counts during the last few years is likely to be the result of me not having yet located all the recent empirical research.
Recent Comments