Archive
Optimal sizing of a product backlog
Developers working on the implementation of a software system will have a list of work that needs to be done, a to-do list, known as the product backlog in Agile.
The Agile development process differs from the Waterfall process in that the list of work items is intentionally incomplete when coding starts (discovery of new work items is an integral part of the Agile process). In a Waterfall process, it is intended that all work items are known before coding starts (as work progresses, new items are invariably discovered).
Complaints are sometimes expressed about the size of a team’s backlog, measured in number of items waiting to be implemented. Are these complaints just grumblings about the amount of work outstanding, or is there an economic cost that increases with the size of the backlog?
If the number of items in the backlog is too low, developers may be left twiddling their expensive thumbs because they have run out of work items to implement.
A parallel is sometimes drawn between items waiting to be implemented in a product backlog and hardware items in a manufacturer’s store waiting to be checked-out for the production line. Hardware occupies space on a shelf, a cost in that the manufacturer has to pay for the building to hold it; another cost is the interest on the money spent to purchase the items sitting in the store.
For over 100 years, people have been analyzing the problem of the optimum number of stock items to order, and at what stock level to place an order. The economic order quantity gives the optimum number of items to reorder,  (the derivation assumes that the average quantity in stock is
(the derivation assumes that the average quantity in stock is  ), it is given by:
), it is given by:
 , where
, where  is the quantity consumed per year,
is the quantity consumed per year,  is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),
is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),  is the annual holding cost per item.
is the annual holding cost per item.
What is the likely range of these values for software?
- is around 1,000 per year for a team of ten’ish people working on multiple (related) projects; based on one dataset,
- is the cost associated with the time taken to gather the requirements, i.e., the items to add to the backlog. If we assume that the time taken to gather an item is less than the time taken to implement it (the estimated time taken to implement varies from hours to days), then the average should be less than an hour or two,
- : While the cost of a post-it note on a board, or an entry in an online issue tracking system, is effectively zero, there is the time cost of deciding which backlog items should be implemented next, or added to the next Sprint.
If the backlog starts with
 items, and it takes
items, and it takes  seconds to decide whether a given item should be implemented next, and
seconds to decide whether a given item should be implemented next, and  is the fraction of items scanned before one is selected: the average decision time per item is:
is the fraction of items scanned before one is selected: the average decision time per item is: /2}*t") seconds. For example, if
seconds. For example, if  , pulling some numbers out of the air,
, pulling some numbers out of the air,  , and
, and  , then
, then  , or 5.4 minutes.
, or 5.4 minutes.The Scrum approach of selecting a subset of backlog items to completely implement in a Sprint has a much lower overhead than the one-at-a-time approach.
If we assume that  , then
, then  .
.
An ‘order’ for 45 work items might make sense when dealing with clients who have formal processes in place and are not able to be as proactive as an Agile developer might like, e.g., meetings have to be scheduled in advance, with minutes circulated for agreement.
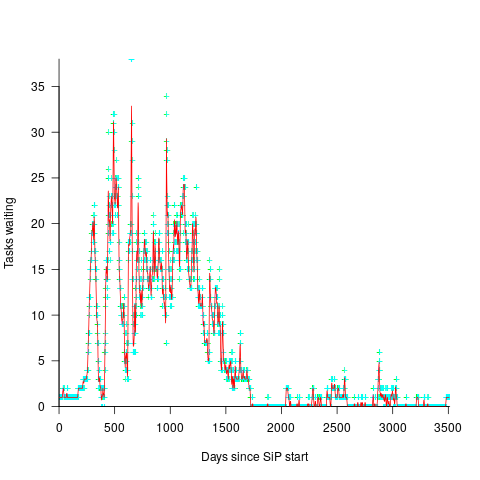
In a more informal environment, with close client contacts, work items are more likely to trickle in or appear in small batches. The SiP dataset came from such an environment. The plot below shows the number of tasks in the backlog of the SiP dataset, for each day (blue/green) and seven-day rolling average (red) (code+data):
Multi-state survival modeling of a Jira issues snapshot
Work items in a formal development process progress through a series of stages, e.g., starting at Open, perhaps moving to Withdrawn or Merged with another item, eventually reaching Development, and finishing at Done (with a few being Reopened, i.e., moving back to the start of the process).
This process can be modelled as a Markov chain, provided data on each stage of the process is available, for each work item; allowing values such as average time spent in each state and transition probabilities to be calculated.
The Jira issue/task/bug/etc tracking system has an option to generate a snapshot of the current status of work items in the system. The snapshot information on each item includes: start-date, current-state, time-in-state, date-of-snapshot.
If we assume that all work items pass through the same sequence of states, from Open to Done, then the snapshot contains enough information to build a multi-state survival model.
The key information is time-in-state, which can be used to calculate the date/time when an item transitioned from its previous state to its current state, providing a required link between all states.
How is a multi-state survival model better than creating a distinct survival model for each state?
The calculation of each state in a multi-state model takes into account information from the succeeding state, i.e., the time-in-state value in the succeeding state provides timing (from the Start state) on when a work item transitioned from its previous state. While this information could be added to each of the distinct models, it’s simpler to bundle everything together in one model.
A data analysis article by Robert Krasinski linked to the data used 🙂 The data does not include a description of the columns, but most of the names appear self-explanatory (I have no idea what key might be). Each of the 3,761 rows includes a story-point estimate, team-id, and a tag name for the work item.
Building a multi-state model provides a means for estimating the impact of team-id and story-points on time-in-state. I would expect items with higher story-point estimates to spend longer in Development, but I’m not sure how much difference there will be on other states.
I pruned the 22 states present in the data down to the following sequence of 13. Items might be Withdrawn or Merged with others items at any time, but I’m keeping things simple. These two states should also be absorbing in that there is no exit from them, I faked this by adding a transition to Done.
Open
Withdrawn
Merged
Backlog
In Analysis
In Refinement
Ready for Development
In Development
Code Review
Ready for Test
In Testing
Ready for Signoff
Done |
I’m familiar with building survival models, but have only ever built a couple of multi-state survival models. R supports several packages, which is the best one to use for this minimalist multi-state dataset?
The msm package is very much into state transition probabilities, or at least that is the impression I got from reading its manual. flexsurv and mstate are other packages I looked at. I decided to stay with the survival package, the default for simpler problems; the manuals contained lots of examples and some of them appeared similar to my problem.
Each row of work item information in the Jira snapshot looks something like the following:
X daysInStatus start status obsdate 1 0.53 2020-05-12 In Development 2020-05-18 |
This work item transitioned from state Ready for Development at time  to state In Development at time
to state In Development at time  , and was still in state In Development at time
, and was still in state In Development at time  (when the snapshot was taken); the
(when the snapshot was taken); the  is a small interval used to separate the states.
is a small interval used to separate the states.
As is often the case with R packages, most of the work went into figuring out how to call the library functions with the data formatted just so, plus of course my own misunderstandings. Once the data was cleaned and process, the analysis was one line of code plus one to print the results; for instance, to estimate the mean time in each state by story-point value (code+data):
sp_fit=survfit(Surv(tstop-tstart, state) ~ sp, data=merged_status) print(sp_fit) |
Given the uncertainties in this model building process, I’m not going to discuss the results. This post is a proof of concept, which others can apply when the sequence of states is known with some degree of confidence, and good reasons for noise in the data are available.
Parkinson’s law, striving to meet a deadline, or happenstance?
How many minutes past the hour was it, when you stopped working on some software related task?
There are sixty minutes in an hour, so if stop times are random, the probability of finishing at any given minute is 1-in-60. If practice (based on the 200k+ time records in the CESAW dataset) the probability of stopping on the hour is 1-in-40, and for stopping on the half-hour is 1-in-48.
Why are developers more likely to stop working on a task, on the hour or half-hour?
Is this a case of Parkinson’s law, or are developers striving to complete a task within a specified time, or are they stopping because a scheduled activity takes priority?
The plot below shows the number of times (y-axis) work on a task stopped on a given minute past the hour (x-axis), for 16 different software projects (project number in blue, with top 10 numbers in red, code+data):

Some projects have peaks at 50, 55, or thereabouts. Perhaps people are stopping because they have a meeting to attend, and a peak is visible because the project had lots of meetings, or no peak was visible because the project had few meetings. Some projects have a peak at 28 or 29, which might be some kind of time synchronization issue.
Is it possible to analyze the distribution of end minutes to reasonably infer developer project behavior, e.g., Parkinson’s law, striving to finish by a given time, or just not watching the clock?
An expected distribution pattern for both Parkinson’s law, and striving to complete, is a sharp decline of work stops after a reference time, e.g., end of an hour (this pattern is present in around ten of the projects plotted). A sharp increase in work stops prior to a reference time could also apply for both behaviors; stopping to switch to other work adds ‘noise’ to the distribution.
The CESAW data is organized by project, not developer, i.e., it does not list everything a developer did during the day. It is possible that end-of-hour work stops are driven by the need to synchronize with non-project activities, i.e., no Parkinson’s law or striving to complete.
In practice, some developers may sometimes follow Parkinson’s law, other times strive to complete, and other times not watch the clock. If models capable of separating out the behaviors were available, they might only be viable at the individual level.
Stop time equals start time plus work duration. If people choose a round number for the amount of work time, there is likely to be some correlation between start/end minutes past the hour. The plot below shows heat maps for start fraction of hour (y-axis) against end fraction of hour (x-axis) for four projects (code+data):
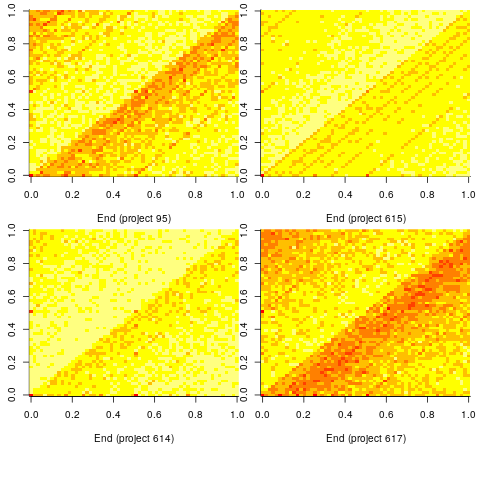
Work durations that are exact multiples of an hour appear along the main diagonal, with zero/zero being the most common start/end pair (at 4% over all projects, with 0.02% expected for random start/end times). Other diagonal lines come from work durations that include a fraction of an hour, e.g., 30-minutes and 20-minutes.
For most work periods, the start minute occurs before the end minute, i.e., the work period does not cross an hour boundary.
What can be learned from this analysis?
The main takeaway is that there is a small bias for work start/end times to occur on the hour or half-hour, and other activities (e.g., meetings) cause ongoing work to be interrupted. Not exactly news.
More interesting ideas and suggestions welcome.
My book’s pdf generation workflow
The process used to generate the pdf of my evidence-based software engineering book has been on my list of things to blog about, for ever. An email arrived this afternoon, asking how I produced various effects using Asciidoc; this post probably contains rather more than N. Psaris wanted to know.
It’s very easy to get sucked into fiddling around with page layout and different effects. So, unless I am about to make a release of a draft, I only generate a pdf once, at the end of each month.
At the end of the month the text is spell checked using aspell, and then grammar checked using Language tool. I have an awk script that checks the text for mistakes I have made in the past; this rarely matches, i.e., I seem to be forever making different mistakes.
The sequencing of tools is: R (Sweave) -> Asciidoc -> docbook -> LaTeX -> pdf; assorted scripts fiddle with the text between outputs and inputs. The scripts and files mention below are available for download.
R generates pdf files (via calls to the Sweave function, I have never gotten around to investigating Knitr; the pdfs are cropped using scripts/pdfcrop.sh) and the ascii package is used to produce a few tables with Asciidoc markup.
Asciidoc is the markup language used for writing the text. A few years after I started writing the book, Stuart Rackham, the creator of Asciidoc, decided to move on from working and supporting it. Unfortunately nobody stepped forward to take over the project; not a problem, Asciidoc just works (somebody did step forward to reimplement the functionality in Ruby; Asciidoctor has an active community, but there is no incentive for me to change). In my case, the output from Asciidoc is xml (it supports a variety of formats).
Docbook appears in the sequence because Asciidoc uses it to produce LaTeX. Docbook takes xml as input, and generates LaTeX as output. Back in the day, Docbook was hailed as the solution to all our publishing needs, and wonderful tools were going to be created to enable people to produce great looking documents.
LaTeX is the obvious tool for anybody wanting to produce lovely looking books and articles; tex/ESEUR.tex is the top-level LaTeX, which includes the generated text. Yes, LaTeX is a markup language, and I could have written the text using it. As a language I find LaTeX too low level. My requirements are not complicated, and I find it easier to write using a markup language like Asciidoc.
The input to Asciidoc and LuaTeX (used to generate pdf from LaTeX) is preprocessed by scripts (written using sed and awk; see scripts/mkpdf). These scripts implement functionality that Asciidoc does not support (or at least I could see how to do it without modifying the Python source). Scripts are a simple way of providing the extra functionality, that does not require me to remember details about the internals of Asciidoc. If Asciidoc was being actively maintained, I would probably have worked to get some of the functionality integrated into a future release.
There are a few techniques for keeping text processing scripts simple. For instance, the cost of a pass over text is tiny, there is little to be gained by trying to do everything in one pass; handling the possibility that markup spans multiple lines can be complicated, a simple solution is to join consecutive lines together if there is a possibility that markup spans these lines (i.e., the actual matching and conversion no longer has to worry about line breaks).
Many simple features are implemented by a script modifying Asciidoc text to include some ‘magic’ sequence of characters, which is subsequently matched and converted in the generated LaTeX, e.g., special characters, and hyperlinks in the pdf.
A more complicated example handles my desire to specify that a figure appear in the margin; the LaTeX sidenotes package supports figures in margins, but Asciidoc has no way of specifying this behavior. The solution was to add the word “Margin”, to the appropriate figure caption option (in the original Asciidoc text, e.g., [caption="Margin ", label=CSD-95-887]), and have a script modify the LaTeX generated by docbook so that figures containing “Margin” in the caption invoked the appropriate macro from the sidenotes package.
There are still formatting issues waiting to be solved. For instance, some tables are narrow enough to fit in the margin, but I have not found a way of embedding this information in the table information that survives through to the generated LaTeX.
My long time pet hate is the formatting used by R’s plot function for exponentiated values as axis labels. My target audience are likely to be casual users of R, so I am sticking with basic plotting (i.e., no calls to ggplot). I do wish the core R team would integrate the code from the magicaxis package, to bring the printing of axis values into the era of laser printers and bit-mapped displays.
Ideas and suggestions welcome.
Recent Comments