Archive
Extracting the original data from a heatmap image
The paper Analysis of the Linux Kernel Evolution Using Code Clone Coverage analysed 136 versions of Linux (from 1.0 to 2.6.18.3) and calculated the amount of source code that was shared, going forward, between each pair of these versions. When I saw the heatmap at the end of the paper (see below) I knew it had to appear in my book. The paper was published in 2007 and I knew from experience that the probability of seven year old data still being available was small, but looked so interesting I had to try. I emailed the authors (Simone Livieri, Yoshiki Higo, Makoto Matsushita and Katsuro Inoue) and received a reply from Makoto Matsushita saying that he had searched for the data and had been able to find the original images created for the paper, which he kindly sent me.
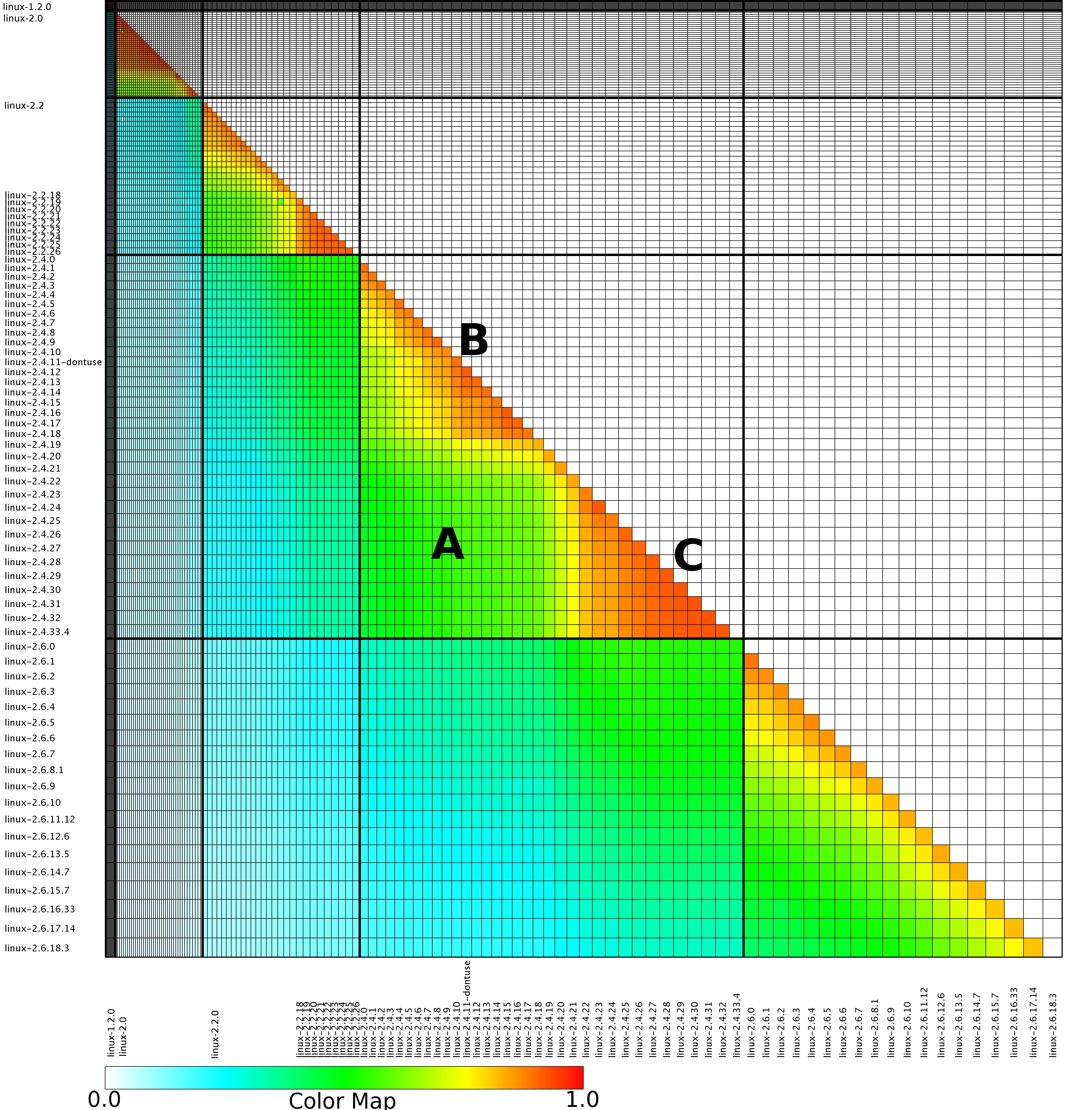
I was confident that I could reverse engineer the original values from the png image and that is what I have just done (I have previously reverse engineered the points in a pdf plot by interpreting the pdf commands to figure out relative page locations).
The idea I had was to find the x/y coordinates of the edge of the staircase running from top left to bottom right. Those black lines appear to complicate things, but the RGB representation of black follows the same pattern as white, i.e., all three components are equal (0 for black and 1 for white). All I had to do was locate the first pixel containing an RGB value whose three components had at least one different value, which proved to be remarkably easy to do using R’s vector operations.
After reducing duplicate sequences to a single item I now had the x/y coordinates of the colored rectangle for each version pair; extracting an RGB value for each pair of Linux releases was one R statement. Now I needed to map RGB values to the zero to one scale denoting the amount of shared Linux source. The color scale under the heatmap contains the information needed and with some trial and error I isolated a vector of RGB pixels from this scale. Passing the offset of each RGB value on this scale to mapvalues (in the plyr package) converted the extracted RGB values.
The extracted array has 130 rows/columns, which means information on 5 versions has been lost (no history is given for the last version). At the moment I am not too bothered, most of the data has been extracted.
Here is the result of calling the R function readPNG (from the png package) to read the original file, mapping the created array of RGB values to amount of Linux source in each version pair and calling the function image to display this array (I have gone for maximum color impact; the code has no for loops):
The original varied the width of the staircase, perhaps by some measure of the amount of source code. I have not done that.
Its suspicious that the letter A is not visible in some form. Its embedded in the original data and I would have expected a couple of hits on that black outline.
The above overview has not bored the reader with my stupidities that occurred along the way.
If you improve the code to handle other heatmap data extraction problems, please share the code.
XSLT, yacc and Yorick
X and Y are for XSLT, yacc and Yorick.
XSLT is the tree climbing Kangaroo of the programming language world. Eating your own dog food is good practice for implementors, but users should not be forced to endure it. Anyway, people only use XML, rather than JSON, to increase the size of their files so they can claim to be working with big data.
yacc grammars don’t qualify as programming languages because they are not Turing complete (because yacc requires its input to be a deterministic context-free grammar, a subset of context-free grammars, that can be implemented using a deterministic pushdown automaton; restructering a context-free grammar into a deterministic context-free grammar is the part of using yacc that mangles the mind the most). While Bison supports GLR parsing, this only extends its input to all context-free grammars; the same notation is used to specify grammars and this does not support the specification of languages such as:  , where
, where  and
and  denotes
denotes  repeated
repeated  times, which requires a context-free grammar. So the yacc grammar notation is not capable of expressing all computations.
times, which requires a context-free grammar. So the yacc grammar notation is not capable of expressing all computations.
Yorick is designed for processing large amounts of scientific data and is a lot like R, with slightly different syntax. Use of Yorick seems to have died out in the last few years. What happened, did its users discover R? I would certainly recommend a switch to R, but I would also suggest Yorick as a subject of study for the maintainers of R; there are language ideas to be mulled over, e.g., global("blah") to declare blah as being a global variable within the function containing the call.
Things to read
The Theory of Parsing, Translation, and Compiling, Vol. 1, Parsing by Alfred V. Aho and Jeffrey D. Ullman. Warning, reading this book will make your head hurt.
Introduction to Automata Theory, Languages, and Computation by John Hopcroft and Jeffrey D. Ullman. Has a great chapter on Turing machines. If you really want your head to hurt, then get the book above rather than the first edition of this book.
Ratfor, R, RUNOFF, RPG and Ruby
R is for Ratfor, R, RUNOFF, RPG and Ruby
Ratfor is a structured form of Fortran from the days when structured programming was the in-thing and Fortran did not have much of it (lots got added in later revisions). I think its success came from allowing users to claim a degree of respectability that Fortran did not have, and which Fortran did not appear to gain when structure constructs were added to it (but then all successful languages are treated with suspicion in some circles).
The maintainers of R provide a valuable lesson on issues that are not important for a language to be widely used, such as the following (which I’m sure many of those involved with languages incorrectly think are important):
- Technical language details are not important (e.g., functional, imperative, declarative, object-oriented, etc); as far as I can tell the language has hardly changed over the years, yet users are not bothered. What is important is how easily the language can be used to solve its users’ problems. There are umpteen different ways a language can be designed around R’s very useful ability to operate on vectors as a single unit or to dynamically create data-frames, it does not make much difference how things are done as long as they work.
- Runtime efficiency is often not important; a look at the source of the R runtime system suggests that there are lots of savings to be had (maybe a factor of two). Users are usually a lot more willing to wait for a running program to complete than struggle with getting the program running in the first place; the R maintainers have concentrated on the tuning the usability of the ecosystem (intentionally or not, I don’t know). Also, R appears to be like Cobol in that the libraries are the best place to invest in performance optimization. I say ‘appears’ because I have noticed a growing number of R libraries completely written in R, rather than being a wrapper to code in C or Fortran; perhaps the efficiency of the runtime system is becoming an important issue.
Most programs don’t use a lot of cpu resources, this was true back when I was using 8-bit cpus running at 4MHz and is even more true today. I used to sell add-on tools to make code run faster and it was surprising how often developers had no idea how long their code took to run, they just felt it was not fast enough; I was happy to go along with these feelings (if the developers could recite timing data a sale was virtually guaranteed).
plot is an unsung hero in R’s success, taking whatever is thrown at it and often producing something useful (if somewhat workman-like visually).
RUNOFF is the granddaddy of text processing systems such as *roff and LaTeX. RUNOFF will do what you tell it to do (groff is a modern descendant), while LaTeX will listen to what you have to say before deciding what to do. A child of RUNOFF shows that visual elegance can be achieved using simple means (maintainers of R’s plot function take note). Businesses used to buy computers and expensive printers so they could use this language, or one of its immediate descendants.
RPG must be the most widely used proprietary programming language ever.
Is Ruby’s current success all down to the success of one web application framework written in it? In its early years C claim to fame was as the language used to write Unix (I know people who gave this as the reason for choosing to use C). We will have to wait and see if Ruby has a life outside of one framework.
Things to read
“The R Book” by Michael J. Crawley.
A book about some important bits of R
I see that Hadley Wickham’s new book, “Advanced R”, is being published in dead tree form and will be available a month or so. Hadley has generously made the material available online; I quickly skimmed the material a few months ago when I first heard about it and had another skim this afternoon.
The main problem with the book is its title, authors are not supposed to write advanced books and then call them advanced. When I studied physics the books all had “advanced” in their titles, but when I got to University the books switched to having some variant of “fundamental” in their title. A similar pattern applies to computer books, with the books aimed at people who know a bit and want to learn a bit more having an advanced-like word in their title and the true advanced stuff having more downbeat titles, e.g., Javascript: The Good Parts, “Algorithms in Snobol 4”, Algorithms + Data Structures = Programs.
Some alternative title suggestions: “R: Some important bits”, “The Anatomy of R” or “The nitty gritty of R”.
The book is full of useful technical details that are scattered about and time consuming to find elsewhere; a useful reference manual, covering how to do technical stuff in R, to have on the shelf.
My main quibble with the book is the amount of airplay that the term “functional programming” gets. Does anybody really care that R has a strong functional flavor? Would many R users recognize another functional language if it jumped up and bit them? The die hard functional folk would probably say that R is not really a functional language, but who cares. I think people who write about R should stop using the words “functional programming”, it just confuses R users and serves no useful purpose; just talk about the convenient things that R allows us to write.
A book that I would really like to read is the R equivalent of books such as “Algorithms in Snobol 4”, “Effective C++” and “SQL for Smarties” (ok, that one has advanced in the subtitle), that take a wide selection of relatively simple problems and solve them in ways that highlight different aspects of the language (perhaps providing multiple solutions to the same problem).
Creating a map showing land covered by rising sea levels
I joined the Geekli.st climate Hackathon this weekend at the Hub Westminster (my favorite venue for Hackathons). While the organizers had lots of enthusiasm they had very little in the way of data for us to work on. No problem, ever since the Flood-relief hackathon I have wanted to use the SRTM ‘whole Earth’ elevation data on a flood related hack. Since this was a climate change related hack the obvious thing to do was to use the data to map the impact of any increases in sea level (try it, with wording for stronger believers).
The hacking officially started Friday evening at 19:00, but I only attended the evening event to meet people and form a team. Rob Finean was interested in the idea of mapping the effects of sea a rise in level (he also had previous experience using leaflet, a JavaScript library for interactive maps) and we formed a team, Florian Rathgeber joined us on Saturday morning.
I downloaded all the data for Eurasia (5.6G) when I got home Friday night and arriving back at the hackthon on Saturday morning started by writing a C program to convert the 5,876 files, each 1-degree by 1-degree squares on the surface of the Earth, to csv files.
The next step was to fit a mesh to the data and then locate constant altitude contours, at 0.5m and 1.5m above current sea level. Fitting a 2-D mesh to the data was easy (I wanted to use least squares rather than splines so that errors in the measurements could be taken into account), as was plotting and drawing contours, but getting the actual values for the contour lat/long proved to be elusive. I got bogged down looking at Python code, Florian knew a lot more Python than me and started looking for a Python solution while I investigated what R had to offer. Given the volume of data a Python solution looked like the best fit for the work-flow.
By late afternoon no real progress had been made and things were not looking good. Google searches on the obvious keywords returned lots of links to contour plotting libraries and papers claiming to have found a better contour evaluation algorithm, but no standalone libraries. I was reduced to downloading the source code of R to search for the code it used to calculate contours, with a view to extracting the code for my own use.
Rob wanted us to produce kml (Keyhole Markup Language) that his front end could read to render an overlay on a map.
At almost the same time Florian found that GDAL (Geospatial Data Abstraction Library) could convert hgt files (the raw SRTM file format) to kml and I discovered the R contourLines function. Florian had worked with GDAl before but having just completed his PhD had to leave to finish a paper he was working on, leaving us with instruction on the required options.
The kml output by GDAL was great for displaying contours, but did not fill in the enclosed area. The output I was generating using R filled the area enclosed by the contours but contained lots of noise because independent contours were treated having a connection to each other. I knew a script could be written to produce the desired output from the raw data, but did not know if GDAL had options to do what we wanted.
Its all very well being able to write a script to produce the desired output, but what is the desired output? Rob was able to figure out how the contour fill data had to be formatted in the kml file and I generated this using R, awk, sed, shell scripts and around six hours of cpu time on my laptop.
Rob’s front end uses leaflet with mapping data from Openstreetmap and the kml files to create a fantastic looking user-configurable map showing the effect of 0.5m and 1.5 rises in sea level.
The sea level data on the displayed map only shows the south of England and some of the north coast of Europe because loading any more results in poor performance (it is all loaded statically). Support is needed for dynamically loading of data on an as required basis. All of the kml files for Eurasia with 1.5 sea level rise are up on Github (900M+ of data). At the moment the contour data is only at the most detailed level of resolution and less detailed resolution is needed for when users zoom out. R’s contourLines function has no arguments for changing the resolution of which it returns; if you know of a better contour library please let me know.
The maps show average sea level. When tides are taken into account the sea level at certain times of the day may be a lot higher in some areas. We did not have access to tide data and would not have had time to make use of it anyway, so the effects of tide on sea level are not included.
Some of the speckling in the overlays may be noise caused by the error bounds of the SRTM data (around 6m for Eurasia; an accuracy level that makes our expectation of a difference between 0.5m and 1.5m contours problematic).
An ISO Standard for R (just kidding)
IST/5, the British Standards’ committee responsible for programming languages in the UK, has a new(ish) committee secretary and like all people in a new role wants to see a vision of the future; IST/5 members have been emailed asking us what we see happening in the programming language standards’ world over the next 12 months.
The answer is, off course, that the next 12 months in programming language standards is very likely to be the same as the previous 12 months and the previous 12 before that. Programming language standards move slowly, you don’t want existing code broken by new features and it would be a huge waste of resources creating a standard for every popular today/forgotten tomorrow language.
While true the above is probably not a good answer to give within an organization that knows its business intrinsically works this way, but pines for others to see it as doing dynamic, relevant, even trendy things. What could I say that sounded plausible and new? Big data was the obvious bandwagon waiting to be jumped on and there is no standard for R, so I suggested that work on this exciting new language might start in the next 12 months.
I am not proposing that anybody start work on an ISO standard for R, in fact at the moment I think it would be a bad idea; the purpose of suggesting the possibility is to create some believable buzz to suggest to those sitting on the committees above IST/5 that we have our finger on the pulse of world events.
The purpose of a standard is to create agreement around one way of doing things and thus save lots of time/money that would otherwise be wasted on training/tools to handle multiple language dialects. One language for which this worked very well is C, for which there were 100+ incompatible compilers in the early 1980s (it was a nightmare); with the publication of the C Standard users finally had a benchmark that they could require their suppliers to meet (it took 4-5 years for the major suppliers to get there).
R is not suffering from a proliferation of implementations (incompatible or otherwise), there is no problem for an R standard to solve.
Programming language standards do get created for reasons other than being generally useful. The ongoing work on C++ is a good example of consultant driven standards development; consultants who make their living writing and giving seminars about the latest new feature of C++ require a steady stream of new feature to talk about and have an obvious need to keep new versions of the standard rolling down the production line. Feeling that a language is unappreciated is another reason for creating an ISO Standard; the Modula-2 folk told me that once it became an ISO Standard the use of Modula-2 would take off. R folk seem to have a reasonable grip on reality, or have I missed a lurking distorted view of reality that will eventually give people the drive to spend years working their fingers to the bone to create a standard that nobody is really that interested in?
Oh, I did not know that [about R]
I recently saw a post about something called ValidR and as somebody with a long standing professional interest in language validation immediately read the article and referenced links. I was disappointed to find that what was being validated was the installation, not the behavior of the implementation. In the context of what I understand ValidR’s target market to be, drug testing, obtaining reproducible results is very important and so it is necessary to know exact what software has been installed (e.g., packages and their versions).
Implementation validation involves checking that the implementation of a language adheres to the requirements specified in the appropriate language standard. While International standards exist for many of the widely used languages, some have standard’s developed through other means and some have no recognized specification at all (e.g., PHP, Perl and R).
Not having a recognized specification is a problem for PHP because there are multiple implementations in common use. Perl and R both have a dominant implementation, which means the definition of the language is accepted as being whatever that implementation does.
Now, anybody who claims that having an open source implementation is as good as having a specification written in English (i.e., people can read the code to discover the behavior) clearly have not done much, if any, reading of language implementations. Over the years I have worked with the source of a fare few language implementations and my general experience is that the fastest and most reliable way of finding out what an implementation does is to write test case, only reading the source when test cases cannot be found that answer the questions.
Does it matter that there is no complete English specification of R (the current specification is very much a work in progress, with lots of progress remaining)?
Who reads computer language specifications (apart from language wonks like me)? Creators of implementations is the most obvious answer. But an R implementation already exists, why should the R team spend time making it easier to create alternative implementations? Actually I see the main customers of an R language specification being the R-core team.
An example of the benefits to the owner of source code in having a specification is provided by the EU/Microsoft competition court case. I was an adviser to the Monitoring Trustee appointed by the Commission to oversee the documentation of the specification of these protocols (no previous documentation existed). A frequently heard comment from the senior Microsoft developers we dealt with, on reading their own new specifications, was “Oh, I did not know that”.
A written specification is much more compact than source code or test cases and is (or should be) organized in a way that helps readers understand what is being said (this is often a stated aim for source code but is rare achieved). There are probably lots of behaviors that the R team are unaware of which, if they get to find out about them, might be interested in ‘fixing’ or at least discussing whether it is a desirable behavior. Or perhaps the R team’s strategy is to make life difficult for competing implementations.
Hack, a template for improving code reliability
My sole prediction for 2014 has come true, Facebook have announced the Hack language (if you don’t know that HHVM is the Hip Hop Virtual Machine you are obviously not a trendy developer).
This language does not follow the usual trend in that it looks useful, rather than being fashion fluff for corporate developers to brag about. Hack extends an existing language (don’t the Facebook developers know about not-invented-here?) by adding features to improve code reliability (how uncool is that) and stuff that will sometimes enable faster code to be generated (which has always been cool).
Well done Facebook. I hope this is the start of a trend of adding features to a language that help developers improve code reliability.
Hack extends PHP to allow programmers to express intent, e.g., this variable only ever holds integer values. Compilers can then check that the code follows the intent and flag when it doesn’t, e.g., a string is assigned to the variable intended to only hold integers. This sounds so trivial to be hardly worth bothering about, but in practice it catches lots of minor mistakes very quickly and saves huge amounts of time that would otherwise be spent debugging code at runtime.
Yes, Hack has added static typing into a dynamically typed language. There is a generally held view that static typing prevents programmers doing what needs to be done and that dynamic typing is all about freedom of expression (who could object to that?) Static typing got a bad name because early languages using it were too disciplinarian in a few places and like the very small stone in a runners shoe these edge cases came to dominate thinking. Dynamic languages are great for small programs and showing off to spotty teenagers students, but are expensive to maintain and a nightmare to work with on 10K+ line systems.
The term gradual typing is a good description for Hack’s type system. Developers can take existing PHP code and gradually give types to existing variables in a piecemeal fashion or add new code that uses types into code that does not. The type checker figures out what it can and does not get too upperty about complaining. If a developer can be talked into giving such a system a try they quickly learn that they can save a lot of debugging time by using it.
I would like to see gradual typing introduced into R, but perhaps the language does not cause its users enough grief to make this happen (it is R’s libraries that cause the grief):
- Compared to PHP’s quirks the R quirk’s are pedestrian. In the interest of balance I should point out that Javascript can at times be as quirky as PHP and C++ error messages can be totally incomprehensible to everybody (including the people who wrote the compiler).
- R programs are often small, i.e., 100 lines’ish. It is only when programs, written in dynamically typed languages, start to exceed around 10k+ lines that they start to fall in on themselves unless that one person who has everything in his head is there to hold it all up.
However, there is a sort of precedent: Perl programs tend to be short (although I don’t think they are as short as R) and it gradually introduced the option of stronger typing. But Perk did/does have one person who was the recognized language designer who could lead the process; R has a committee.
By now I ought to feel more knowledgeable about R
I was surprised to find recently that there are now over 15,000 lines of R code in the book I am working on. If I had written that much code in another ‘newly’ acquired language I would probably feel a lot more knowledgeable about it than I currently feel about R. Why don’t I feel more knowledgeable about R?
Those 15,000 lines are not all real lines, lots of cut-and-paste has been going on; yes, R is a cut-and-paste language just like Cobol and ‘web’ languages. ‘Real’ programmers often look down their noses at such languages, but that is just a failure on their part to understand what they are really all about. Perhaps I have written 5,000 actual lines of R, still a decent amount and half way to the 10,000 line minimum I ask newbies if they have reached.
An expert in a language should be able to pick up a random sample of code and to have been there, done that and got the t-shirt. I still regularly learn new stuff when reading other people’s code, so I’m still a long way from being an R expert. But then R is in the mold of a functional language and one characteristic of languages in this mold is that they provide umpteen different ways of doing the same thing. The combination of this language characteristic along with the lack of common culture in R usage (when this exists it significantly reduces the patterns of code usage commonly encountered) could mean that I am on the treadmill of forever and regularly learning new R coding techniques (which is great source for blog articles but gets tedious after a while); Perl is a lot like this.
As a compiler guy I’m used to learning a language by reading the language definition. Reading this document gives me a warm fuzzy feeling of knowing the language, this has nothing to do with being able to program in it and there is no way of knowing that I understood what the words meant. I was going to say that the R language definition was little more than some brief notes jotted down by somebody to be written up later, but checking the link to the page I discovered that somebody had been spending time significantly improving on what existed a few years ago; there is still a way to go but the R language definition is starting to look respectable. Hopefully my feeling of R knowledgeability will improve after I have read through this updated definition a few times.
Use of R is usually intimately bound up with the data being manipulated; on a per line of code basis much more so than other languages (in this regard it is like Cobol). Perhaps the need to have to learn lots more about the data than I normally have to adds to my feeling of not knowing. Would my feeling of knowledgeability increase if I worked with the same kind of data ll the time?
Performing a non-local return in R
In most languages return is a statement, but in R it is a function (in fact R does not really have statements, it only has expressions). This function-like behavior of return is useful for figuring out the order in which operations are performed, e.g., the value returned by return(1)+return(2) tells us that binary operators are evaluated left to right.
R also supports lazy evaluation, operands are only evaluated when their value is required. The question of when a value might be required is a very complicated rabbit hole. In R’s case arguments to function calls are lazy and in the following code:
ret_a_b=function(a, b) { if (runif(1, -1, 1) < 0) a else b } helpless=function() { ret_a_b(return(3), return(4)) return(99) } |
a call to helpless results in either 3 or 4 being returned.
This ability to perform non-local returns is just what is needed to implement exception handling recovery, i.e., jumping out of some nested function to a call potentially much higher up in the call tree, without passing back up through the intervening function called, when something goes wrong.
Having to pass the return-blob to every function called would be a pain, using a global variable would make life much simpler and less error prone. Simply assigning to a global variable will not work because the value being assigned is evaluated (it does not have to be, but R chooses to not to be lazy here). My first attempt to get what I needed into a global variable involved delayedAssign, but that did not work out. The second attempt made use of the environment created by a nested function definition, as follows:
# Create an environment containing a return that can be evaluated later. set_up=function(the_ret) { ret_holder=function() { the_ret } return(ret_holder) } # For simplicity this is not nested in some complicated way do_stuff=function() { # if (something_gone_wrong) get_out_of_jail() return("done") } get_out_of_jail=0 # Out friendly global variable control_func=function(a) { # Set up what will get called get_out_of_jail <<- set_up(return(a)) # do some work do_stuff() return(0) } control_func(11) |
and has the desired effect 🙂
Recent Comments