Archive
Reliability chapter of ‘evidence-based software engineering’ updated
The Reliability chapter of my evidence-based software engineering book has been updated (draft pdf).
Unlike the earlier chapters, there were no major changes to the initial version from over 18-months ago; we just don’t know much about software reliability, and there is not much public data.
There are lots of papers published claiming to be about software reliability, but they are mostly smoke-and-mirror shows derived from work down one of several popular rabbit holes:
- Machine learning is a popular technique for fault prediction, and I have written about what a train wreck this research is, along with the incomplete and very noisy data that makes nearly every attempt at fault prediction a waste of time.
- Mutation testing sounds like a technique that would be useful (and it is for pumping out papers), but it has the fatal flaw of telling people what they already know (i.e., that their test suites are not very good), and targeting coding mistakes that represent around 5% of known fault experiences (around 5% of all fixes to reported faults involve changing one line; most mutation testing works by modifying a single line of code).
- Other researchers are busily adding more epicycles to models based on the nonhomogeneous Poisson process.
The growth in research on Fuzzing is the only good news (especially with the availability of practical introductory material).
There is one source of fault experience data that looks like it might be very useful, but it’s hard to get hold of; NASA has kept detailed about what happened using space missions. I have had several people promise to send me data, but none has arrived yet :-(.
Updating the reliability chapter did not take too much time, so I updated earlier chapters with data that has arrived since they were last released.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Source code chapter.
The Renzo Pomodoro dataset
Estimating how long it will take to complete a task is hard work, and the most common motivation for this work comes from external factors, e.g., the boss, or a potential client asks for an estimate to do a job.
People also make estimates for their own use, e.g., when planning work for the day. Various processes and techniques have been created to help structure the estimation process; for developers there is the Personal Software Process, and specifically for time estimation (but not developer specific), there is the Pomodoro Technique.
I met Renzo Borgatti at the first talk I gave on the SiP dataset (Renzo is the organizer of the Papers We Love meetup). After the talk, Renzo told me about his use of the Pomodoro Technique, and how he had 10-years worth of task estimates; wow, I was very interested. What happened next, and a work-in-progress analysis (plus data and R scripts) of the data can be found in the Renzo Pomodoro dataset repo.
The analysis progressed in fits and starts; like me Renzo is working on a book, and is very busy. The work-in-progress pdf is reasonably consistent.
I had never seen a dataset of estimates made for personal use, and had not read about the analysis of such data. When estimates are made for consumption by others, the motives involved in making the estimate can have a big impact on the values chosen, e.g., underestimating to win a bid, or overestimating to impress the boss by completing a task under budget. Is a personal estimate motive free? The following plot led me to ask Renzo if he was superstitious (in not liking odd numbers).
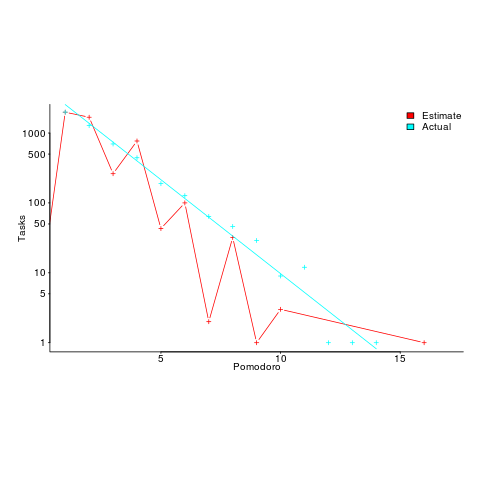
The plot shows the number of tasks for which there are a given number of estimates and actuals (measured in Pomodoros, i.e., units of 25 minutes). Most tasks are estimated to require one Pomodoro, and actually require this amount of effort.
Renzo educated me about the details of the Pomodoro technique, e.g., there is a 15-30 minute break after every four Pomodoros. Did this mean that estimates of three Pomodoros were less common because the need for a break was causing Renzo to subconsciously select an estimate of two or four Pomodoro? I am not brave enough to venture an opinion about what is going on in Renzo’s head.
Each estimated task has an associated tag name (sometimes two), which classifies the work involved, e.g., @planning. In the task information these tags have the form @word; I refer to them as at-words. The following plot is very interesting; it shows the date of use of each at-word, over time (ordered by first use of the at-word).
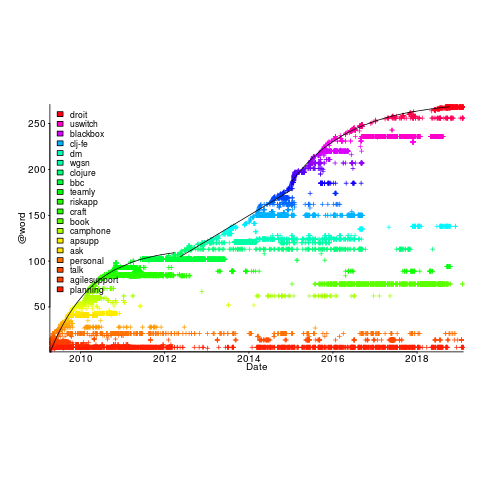
The first and third black lines are fitted regression models of the form  , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
The slow down in the growth of new at-words suggests (at least to me) a period of time working in the same application domain (which involves a fixed number of distinct activities, that are ‘discovered’ by Renzo over time). More discussion with Renzo is needed to see if we can tie this down to what he was working on at the time.
I have looked for various other patterns and associations, involving at-words, but have not found any (but I did learn some new sequence analysis techniques, and associated R packages).
The data is now out there. What patterns and associations can you find?
Renzo tells me that there is a community of people using the Pomodoro technique. I’m hoping that others users of this technique, involved in software development, have recorded their tasks over a long period (I don’t think I could keep it up for longer than a week).
Perhaps there are PSP followers out there with data…
I offer to do a free analysis of software engineering data, provided I can make data public (in anonymized form). Do get in touch.
Projects chapter of ‘evidence-based software engineering’ reworked
The Projects chapter of my evidence-based software engineering book has been reworked; draft pdf available here.
A lot of developers spend their time working on projects, and there ought to be loads of data available. But, as we all know, few companies measure anything, and fewer hang on to the data.
Every now and again I actively contact companies asking data, but work on the book prevents me spending more time doing this. Data is out there, it’s a matter of asking the right people.
There is enough evidence in this chapter to slice-and-dice much of the nonsense that passes for software project wisdom. The problem is, there is no evidence to suggest what might be useful and effective theories of software development. My experience is that there is no point in debunking folktales unless there is something available to replace them. Nature abhors a vacuum; a debunked theory has to be replaced by something else, otherwise people continue with their existing beliefs.
There is still some polishing to be done, and a few promises of data need to be chased-up.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Reliability chapter.
Ecosystems chapter of “evidence-based software engineering” reworked
The Ecosystems chapter of my evidence-based software engineering book has been reworked (I have given up on the idea that this second pass is also where the polishing happens; polishing still needs to happen, and there might be more material migration between chapters); download here.
I have been reading books on biological ecosystems, and a few on social ecosystems. These contain lots of interesting ideas, but the problem is, software ecosystems are just very different, e.g., replication costs are effectively zero, source code does not replicate itself (and is not self-evolving; evolution happens because people change it), and resources are exchanged rather than flowing (e.g., people make deals, they don’t get eaten for lunch). Lots of caution is needed when applying ecosystem related theories from biology, the underlying assumptions probably don’t hold.
There is a surprising amount of discussion on the computing world as it was many decades ago. This is because ecosystem evolution is path dependent; understanding where we are today requires knowing something about what things were like in the past. Computer memory capacity used to be a big thing (because it was often measured in kilobytes); memory does not get much publicity because the major cpu vendor (Intel) spends a small fortune on telling people that the processor is the most important component inside a computer.
There are a huge variety of software ecosystems, but you would not know this after reading the ecosystems chapter. This is because the work of most researchers has been focused on what used to be called the desktop market, which over the last few years the focus has been shifting to mobile. There is not much software engineering research focusing on embedded systems (a vast market), or supercomputers (a small market, with lots of money), or mainframes (yes, this market is still going strong). As the author of an evidence-based book, I have to go where the data takes me; no data, then I don’t have anything to say.
Empirical research (as it’s known in academia) needs data, and the ‘easy’ to get data is what most researchers use. For instance, researchers analyzing invention and innovation invariably use data on patents granted, because this data is readily available (plus everybody else uses it). For empirical research on software ecosystems, the readily available data are package repositories and the Google/Apple Apps stores (which is what everybody uses).
The major software ecosystems barely mentioned by researchers are the customer ecosystem (the people who pay for everything), the vendors (the companies in the software business) and the developer ecosystem (the people who do the work).
Next, the Projects chapter.
Converting lines in an svg image to csv
During a search for data on programming language usage I discovered Stack Overflow Trends, showing an interesting plot of language tags appearing on Stack Overflow questions (see below). Where was the csv file for these numbers? Somebody had asked this question last year, but there were no answers.

The graphic is in svg format; has anybody written an svg to csv conversion tool? I could only find conversion tools for specialist uses, e.g., geographical data processing. The svg file format is all xml, and using a text editor I could see the numbers I was after. How hard could it be (it had to be easier than a png heatmap)?
Extracting the x/y coordinates of the line segments for each language turned out to be straight forward (after some trial and error). The svg generation process made matching language to line trivial; the language name was included as an xml attribute.
Programmatically extracting the x/y axis information exhausted my patience, and I hard coded the numbers (code+data). The process involves walking an xml structure and R’s list processing, two pet hates of mine (the data is for a book that uses R, so I try to do everything data related in R).
I used R’s xml2 package to read the svg files. Perhaps if my mind had a better fit to xml and R lists, I would have been able to do everything using just the functions in this package. My aim was always to get far enough down to convert the subtree to a data frame.
Extracting data from graphs represented in svg files is so easy (says he). Where is the wonderful conversion tool that my search failed to locate? Pointers welcome.
My book’s pdf generation workflow
The process used to generate the pdf of my evidence-based software engineering book has been on my list of things to blog about, for ever. An email arrived this afternoon, asking how I produced various effects using Asciidoc; this post probably contains rather more than N. Psaris wanted to know.
It’s very easy to get sucked into fiddling around with page layout and different effects. So, unless I am about to make a release of a draft, I only generate a pdf once, at the end of each month.
At the end of the month the text is spell checked using aspell, and then grammar checked using Language tool. I have an awk script that checks the text for mistakes I have made in the past; this rarely matches, i.e., I seem to be forever making different mistakes.
The sequencing of tools is: R (Sweave) -> Asciidoc -> docbook -> LaTeX -> pdf; assorted scripts fiddle with the text between outputs and inputs. The scripts and files mention below are available for download.
R generates pdf files (via calls to the Sweave function, I have never gotten around to investigating Knitr; the pdfs are cropped using scripts/pdfcrop.sh) and the ascii package is used to produce a few tables with Asciidoc markup.
Asciidoc is the markup language used for writing the text. A few years after I started writing the book, Stuart Rackham, the creator of Asciidoc, decided to move on from working and supporting it. Unfortunately nobody stepped forward to take over the project; not a problem, Asciidoc just works (somebody did step forward to reimplement the functionality in Ruby; Asciidoctor has an active community, but there is no incentive for me to change). In my case, the output from Asciidoc is xml (it supports a variety of formats).
Docbook appears in the sequence because Asciidoc uses it to produce LaTeX. Docbook takes xml as input, and generates LaTeX as output. Back in the day, Docbook was hailed as the solution to all our publishing needs, and wonderful tools were going to be created to enable people to produce great looking documents.
LaTeX is the obvious tool for anybody wanting to produce lovely looking books and articles; tex/ESEUR.tex is the top-level LaTeX, which includes the generated text. Yes, LaTeX is a markup language, and I could have written the text using it. As a language I find LaTeX too low level. My requirements are not complicated, and I find it easier to write using a markup language like Asciidoc.
The input to Asciidoc and LuaTeX (used to generate pdf from LaTeX) is preprocessed by scripts (written using sed and awk; see scripts/mkpdf). These scripts implement functionality that Asciidoc does not support (or at least I could see how to do it without modifying the Python source). Scripts are a simple way of providing the extra functionality, that does not require me to remember details about the internals of Asciidoc. If Asciidoc was being actively maintained, I would probably have worked to get some of the functionality integrated into a future release.
There are a few techniques for keeping text processing scripts simple. For instance, the cost of a pass over text is tiny, there is little to be gained by trying to do everything in one pass; handling the possibility that markup spans multiple lines can be complicated, a simple solution is to join consecutive lines together if there is a possibility that markup spans these lines (i.e., the actual matching and conversion no longer has to worry about line breaks).
Many simple features are implemented by a script modifying Asciidoc text to include some ‘magic’ sequence of characters, which is subsequently matched and converted in the generated LaTeX, e.g., special characters, and hyperlinks in the pdf.
A more complicated example handles my desire to specify that a figure appear in the margin; the LaTeX sidenotes package supports figures in margins, but Asciidoc has no way of specifying this behavior. The solution was to add the word “Margin”, to the appropriate figure caption option (in the original Asciidoc text, e.g., [caption="Margin ", label=CSD-95-887]), and have a script modify the LaTeX generated by docbook so that figures containing “Margin” in the caption invoked the appropriate macro from the sidenotes package.
There are still formatting issues waiting to be solved. For instance, some tables are narrow enough to fit in the margin, but I have not found a way of embedding this information in the table information that survives through to the generated LaTeX.
My long time pet hate is the formatting used by R’s plot function for exponentiated values as axis labels. My target audience are likely to be casual users of R, so I am sticking with basic plotting (i.e., no calls to ggplot). I do wish the core R team would integrate the code from the magicaxis package, to bring the printing of axis values into the era of laser printers and bit-mapped displays.
Ideas and suggestions welcome.
Complexity is a source of income in open source ecosystems
I am someone who regularly uses R, and my interest in programming languages means that on a semi-regular basis spend time reading blog posts about the language. Over the last year, or so, I had noticed several patterns of behavior, and after reading a recent blog post things started to make sense (the blog post gets a lot of things wrong, but more of that later).
What are the patterns that have caught my attention?
Some background: Hadley Wickham is the guy behind some very useful R packages. Hadley was an academic, and is now the chief scientist at RStudio, the company behind the R language specific IDE of the same name. As Hadley’s thinking about how to manipulate data has evolved, he has created new packages, and has been very prolific. The term Hadley-verse was coined to describe an approach to data manipulation and program structuring, based around use of packages written by the man.
For the last nine-months I have noticed that the term Tidyverse is being used more regularly to describe what had been the Hadley-verse. And???
Another thing that has become very noticeable, over the last six-months, is the extent to which a wide range of packages now have dependencies on packages in the HadleyTidyverse. And???
A recent post by Norman Matloff complains about the Tidyverse’s complexity (and about the consistency between its packages; which I had always thought was a good design principle), and how RStudio’s promotion of the Tidyverse could result in it becoming the dominant R world view. Matloff has an academic world view and misses what is going on.
RStudio, the company, need to sell their services (their IDE is clunky and will be wiped out if a top of the range product, such as Jetbrains, adds support for R). If R were simple to use, companies would have less need to hire external experts. A widely used complicated library of packages is a god-send for a company looking to sell R services.
I don’t think Hadley Wickam intentionally made things complicated, any more than the creators of the Microsoft server protocols added interdependencies to make life difficult for competitors.
A complex package ecosystem was probably not part of RStudio’s product vision, at least for many years. But sooner or later, RStudio management will have realised that simplicity and ease of use is not in their interest.
Once a collection of complicated packages exist, it is in RStudio’s interest to get as many other packages using them, as quickly as possible. Infect the host quickly, before anybody notices; all the while telling people how much the company is investing in the community that it cares about (making lots of money from).
Having this package ecosystem known as the Hadley-verse gives too much influence to one person, and makes it difficult to fire him later. Rebranding as the Tidyverse solves these problems.
Matloff accuses RStudio of monopoly behavior, I would have said they are fighting for survival (i.e., creating an environment capable of generating the kind of income a VC funded company is expected to make). Having worked in language environments where multiple, and incompatible, package ecosystems existed, I can see advantages in there being a monopoly. Matloff is also upset about a commercial company swooping in to steal their precious, a common academic complaint (academics swooping in to steal ideas from commercially developed software is, of course, perfectly respectable). Matloff also makes claims about teachability of programming that are not derived from any experimental evidence, but then everybody makes claims about programming languages without there being any experimental evidence.
RStudio management rode in on the data science wave, raising money from VCs. The wave is subsiding and they now need to appear to have a viable business (so they can be sold to a bigger fish), which means there has to be a visible market they can sell into. One way to sell in an open source environment is for things to be so complicated, that large companies will pay somebody to handle the complexity.
Cognitive capitalism chapter reworked
The Cognitive capitalism chapter of my evidence-based software engineering book took longer than expected to polish; in fact it got reworked, rather than polished (which still needs to happen, and there might be more text moving from other chapters).
Changing the chapter title, from Economics to Cognitive capitalism, helped clarify lots of decisions about the subject matter it ought to contain (the growth in chapter page count is more down to material moving from other chapters, than lots of new words from me).
I over-spent time down some interesting rabbit holes (e.g., real options), before realising that no public data was available, and unlikely to be available any time soon. Without data, there is not a lot that can be said in a data driven book.
Social learning is a criminally under researched topic in software engineering. Some very interesting work has been done by biologists (e.g., Joseph Henrich, and Kevin Laland), in the last 15 years; the field has taken off. There is a huge amount of social learning going on in software engineering, and virtually nobody is investigating it.
As always, if you know of any interesting software engineering data, please let me know.
Next, the Ecosystems chapter.
Polished human cognitive characteristics chapter
It has been just over two years since I release the first draft of the Human cognitive characteristics chapter of my evidence-based software engineering book. As new material was discovered, it got added where it seemed to belong (at the time), no effort was invested in maintaining any degree of coherence.
The plan was to find enough material to paint a coherence picture of the impact of human cognitive characteristics on software engineering. In practice, finishing the book in a reasonable time-frame requires that I stop looking for new material (assuming it exists), and go with what is currently available. There are a few datasets that have been promised, and having these would help fill some holes in the later sections.
The material has been reorganized into what is essentially a pass over what I think are the major issues, discussed via studies for which I have data (the rule of requiring data for a topic to be discussed, gets bent out of shape the most in this chapter), presented in almost a bullet point-like style. At least there are plenty of figures for people to look at, and they are in color.
I think the material will convince readers that human cognition is a crucial topic in software development; download the draft pdf.
Model building by cognitive psychologists is starting to become popular, with probabilistic languages, such as JAGS and Stan, becoming widely used. I was hoping to build models like this for software engineering tasks, but it would have taken too much time, and will have to wait until the book is done.
As always, if you know of any interesting software engineering data, please let me know.
Next, the cognitive capitalism chapter.
Polished statistical analysis chapters in evidence-based software engineering
I have completed the polishing/correcting/fiddling of the eight statistical analysis related chapters of my evidence-based software engineering book, and an updated draft pdf is now available (download here).
The material was in much better shape than I recalled, after abandoning it to the world 2-years ago, to work on the software engineering chapters.
Changes include moving more figures into the margin (which is responsible for a lot of the reduction in page count), fixing grammatical typos, removing place-holders for statistical techniques that are unlikely to be of general interest to software engineers, and mostly minor shuffling around (the only big change was moving a lot of material from the Experiments chapter to the Statistics chapter).
There is still some work to be done, in places (most notably the section on surveys).
What next? My collection of data waiting to be analysed has been piling up, so I will spend the next month reducing the backlog.
The six chapters covering the major areas of software engineering need to be polished and fleshed out, from their current bare-bones state. All being well, this time next year a beta release will be ready.
While working on the statistical material, I have been making monthly updates to the pdf+data available. If it makes sense to do this for the rest of the material, then it will happen. I’m not going to write a blog post every month; perhaps a post after what look like important milestones.
As always, if you know of any interesting software engineering data, please tell me.
Recent Comments