Archive
Pomodoros worked during a day: an analysis of Alex’s data
Regular readers know that I am always on the lookout for software engineering data. One search technique is to feed a ‘magic’ phrase into a search engine, this can locate data hiding in plain sight. This week the magic phrase: “record of pomodoros” returned pages discussing two collections of daily Pomodoros worked, each over a year, plus several possible collections, i.e., not explicitly stated. My email requests for data have so far returned one of the collections, kindly made available by Alex Altair, and this post discusses Alex’s data (I have not discussed the data with Alex, who I’m hoping won’t laugh too loud at the conclusions I have reached).
Before analyzing data I always make predictions about what I expect to see. I know from the email containing the data that it consisted of two columns: date and Pomodoro’s worked, i.e., no record of task names. The first two predictions for this data were the two most common patterns seen in estimation data, i.e., use of round numbers, and a weekend-effect (most people don’t work during the weekend and the autocorrelation of the daily counts contain peaks at lags of 6 and 7). The third prediction was that over time the daily total Pomodoro counts would refine into counts for each of the daily tasks (I had looked at the first few lines of the data and seen totals for the daily Pomodoros worked.
The Renzo Pomodoro dataset is my only previous experience analysing Pomodoro data. Renzo created a list of tasks for the day, estimated the number of Pomodoros for each task would take, and recorded how many it actually took. For comparison, the SiP effort estimation dataset estimates software engineering tasks in hours.
Alex uses Pomodoros as a means of focusing his attention on the work to be done, and the recorded data is a measure of daily Pomodoro work done.
I quickly discovered that all my predictions were wrong, i.e., no obvious peaks showing use of round numbers, no weekend effect, and always daily totals. Ho-hum.
The round number effect is very prominent in estimates, but is not always visible in actuals; unless people are aiming to meet targets or following Parkinson’s law.
How many days had one Pomodoro worked, how many two Pomodoro, etc? The plot below shows the number of days for which a given number of Pomodoros were worked (the number of days with zero Pomodoros is not shown); note the axis are log scaled. The blue points are for all days in 2020, and the green points are all days in 2020+178 days of 2021. The red lines are two sets of two fitted power laws (code+data):
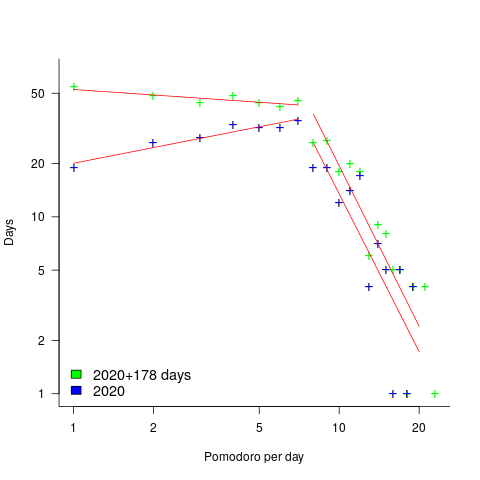
Why the sudden change of behavior after seven Pomodoro? Given a Pomodoro of 25-minutes (Alex says he often used this), seven of them is just under 3-hours, say half a day. Perhaps Alex works half a day, for every day of the week.
Why the change of behavior since the end of 2020 (i.e., exponent of left line changes from 0.3 to -0.1, exponent of right line is -3.0 in both cases)? Perhaps Alex is trying out another technique. The initial upward trend is consistent with the Renzo Pomodoro dataset.
The daily average Pomodoros worked is unchanged at around 5.6. The following plot shows daily Pomodoros worked over the 543 days, red line is a fitted loess model.
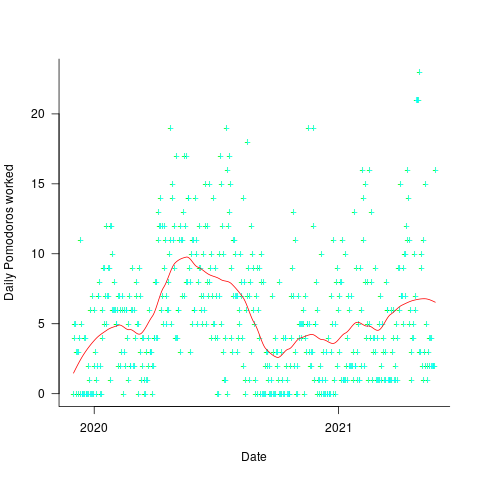
The weekend effect might not be present, but there is a strong correlation between adjacent days (code+data). The best fitting ARIMA model gives the equation:  , where:
, where:  is the Pomodoros worked on day
is the Pomodoros worked on day  ,
,  Pomodoros worked on the previous day,
Pomodoros worked on the previous day,  is white noise (e.g., a Normal distribution) with a zero mean and a standard deviation of 4 (in this case) on day , and
is white noise (e.g., a Normal distribution) with a zero mean and a standard deviation of 4 (in this case) on day , and  the previous day’s noise (see section 11.10 of my book for technical time series details).
the previous day’s noise (see section 11.10 of my book for technical time series details).
This model is saying that the number of Pomodoros worked today is strongly influenced by yesterday’s Pomodoro worked, modulated by a large random component that could be large enough to wipe out the previous days influence. Is this likely to be news to Alex, or to anybody looking at the plot of Pomodoros over time? Probably not.
For me, the purpose of data analysis is to find patterns of behavior that are of use to those involved in the processes that generated the data (for many academics, at least in software engineering, the purpose appears to be to find patterns that can be used to publish papers, and given enough searching, it is always possible to find patterns in data). What patterns of behavior might Alex be interested in?
Does more Pomodoro work get done at the start of the week, compared to the end of the week? The following heatmap is based on the number of week days on which a given number of Pomodoros were worked. The redder the region, the more likely that value is likely to occur (code+data):
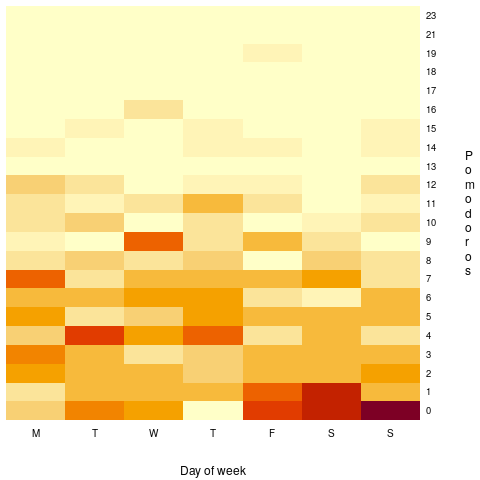
There are certainly more days near the end of the week having little or no Pomodoro work, and the high Pomodoro work days appear to be nearer the start of the week. I need to find a statistical technique that quantifies these observations.
I think that the middle plot is the most generally useful, it illustrates how variable the work done during a day can be.
Is Alex’s Pomodoro work typical or unusual? We will have to wait for a lot more data before that question can be addressed.
If you are a Pomodoro user, and have ideas for possible patterns in the data, please let me know.
As always, pointers to more data, Pomodoro or otherwise, most welcome.
The Renzo Pomodoro dataset
Estimating how long it will take to complete a task is hard work, and the most common motivation for this work comes from external factors, e.g., the boss, or a potential client asks for an estimate to do a job.
People also make estimates for their own use, e.g., when planning work for the day. Various processes and techniques have been created to help structure the estimation process; for developers there is the Personal Software Process, and specifically for time estimation (but not developer specific), there is the Pomodoro Technique.
I met Renzo Borgatti at the first talk I gave on the SiP dataset (Renzo is the organizer of the Papers We Love meetup). After the talk, Renzo told me about his use of the Pomodoro Technique, and how he had 10-years worth of task estimates; wow, I was very interested. What happened next, and a work-in-progress analysis (plus data and R scripts) of the data can be found in the Renzo Pomodoro dataset repo.
The analysis progressed in fits and starts; like me Renzo is working on a book, and is very busy. The work-in-progress pdf is reasonably consistent.
I had never seen a dataset of estimates made for personal use, and had not read about the analysis of such data. When estimates are made for consumption by others, the motives involved in making the estimate can have a big impact on the values chosen, e.g., underestimating to win a bid, or overestimating to impress the boss by completing a task under budget. Is a personal estimate motive free? The following plot led me to ask Renzo if he was superstitious (in not liking odd numbers).
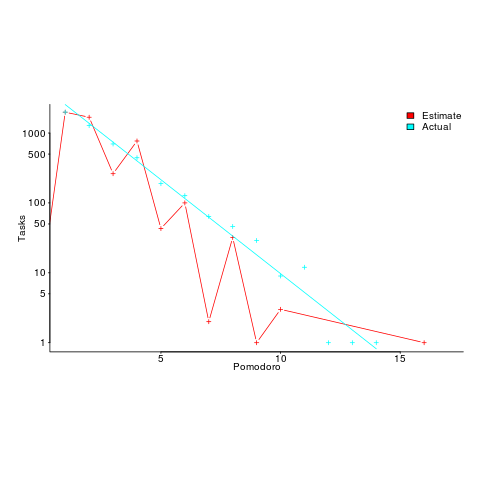
The plot shows the number of tasks for which there are a given number of estimates and actuals (measured in Pomodoros, i.e., units of 25 minutes). Most tasks are estimated to require one Pomodoro, and actually require this amount of effort.
Renzo educated me about the details of the Pomodoro technique, e.g., there is a 15-30 minute break after every four Pomodoros. Did this mean that estimates of three Pomodoros were less common because the need for a break was causing Renzo to subconsciously select an estimate of two or four Pomodoro? I am not brave enough to venture an opinion about what is going on in Renzo’s head.
Each estimated task has an associated tag name (sometimes two), which classifies the work involved, e.g., @planning. In the task information these tags have the form @word; I refer to them as at-words. The following plot is very interesting; it shows the date of use of each at-word, over time (ordered by first use of the at-word).
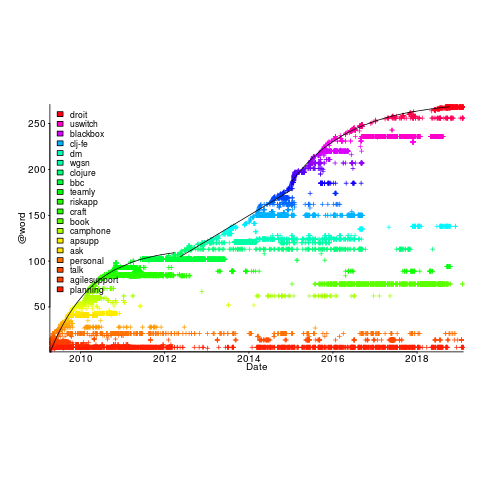
The first and third black lines are fitted regression models of the form  , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted. The second (middle) black line is a fitted straight line.
The slow down in the growth of new at-words suggests (at least to me) a period of time working in the same application domain (which involves a fixed number of distinct activities, that are ‘discovered’ by Renzo over time). More discussion with Renzo is needed to see if we can tie this down to what he was working on at the time.
I have looked for various other patterns and associations, involving at-words, but have not found any (but I did learn some new sequence analysis techniques, and associated R packages).
The data is now out there. What patterns and associations can you find?
Renzo tells me that there is a community of people using the Pomodoro technique. I’m hoping that others users of this technique, involved in software development, have recorded their tasks over a long period (I don’t think I could keep it up for longer than a week).
Perhaps there are PSP followers out there with data…
I offer to do a free analysis of software engineering data, provided I can make data public (in anonymized form). Do get in touch.
Recent Comments