Archive
Why is actual implementation time often reported in whole hours?
Estimates of the time needed to implement a software task are often given in whole hours (i.e., no minutes), with round numbers being preferred. Surprisingly, reported actual implementation times also share this ‘preference’ for whole hours and round numbers (around a third of short task estimates are accurate, so it is to be expected that around a third of actual implementation times will be some number of whole hours, at least for the small percentage of projects that record task implementation time).
Even for accurate estimates, some variation in minutes around the hour boundary is to be expected for the actual implementation time. Why are developers reporting integer hour values for actual time?
The following are some of the possible reasons, two at opposite ends of the spectrum, for developers to log actual time as an integer number of hours:
- Parkinson’s law, i.e., the task was completed earlier and the minutes before the whole hour were filled with other activities,
- striving to complete a task by the end of the hour, much like a marathon runner strives to complete a race on a preselected time boundary,
- performing short housekeeping tasks once the primary task is complete, where management is aware of this overhead accounting.
Is it possible to distinguish between these developer behaviors by analysing many task durations?
My thinking is that all three of these practices occur, with some developers having a preference for following Parkinson’s law, and a few developers always striving to get things done.
Given that Parkinson’s law is 70 years old and well known, there ought to be a trail of research papers analysing a variety of models.
Parkinson specified two ‘laws’. The less well known second law, specifies that the number of bureaucrats in an organization tends to grow, regardless of the amount of work to be done. Governments and large organizations publish employee statistics, and these have been used to check Parkinson’s second law.
With regard to Parkinson’s first law, there are papers whose titles suggest that something more than arm waving is to be found within. Sadly, I have yet to find a non-arm waving paper. Given the extreme difficulty of obtaining data on task durations, this lack of papers is not surprising.
Perhaps our LLM overlords, having been trained on the contents of the Internet, will succeed where traditional search engines have failed. The usual suspects (Grok, ChatGPT, Perplexity and Deepseek) suggested various techniques for fitting models to data, rather than listing existing models.
A new company, Kimi, launched their highly-rated model yesterday, and to try it out I asked: “Discuss mathematical models that analyse the impact of project staff following Parkinson’s law”. The quality of the reply was impressive (my registration has not yet been accepted, so I cannot obtain a link to Kimi’s response). A link to Grok 3’s evaluation of Kimi’s five suggested modelling techniques.
Having spent a some time studying the issues of integer hour actual times, I have not found a way to distinguish between the three possibilities listed above, using estimate/actual time data. Software development involves too many possible changeable activities to be amenable to Taylor’s scientific management approach.
Good luck trying to constrain what developers can do and when they can do it, or requiring excessive logging of activities, just to make it possible to model the development process.
Rounding in reported task implementation time
There is lots of evidence that people often pick a round number when estimating the time needed to implement a task. Parkinson’s law suggests that reported actual implementation time will often also be a round number, e.g., report 30 minutes for a task that actually took 28 minutes.
If a task is estimated to take 1-hour, what is the distribution of reported implementations times? The analysis in this article uses the SiP task dataset, and similar patterns occur in other datasets.
The plot below shows the number of tasks having a given reported implementation time, for tasks estimated to take 1-hour, with main peaks labelled in red (reported times rounded to one decimal place and quarter hours; code+data):
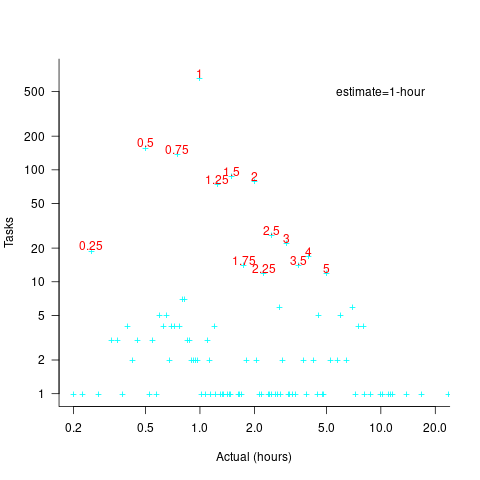
With 1-hour estimates, there is limited scope for a wide range of actual times (at least for times less than estimates). The labelled peaks contain 89% of 1-hour estimate tasks (1,525 tasks, 21% less than estimate, 44% equal estimate, 24% greater than estimate).
Tasks with larger estimated times are likely to take longer, creating more possible rounding peaks in the implementation time distribution. The plot below shows the number of tasks having a given reported implementation time, for tasks estimated to take 7-hour (i.e., 1-day), with main peaks labelled in red (reported times rounded to one decimal place and quarter hours; code+data):
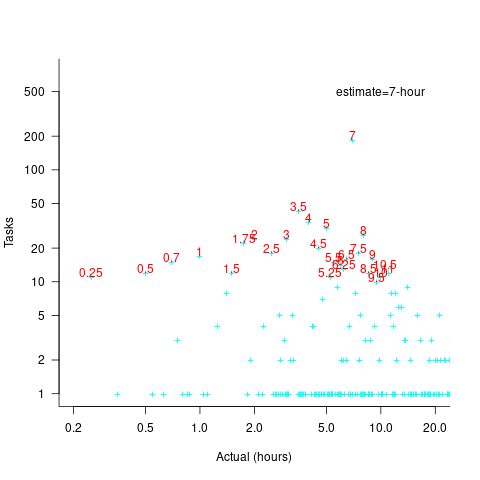
As expected, there are more peaks and implementation times are distributed over a larger range of values.
These plots suggest that many actual times are being rounded to 15-minute intervals. The plot below is based on the minute portion of the reported time (i.e., the hour part is ignored), and shows the fraction of tasks, for estimates of 1, 2, 3, 5, 7, and 14 hours, whose minute component of reported time has a given value (code+data):
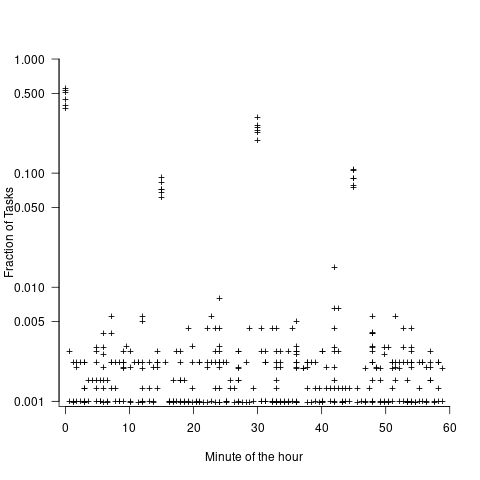
For estimates of a few hours, around 90% of reported task time is on a 15-minute mark, while for 7- and 14-hour tasks the percentage drops to 80%.
If staff are manually entering task finish times, then some degree of rounding is to be expected. When the finish time is indirectly calculated, based on the submission of a completed form, there will be some fuzziness to the rounding number process.
Parkinson’s law, striving to meet a deadline, or happenstance?
How many minutes past the hour was it, when you stopped working on some software related task?
There are sixty minutes in an hour, so if stop times are random, the probability of finishing at any given minute is 1-in-60. If practice (based on the 200k+ time records in the CESAW dataset) the probability of stopping on the hour is 1-in-40, and for stopping on the half-hour is 1-in-48.
Why are developers more likely to stop working on a task, on the hour or half-hour?
Is this a case of Parkinson’s law, or are developers striving to complete a task within a specified time, or are they stopping because a scheduled activity takes priority?
The plot below shows the number of times (y-axis) work on a task stopped on a given minute past the hour (x-axis), for 16 different software projects (project number in blue, with top 10 numbers in red, code+data):

Some projects have peaks at 50, 55, or thereabouts. Perhaps people are stopping because they have a meeting to attend, and a peak is visible because the project had lots of meetings, or no peak was visible because the project had few meetings. Some projects have a peak at 28 or 29, which might be some kind of time synchronization issue.
Is it possible to analyze the distribution of end minutes to reasonably infer developer project behavior, e.g., Parkinson’s law, striving to finish by a given time, or just not watching the clock?
An expected distribution pattern for both Parkinson’s law, and striving to complete, is a sharp decline of work stops after a reference time, e.g., end of an hour (this pattern is present in around ten of the projects plotted). A sharp increase in work stops prior to a reference time could also apply for both behaviors; stopping to switch to other work adds ‘noise’ to the distribution.
The CESAW data is organized by project, not developer, i.e., it does not list everything a developer did during the day. It is possible that end-of-hour work stops are driven by the need to synchronize with non-project activities, i.e., no Parkinson’s law or striving to complete.
In practice, some developers may sometimes follow Parkinson’s law, other times strive to complete, and other times not watch the clock. If models capable of separating out the behaviors were available, they might only be viable at the individual level.
Stop time equals start time plus work duration. If people choose a round number for the amount of work time, there is likely to be some correlation between start/end minutes past the hour. The plot below shows heat maps for start fraction of hour (y-axis) against end fraction of hour (x-axis) for four projects (code+data):
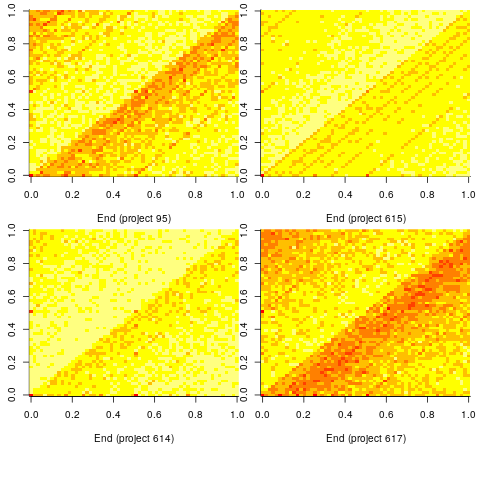
Work durations that are exact multiples of an hour appear along the main diagonal, with zero/zero being the most common start/end pair (at 4% over all projects, with 0.02% expected for random start/end times). Other diagonal lines come from work durations that include a fraction of an hour, e.g., 30-minutes and 20-minutes.
For most work periods, the start minute occurs before the end minute, i.e., the work period does not cross an hour boundary.
What can be learned from this analysis?
The main takeaway is that there is a small bias for work start/end times to occur on the hour or half-hour, and other activities (e.g., meetings) cause ongoing work to be interrupted. Not exactly news.
More interesting ideas and suggestions welcome.
Actual implementation times are often round numbers
To what extent do developers consciously influence the time taken to actually complete a task?
If the time estimated to complete a task is rather generous, a developer has the opportunity to follow Parkinson’s law (i.e., “work expands so as to fill the time available for its completion”), or if the time is slightly less than appears to be required, they might work harder to finish within the estimated time (like some marathon runners have a target time)?
The use of round numbers are a prominent pattern seen in task estimation times.
If round numbers appeared more often in the actual task completion time than would be expected by chance, it would suggest that developers are sometimes working to a target time. The following plot shows the number of tasks taking a given amount of actual time to complete, for project 615 in the CESAW dataset (similar patterns are present in the actual times of other projects; code+data):
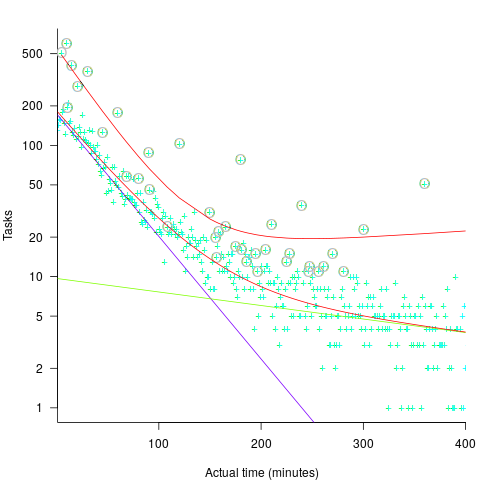
The red lines are a fitted bi-exponential distribution to the ‘spike’ (i.e., round numbers, circled in grey) and non-spike points (spikes automatically selected, see code for details), green and purple lines are the two components of the non-spike fit.
Tasks are not always started and completed in one continuous work session, work may be spread over multiple work sessions; the CESAW data includes the start/end time of every work session associated with each task (85% of tasks involve more than one work session, for project 615). The following plots are based on work sessions, rather than tasks, for tasks worked on over two (left) and three (right) sessions; colored lines denote session ordering within a task (code+data):
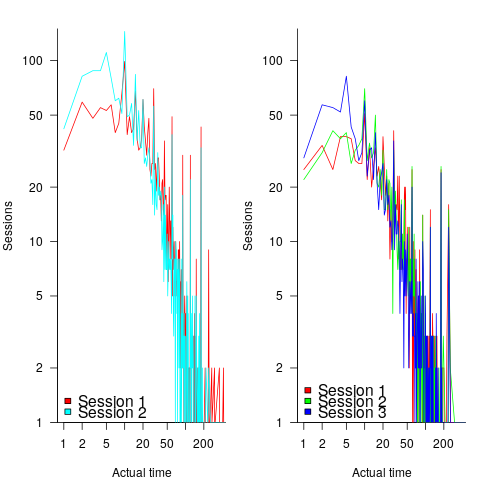
Shorter sessions dominate for the last session of task implementation, and spikes in the counts indicate the use of round numbers in all session positions (e.g., 180 minutes, which may be half a day).
Perhaps round number work session times are a consequence of developers using round number wall-clock times to start and end work sessions. The plot below shows (left) the number of work sessions starting at a given number of minutes past the hour, and (right) the number of work sessions ending at a given number of minutes past the hour; both for project 615 (code+data):

The arrow (green) shows the direction of the mean, and the almost invisible interior line shows that the length of the mean is almost zero. The five-minute points have slightly more session starts/ends than the surrounding minute values, but are more like bumps than spikes. The start of the hour, and 30-minutes, have prominent spikes, which might be caused by the start/end of the working day, and start/end of the lunch break.
Five-minutes is a convenient small rounding interval to either expand implementation time, or to target as a completion time. The following plot shows, for each of the 47 individuals working on project 615, the number of actual session times and the number exactly divisible by five. The green line shows the case where every actual is divisible by five, the purple line where 20% are divisible by five (expected for unbiased timing), the dashed purple lines show one standard deviation, the blue/green line is a fitted regression model ( ) (code+data):
) (code+data):
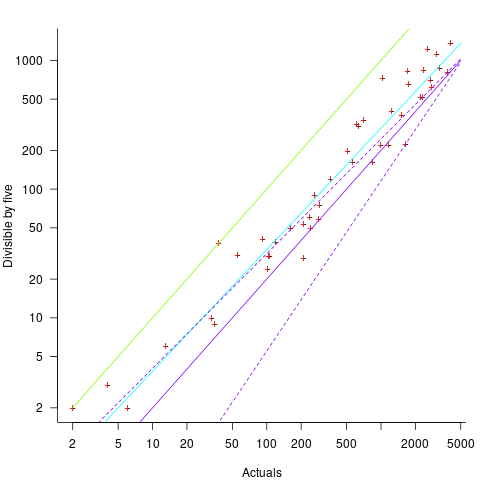
It appears that on average, five-minute session times occur twice as often as expected by chance; two individuals round all their actual session times (ok, it’s not that unlikely for the person with just two sessions).
Does it matter that some developers have a preference for using round numbers when recording time worked?
The use of round numbers in the recording of actual work sessions will inflate the total actual time for most tasks (because most tasks involve more than one session, and assuming that most rounding is not caused by developers striving to meet a target). The amount of error introduced is probably a lot less than the time variability caused by other implementation factors (I have yet to do the calculation).
I see the use of round numbers as a means of unpicking developer work habits.
Given the difficulty of getting developers to record anything, requiring them to record to minute-level accuracy appears at best optimistic. Would you work for a manager that required this level of effort detail (I know there is existing practice in other kinds of jobs)?
Recent Comments