Archive
Example of an initial analysis of some new NASA data
For the last 20 years, the bug report databases of Open source projects have been almost the exclusive supplier of fault reports to the research community. Which, if any, of the research results are applicable to commercial projects (given the volunteer nature of most Open source projects and that anybody can submit a report)?
The only way to find out if Open source patterns are present in closed source projects is to analyse fault reports from closed source projects.
The recent paper Software Defect Discovery and Resolution Modeling incorporating Severity by Nafreen, Shi and Fiondella caught my attention for several reasons. It does non-trivial statistical analysis (most software engineering research uses simplistic techniques), it is a recent dataset (i.e., might still be available), and the data is from a NASA project (I have long assumed that NASA is more likely than most to reliable track reported issues). Lance Fiondella kindly sent me a copy of the data (paper giving more details about the data)!
Over the years, researchers have emailed me several hundred datasets. This NASA data arrived at the start of the week, and this post is an example of the kind of initial analysis I do before emailing any questions to the authors (Lance offered to answer questions, and even included two former students in his email).
It’s only worth emailing for data when there looks to be a reasonable amount (tiny samples are rarely interesting) of a kind of data that I don’t already have lots of.
This data is fault reports on software produced by NASA, a very rare sample. The 1,934 reports were created during the development and testing of software for a space mission (which launched some time before 2016).
For Open source projects, it’s long been known that many (40%) reported faults are actually requests for enhancements. Is this a consequence of allowing anybody to submit a fault report? It appears not. In this NASA dataset, 63% of the fault reports are change requests.
This data does not include any information on the amount of runtime usage of the software, so it is not possible to estimate the reliability of the software.
Software development practices vary a lot between organizations, and organizational information is often embedded in the data. Ideally, somebody familiar with the work processes that produced the data is available to answer questions, e.g., the SiP estimation dataset.
Dates form the bulk of this data, i.e., the date on which the report entered a given phase (expressed in days since a nominal start date). Experienced developers could probably guess from the column names the work performed in each phase; see list below:
Date Created
Date Assigned
Date Build Integration
Date Canceled
Date Closed
Date Closed With Defect
Date In Test
Date In Work
Date on Hold
Date Ready For Closure
Date Ready For Test
Date Test Completed
Date Work Completed |
There are probably lots of details that somebody familiar with the process would know.
What might this date information tell us? The paper cited had fitted a Cox proportional hazard model to predict fault fix time. I might try to fit a multi-state survival model.
In a priority queue, task waiting times follow a power law, while randomly selecting an item from a non-prioritized queue produces exponential waiting times. The plot below shows the number of reports taking a given amount of time (days elapsed rounded to weeks) from being assigned to build-integration, for reports at three severity levels, with fitted exponential regression lines (code+data):
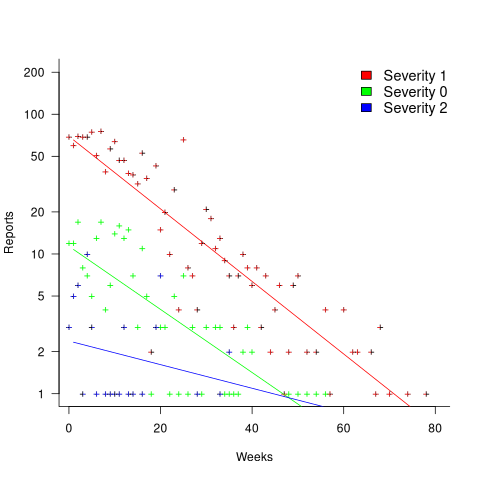
Fitting an exponential, rather than a power law, suggests that the report to handle next is effectively selected at random, i.e., reports are not in a priority queue. The number of severity 2 reports is not large enough for there to be a significant regression fit.
I now have some familiarity with the data and have spotted a pattern that may be of interest (or those involved are already aware of the random selection process).
As always, reader suggestions welcome.
A new NASA software dataset from the 1970s
When modeling the process of software development, to optimise the creation of new projects, the best measurement data to use are those relating to whatever developers are doing today.
Unfortunately, measurement data for software engineering processes is very hard to find; few development groups record anything about what they do, and even when they do the files are rarely kept.
Anybody involved in evidence-based software engineering has to be willing to work with whatever data is available, even when it is for software systems built decades ago.
The usefulness of any measurement data, ancient or recent, is dependent on its relevance to the questions being analysed.
During a recent search for the DACS dataset, I found measurement data for 29 software projects contained in a 1981 NASA report. While the projects happened decades ago (1975-1981) for a niche application (software for spacecraft), the measurement data is much more extensive than usual, containing background information on many of the projects; given the rarity of software project data from this period, the 47 rows of data on each project, in Table 3.1-1, looked interesting enough to extract and analyse (output from Amazon’s usually robust Textract needed some hours of manual post-processing; code+data).
While this data is not of immediate use, I will invariably get involved in a discussion, or analysis, where this dataset will be a big improvement on nothing.
Are there any points to note?
- there is a linear relationship between the totals of programmer hours and management hours, with an average of 4.4 programmer hours per management hour. This sounds low, but these projects are developing embedded software and there are likely to be many stakeholders,
- the average percentage of time spent in each phase of the Waterfall process used was: Design 31%, Code-Test 29%, System testing 11%, Acceptance testing 10%, Cleanup 20%. Lots of testing is to be expected for spacecraft software,
- the average number of project source lines was 34k. I don’t know whether this is high or low, NASA press releases invariably cite the total amount of code on the spacecraft.
It’s worth noting that this small dataset is of a size and project detail that was used by researchers in the 1970s/1980s to validate software theories that are still with us today, e.g., the COCOMO estimation model, the McCabe metrics were not validated on any data, and the Halstead metrics were checked using multiple datasets each of similar size. I suspect that many of these datasets also came from DOD or NASA projects.
A disheartening Space Apps hackathon
Every hackathon has its share of crazies, fortunately they rarely achieve sufficient critical mass to bother anybody else, generally wandering harmlessly around the venue. Hackathons involving outer space attracts crazies in droves and much of the first day is spent with everybody floating around in zero gravity.
This morning I stopped by the NASA SpaceApp hackathon in London to pick up my pass, say hi to a few people I knew were going and let them know I would be back later. A computational semantics hackathon was happening a few miles away, but finishing for the day at five (I know, academic hackathons). My plan was do interesting language analysis stuff, giving the crazies plenty of time to save the world (and then leave), before I returned to spend the rest of the weekend hacking on something space’ish.
The computational semantics hack was as interesting as it promised to be and I’m returning to it tomorrow (not the original plan).
I returned to the SpaceApp hack to find that while most of the crazies had gone, a lot of developers had also left. Had the crazies caused those with a firmer grip on reality to flee to the hills? The lack of coffee (yes, I did check several times that there were no plans to supply any coffee for the duration) and the wifi not being able to support everybody could not have helped. The few developers left (a fare few engineers, designers and ‘ideas’ people were still there) seemed to have been reduced to nibbling away at uninteresting bits (to me at least) of big problems. I left disheartened.
I think that part of the reason that non-crazies have trouble connecting with NASA’s proposed plans is that it is hard to tell the difference between NASA and the crazies. NASA’s mission has always been about politics first and science second. First as a means of boosting the US image around the world (the moon landing years) and then as a means of pork-barrel funding for favored politicians. To keep serious funding rolling in NASA has to ignite the public imagination. Fortunately for them the public is not very good at working out the economics of the proposed ventures (e.g., Google search on economics of asteroid mining to find plenty of articles exposing the economics flaws of this proposal).
While I am happy for the US taxpayer to funding NASA to do interesting space stuff and share it with the rest of the world, I do wish they could do it in a way that made technical and economic sense (I have no problem with them feeding the crazies, who have as much right to enjoy hackathons as the rest of us).
Recent Comments