Archive
Half-life of Microsoft products is 7 years
I get a lot of pushback from developers/managers when I tell them that the average application has a relatively short lifetime, i.e., half-life of 4-8 years. The pushback kicks in when I start citing data, up until then my listeners appear surprised/skeptical. The fact that source code has a brief and lonely existence is accepted, but telling them about the (one study) evidence that a coding mistake is more likely to disappear because of an unrelated coding change than as a result of fixing a fault report appears to make them feel uncomfortable.
Some applications live a long time, and most developers will spend most of their time working on long-lived applications. Short-lived applications are not around long enough to acquire significant developer/manager mind share.
I think the pushback is rooted in more than developer experience; developers don’t like the thought of their work disappearing from the world. The desire for permanence in what we create may be a human characteristic. Extolling the creation of reliable, maintainable, readable code creates an implicit assumption that applications are going to live long enough for the cost of these activities to be paid back.
How accurate are these half-life estimates?
The 4-8 year half-life range is derived from two datasets. A while ago I spotted another dataset: Fabiano Riccardi‘s Killed by Microsoft, currently containing information on 141 killed products.
All three datasets list just the products that have been killed, i.e., they are not a list of all products. A half-life calculation based only on killed products could underestimate the actual lifetime, it depends on whether the rate of killed products remains roughly the same percentage of all products or not. If the number of products killed, in any period, is always roughly the same percentage of all current products, then the calculated lifetime is not affected by the lack of data on the number of live products. Uncertainty in the calculated lifetime is created when the number of products killed is unconnected with the current number of live products.
It’s possible, to save money, products are more likely to be killed when a company is going through a period of poor performance, or the economy is in recession, compared to when business is booming.
Another source of uncertainty is sampling bias. Companies announce when products are released/withdrawn, creating recency bias because it’s easier to monitor the news than actively search for data on past product releases/withdraws. The plot below shows the number of products Microsoft killed in each year (red bars; post 2025 are to be killed-by dates) and number of new products launched each year blue/green line (code+data):
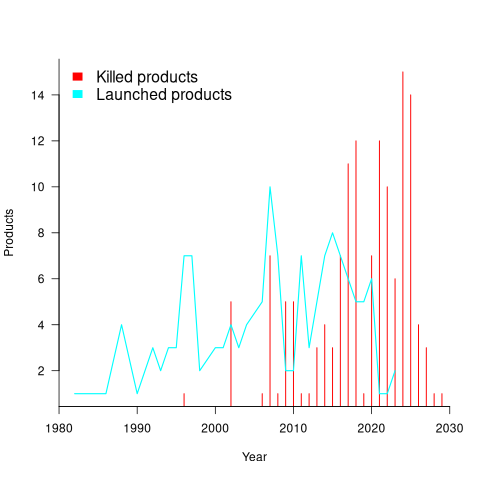
I’m sure that Microsoft killed more than one product before 2000. The Dot-com bubble burst in March 2000, and I would expect this to have resulted in lots of killed products. The lack of data on products killed before 2000 means that shorter lived products are undercounted.
The plot below shows the number of Microsoft (eventually killed) products still supported a given number of years after launch, the red line is a regression fit for products aged between 4 months and 22 years (code+data):
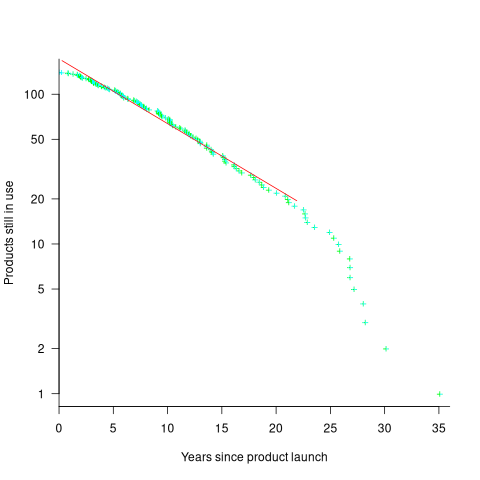
The half-life of the Microsoft products in this dataset, aged between 4 months and 22 years, is 7 years. Is the sharp decline in half-life after 22 years a real thing, or a consequence of the small amount of data before 2005? As always, more data is needed.
Relative sizes of computer companies
How large are computer companies, compared to each other and to companies in other business areas?
Stock market valuation is a one measure of company size, another is a company’s total revenue (i.e., total amount of money brought in by a company’s operations). A company can have a huge revenue, but a low stock market valuation because it makes little profit (because it has to spend an almost equally huge amount to produce that income) and things are not expected to change.
The plot below shows the stock market valuation of IBM/Microsoft/Apple, over time, as a percentage of the valuation of tech companies on the US stock exchange (code+data on Github):
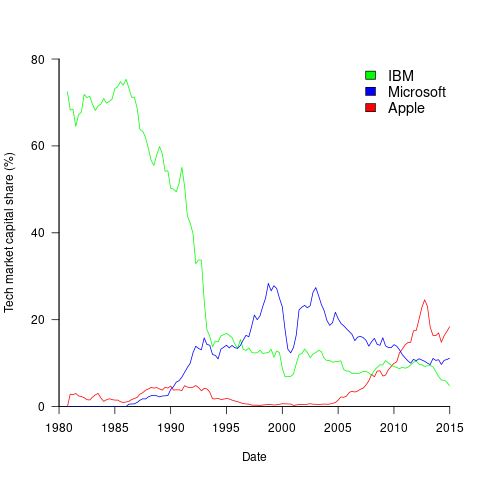
The growth of major tech companies, from the mid-1980s caused IBM’s dominant position to dramatically decline, while first Microsoft, and then Apple, grew to have more dominant market positions.
Is IBM’s decline in market valuation mirrored by a decline in its revenue?
The Fortune 500 was an annual list of the top 500 largest US companies, by total revenue (it’s now a global company list), and the lists from 1955 to 2012 are available via the Wayback Machine. Which of the 1,959 companies appearing in the top 500 lists should be classified as computer companies? Lacking a list of business classification codes for US companies, I asked Chat GPT-4 to classify these companies (responses, which include a summary of the business area). GPT-4 sometimes classified companies that were/are heavy users of computers, or suppliers of electronic components as a computer company. For instance, I consider Verizon Communications to be a communication company.
The plot below shows the ranking of those computer companies appearing within the top 100 of the Fortune 500, after removing companies not primarily in the computer business (code+data):
![]()
IBM is the uppermost blue line, ranking in the top-10 since the late-1960s. Microsoft and Apple are slowly working their way up from much lower ranks.
These contrasting plots illustrate the fact that while IBM continued to a large company by revenue, its low profitability (and major losses) and the perceived lack of a viable route to sustainable profitability resulted in it having a lower stock market valuation than computer companies with much lower revenues.
When will Microsoft stop bothering to sell compilers?
The amount of money Microsoft make from selling compilers is peanuts compared to the profits from their Office and OS products (they may even lose money), and this will never change.
In the 80s, when the IBM PC was first introduced and began to take over the computing world, the Microsoft C compiler was not the market leader and not the favorite among developers who had a choice (large companies preferred to buy from large companies and so Microsoft C did well in the corporate market).
The developer market back then was not large and companies selling compilers soon found themselves selling into a saturated market, and many disappeared.
C++ came along and compiler companies jumped on this bandwagon, giving them a new product to sell for a few years.
As an OS vendor, Microsoft needed its own compiler to appear credible to developers. The libraries (the one part of the compiler suite that everybody liked) came along for free, courtesy of being an OS vendor. The IDE, Visual Studio, has grown on developers over time and has gotten a lot better. Visual C++ became the dominant Windows compiler because it was the last man standing.
Like all compilers, Visual C++ supports its own way of doing things in various parts of the language. Use of compiler language foibles are the mechanism by which application developers build porting cost barriers, to other compilers, into their code. Any large application built using Visual C++ will need a lot of effort to port to another compiler, a benefit for Microsoft.
The porting cost generated by compiler differences is a two-way street. Porting applications from another compiler to Visual C++ could be just as expensive as porting from Visual C++.
Microsoft can remove the cost of porting to Windows by supporting llvm within Visual Studio (I don’t ever see them supporting gcc for licensing reasons), plus command line support so that existing make files work and at the end of last year they sort of did just that (they bolted the llvm C/C++ front end onto the code generators for Visual C++; they obviously did not want to cause embarrassment by making it easy for developers to compare the performance of generated code ;-).
There is a large potential downside for Microsoft supporting llvm, it provides an in-your-face opportunity for current Visual C++ users to try another compiler (I suspect a goodly number have never touched any other C+ compiler). The problem with existing Visual C++ user accessing other compilers is not about code quality (Microsoft compilers have never been known for generating the fastest code), it is about making it easy for developers to learn how to make their code portable to other compilers.
Why would a company want to support a version of its product that compiles with Visual C++ abd a version that compiles with llvm? In the short term expediency, but in the long term it makes sense to use a single compiler.
Microsoft has ported it’s Office products to non-Windows platforms. Was Visual C++ involved? Using Visual C++ would have meant extending it to support the language extensions that occur in the headers files present on other platforms. There are advantages to using the compiler used to build the OS and I suspect this is what the Office team did (I don’t have any inside knowledge).
Is the only long term customer of Visual C++ the Windows development group? I wonder how hard it would be to tweak Windows+llvm so that one could build the other?
The writing is on the wall for Visual C++; how long does it have? Five years, 10?
I would not be surprised if there are a few very large customers, with many millions of lines of code they do not want to touch, who would put up the money to keep the development group on life support. Visual studio could be around 50 years from now, kept alive by the need to compile huge dinosaurs that are not quite important enough or cause enough grief to warrant rewriting. Perhaps it will end up being the oldest commercial compiler still in production use.
Will programming languages now have to follow ISO fast-track rules?
A while back I wrote about how updated versions of ECMAscript (i.e., the Standard for Javascript) had twice been fast tracked to replace an existing ISO Standard, however the ISO rules require that once a document becomes one of its standards all future work be done using the ISO process (i.e., you only supposed to get the one original fast track and then you have to get at least half a dozen countries to say they will actively participate in ongoing work). Thirteen years after I asked why it was being allowed to happen (as I recall I only raised the issue because I thought I had misunderstood the rules, not because I had a burning desire to enforce them) the issue has suddenly sprung to life (we are talking Standard’s world ‘sudden’ here), with a question being raised at the last SC22 meeting and a more detailed one being prepared by BSI for the next meeting (they occur once per year).
The Elephant in the room here is ISO/IEC 29500:2008, not a programming language but Microsoft’s Office Open XML; there was quite a bit of fuss when this was fast tracked.
If the ISO rules on one-time only use of the fast track process was limited to programming languages I imagine the bureaucrats in Geneva would probably never get to hear about it (SC22 would probably conclude that there was not enough interest in the various documents outside of the submitting country to form an active ISO working group; so leave well alone).
ISO sells over 19,000 standards and has better things to do than spend time on the goings on in an unfashionable part of the galaxy, unless, that is, it has the potential to generate lots of fuss that undermines credibility.
Will Microsoft try to fast track an updated version of ISO 29500? I don’t even know if they are updating it. The possibility that ISO 29500 might be updated and submitted for fast track will make it hard for SC22 to agree to any future fast-track updates to existing ISO Standards it is responsible for.
The following is a list of documents that have been fast tracked to become an ISO Standard:
ECMAScript: ECMA-262 (1st edn) = ISO 16262:1998 ECMA-262 (3rd edn) = ISO 16262:1999 ECMA-262 (5th edn) = ISO 16262:2011 C#: ECMA-334 (2nd edn) = ISO 23270:2003 ECMA-334 (4th edn) = ISO 23270:2006 CLI: ECMA-335 (2nd edn) = ISO 23271:2003 ECMA-335 (6th edn) = ISO 23271:2012 ECMA standards fast-tracked to ISO and not yet revised: ECMA-149 PCTE part 1 = ISO 13719-1:1998 ECMA-158 PCTE part 2 = ISO 13719-2:1998 ECMA-162 PCTE part 3 = ISO 13719-3:1998 ECMA-230 PCTE IDL binding = ISO 13719-4:1998 ECMA-367 EIFFEL = ISO 25436:2006 ECMA-372 C++/CLI -> DIS 26926; failed DIS ballot and project cancelled Replaced rather than revised under JTC1 rules: CHILL (from CCITT): ISO standards 9496:1989, 9496:1995, 9496:1998, 9496:2003 MUMPS/M (from Mass Gen Hospital/ANSI): ISO standards 11756:1992, 11756:1999 Non-ECMA documents fast-tracked through ISO and not yet revised: FORTH (from FORTH Inc): ISO 15145:1997 JEFF (from J consortium): ISO 20970:2002 Ruby (from Japanese Industrial Standards Committee): ISO/IEC 30170:2012
Popularity of Open source Operating systems over time
Surveys of operating system usage trends are regularly published and we get to read about how the various Microsoft products are doing and the onward progress of mobile OSs; sometimes Linux gets an entry at the bottom of the list, sometimes it is just ‘others’ and sometimes it is both.
Operating systems are pervasive and a variety of groups actively track reported faults in order to issue warnings to the public; the volume of OS fault informations available makes it an obvious candidate for testing fault prediction models (e.g., how many faults will occur in a given period of time). A very interesting fault history analysis of OpenBSD in a paper by Ozment and Schechter recently caught my eye and I wondered if the fault time-line could be explained by the time-line of OpenBSD usage (e.g., more users more faults reported). While collecting OS usage information is not the primary goal for me I thought people would be interested in what I have found out and in particular to share the OS usage data I have managed to obtain.
How might operating system usage be measured? Analyzing web server logs is an obvious candidate method; when a web browser requests information many web servers write information about the request to a log file and this information sometimes includes the name of the operating system on which the browser is running.
Other sources of information include items sold (licenses in Microsoft’s case, CDs/DVD’s for Open source or perhaps books {but book sales tend not to be reported in the way programming language book sales are reported}) and job adverts.
For my time-line analysis I needed OpenBSD usage information between 1998 and 2005.
The best source of information I found, by far, of Open source OS usage derived from server logs (around 138 million Open source specific entries) is that provided by Distrowatch who count over 700 different distributions as far back as 2002. What is more Ladislav Bodnar the founder and executive editor of DistroWatch was happy to run a script I sent him to extract the count data I was interested in (I am not duplicating Distrowatch’s popularity lists here, just providing the 14 day totals for OS count data). Some analysis of this data below.
As luck would have it I recently read a paper by Diomidis Spinellis which had used server log data to estimate the adoption of Open Source within organizations. Diomidis researches Open source and was willing to run a script I wrote to extract the User Agent string from the 278 million records he had (unfortunately I cannot make this public because it might contain personal information such as email addresses, just the monthly totals for OS count data, tar file of all the scripts I used to process this raw log data; the script to try on your own logs is countos.sh).
My attempt to extract OS names from the list of User Agent strings Diomidis sent me (67% of of the original log entries did contain a User Agent string) provides some insight into the reliability of this approach to counting usage (getos.awk is the script to try on the strings extracted with the earlier script). There is no generally agreed standard for:
- what information should be present; 6% of UA strings contained no OS name that I knew (this excludes those entries that were obviously robots/crawlers/spiders/etc),
- the character string used to specify a given OS or a distribution; the only option is to match a known list of names (OS names used by Distrowatch,
missos.awkis the tar file script to print out any string not containing a specified list of OS names, the Wikipedia List of operating systems article), - quality assurance; some people cannot spell ‘windows’ correctly and even though the source is now available I don’t think anybody uses CP/M to access the web (at least 91 strings,
 %, would not have passed).
%, would not have passed).
Ladislav Bodnar thinks that log entries from the same IP addresses should only be counted once per day per OS name. I agree that this approach is much better than ignoring address information; why should a person who makes 10 accesses be counted 10 times, a person who makes one access is only counted once. It is possible that two or more separate machines running the same OS are accessing the Internet through a common gateway that results in them having the IP address from an external server’s point of view; this possibility means that the Distrowatch data undercounts the unique accesses (not a serious problem if most visitors have direct Internet access rather than through a corporate network).
The Distrowatch data includes counts for all IP address and from 13 May 2004 onwards unique IP address per day per OS. The mean ratio between these two values, summed over all OS counts within 14 day periods, is 1.9 (standard deviation 0.08) and the Pearson correlation coefficient between them is 0.987 (95% confidence interval is 0.984 to 0.990), i.e., almost perfect correlation.
The Spinellis data ignores IP address information (I got this dataset first, and have already spent too much time collecting to do more data extraction) and has 10 million UA strings containing Open source OS names (6% of all OS names matched).
How representative are the Distrowatch and Spinellis data? The data is as representative of the general OS population as the visitors recorded in the respective server logs are representative of OS usage. The plot below shows the percentage of visitors to Distrowatch that use Ubuntu, Suse, Redhat. Why does Redhat, a very large company in the Open source world, have such a low percentage compared to Ubuntu? I imagine because Redhat customers get their updates from Redhat and don’t see a need to visit sites such as Distrowatch; a similar argument can be applied to Suse. Perhaps the Distrowatch data underestimates those distributions that have well known websites and users who have no interest in other distributions. I have not done much analysis of the Spinellis data.
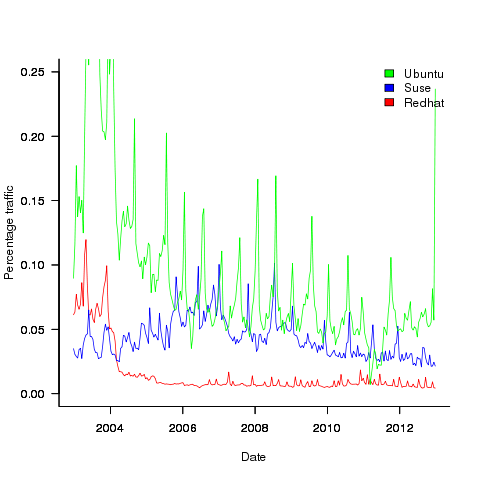
Presumably the spikes in usage occur around releases of new versions, I have not checked.
For my analysis I am interested in relative change over time, which means that representativeness and not knowing the absolute number of OSs in use is not a problem. Researchers interested in a representative sample or estimating the total number of OSs in use are going to need a wider selection of data; they might be interested in the following OS usage information I managed to find (yes I know about Netcraft, they charge money for detailed data and I have not checked what the Wayback Machine has on file):
- Wikimedia has OS count information back to 2009. Going forward this is a source of log data to rival Distrowatch’s, but the author of the scripts probably ought to update the list of OS names matched against,
- w3schools has good summary data for many months going back to 2003,
- statcounter has good summary data (daily, weekly, monthly) going back to 2008,
- TheCounter.com had data from 2000 to 2009 (csv file containing counts obtained from Wayback Machine).
If any reader has or knows anybody who has detailed OS usage data please consider sharing it with everybody.
Number of possible different one line programs
Writing one line programs is a popular activity in some programming languages (e.g., awk and Perl). How many different one line programs is it possible to write?
First we need to get some idea of the maximum number of characters that written on one line. Microsoft Windows XP or later has a maximum command line length of 8191 characters, while Windows 2000 and Windows NT 4.0 have a 2047 limit. POSIX requires that _POSIX2_LINE_MAX have a value of at least 2048.
In 2048 characters it is possible to assign values to and use at least once 100 different variables (e.g., a1=2;a2=2.3;....; print a1+a2*a3...). To get a lower bound lets consider the number of different expressions it is possible to write. How many functionally different expressions containing 100 binary operators are there?
If a language has, say, eight binary operators (e.g., +, -, *, /, %, &, |, ^), then it is possible to write  visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g.,
visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g., + * can also be written as * + (the appropriate operands will also have the be switched around).
If we just consider expressions created using the commutative operators (i.e., +, *, &, |, ^), then with these five operators it is possible to write 1170671511684728695563295535920396 mathematically different expressions containing 100 operators (assuming the common case that the five operators have different precedence levels, which means the different expressions have a one to one mapping to a rooted tree of height five); this  is a lot smaller than
is a lot smaller than  .
.
Had the approximately  computers/smart phones in the world generated expressions at the rate of
computers/smart phones in the world generated expressions at the rate of  per second since the start of the Universe,
per second since the start of the Universe,  seconds ago, then the
seconds ago, then the  created so far would be almost half of the total possible.
created so far would be almost half of the total possible.
Once we start including the non-commutative operators such a minus and divide the number of possible combinations really starts to climb and the calculation of the totals is real complicated. Since the Universe is not yet half way through the commutative operators I will leave working this total out for another day.
Update (later in the day)
To get some idea of the huge jump in number of functionally different expressions that occurs when operator ordering is significant, with just the three operators -, / and % is is possible to create  mathematically different expressions. This is a factor of
mathematically different expressions. This is a factor of  greater than generated by the five operators considered above.
greater than generated by the five operators considered above.
If we consider expressions containing just one instance of the five commutative operators then the number of expressions jumps by another two orders of magnitude to  . This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
. This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
Update (April 2012).
Sequence A140606 in the On-Line Encyclopedia of Integer Sequences lists the number of inequivalent expressions involving n operands; whose first few values are: 1, 6, 68, 1170, 27142, 793002, 27914126, 1150212810, 54326011414, 2894532443154, 171800282010062, 11243812043430330, 804596872359480358, 62506696942427106498, 5239819196582605428254, 471480120474696200252970, 45328694990444455796547766, 4637556923393331549190920306
Ruby becoming an ISO Standard
The Ruby language is going through the process of becoming an ISO Standard (it has been assigned the document number ISO/IEC 30170).
There are two ways of creating an ISO Standard, a document that has been accepted by another standards’ body can be fast tracked to be accepted as-is by ISO or a committee can be set up to write the document. In the case of Ruby a standard was created under the auspices of JISC (Japanese Industrial Standards Committee) and this has now been submitted to ISO for fast tracking.
The fast track process involves balloting the 18 P-members of SC22 (the ISO committee responsible for programming languages), asking for a YES/NO/ABSTAIN vote on the submitted document becoming an ISO Standard. NO votes have to be accompanied by a list of things that need to be addressed for the vote to change to YES.
In most cases the fast tracking of a document goes through unnoticed (Microsoft’s Office Open XML being a recent high profile exception). The more conscientious P-members attempt to locate national experts who can provide worthwhile advice on the country’s response, while the others usually vote YES out of politeness.
Once an ISO Standard is published future revisions are supposed to be created using the ISO process (i.e., a committee attended by interested parties from P-member countries proposes changes, discusses and when necessary votes on them). When the C# ECMA Standard was fast tracked through ISO in 2005 Microsoft did not start working with an ISO committee but fast tracked a revised C# ECMA Standard through ISO; the UK spotted this behavior and flagged it. We will have to wait and see where work on any future revisions takes place.
Why would any group want to make the effort to create an ISO Standard? The Ruby language designers reasons appear to be “improve the compatibility between different Ruby implementations” (experience shows that compatibility is driven by customer demand not ISO Standards) and government procurement in Japan (skip to last comment).
Prior to the formal standards work the Rubyspec project aimed to create an executable specification. As far as I can see this is akin to some of the tools I wrote about a few months ago.
IST/5, the committee at British Standards responsible for language standards is looking for UK people (people in other countries have to contact their national standards’ body) interested in getting involved with the Ruby ISO Standard’s work. I am a member of IST/5 and if you email me I will pass your contact details along to the chairman.
Using evolution to reduce competition
The Microsoft purchase of Skype got me thinking back to my time as an advisor to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case. The Commission wanted to introduce competition into the Windows Work Group server market and it hoped that by requiring Microsoft to license all of the necessary communication protocols companies would produce products that were plug-compatible with Microsoft products. The major flaw in this plan turned out to be economics, we estimated it would cost around £100 million to implement the protocols and making a worthwhile profit on this investment looked decidedly problematic.
Microsoft’s approach to publishing protocol specifications went through three stages: 1) doing everything they could not to do it, 2) following the judgment handed down by the court, 3) actively documenting additional protocols and making all the documents publicly available. Yes, as the documentation process progressed Microsoft started to see the benefits of having English prose documentation (previously the documentation was the source code) but I suspect the switch from (2) to (3) was made possible by the economic analysis that implied there would not be any competition in the server market.
Skype have not made their client/server protocols public, will Microsoft do so? I suspect not because there is no benefit for them to do so. Also I’m sure that Microsoft will want to steer clear of antitrust authorities and will not be making Skype an integral part of Windows’ internal functionality.
What progress has been made in reverse engineering the Skype protocols? There is a community of people trying to figure them out but they have not made the progress that enabled Andrew Tridgell to quickly get something useful up and running that could then evolve into a full blown implementation of a Microsoft protocol.
What lesson can Skype product managers learn from the Microsoft experience of having to make their proprietary protocols available to third parties? I don’t think Microsoft intentionally did any the following:
- Don’t write any English prose documentation; ensure that the source code is the only specification of the protocols. This will make it easier for point 3) to occur,
- proprietary protocols are your friend, even designing ‘better’ alternatives to non-proprietary protocols,
- don’t put too much of a brake on evolution, i.e., allow developers to do what they always want to do which is to make quick fixes to the code and tweak it here and there resulting in a tangle that cannot be simplified. This will significantly drive up third-party costs as they will not be able to create a product handling a useful subset (i.e., they will have to implement everything) and the tangle make sit harder form them to sure that what they have done is correct.
What might be the short term costs of following this strategy? Very good developers are used to learning by reading code (lack of documentation is a fact of life for may of them). Experience has shown that allowing developers to make quick fixes and tweak code often results in difficult to maintain code (ok, so a small group of developers have to be paid above the market rate to ensure access to their code memory). If developers really do dig themselves into a very large hole it is always possible to completely redesign the protocols and provide a very major upgrade (Skype can always reinvent its own protocols, an option not available to third parties which have to follow slavishly behind; this option has always been open to Microsoft with its protocols, i.e., the courts did not place any restrictions on protocol changes).
Where did the £100 million figure come from? The problem of estimating development cost was approached from various angles. The one I used was to estimate the number of requirements at 50,000 (there are 38,158 MUSTs in the first public release of the documents) of which 1,651 occur in the SMB specification for which there is a 450KLOC implementation (i.e., samba source in 2006), giving an estimate of (50000/1651)*450K -> 13.6 MLOC in the final implementation. At £10 per line we get a bit more than £100 million.
Predictions for 2009
If the shape of code does change over time, it changes very slowly. Styles become more or less popular, but again the time-scale is generally longer than a year. Anyway, here are my predictions for goings on the in the community that shapes code.
1) Functional programming will continue to entrance the young whose idealism will continue to be dashed when they have to deal with the real world. Ok, I started with something obvious that will still be true in 20 years and I promise not to to to keep repeating myself on this one every year.
2) The LLVM project will die. I am surprised that it has lasted this long, but it is probably costing Apple so little that it is not on management’s radar. Who needs another C compiler; perhaps 10 years ago they could have given the moribund gcc project a run for its money, but an infusion of keen people and a complete reworking of its internals has kept gcc as the leading contender to be the only C compiler developers use in 10 years time.
3) Static analysis will go mainstream. The driving force will not be developers loosing their aversion to being told of their mistakes, but because the world’s economic predicament will force them to deliver better performance in less time, ie they will be forced to use tools to help them find coding faults. The fact that various groups are starting to add hooks to the mainstream compilers (e.g., Microsoft’s Phoenix, gcc’s Dehydra), ensuring compatibility with an existing code base and making it easier for developers use, also helps. The gcc people may yet shoot themselves in the foot. Of course people will continue to develop new stand-alone tools and extract money from government to do something that sounds useful.
4) Natural language programming will finally gain a foothold. One of the big unnoticed announcements of the year was the Attempto project releasing the source code of their controlled English system.
5) The rate of gcc’s progress to world domination will accelerate. There are still quite a few market niches where gcc is a minority player (eg, embedded systems) and various compilers need to disappear for it to gain market share. Compiler writing has never been a very profitable business and compiler companies usually go bust or are taken over by hardware vendors looking for customer lock-in. The current economic situation means that compiler companies are both more likely to go bust and to not be brought, ie, their compilers will (commercially) disappear.
6) The number of people involved in writing software will continue to decline in the West and increase in the East. These days there is not a lot of difference in cost between east/west, it is the quality of developers (or rather there are more of a reasonable standard available). The declining standards in science/engineering education is the driving factor, the economic situation is just creating extra exposure.
Recent Comments