Archive
How has the price of a computer changed over time?
We are told that computers are now orders of magnitude cheaper than they once were. Computers have changed an awful lot over the last 70 years; how is the functionality supported by different computers normalised such that the price of computers from long ago can be compared with today’s computers?
One approach is to narrow the question down to calculating the cost of performing some basic operation, e.g., numerical calculation or sorting a list of values. Nordhaus’s famous paper: Two Centuries of Productivity Growth in Computing uses this approach.
The primary advantage of the cost-of-operation approach is that it can be made to work across the complete range of computing platforms. The major disadvantage of this approach is that it focuses on the performance of the cpu/memory, ignoring the ability to store large amounts of data and perform I/O (which is most of the cost of some computer systems).
The US consumer price index (CPI) uses Hedonic regression to adjust the average price of a product family whose quality changes over time (the CPI is used to track inflation, and so every price needs to be for a product identical to the exemplar chosen at some start date). Hedonic pricing models are also used to understand how specific features within a product category (e.g., housing, automobiles, or electronics) contribute to the price. The term hedonic is derived from hedonism, and was first used in a 1939 paper analysing the price/quality of automobiles.
The 1979 paper “Hedonic Prices and the Structure of the Digital Computer Industry” by R. Michaels (cannot find a downloadable copy) appears to have kick-started the computer/hedonic research rabbit hole (the 1969 book “The Economics of Computers” by W. F. Sharpe covers computer costings in detail). Hedonic regression estimates the value of a product by braking it down into its major components which are used as the explanatory variables in a regression model that predicts the product price on given dates, e.g., for mainframe computers: price, cpu speed, amount of memory, number/size of hard disks, number of tape drives and card readers.
While mainframes and microcomputers share some characteristics (e.g., cpu, memory, and discs), they address different markets with very different requirements (e.g., mission-critical requires high reliability and tape backups). Different Hedonic regression models need to be fitted for each.
Gathering a representative sample of information on all the major components of a product, preferably for each year, is a lot of work. Many papers make use of information from proprietary databases. A lot of historical information is now available in scanned trade publications, but LLMs are not yet good enough to reliably extract detailed information from scanned documents (e.g., they sometimes ignore information, rather than hallucinating). I am waiting for the error rate to decrease.
The analysis in the book chapter Computer Processors and Peripherals by R. J. Gordon spends a lot of time dealing with the issues around potentially inconsistent data sources. The final price index (table 6.7) shows that the normalised price of mainframes decreased by a factor of 922 between 1951 and 1983 (23% per year, for 33 years). That is, the equivalent 1951 mainframe purchased in 1983 would have been cheaper by a factor of 922. In practice, prices did not decrease by a factor of 922, rather some combination of price/quality of the average mainframe changed by this factor (where quality is some combination of faster cpus, more memory and other factors). For an analysis of computer related products see the book “Price Measurements and Their Uses” by Foss, Manser, and Young.
The price of microcomputers (or computers as we call them today, as there is little public perception of any other type of computer) has decreased, but by how much (in the Hedonic sense)?
The first Hedonic analysis of microcomputers was Cohen’s 1988 Master’s thesis, for personal computers between 1976 and 1987. I think Cohen is pushing product family boundaries to treat the 8-bit computers introduced before the IBM PC in August 1981 (which did not include a hard disk until 1983, and did not really become a 16-bit computer until the IBM AT in 1987) as being comparable with later microcomputers. Cohen’s analysis found positive/negative swings in the adjusted prices of the microcomputers.
The paper Price and quality of desktop and mobile personal computers: A quarter-century historical overview by Berndt, Dulberger and Rappaport claim that there was an average annual 27% decline in microcomputer prices between 1976 and 1999. Again, my comments on pre-1987 microcomputers applies. A later paper (appendix table 1) shows average actual prices increasing until 1991 and decreasing thereafter, with the averages of cpu frequency, memory capacity and hard disk size continually increasing. There was little difference in the prices at the start(1976)/end(2002) of the period analysed, but a huge difference in the quality characteristics. While writing my Evidence-based software engineering book, I emailed Berndt for the data, which a co-author kindly made available. Unfortunately, I found that much of the data was confidential (the name of a company that sold computer sales data appeared in the files), and could not be publicly shared 🙁
Hedonic analysis of computers appears to have become unfashionable around the start of 2000. More recent papers analyse products such as mobile phones and cloud services. Please leave a comment if you know of any recent hedonic analysis of computer prices.
The only detailed microcomputer price data I know of consists of 6,259 detailed prices collected by Stengos, and Zacharias over 35 months, starting in January 1993, from the adverts in PC Magazine.
Analyzing mainframe data in light of the IBM antitrust cases
Issues surrounding the decades of decreasing cost/increasing performance of microcomputers, powered by Intel’s x86/Pentium have been extensively analysed. There has been a lot of analysis of pre-Intel computers, in particular Mainframe computers. Is there any major difference?
Mainframes certainly got a lot faster throughout the 1960s and 1970s, and the Computer and Automation’s monthly census shows substantial decreases in rental prices (the OCR error rate is not yet low enough for me to be willing to spend time extracting 300 pages of tabular data).
During the 1960s and 1970s the computer market was dominated by IBM, whose market share was over 70% (its nearest rivals, Sperry Rand, Honeywell, Control Data, General Electric, RCA, Burroughs, and NCR, were known as the seven dwarfs).
While some papers analyzing the mainframe market do mention that there was an antitrust case against IBM, most don’t mention it. There are some interesting papers on the evolution of families of IBM products, but how should this analysis be interpreted in light of IBM’s dominant market position?
For me, the issue of how to approach the interpretation of IBM mainframe cost/performance/sales data is provided by the book The U.S. Computer Industry: A Study of Market Power by Gerald Brock.
Brock compares the expected performance of a dominant company in a hypothetical computer industry, where anticompetitive practices do not occur, with IBM’s performance in the real world. There were a variety of mismatches (multiple antitrust actions have found IBM guilty of abusing its dominant market power).
Any abuse of market power by IBM does not impact the analysis of computer related issues about what happened in the 1950s/1960s/1970, but the possibility of this behavior introduces uncertainty into any analysis of why things happened.
Intel also had its share of antitrust cases, which will be of interest to people analysing the x86/Pentium compatible processor market.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Half-life of software as a service, services
How is software used to provide a service (e.g., the software behind gmail) different from software used to create a product (e.g., sold as something that can be installed)?
This post focuses on one aspect of the question, software lifetime.
The Killed by Google website lists Google services and products that are no more. Cody Ogden, the creator of the site, has open sourced the code of the website; there are product start/end dates!
After removing 20 hardware products from the list, we are left with 134 software services. Some of the software behind these services came from companies acquired by Google, so the software may have been used to provide a service pre-acquisition, i.e., some calculated lifetimes are underestimates.
The plot below shows the number of Google software services (blue) having a given lifetime (calculated as days between Google starting/withdrawing service), mainframe software from the 1990s (red; only available at yearly resolution), along with fitted exponential regression lines (code+data):
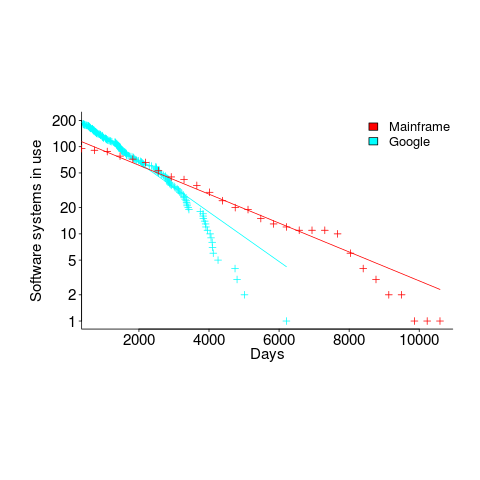
Overall, an exponential is a good fit (squinting to ignore the dozen red points), although product culling is not exponentially ruthless at short lifetimes (newly launched products are given a chance to prove themselves).
The Google service software half-life is 1,500 days, about 4.1 years (assuming the error/uncertainty is additive, if it is multiplicative {i.e., a percentage} the half-life is 1,300 days); the half-life of mainframe software is 2,600 days (with the same assumption about the kind of error/uncertainty).
One explanation of the difference is market maturity. Mainframe software has been evolving since the 1950s and probably turned over at the kind of rate we saw a few years ago with Internet services. By the 1990s things had settled down a bit in the mainframe world. Will software-based services on the Internet settle down faster than mainframe software? Who knows.
Based on this Google data, the cost/benefit ratio when deciding whether to invest in reducing future software maintenance costs, is going to have to be significantly better than the ratio calculated for mainframe software.
Software system lifetime data is extremely hard to find (this is only the second set I have found). Any pointers to other lifetime data very welcome, e.g., a collection of Microsoft product start/end dates 🙂
Break even ratios for development investment decisions
Developers are constantly being told that it is worth making the effort when writing code to make it maintainable (whatever that might be). Looking at this effort as an investment what kind of return has to be achieved to make it worthwhile?
Short answer: The percentage saving during maintenance has to be twice as great as the percentage investment during development to break even, higher ratio to do better.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments and pointers to more data welcome. R code and data here.
Break even ratios for development investment decisions
Upfront investments are often made during software development with the aim of achieving benefits later (e.g., reduced cost or time). Examples of such investments include spending time planning, designing or commenting the code. The following analysis calculates the benefit that must be achieved by an investment for that investment to break even.
While the analysis uses years as the unit of time it is not unit specific and with suitable scaling months, weeks, hours, etc can be used. Also the unit of development is taken to be a complete software system, but could equally well be a subsystem or even a function written by one person.
Let  be the original development cost and
be the original development cost and  the yearly maintenance costs, we start by keeping things simple and assume is the same for every year of maintenance; the total cost of the system over
the yearly maintenance costs, we start by keeping things simple and assume is the same for every year of maintenance; the total cost of the system over  years is:
years is:

If we make an investment of  % in reducing future maintenance costs with the expectations of achieving a benefit of
% in reducing future maintenance costs with the expectations of achieving a benefit of  %, the total cost becomes:
%, the total cost becomes:
 + y*m*(1+i)*(1-b)")
and for the investment to break even the following inequality must hold:
 + y*m*(1+i)*(1-b) < d + y*m")
expanding and simplifying we get:

or:

If the inequality is true the ratio  is the primary contributor to the right-hand-side and must be greater than 1.
is the primary contributor to the right-hand-side and must be greater than 1.
A significant problem with the above analysis is that it does not take into account a major cost factor; many systems are replaced after a surprisingly short period of time. What relationship does the ratio need to have when system survival rate is taken into account?
Let  be the percentage of systems that survive each year, total system cost is now:
be the percentage of systems that survive each year, total system cost is now:

where *(1-b)")
Summing the power series for the maximum of years that any system in a company’s software portfolio survives gives:
}/{1 - s}")
and the break even inequality becomes:
} < {b}/{i} + b")
The development/maintenance ratio is now based on the yearly cost multiplied by a factor that depends on the system survival rate, not the total maintenance cost
If we take >= 5 and a survival rate of less than 60% the inequality simplifies to very close to:

telling us that if the yearly maintenance cost is equal to the development cost (a situation more akin to continuous development than maintenance and seen in 5% of systems in the IBM dataset below) then savings need to be at least twice as great as the investment for that investment to break even. Taking the mean of the IBM dataset and assuming maintenance costs spread equally over the 5 years, a break even investment requires savings to be six times greater than the investment (for a 60% survival rate).
The plot below gives the minimum required saving/investment ratio that must be achieved for various system survival rates (black 0.9, red 0.8, blue 0.7 and green 0.6) and development/yearly maintenance cost ratios; the line bundles are for system lifetimes of 5.5, 6, 6.5, 7 and 7.5 years (ordered top to bottom)
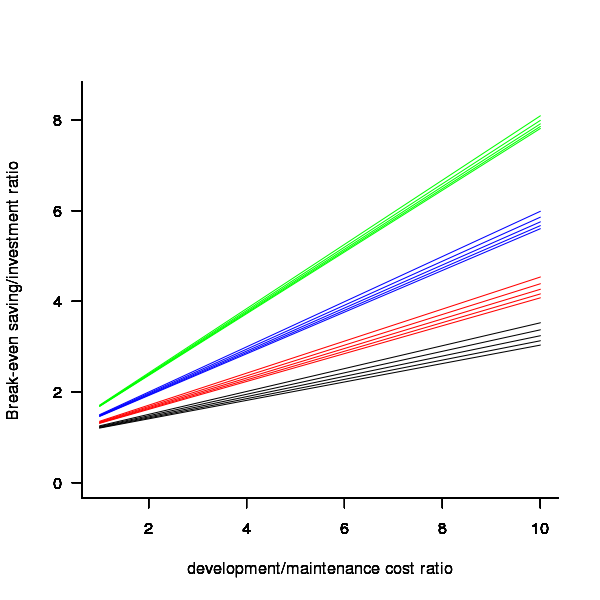
Figure 1. Break even saving/investment ratio for various system survival rates (black 0.9, red 0.8, blue 0.7 and green 0.6) and development/maintenance ratios; system lifetimes are 5.5, 6, 6.5, 7 and 7.5 years (ordered top to bottom)
Development and maintenance costs
Dunn’s PhD thesis <book Dunn_11> lists development and total maintenance costs (for the first five years) of 158 software systems from IBM. The systems varied in size from 34 to 44,070 man hours of development effort and from 21 to 78,121 man hours of maintenance.
The plot below shows the ratio of development to five year maintenance costs for the 158 software systems. The mean value is around one and if we assume equal spending during the maintenance period then  .
.
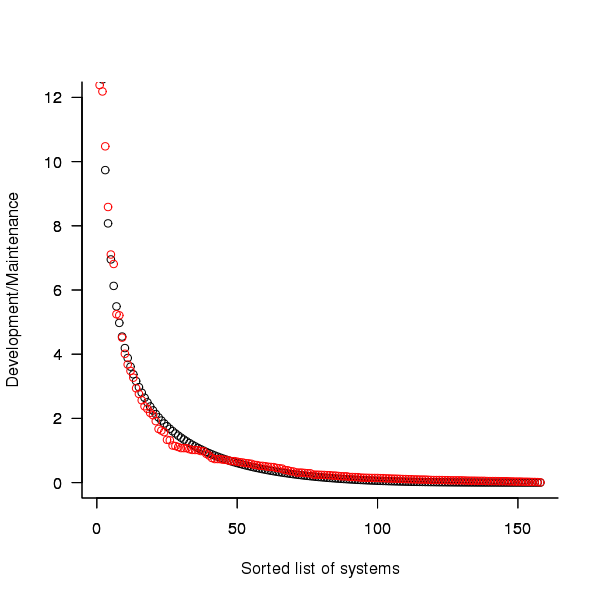
Figure 2. Ratio of development to five year maintenance costs for 158 IBM software systems sorted in size order. Data from Dunn <book Dunn_11>.
The best fitting common distribution for the maintenance/development ratio is the <Beta distribution>, a distribution often encountered in project planning.
Is there a correlation between development man hours and the maintenance/development ratio (e.g., do smaller systems tend to have a lower/higher ratio)? A Spearman rank correlation test between the maintenance/development ratio and development man hours gives:
|
showing very little connection between the two values.
Is the data believable?
While a single company dataset might be thought to be internally consistent in its measurement process, IBM is a very large company and it is possible that the measurement processes used were different.
The maintenance data applies to software systems that have not yet reached the end of their lifespan and is not broken down by year. Any estimate of total or yearly maintenance can only be based on assumptions or lifespan data from other studies.
System lifetime
A study by Tamai and Torimitsu <book Tamai_92> obtained data on the lifespan of 95 software systems. The plot below shows the number of systems surviving for at least a given number of years and a fit of an <Exponential distribution> to the data.
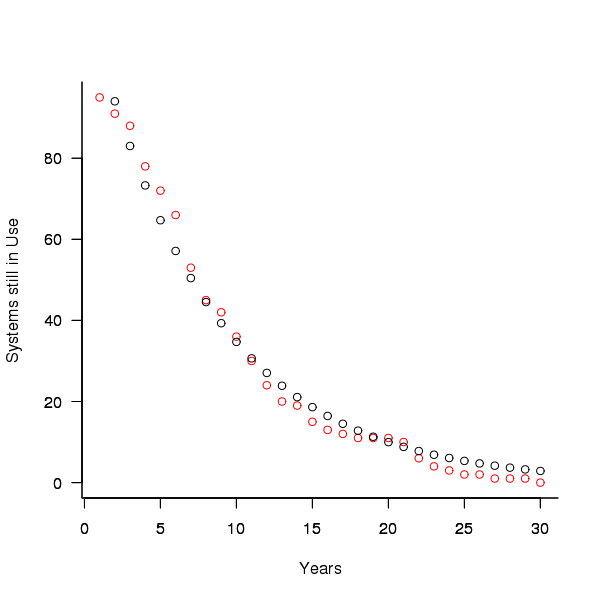
Figure 3. Number of software systems surviving to a given number of years (red) and an exponential fit (black, data from Tamai <book Tamai_92>).
The nls function gives  as the best fit, giving a half-life of 5.4 years (time for the number of systems to reduce by 50%), while rounding to
as the best fit, giving a half-life of 5.4 years (time for the number of systems to reduce by 50%), while rounding to  gives a half-life of 6.6 years and reducing to
gives a half-life of 6.6 years and reducing to  a half life of 4.6 years.
a half life of 4.6 years.
It is worrying that such a small change to the estimated fit can have such a dramatic impact on estimated half-life, especially given the uncertainty in the applicability of the 20 year old data to today’s environment. However, the saving/investment ratio plot above shows that the final calculated value is not overly sensitive to number of years.
Is the data believable?
The data came from a questionnaire sent to the information systems division of corporations using mainframes in Japan during 1991.
It could be argued that things have stabilised over the last 20 years ago and complete software replacements are rare with most being updated over longer periods, or that growing customer demands is driving more frequent complete system replacement.
It could be argued that large companies have larger budgets than smaller companies and so have the ability to change more quickly, or that larger companies are intrinsically slower to change than smaller companies.
Given the age of the data and the application environment it came from a reasonably wide margin of uncertainty must be assigned to any usage patterns extracted.
Summary
Based on the available data an investment during development must recoup a benefit during maintenance that is at least twice as great in percentage terms to break even:
- systems with a yearly survival rate of less than 90% must have a benefit/investment rate greater than two if they are to break even,
- systems with a development/yearly maintenance rate of greater than 20% must have a benefit/investment rate greater than two if they are to break even.
The availanble software system replacement data is not reliable enough to suggest any more than that the estimated half-life might be between 4 and 8 years.
This analysis only considers systems that have been delivered and started to be used. Projects are cancelled before reaching this stage and including these in the analysis would increase the benefit/investment break even ratio.
Brief history of syntax error recovery
Good recovery from syntax errors encountered during compilation is hard to achieve. The two most common strategies are to insert one or more tokens or to delete one or more tokens. Make the wrong decision and a second syntax error will occur, often leading to another and soon the developer is flooded by a nonsensical list of error messages. Compiler writers soon learn that their first priority is ensuring that syntax error recovery does not result in lots of cascading errors. In languages that use a delimiter to indicate end of statement/declaration, usually a semicolon, the error recovery strategy of deleting all tokens until this delimiter is next encountered is remarkably effective.
The era of very good syntax error recovery was the 1970s and early 1980s. Developers working on mainframes might only be able to achieve one or two compilations per day on a batch oriented mainframe and they were not happy if a misplaced comma or space resulted in a whole day being wasted. Most compilers were rented for lots of money and customer demand resulted in some very fancy error recovery strategies.
Borland’s Turbo Pascal had a very different approach to handling errors in code, it stopped processing the source as soon as one was detected. The combination of amazing compilation rates and an interactive environment (MS-DOS running on the machine in front of the developer) made this approach hugely attractive.
To a large extent syntax error recovery has been driven by the methods commonly used to write parsers. Many compilers use a table driven approach to syntax analysis with the tables being generated by parser generator tools such as Yacc. During the 1970s and 80s a lot of the research on parser generators was aimed at reducing the size of the generated tables. A table of 10k bytes was a significant percentage of available storage for machines that supported a maximum of 64k of memory. Some parser table compression techniques involve assuming the default behavior and then handling any special cases when these defaults are found not to apply, but one consequence is that context information needed for good error recovery is often not available when an error is detected. The last major release of Yacc from AT&T in the early 1990s managed another reduction in table size, just as typical storage sizes were getting into the ten of megabytes, but at the expense of increasing the difficulty of doing good error recovery.
While there are still some application areas where the amount of storage occupied by parser tables is still a big issue, e.g., the embedded market, developers of parser generators such as Bison ought to start addressing the needs of users wanting to do good error recovery and who are willing to accept larger tables.
I am pleased to see that the LLVM project is making an effort to provide good syntax error recovery. A frustrating barrier to providing better error recovery is lack of information on the kinds of syntax errors commonly made by developers; there are a few papers and reports containing small scale measurements of errors made by students. Perhaps the LLVM developers will provide a mechanism for automatically collecting compilation errors and providing users with the option to send the results to the LLVM project.
One of my favorite syntax error recovery techniques (implemented in a PL/1 mainframe compiler; I have never been able to justify implementing it on any project I worked on) is the following:
// Use of an undeclared identifier is a syntax error in C and some other // languages, while in other languages it is a semantic error. // no identifier with name result visible here { int result; ... result=... ... } ... calc=result*2; // Error reported by most compilers is use of an undeclared variable |
The ‘real’ error is probably the misplaced closing bracket. Other possibilities include result being a misspelled version of another variable or the assignment to calc being in the wrong place.
There seems to be a trend over the last 20 years to create languages that require more and more semantic information during parsing. Deciphering a syntax error today can involve a lot more than figuring out which surrounding tokens have been omitted or misplaced, information on which types are in scope and visible (oh for the days when that meant the same thing) and where they might be found in the umpteen thousand lines of included source has to be distilled and presented to the developer in a helpful message.
For a long time compilers have primarily been benchmarked on the quality of their code. With every diminishing returns from improved optimization, the increasing complexity of languages and the increasing volume of header code pulled in during compilation perhaps the quality of syntax error recovery will grow in importance.
Recent Comments