Archive
2019 in the programming language standards’ world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There has been progress on a few issues discussed last year, and one interesting point came up.
It is starting to look as if there might be another iteration of the Cobol Standard. A handful of people, in various countries, have started to nibble around the edges of various new (in the Cobol sense) features. No, the INCITS Cobol committee (the people who used to do all the heavy lifting) has not been reformed; the work now appears to be driven by people who cannot let go of their involvement in Cobol standards.
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard, has been updated and we were asked for a UK position on the document being published. Abstain seemed to be the only sensible option.
Our WG20 representative reported that the ongoing debate over pile of poo emoji has crossed the chasm (he did not exactly phrase it like that). Vendors want to have the freedom to specify code-points for use with their own emoji, e.g., pineapple emoji. The heady days, of a few short years ago, when an encoding for all the world’s character symbols seemed possible, have become a distant memory (the number of unhandled logographs on ancient pots and clay tablets was declining rapidly). Who could have predicted that the dream of a complete encoding of the symbols used by all the world’s languages would be dashed by pile of poo emoji?
The interesting news is from WG9. The document intended to become the Ada20 standard was due to enter the voting process in June, i.e., the committee considered it done. At the end of April the main Ada compiler vendor asked for the schedule to be slipped by a year or two, to enable them to get some implementation experience with the new features; oops. I have been predicting that in the future language ‘standards’ will be decided by the main compiler vendors, and the future is finally starting to arrive. What is the incentive for the GNAT compiler people to pay any attention to proposals written by a bunch of non-customers (ok, some of them might work for customers)? One answer is that Ada users tend to be large bureaucratic organizations (e.g., the DOD), who like to follow standards, and might fund GNAT to implement the new document (perhaps this delay by GNAT is all about funding, or lack thereof).
Right on cue, C++ users have started to notice that C++20’s added support for a system header with the name version, which conflicts with much existing practice of using a file called version to contain versioning information; a problem if the header search path used the compiler includes a project’s top-level directory (which is where the versioning file version often sits). So the WG21 committee decides on what it thinks is a good idea, implementors implement it, and users complain; implementors now have a good reason to not follow a requirement in the standard, to keep users happy. Will WG21 be apologetic, or get all high and mighty; we will have to wait and see.
Popularity of Open source Operating systems over time
Surveys of operating system usage trends are regularly published and we get to read about how the various Microsoft products are doing and the onward progress of mobile OSs; sometimes Linux gets an entry at the bottom of the list, sometimes it is just ‘others’ and sometimes it is both.
Operating systems are pervasive and a variety of groups actively track reported faults in order to issue warnings to the public; the volume of OS fault informations available makes it an obvious candidate for testing fault prediction models (e.g., how many faults will occur in a given period of time). A very interesting fault history analysis of OpenBSD in a paper by Ozment and Schechter recently caught my eye and I wondered if the fault time-line could be explained by the time-line of OpenBSD usage (e.g., more users more faults reported). While collecting OS usage information is not the primary goal for me I thought people would be interested in what I have found out and in particular to share the OS usage data I have managed to obtain.
How might operating system usage be measured? Analyzing web server logs is an obvious candidate method; when a web browser requests information many web servers write information about the request to a log file and this information sometimes includes the name of the operating system on which the browser is running.
Other sources of information include items sold (licenses in Microsoft’s case, CDs/DVD’s for Open source or perhaps books {but book sales tend not to be reported in the way programming language book sales are reported}) and job adverts.
For my time-line analysis I needed OpenBSD usage information between 1998 and 2005.
The best source of information I found, by far, of Open source OS usage derived from server logs (around 138 million Open source specific entries) is that provided by Distrowatch who count over 700 different distributions as far back as 2002. What is more Ladislav Bodnar the founder and executive editor of DistroWatch was happy to run a script I sent him to extract the count data I was interested in (I am not duplicating Distrowatch’s popularity lists here, just providing the 14 day totals for OS count data). Some analysis of this data below.
As luck would have it I recently read a paper by Diomidis Spinellis which had used server log data to estimate the adoption of Open Source within organizations. Diomidis researches Open source and was willing to run a script I wrote to extract the User Agent string from the 278 million records he had (unfortunately I cannot make this public because it might contain personal information such as email addresses, just the monthly totals for OS count data, tar file of all the scripts I used to process this raw log data; the script to try on your own logs is countos.sh).
My attempt to extract OS names from the list of User Agent strings Diomidis sent me (67% of of the original log entries did contain a User Agent string) provides some insight into the reliability of this approach to counting usage (getos.awk is the script to try on the strings extracted with the earlier script). There is no generally agreed standard for:
- what information should be present; 6% of UA strings contained no OS name that I knew (this excludes those entries that were obviously robots/crawlers/spiders/etc),
- the character string used to specify a given OS or a distribution; the only option is to match a known list of names (OS names used by Distrowatch,
missos.awkis the tar file script to print out any string not containing a specified list of OS names, the Wikipedia List of operating systems article), - quality assurance; some people cannot spell ‘windows’ correctly and even though the source is now available I don’t think anybody uses CP/M to access the web (at least 91 strings,
 %, would not have passed).
%, would not have passed).
Ladislav Bodnar thinks that log entries from the same IP addresses should only be counted once per day per OS name. I agree that this approach is much better than ignoring address information; why should a person who makes 10 accesses be counted 10 times, a person who makes one access is only counted once. It is possible that two or more separate machines running the same OS are accessing the Internet through a common gateway that results in them having the IP address from an external server’s point of view; this possibility means that the Distrowatch data undercounts the unique accesses (not a serious problem if most visitors have direct Internet access rather than through a corporate network).
The Distrowatch data includes counts for all IP address and from 13 May 2004 onwards unique IP address per day per OS. The mean ratio between these two values, summed over all OS counts within 14 day periods, is 1.9 (standard deviation 0.08) and the Pearson correlation coefficient between them is 0.987 (95% confidence interval is 0.984 to 0.990), i.e., almost perfect correlation.
The Spinellis data ignores IP address information (I got this dataset first, and have already spent too much time collecting to do more data extraction) and has 10 million UA strings containing Open source OS names (6% of all OS names matched).
How representative are the Distrowatch and Spinellis data? The data is as representative of the general OS population as the visitors recorded in the respective server logs are representative of OS usage. The plot below shows the percentage of visitors to Distrowatch that use Ubuntu, Suse, Redhat. Why does Redhat, a very large company in the Open source world, have such a low percentage compared to Ubuntu? I imagine because Redhat customers get their updates from Redhat and don’t see a need to visit sites such as Distrowatch; a similar argument can be applied to Suse. Perhaps the Distrowatch data underestimates those distributions that have well known websites and users who have no interest in other distributions. I have not done much analysis of the Spinellis data.
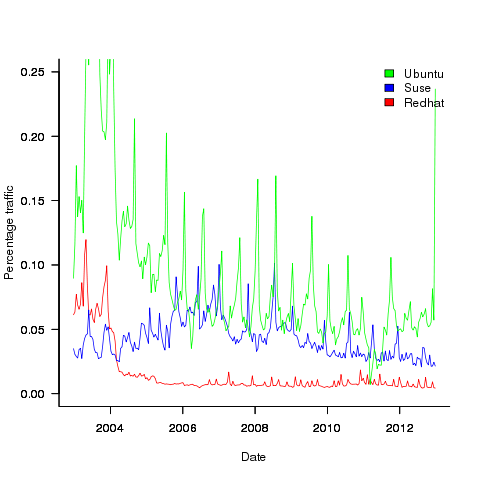
Presumably the spikes in usage occur around releases of new versions, I have not checked.
For my analysis I am interested in relative change over time, which means that representativeness and not knowing the absolute number of OSs in use is not a problem. Researchers interested in a representative sample or estimating the total number of OSs in use are going to need a wider selection of data; they might be interested in the following OS usage information I managed to find (yes I know about Netcraft, they charge money for detailed data and I have not checked what the Wayback Machine has on file):
- Wikimedia has OS count information back to 2009. Going forward this is a source of log data to rival Distrowatch’s, but the author of the scripts probably ought to update the list of OS names matched against,
- w3schools has good summary data for many months going back to 2003,
- statcounter has good summary data (daily, weekly, monthly) going back to 2008,
- TheCounter.com had data from 2000 to 2009 (csv file containing counts obtained from Wayback Machine).
If any reader has or knows anybody who has detailed OS usage data please consider sharing it with everybody.
My no loops in R hair shirt
Being professionally involved with analyzing source code, I get to work with a much larger number of programming languages than most people. There is a huge difference between knowing the intricate details of the semantics of a language and being able to fluently program in a language like a native developer. There are languages whose semantics I probably know better than nearly all its users and yet can only code in like a novice, and there are languages whose reference manual I might have read once and yet can write fluently.
I try not to learn new languages in which to write programs, they just clutter my brain. It can be very embarrassing having somebody sitting next to me while I write an example and not be able to remember whether the language I am using requires a then in its if-statement or getting the details of a print statement wrong; I am supposed to be a computer language expert.
Having decided to migrate from being a casual R user to being a native user (my current status is somebody who owns more than 10 books that make extensive use of R) I resolved to invest the extra time needed to learn how to write code the ‘R-way’ (eighteen months later I’m not sure that there is an ‘R way’ in the sense that could be said to exist in other languages, or if there is it is rather diffuse). One of my self-appointed R-way rules is that any operation involving every element of a vector should be performed using whole vector operations (i.e., no looping constructs).
Today I was analyzing the release history of the Linux kernel and wanted to get the list of release dates for the current version of the major branch; I had a list of dates for every release. The problem is that when a major release branch is started previous branches, now in support only mode, may continue to be maintained for some time, for instance after the version 2.3 branch was created the version 2.2 branch continued to have releases made for it for another five years.
The obvious solution to removing non-applicable versions from the release list is to sort on release date and then loop through the elements, removing those whose version number was less than the version appearing before them in the list. In the following excerpt the release of 2.3.0 causes the following 2.2.9 release to be removed from the list, also versions 2.0.37 and 2.2.10 should be removed.
Version Release_date 2.2.8 1999-05-11 2.3.0 1999-05-11 2.2.9 1999-05-13 2.3.1 1999-05-14 2.3.2 1999-05-15 2.3.3 1999-05-17 2.3.4 1999-06-01 2.3.5 1999-06-02 2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 2.3.8 1999-06-22 |
While this is an easy problem to solve using a loop, what is the R-way of solving it (use the xyz package would be the answer half said in jest)? My R-way rule did not allow loops, so a-head scratching I did go. On the assumption that the current branch version dates would be intermingled with releases of previous branches I decided to use simple pair-wise comparison (which could be coded up as a whole vector operation); if an element contained a version number that was less than the element before it, then it was removed.
Here is the code (treat step parameter was introduced later as part of the second phase tidy up; data here):
ld=read.csv("/usr1/rbook/examples/regression/Linux-days.csv") ld$Release_date=as.POSIXct(ld$Release_date, format="%d-%b-%Y") ld.ordered=ld[order(ld$Release_date), ] strip.support.v=function(version.date, step) { # Strip off the least significant value of the Version id v = substr(version.date$Version, 1, 3) # Build a vector of TRUE/FALSE indicating ordering of element pairs q = c(rep(TRUE, step), v[1:(length(v)-step)] <= v[(1+step):length(v)]) # Only return TRUE entries return (version.date[q, ]) } h1=strip.support.v(ld.ordered, 1) |
This pair-wise approach only partially handles the following sequence (2.2.10 is greater than 2.0.37 and so would not be removed).
2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 |
The no loops rule prevented me iterating over calls to strip.support.v until there were no more changes.
Would a native R speaker assume there would not be many extraneous Version/Release_date pairs and be willing to regard their presence as a minor data pollution problem? If so, I have some way to go before I might be able to behave as a native.
My next line of reasoning was that any contiguous sequence of non-applicable version numbers would probably be a remote island in a sea of applicable values. Instead of comparing an element against its immediate predecessor, it should be compared against an element step back (I chose a value of 5).
h2=strip.support.v(h1, 5) |
The original vector contained 832 rows, which was reduced to 745 and then down to 734 on the second step.
Are there any non-loop solutions that are capable of handling a higher density of non-applicable values? Do tell if you can think of one.
Update (a couple of days later)
Thanks to Charles Lowe, Wojtek and kaz_yos for their solutions using cummax, a function that I was previously unaware of. This was a useful reminder that what other languages do in the syntax/semantics R surprisingly often does via a function call (I’m still getting my head around the fact that a switch-statement is implemented via a function in R); as a wannabe native R speaker I need to remove my overly blinked language approach to problems and learn a lot more about the functions that come as part of the base system
Recent Comments