Archive
Comparing developer/LLM coding performance
Lots of claims are being made about how LLMs will soon outperform developers on coding tasks. Given the lack of any effective measure of developer performance, these claims are meaningless. At some point, lower costs will entice management to accept good enough LLM performance as a replacement for human developers, i.e., LLM don’t need to be technically better than developers.
The outperform claims are, currently, marketing puff, and I was not expecting anybody to make a serious attempt to compare developer/LLM performance. However, concerns about AI exceeding human capacity to control it (and maybe wiping out humans) has resulted in some well funded AI safety research groups. There is at least one group actively recruiting developers to “… establish human performance baselines on tasks related to software engineering, machine learning, and cybersecurity …”.
The most talked about AI threat scenarios all seem to start with recursive self-improvement, i.e., LLMs training themselves, exponentially improving with each iteration (the implied exponential always seems to be continuously up, rather than getting exponentially closer to a maximum).
Can current LLMs improve themselves faster than a developer can?
Implementing a new LLM is beyond the ability of today’s LLM, but they can implement some of the components used to build an LLM. How does LLM performance compare against developers, on the implementation of these components?
The paper RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts from METR (Model Evaluation & Threat Research) comes with code and “… anonymized human expert data coming soon.” for seven tasks. The baseline was derived from the performance of 61 human experts.
I’m always pleased to see researchers doing experiments with developers. I wish there were more groups doing this kind of thing.
However, I think that these researchers have made the common mistake of using very complicated subject tasks in their experiment. Most software development tasks are mundane, with the occasional complicated task (which can often be solved by using an appropriate package/library). The tasks may be representative of the harder tasks that need to be done, but they are not representative of the complete LLM implementation scenario.
A consequence of using complicated tasks is that most subjects only had enough time to complete one task (they were given 8 hours). With so few tasks (seven) the confidence intervals are going to be very wide on any general statement about human/LLM performance. With around ten subjects per task, the individual task confidence intervals are also going to be wide.
Task 7 made me laugh: “… that generates solutions to CodeContests problems in Rust, …”
Why Rust? Did they happen to have access to lots of Rust experts, or does the research group contain enthusiastic fans of Rust? I suspect the latter. There is a certain kind of highly intelligent developer who strongly believes that writing programs in a particular language imbues the code with magical properties (their rationale won’t be worded that way). For the last few years, Rust has been one of these pixie dust languages. Many decades ago, C had this charisma.
Perhaps each generation of ever more ‘intelligent’ LLMs will choose to design a new language to use to implement their ‘successor’.
There are a myriad of tasks related to software engineering. Solving GitHub issues is a thankless task, and having LLMs reliably close open issues would be of enormous benefit. A study published two months ago obtained a 1.96% solution rate (no explicit testing of developers).
Shopper estimates of the total value of items in their basket
Agile development processes break down the work that needs to be done into a collection of tasks (which may be called stories or some other name). A task, whose implementation time may be measured in hours or a few days, is itself composed of a collection of subtasks (which may in turn be composed of subsubtasks, and so on down).
When asked to estimate the time needed to implement a task, a developer may settle on a value by adding up estimates of the effort needed to implement the subtasks thought to be involved. If this process is performed in the mind of the developer (i.e., not by writing down a list of subtask estimates), the accuracy of the result may be affected by the characteristics of cognitive arithmetic.
Humans have two cognitive systems for processing quantities, the approximate number system (which has been found to be present in the brain of many creatures), and language. Researchers studying the approximate number system often ask subjects to estimate the number of dots in an image; I recently discovered studies of number processing that used language.
In a study by Benjamin Scheibehenne, 966 shoppers at the checkout counter in a grocery shop were asked to estimate the total value of the items in their shopping basket; a subset of 421 subjects were also asked to estimate the number of items in their basket (this subset were also asked if they used a shopping list). The actual price and number of items was obtained after checkout.
There are broad similarities between shopping basket estimation and estimating task implementation time, e.g., approximate idea of number of items and their cost. Does an analysis of the shopping data suggest ideas for patterns that might be present in software task estimate data?
The left plot below shows shopper estimated total item value against actual, with fitted regression line (red) and estimate==actual (grey); the right plot shows shopper estimated number of items in their basket against actual, with fitted regression line (red) and estimate==actual (grey) (code+data):
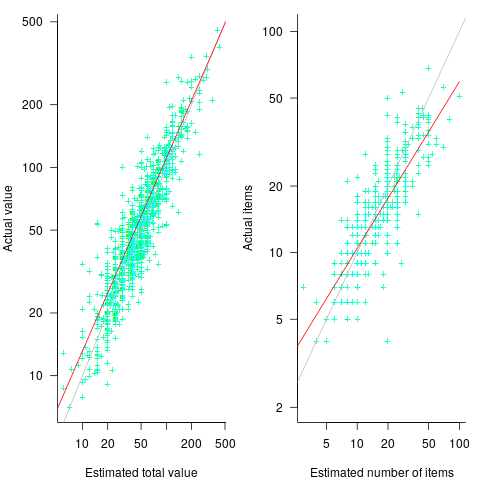
The model fitted to estimated total item value is:  , which differs from software task estimates/actuals in always underestimating over the range measured; the exponent value,
, which differs from software task estimates/actuals in always underestimating over the range measured; the exponent value,  , is at the upper range of those seen for software task estimates.
, is at the upper range of those seen for software task estimates.
The model fitted to estimated number of items in the basket is:  . This pattern, of underestimating small values and overestimating large values is seen in software task estimation, but the exponent of
. This pattern, of underestimating small values and overestimating large values is seen in software task estimation, but the exponent of  is much smaller.
is much smaller.
Including the estimated number of items in the shopping basket,  , in a model for total value produces a slightly better fitting model:
, in a model for total value produces a slightly better fitting model:  , which explains 83% of the variance in the data (use of a shopping list had a relatively small impact).
, which explains 83% of the variance in the data (use of a shopping list had a relatively small impact).
The accuracy of a software task implementation estimate based on estimating its subtasks dependent on identifying all the subtasks, or having a good enough idea of the number of subtasks. The shopping basket study found a pattern of inaccuracies in estimates of the number of recently collected items, which has been seen before. However, adding to the Shopping model only reduced the unexplained variance by a few percent.
Would the impact of adding an estimate of the number of subtasks to models of software task estimates also only be a few percent? A question to add to the already long list of unknowns.
Like task estimates, round numbers were often given as estimate values; see code+data.
The same study also included a laboratory experiment, where subjects saw a sequence of 24 numbers, presented one at a time for 0.5 seconds each. At the end of the sequence, subjects were asked to type in their best estimate of the sum of the numbers seen (other studies asked subjects to type in the mean). Each subject saw 75 sequences, with feedback on the mean accuracy of their responses given after every 10 sequences. The numbers were described as the prices of items in a shopping basket. The values were drawn from a distribution that was either uniform, positively skewed, negatively skewed, unimodal, or bimodal. The sequential order of values was either increasing, decreasing, U-shaped, or inversely U-shaped.
Fitting a regression model to the lab data finds that the distribution used had very little impact on performance, and the sequence order had a small impact; see code+data.
Impact of number of files on number of review comments
Code review is often discussed from the perspective of changes to a single file. In practice, code review often involves multiple files (or at least pull-based reviews do), which begs the question: Do people invest less effort reviewing files appearing later?
TLDR: The number of review comments decreases for successive files in the pull request; by around 16% per file.
The paper First Come First Served: The Impact of File Position on Code Review extracted and analysed 219,476 pull requests from 138 Java projects on Github. They also ran an experiment which asked subjects to review two files, each containing a seeded coding mistake. The paper is relatively short and omits a lot of details; I’m guessing this is due to the page limit of a conference paper.
The plot below shows the number of pull requests containing a given number of files. The colored lines indicate the total number of code review comments associated with a given pull request, with the red dots showing the 69% of pull requests that did not receive any review comments (code+data):
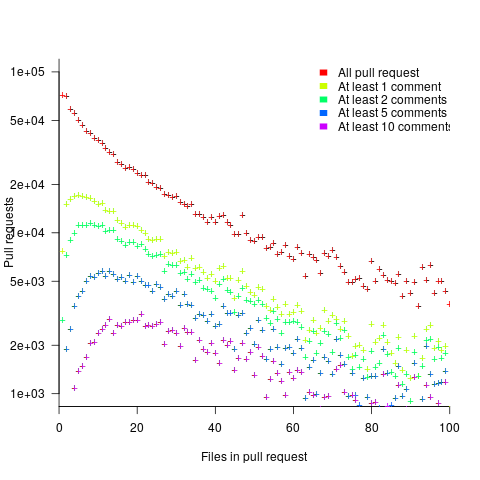
Many factors could influence the number of comments associated with a pull request; for instance, the number of people commenting, the amount of changed code, whether the code is a test case, and the number of files already reviewed (all items which happen to be present in the available data).
One factor for which information is not present in the data is social loafing, where people exert less effort when they are part of a larger group; or at least I did not find a way of easily estimating this factor.
The best model I could fit to all pull requests containing less than 10 files, and having a total of at least one comment, explained 36% of the variance present, which is not great, but something to talk about. There was a 16% decline in comments for successive files reviewed, test cases had 50% fewer comments, and there was some percentage increase with lines added; number of comments increased by a factor of 2.4 per additional commenter (is this due to importance of the file being reviewed, with importance being a metric not present in the data).
The model does not include information available in the data, such as file contents (e.g., Java, C++, configuration file, etc), and there may be correlated effects I have not taken into account. Consequently, I view the model as a rough guide.
Is the impact of file order on number of comments a side effect of some unrelated process? One way of showing a causal connection is to run an experiment.
The experiment run by the authors involved two five files, each with the first and last containing one seeded coding mistake. The 102 subjects were asked to review the two five files, with mistake file order randomly selected. The experiment looks well-structured and thought through (many are not), but the analysis of the results is confused.
The good news is that the seeded coding mistake in the first file was much more likely to be detected than the mistake in the second last file, and years of Java programming experience also had an impact (appearing first had the same impact as three years of Java experience). The bad news is that the model (a random effect model using a logistic equation) explains almost none of the variance in the data, i.e., these effects are tiny compared to whatever other factors are involved; see code+data.
What other factors might be involved?
Most experiments show a learning effect, in that subject performance improves as they perform more tasks. Having subjects review many pairs of files would enable this effect to be taken into account. Also, reviewing multiple pairs would reduce the impact of random goings-on during the review process.
The identity of the seeded mistake did not have a significant impact on the model.
Review comments are an important issue which is amenable to practical experimental investigation. I hope that the researchers run more experiments on this issue.
Cognitive effort, whatever it might be
Software developers spend a lot of time acquiring knowledge and understanding of the software system they are working on. This mental activity fits within the field of Cognition, which covers all aspects of intellectual functions and processes. Human cognition as it related to software development is covered in chapter 2 of my book Evidence-based software engineering; a reading list.
Cognitive effort (e.g., thinking) is hard work, or at least mental effort feels like hard work. It has become fashionable for those extolling the virtues of some development technique/process to claim that one of its benefits is a reduction in cognitive effort; sometimes the term cognitive load is used, but I suspect this is not a reference to cognitive load theory (which is working memory based).
A study by Arai, with herself as the subject, measured the time taken to mentally multiply two four-digit values (e.g., 2,645 times 5,784). Over 2-weeks, Arai practiced on four days, on each day multiplying over 20 four-digit value pairs. A week later Arai multiplied 40 four-digit value pairs (starting at 1:45pm, finishing at 6:31pm), had dinner between 6:31-7:41 pm, and then, multiplied 20 four-digit value pairs (starting at 7:41, finishing at 10:07). The plot below shows the time taken for each mental multiplication sequence, with fitted regression lines (code+data):
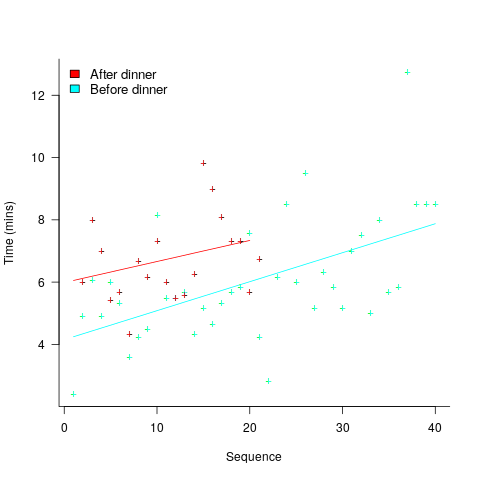
Over the course of the first, 5-hour session, average time taken slowed from four to eight minutes. The slope of the regression fit for the second session is poor, although the fit for the start value (6 minutes) is good.
The average increase in time taken is assumed to be driven by a reduction in mental effort, caused by the mental fatigue experienced during an extended period of continuous mental work.
What do we know about cognitive effort?
TL;DR Many theories and little evidence.
Cognitive psychologists are still at the stage of figuring out what exactly cognitive effort is. For instance, what is going on when we try harder (or decide to give up), and what is being conserved when we conserve our mental resources? The major theories include:
- Cognitive control: Mental processes form a continuum, from those that can be performed automatically with little or no effort, to those requiring concentrated conscious effort. Here, cognitive control is viewed as the force through which cognitive effort is exerted. The idea is that mental effort regulates the engagement of cognitive control in the same way as physical effort regulates the engagement of muscles.
- Metabolic constraints: Mental processes consume energy (glucose is the brain’s primary energy source), and the feeling of mental effort is caused by reduced levels of glucose. The extent to which mental effort is constrained by glucose levels is an ongoing debate.
- Capacity constraints: Working memory has a limited capacity (i.e., the oft quoted 7±2 limit), and tasks that fill this capacity do feel effortful. Cognitive load theory is based around this idea. A capacity limited working memory, as a basis of cognitive effort, suffers from the problem that people become mentally tired in the sense that later tasks feel like they require more effort. A capacity constrained model does not predict this behavior. Neither does a constraints model predict that increasing rewards can result in people exerting more cognitive effort.
How might cognitive effort be measured?
TL;DR It’s all relative or not at all.
To date, experiments have compared relative expenditure of effort between different tasks (some comparing cognitive with physical effort, other purely cognitive). For instance, showing that subjects are willing to perform a task requiring more cognitive effort when the expected reward is higher.
As always with human experiments, people can have very different behavioral characteristics. In particular, people differ in what is known as need for cognition, i.e., their willingness to invest cognitive effort.
While a lot of research has investigated the characteristics of working memory, the only real metric studied has been capacity, e.g., the longest sequence of digits that can be remembered/recalled, or span tasks involving having to remember words while performing simple arithmetic operations.
Experimental research on cognitive effort seems to be picking up, but don’t hold your breadth for reliable answers. Research of human characteristics can start out looking straight forward, but tends to quickly disappear down multiple, inconclusive rabbit holes.
Evaluating estimation performance
What is the best way to evaluate the accuracy of an estimation technique, given that the actual values are known?
Estimates are often given as point values, and accuracy scoring functions (for a sequence of estimates) have the form }") , where
, where  is the number of estimated values,
is the number of estimated values,  the estimates, and
the estimates, and  the actual values; smaller
the actual values; smaller  is better.
is better.
Commonly used scoring functions include:
=(E-A)^2") , known as squared error (SE)
, known as squared error (SE)=delim{|}{E-A}{|}") , known as absolute error (AE)
, known as absolute error (AE)=delim{|}{E-A}{|}/A") , known as absolute percentage error (APE)
, known as absolute percentage error (APE)=delim{|}{E-A}{|}/E") , known as relative error (RE)
, known as relative error (RE)
APE and RE are special cases of: =delim{|}{1-(A/E)^{beta}}{|}") , with
, with  and
and  respectively.
respectively.
Let’s compare three techniques for estimating the time needed to implement some tasks, using these four functions.
Assume that the mean time taken to implement previous project tasks is known,  . When asked to implement a new task, an optimist might estimate 20% lower than the mean,
. When asked to implement a new task, an optimist might estimate 20% lower than the mean,  , while a pessimist might estimate 20% higher than the mean,
, while a pessimist might estimate 20% higher than the mean,  . Data shows that the distribution of the number of tasks taking a given amount of time to implement is skewed, looking something like one of the lines in the plot below (code):
. Data shows that the distribution of the number of tasks taking a given amount of time to implement is skewed, looking something like one of the lines in the plot below (code):
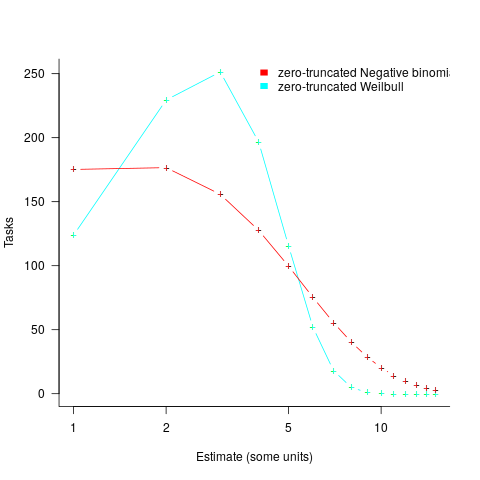
We can simulate task implementation time by randomly drawing values from a distribution having this shape, e.g., zero-truncated Negative binomial or zero-truncated Weibull. The values of  and
and  are calculated from the mean, , of the distribution used (see code for details). Below is each estimator’s score for each of the scoring functions (the best performing estimator for each scoring function in bold; 10,000 values were used to reduce small sample effects):
are calculated from the mean, , of the distribution used (see code for details). Below is each estimator’s score for each of the scoring functions (the best performing estimator for each scoring function in bold; 10,000 values were used to reduce small sample effects):
SE AE APE RE
2.73 1.29 0.51 0.56
2.31 1.23 0.39 0.68
2.70 1.37 0.36 0.86
Surprisingly, the identity of the best performing estimator (i.e., optimist, mean, or pessimist) depends on the scoring function used. What is going on?
The analysis of scoring functions is very new. A 2010 paper by Gneiting showed that it does not make sense to select the scoring function after the estimates have been made (he uses the term forecasts). The scoring function needs to be known in advance, to allow an estimator to tune their responses to minimise the value that will be calculated to evaluate performance.
The mathematics involves Bregman functions (new to me), which provide a measure of distance between two points, where the points are interpreted as probability distributions.
Which, if any, of these scoring functions should be used to evaluate the accuracy of software estimates?
In software estimation, perhaps the two most commonly used scoring functions are APE and RE. If management selects one or the other as the scoring function to rate developer estimation performance, what estimation technique should employees use to deliver the best performance?
Assuming that information is available on the actual time taken to implement previous project tasks, then we can work out the distribution of actual times. Assuming this distribution does not change, we can calculate APE and RE for various estimation techniques; picking the technique that produces the lowest score.
Let’s assume that the distribution of actual times is zero-truncated Negative binomial in one project and zero-truncated Weibull in another (purely for convenience of analysis, reality is likely to be more complicated). Management has chosen either APE or RE as the scoring function, and it is now up to team members to decide the estimation technique they are going to use, with the aim of optimising their estimation performance evaluation.
A developer seeking to minimise the effort invested in estimating could specify the same value for every estimate. Knowing the scoring function (top row) and the distribution of actual implementation times (first column), the minimum effort developer would always give the estimate that is a multiple of the known mean actual times using the multiplier value listed:
APE RE
Negative binomial 1.4 0.5
Weibull 1.2 0.6
For instance, management specifies APE, and previous task/actuals has a Weibull distribution, then always estimate the value  .
.
What mean multiplier should Esta Pert, an expert estimator aim for? Esta’s estimates can be modelled by the equation ") , i.e., the actual implementation time multiplied by a random value uniformly distributed between 0.5 and 2.0, i.e., Esta is an unbiased estimator. Esta’s table of multipliers is:
, i.e., the actual implementation time multiplied by a random value uniformly distributed between 0.5 and 2.0, i.e., Esta is an unbiased estimator. Esta’s table of multipliers is:
APE RE
Negative binomial 1.0 0.7
Weibull 1.0 0.7
A company wanting to win contracts by underbidding the competition could evaluate Esta’s performance using the RE scoring function (to motivate her to estimate low), or they could use APE and multiply her answers by some fraction.
In many cases, developers are biased estimators, i.e., individuals consistently either under or over estimate. How does an implicit bias (i.e., something a person does unconsciously) change the multiplier they should consciously aim for (having analysed their own performance to learn their personal percentage bias)?
The following table shows the impact of particular under and over estimate factors on multipliers:
0.8 underestimate bias 1.2 overestimate bias
Score function APE RE APE RE
Negative binomial 1.3 0.9 0.8 0.6
Weibull 1.3 0.9 0.8 0.6
Let’s say that one-third of those on a team underestimate, one-third overestimate, and the rest show no bias. What scoring function should a company use to motivate the best overall team performance?
The following table shows that neither of the scoring functions motivate team members to aim for the actual value when the distribution is Negative binomial:
APE RE
Negative binomial 1.1 0.7
Weibull 1.0 0.7
One solution is to create a bespoke scoring function for this case. Both APE and RE are special cases of a more general scoring function (see top). Setting  in this general form creates a scoring function that produces a multiplication factor of 1 for the Negative binomial case.
in this general form creates a scoring function that produces a multiplication factor of 1 for the Negative binomial case.
Study of developers for the cost of a phase I clinical drug trial
For many years now, I have been telling people that software researchers need to be more ambitious and apply for multi-million pound/dollar grants to run experiments in software engineering. After all, NASA spends a billion or so sending a probe to take some snaps of a planet and astronomers lobby for $100million funding for a new telescope.
What kind of experimental study might be run for a few million pounds (e.g., the cost of a Phase I clinical drug trial)?
Let’s say that each experiment involves a team of professional developers implementing a software system; call this a Project. We want the Project to be long enough to be realistic, say a week.
Different people exhibit different performance characteristics, and the experimental technique used to handle this is to have multiple teams independently implement the same software system. How many teams are needed? Fifteen ought to be enough, but more is better.
Different software systems contain different components that make implementation easier/harder for those involved. To remove single system bias, a variety of software systems need to be used as Projects. Fifteen distinct Projects would be great, but perhaps we can get away with five.
How many developers are on a team? Agile task estimation data shows that most teams are small, i.e., mostly single person, with two and three people teams making up almost all the rest.
If we have five teams of one person, five of two people, and five of three people, then there are 15 teams and 30 people.
How many people will be needed over all Projects?
15 teams (30 people) each implementing one Project 5 Projects, which will require 5*30=150 people (5*15=75 teams) |
How many person days are likely to be needed?
If a 3-person team takes a week (5 days), a 2-person team will take perhaps 7-8 days. A 1-person team might take 9-10 days.
The 15 teams will consume 5*3*5+5*2*7+5*1*9=190 person days The 5 Projects will consume 5*190=950 person days |
How much is this likely to cost?
The current average daily rate for a contractor in the UK is around £500, giving an expected cost of 190*500=£475,000 to hire the experimental subjects. Venue hire is around £40K (we want members of each team to be co-located).
The above analysis involves subjects implementing one Project. If, say, each subject implements two, three or four Projects, one after the other, the cost is around £2million, i.e., the cost of a Phase I clinical drug trial.
What might we learn from having subjects implement multiple Projects?
Team performance depends on the knowledge and skill of its members, and their ability to work together. Data from these experiments would be the first of their kind, and would provide realistic guidance on performance factors such as: impact of team size; impact of practice; impact of prior experience working together; impact of existing Project experience. The multiple implementations of the same Project created provide a foundation for measuring expected reliability and theories of N-version programming.
A team of 1 developer will take longer to implement a Project than a team of 2, who will take longer than a team of 3.
If 20 working days is taken as the ballpark period over which a group of subjects are hired (i.e., a month), there are six team size sequences that one subject could work (A to F below); where individual elapsed time is close to 20 days (team size 1 is 10 days elapsed, team size 2 is 7.5 days, team size 3 is 5 days).
Team size A B C D E F
1 twice once once
2 once thrice once
3 twice twice four |
The cost of hiring subjects+venue+equipment+support for such a study is likely to be at least £1,900,000.
If the cost of beta testing, venue hire and research assistants (needed during experimental runs) is included, the cost is close to £2.75 million.
Might it be cheaper and simpler to hire, say, 20-30 staff from a medium size development company? I chose a medium-sized company because we would be able to exert some influence over developer selection and keeping the same developers involved. The profit from 20-30 people for a month is not enough to create much influence within a large company, and a small company would not want to dedicate a large percentage of its staff for a solid month.
Beta testing is needed to validate both the specifications for each Project and that it is possible to schedule individuals to work in a sequence of teams over a month (individual variations in performance create a scheduling nightmare).
Where are we with models of human learning?
Learning is an integral part of writing software. What have psychologists figured out about the characteristics of human learning?
A study of memory, published in 1885, kicked off the start of modern psychology research. At the start of the 1900s, learning research was still closely tied to the study of the characteristics of what we now call working memory, e.g., measuring the time taken for subjects to correctly recall sequences of digits, nonsense syllables, words and prose. By the 1930s, learning was a distinct subject in its own right.
What is now known as the power law of learning was first proposed in 1926. Wikipedia is right to use the phrase power law of practice, since it is some measure of practice that appears in the power law of learning equation:  , where:
, where:  is the time taken to do the task,
is the time taken to do the task, is some measure of practice (such as the number of times the subject has performed the task), and
is some measure of practice (such as the number of times the subject has performed the task), and  ,
,  , and
, and  are constants fitted to the data.
are constants fitted to the data.
For the next 70 years some form of power law did a good job of fitting the learning data produced by researchers. Then in 1997 a paper pointed out that researchers were fitting aggregate data (i.e., one equation fitted to all subject data), and that an exponential equation was a better fit to individual subject response times:  . The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
. The power law appeared to be the result of aggregating the exponential response performance of multiple subjects; oops.
What is the situation today, 25 years later? Do the subsystems of our brains produce a power law or exponential improvement in performance, with practice?
The problem with answering this question is that both equations can fit the available data quite well, with one being a technically better fit than the other for different datasets. The big difference between the two equations is in their tails, however, it is costly and time-consuming to obtain enough data to distinguish between them in this region.
When discussing learning in my evidence-based software engineering book, I saw no compelling reason to run counter to the widely cited power law, but I did tell readers about the exponential fit issue.
Studies of learnings have tended to use simple tasks; subjects are usually only available for a short time, and many task repetitions are needed to model the impact of learning. Simple tasks tend to be dominated by one primary activity, which means that subjects can focus their learning on this one activity.
Complicated tasks involve many activities, each potentially providing distinct learning opportunities. Which activities will a subject focus on improving, will the performance on one activity improve faster than others, will the approach chosen for one activity limit the performance on a second activity?
For a complicated task, the change in performance with amount of practice could be a lot more complicated than a single power law/exponential equation, e.g., there may be multiple equations with each associated with one or more activities.
In the previous paragraph, I was careful to say “could be a lot more complicated”. This is because the few datasets of organizational learning show a power law performance improvement, e.g., from 1936 we have the most cited study Factors Affecting the Cost of Airplanes, and the less well known but more interesting Liberty shipbuilding from the 1940s.
If the performance of something involving multiple people performing many distinct activities follows a power law improvement with practice, then the performance of an individual carrying out a complicated task might follow a simple equation; perhaps the combined form of many distinct simple learning activities is a simple equation.
Researchers are now proposing more complicated models of learning, along with fitting them to existing learning datasets.
Which equation should software developers use to model the learning process?
I continue to use a power law. The mathematics tend to be straight-forward, and it often gives an answer that is good enough (because the data fitted contains lots of variance). If it turned out that an exponential would be easier to work with, I would be happy to switch. Unless there is a lot of data in the tail, the difference between power law/exponent is usually not worth worrying about.
There are situations where I have failed to successfully add a learning (power law) component to a model. Was this because there was no learning present, or was the learning not well-fitted by a power law? I don’t know, and I cannot think of an alternative equation that might work, for these cases.
Claiming that software is AI based is about to become expensive
The European Commission is updating the EU Machinery Directive, which covers the sale of machinery products within the EU. The updates include wording to deal with intelligent robots, and what the commission calls AI software (contained in machinery products).
The purpose of the initiative is to: “… (i) ensuring a high level of safety and protection for users of machinery and other people exposed to it; and (ii) establishing a high level of trust in digital innovative technologies for consumers and users, …”
What is AI software, and how is it different from non-AI software?
Answering these questions requires knowing what is, and is not, AI. The EU defines Artificial Intelligence as:
- ‘AI system’ means a system that is either software-based or embedded in hardware devices, and that displays behaviour simulating intelligence by, inter alia, collecting and processing data, analysing and interpreting its environment, and by taking action, with some degree of autonomy, to achieve specific goals;
- ‘autonomous’ means an AI system that operates by interpreting certain input, and by using a set of predetermined instructions, without being limited to such instructions, despite the system’s behaviour being constrained by and targeted at fulfilling the goal it was given and other relevant design choices made by its developer;
‘Simulating intelligence’ sounds reasonable, but actually just moves the problem on, to defining what is, or is not, intelligence. If intelligence is judged on an activity by activity bases, will self-driving cars be required to have the avoidance skills of a fly, while other activities might have to be on par with those of birds? There is a commission working document that defines: “Autonomous AI, or artificial super intelligence (ASI), is where AI surpasses human intelligence across all fields.”
The ‘autonomous’ component of the definition is so broad that it covers a wide range of programs that are not currently considered to be AI based.
The impact of the proposed update is that machinery products containing AI software are going to incur expensive conformance costs, which products containing non-AI software won’t have to pay.
Today it does not cost companies to claim that their systems are AI based. This will obviously change when a significant cost is involved. There is a parallel here with companies that used to claim that their beauty products provided medical benefits; the Federal Food and Drug Administration started requiring companies making such claims to submit their products to the new drug approval process (which is hideously expensive), companies switched to claiming their products provided “… the appearance of …”.
How are vendors likely to respond to the much higher costs involved in selling products that are considered to contain ‘AI software’?
Those involved in the development of products labelled as ‘safety critical’ try to prevent costs escalating by minimizing the amount of software treated as ‘safety critical’. Some of the arguments made for why some software is/is not considered safety critical can appear contrived (at least to me). It will be entertaining watching vendors, who once shouted “our products are AI based”, switching to arguing that only a tiny proportion of the code is actually AI based.
A mega-corp interested in having their ‘AI software’ adopted as an industry standard could fund the work necessary for the library/tool to be compliant with the EU directives. The cost of initial compliance might be within reach of smaller companies, but the cost of maintaining compliance as the product evolves is something that only a large company is likely to be able to afford.
The EU’s updating of its machinery directive is the first step towards formalising a legal definition of intelligence. Many years from now there will be a legal case that creates what later generation will consider to be the first legally accepted definition.
The impact of believability on reasoning performance
What are the processes involved in reasoning? While philosophers have been thinking about this question for several thousand years, psychologists have been running human reasoning experiments for less than a hundred years (things took off in the late 1960s with the Wason selection task).
Reasoning is a crucial ability for software developers, and I thought that there would be lots to learn from the cognitive psychologists research into reasoning. After buying all the books, and reading lots of papers, I realised that the subject was mostly convoluted rabbit holes individually constructed by tiny groups of researchers. The field of decision-making is where those psychologists interested in reasoning, and a connection to reality, hang-out.
Is there anything that can be learned from research into human reasoning (other than that different people appear to use different techniques, and some problems are more likely to involve particular techniques)?
A consistent result from experiments involving syllogistic reasoning is that subjects are more likely to agree that a conclusion they find believable follows from the premise (and are more likely to disagree with a conclusion they find unbelievable). The following is perhaps the most famous syllogism (the first two lines are known as the premise, and the last line is the conclusion):
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Would anybody other than a classically trained scholar consider that a form of logic invented by Aristotle provides a reasonable basis for evaluating reasoning performance?
Given the importance of reasoning ability in software development, there ought to be some selection pressure on those who regularly write software, e.g., software developers ought to give a higher percentage of correct answers to reasoning problems than the general population. If the selection pressure for reasoning ability is not that great, at least software developers have had a lot more experience solving this kind of problem, and practice should improve performance.
The subjects in most psychology experiments are psychology undergraduates studying in the department of the researcher running the experiment, i.e., not the general population. Psychology is a numerate discipline, or at least the components I have read up on have a numeric orientation, and I have met a fair few psychology researchers who are decent programmers. Psychology undergraduates must have an above general-population performance on syllogism problems, but better than professional developers? I don’t think so, but then I may be biased.
A study by Winiger, Singmann, and Kellen asked subjects to specify whether the conclusion of a syllogism was valid/invalid/don’t know. The syllogisms used were some combination of valid/invalid and believable/unbelievable; examples below:
Believable Unbelievable
Valid
No oaks are jubs. No trees are punds.
Some trees are jubs. Some Oaks are punds.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
Invalid
No tree are brops. No oaks are foins.
Some oaks are brops. Some trees are foins.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees. |
The experiment was run using an online crowdsource site, and 354 data sets were obtained.
The plot below shows the impact of conclusion believability (red)/unbelievability (blue/green) on subject performance, when deciding whether a syllogism was valid (left) or invalid (right), (code+data):
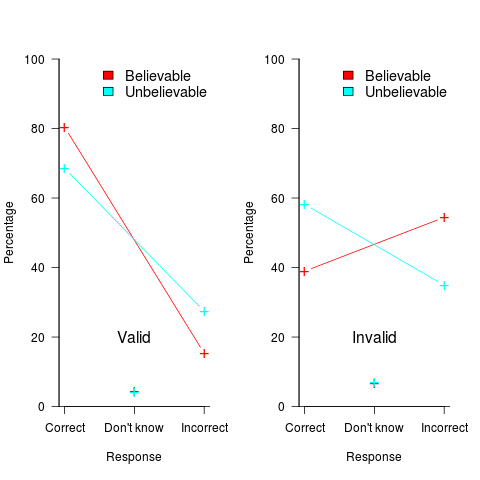
The believability of the conclusion biases the responses away/towards the correct answer (the error bars are tiny, and have not been plotted). Building a regression model puts numbers to the difference, and information on the kind of premise can also be included in the model.
Do professional developers exhibit such a large response bias (I would expect their average performance to be better)?
People tend to write fewer negative tests, than positive tests. Is this behavior related to the believability that certain negative events can occur?
Believability is an underappreciated coding issue.
Hopefully people will start doing experiments to investigate this issue 🙂
Time-to-fix when mistake discovered in a later project phase
Traditionally the management of software development projects divides them into phases, e.g., requirements, design, coding and testing. A mistake introduced in one phase may not be detected until a later phase. There is long-standing folklore that earlier mistakes detected in later phases are much much more costly to fix persists, despite the original source of this folklore being resoundingly debunked. Fixing a mistake later is likely to a bit more costly, but how much more costly? A lack of data prevents reliable analysis; this question also suffers from different projects having different cost-to-fix profiles.
This post addresses the time-to-fix question (cost involves all the resources needed to perform the fix). Does it take longer to correct mistakes when they are detected in phases that come after the one in which they were made?
The data comes from the paper: Composing Effective Software Security Assurance Workflows. The 35,367 (yes, thirty-five thousand) logged fixes, from 39 projects drawn from three organizations, contains information on: phases in which the mistake was made and fixed, time taken, person ID, project ID, date/time, plus other stuff 🙂
Every project has its own characteristics that affect time-to-fix. Project 615, avionics software developed by organization A, has the most fixes (7,503) and is analysed here.
Avionics software is safety critical, and each major phase included its own review and inspection. The major phases include: requirements gathering, requirements analysis, high level design, design, coding, and testing. When counting the number of phases between introduction/fix, should review and inspection each count as a phase?
The primary reason for doing a review and inspection is to check the correctness (i.e., lack of mistakes) in the corresponding phase. If there is a time-to-fix penalty for mistakes found in these symbiotic-phases, I suspect it will be different from the time-to-fix penalty between major phases (which for simplicity, I’m assuming is major-phase independent).
The time-to-fix has a resolution of 1-minute, and some fix times are listed as taking a minute; 72% of fixes are recorded as taking less than 10-minutes. What kind of mistakes require less than 10-minutes to fix? Typos and other minutiae.
The plot below shows time-to-fix for mistakes having a given ‘distance’ between introduction/fix phase, for fixes taking at least 1, 5 and 10-minutes (code+data):
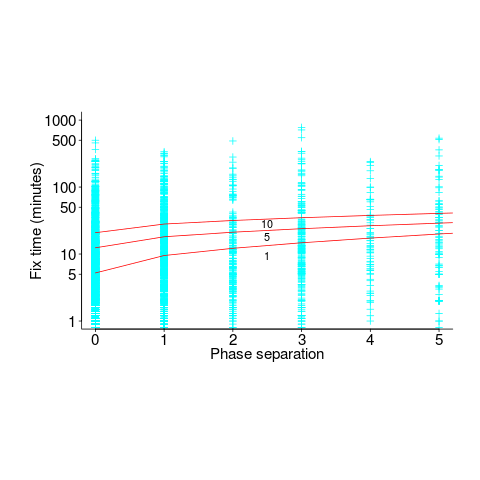
There is a huge variation in time-to-fix, and the regression lines (which have the form:  ) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
All but one of the 38 people who worked on the project made multiple fixes (30 made more than 20 fixes), and may have got faster with practice. Adding the number of previous fixes by people making more than 20 fixes to the model gives:  , and improves the model by less than 1-percent.
, and improves the model by less than 1-percent.
Fixing mistakes is a human activity, and individual performance often has a big impact on fitted models. Adding person ID to the model as a multiplication factor: i.e.,  , improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of
, improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of  varies between 0.66 and 1.4 (factor of two, human variation).
varies between 0.66 and 1.4 (factor of two, human variation).
The answer to the time-to-fix question posed earlier (for project 615), is that it does take slightly longer to fix a mistake detected in phases occurring after the one in which the mistake was introduced. The phase difference is tiny, with differences in human performance having a bigger impact.
Recent Comments