Archive
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
MC/DC a step towards safety critical Open source software
Open source projects and safety critical software are at opposite ends of the development process spectrum. From the user perspective, when an Open source project becomes very widely used within its application domain, there is a huge incentive to run it within safety critical domains.
How might software that was not originally developed using a safety critical process be certified for use in a safety critical domain?
A mass of process bureaucracy has sprung up around building software systems whose correct operation is depended on in safety critical situations. There is no evidence that any process bureaucracy produces more reliable software than any other process bureaucracy, and organizations adapt processes to fit within the rules and deliver a system given the available funding.
Some processes specify measurable output requirements, and being able to show that a program developed using an Open source process meets the desired measurable requirements is a step on the path to possible certification. One of the requirements specified in DO-178C (“Software Considerations in Airborne Systems and Equipment Certification”, a non-free publication) for level A: Anomalous behavior produces a catastrophic failure condition, is 100% Modified condition/decision coverage (MC/DC) of the source code. In the automotive world, the same coverage requirement is specified for Automotive Safety Integrity Level D of ISO 26262. As far as I know, the only DO-178C certified Open source program, at this level (which does not imply being safety critical), is SQLite.
The two main hurdles to the adoption of MC/DC by Open source projects are the huge amount of work involved in creating the necessary tests and, until recently, the lack of industrial strength Open source tools for measuring MC/DC (there are many commercial tools).
While compiler support for statement coverage has long been available in both GCC and clang, support for MC/DC only became available in an official release of clang this year (the initial functionality was pushed in 2021). The official releases of GCC do not yet support MC/DC, but a patch has been available since 2022 (talk by author).
Making available an industrial strength Open source compiler that supports MC/DC testing removes one barrier on the path to DO-178C certification of Open source programs. The certification process itself requires that support tools meet certain minimum requirements, which are specified in DO-330. A tool used as part of the verification process of a program at Level A needed not itself have 100% MC/DC, or even 100% statement coverage. The LLVM project tracks statement coverage, which is not even close to 100%.
Are there any coding constructs that get in the way of achieving 100% MC/DC?
It’s possible to write a condition that cannot be tested in a way that meets the MC/DC requirement: Each condition in a decision is shown to independently affect the outcome of the decision. For instance, in the following condition:
if ((A && B) || (!A && C)) |
the value of the variable A affects the outcome of both operands of ||, and the complete expression cannot be rewritten, using just A, B, C, to change this situation. The complete boolean expression is said to be strongly coupled. An expression involving the same variable in multiple relational or equality tests (e.g., (x > 0) && (x < 10)) is said to be weakly coupled.
An analysis of the Ada source code (appendix C) contained in five aircraft flight recorders finds examples of strongly and weakly coupled conditions. This suggests that occurrences of these construct in source code does not prevent a program becoming DO-178C certified.
Linux must be the prime candidate for an Open source program being considered for some kind of safety critical certification. A kernel patch to support MC/DC profiling is in the works (with a kernel MC/DC of around 2.33%, lots of new tests are going to have to be written). Lots of other significant certification requirements also need to be met.
In C, around 90% of if-statements contain a single conditional test (statement 1739), while in Java around 90% of if-statements contain a single conditional test, with around 0.1% containing five or more.
A kind of coverage that is not so often discussed is object code structural coverage, i.e., coverage based on the conditions contained in generated machine code, such as from a compiler. Object code coverage is designed to handle the possibility of compilers generating code containing conditions that are not present in the original source.
Some compilers generate the same machine code for both top level if-statements in the following code:
int g; void square(int a, int b, int c) { if (a && b && c) g++; if (a) if (b) if (c) g++; } |
Memory capacity growth: a major contributor to the success of computers
The growth in memory capacity is the unsung hero of the computer revolution. Intel’s multi-decade annual billion dollar marketing spend has ensured that cpu clock frequency dominates our attention (a lot of people don’t know that memory is available at different frequencies, and this can have a larger impact on performance that cpu frequency).
In many ways memory capacity is more important than clock frequency: a program won’t run unless enough memory is available but people can wait for a slow cpu.
The growth in memory capacity of customer computers changed the structure of the software business.
When memory capacity was limited by a 16-bit address space (i.e., 64k), commercially saleable applications could be created by one or two very capable developers working flat out for a year. There was no point hiring a large team, because the resulting application would be too large to run on a typical customer computer. Very large applications were written, but these were bespoke systems consisting of many small programs that ran one after the other.
Once the memory capacity of a typical customer computer started to regularly increase it became practical, and eventually necessary, to create and sell applications offering ever more functionality. A successful application written by one developer became rarer and rarer.
Microsoft Windows is the poster child application that grew in complexity as computer memory capacity grew. Microsoft’s MS-DOS had lots of potential competitors because it was small (it was created in an era when 64k was a lot of memory). In the 1990s the increasing memory capacity enabled Microsoft to create a moat around their products, by offering an increasingly wide variety of functionality that required a large team of developers to build and then support.
GCC’s rise to dominance was possible for the same reason as Microsoft Windows. In the late 1980s gcc was just another one-man compiler project, others could not make significant contributions because the resulting compiler would not run on a typical developer computer. Once memory capacity took off, it was possible for gcc to grow from the contributions of many, something that other one-man compilers could not do (without hiring lots of developers).
How fast did the memory capacity of computers owned by potential customers grow?
One source of information is the adverts in Byte (the magazine), lots of pdfs are available, and perhaps one day a student with some time will extract the information.
Wikipedia has plenty of articles detailing cpu performance, e.g., Macintosh models by cpu type (a comparison of Macintosh models does include memory capacity). The impact of Intel’s marketing dollars on the perception of computer systems is a PhD thesis waiting to be written.
The SPEC benchmarks have been around since 1988, recording system memory capacity since 1994, and SPEC make their detailed data public 🙂 Hardware vendors are more likely to submit SPEC results for their high-end systems, than their run-of-the-mill systems. However, if we are looking at rate of growth, rather than absolute memory capacity, the results may be representative of typical customer systems.
The plot below shows memory capacity against date of reported benchmarking (which I assume is close to the date a system first became available). The lines are fitted using quantile regression, with 95% of systems being above the lower line (i.e., these systems all have more memory than those below this line), and 50% are above the upper line (code+data):
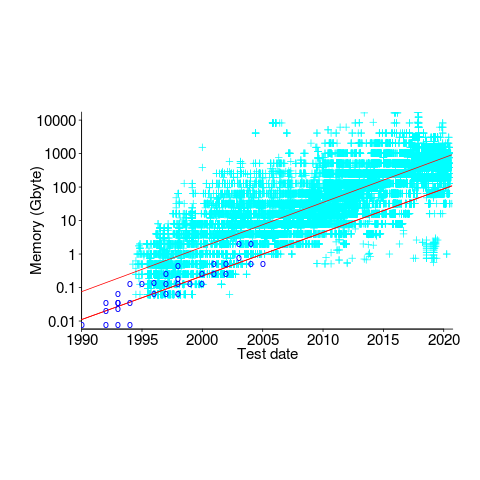
The fitted models show the memory capacity doubling every 845 or 825 days. The blue circles are memory that comes installed with various Macintosh systems, at time of launch (memory doubling time is 730 days).
How did applications’ minimum required memory grow over time? I have a patchy data for a smattering of products, extracted from Wikipedia. Some vendors probably required customers to have a fairly beefy machine, while others went for a wider customer base. Data on the memory requirements of the various versions of products launched in the 1990s is very hard to find. Pointers very welcome.
Growth and survival of gcc options and processor support
Like any actively maintained software, compilers get more complicated over time. Languages are still evolving, and options are added to control the support for features. New code optimizations are added, which don’t always work perfectly, and options are added to enable/disable them. New ways of combining object code and libraries are invented, and new options are added to allow the desired combination to be selected.
The web pages summarizing the options for gcc, for the 96 versions between 2.95.2 and 9.1 have a consistent format; which means they are easily scrapped. The following plot shows the number of options relating to various components of the compiler, for these versions (code+data):
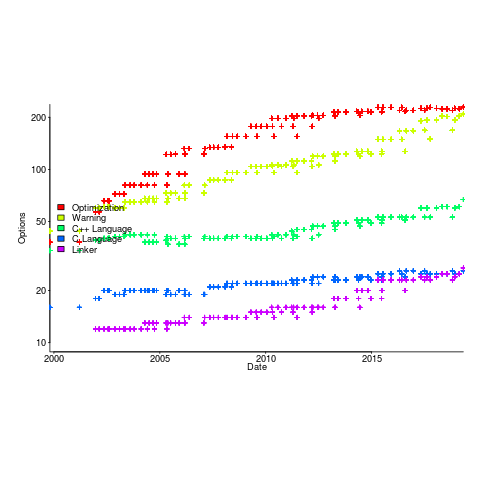
The total number of options grew from 632 to 2,477. The number of new optimizations, or at least the options supporting them, appears to be leveling off, but the number of new warnings continues to increase (ah, the good ol’ days, when -Wall covered everything).
The last phase of a compiler is code generation, and production compilers are generally structured to enable new processors to be supported by plugging in an appropriate code generator; since version 2.95.2, gcc has supported 80 code generators.
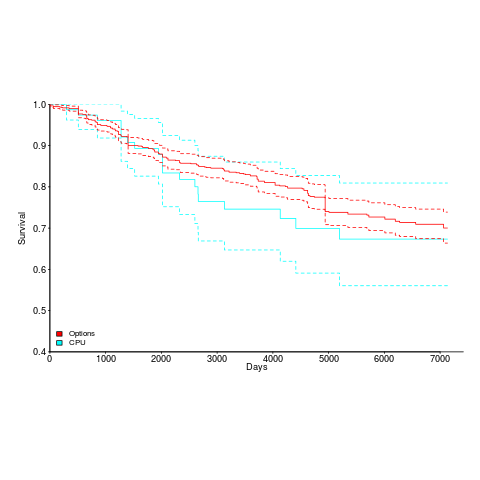
What can be added can be removed. The plot below shows the survival curve of gcc support for processors (80 supported cpus, with support for 20 removed up to release 9.1), and non-processor specific options (there have been 1,091 such options, with 214 removed up to release 9.1); the dotted lines are 95% confidence internals.
Users of Open source software are either the product or are irrelevant
Users of software often believe that the people who produced it are interested in the views and opinions of their users.
In a commercial environment there are producers who are interested in what users have to say, because of the financial incentive, and some Open source software exists within this framework, e.g., companies selling support services for the code they have Open sourced.
Without a commercial framework why would any producer of Open source be interested in the views and opinions of users? Answers include:
- users are the product: I have met developers who are strongly motivated by the pleasure they get from being at the center of a community, i.e., the community of people using the software that they are actively involved in creating,
- users are irrelevant: other developers are more strongly motivated by the pleasure of building things and in particular building using what are considered to be the right tools and techniques, i.e., the good-enough approach is not considered to be good-enough.
How do these Open source dynamics play out in the evolution of software systems?
It is the business types who are user oriented or rather source of money oriented. They are the people who stop developers from upsetting customers by introducing incompatibilities with previous releases, in fact a lot of the time its the business types pushing developers to concentrate on fixing problems and not wasting time doing more interesting stuff.
Keeping existing customers happy often means that products change slowly and gradually ossify (unless the company involved has a dominant market position that forces users to take what they are given).
A project primarily fueled its developers’ desire for pleasure cannot stand still, it has to change. Users who complain that change has an impact on their immediate need for compatibility get told that today’s pain is necessary for a brighter future tomorrow.
An example of users as the product is gcc. Companies pay people to work on gcc because they want access to the huge amount of software written by ‘the product’ using gcc.
As example of users as irrelevant is llvm. Apple is paying for llvm to happen and what does this have to do with anybody else using it?
The users of Angular.js now know what camp they are in.
As Bob Dylan pointed out: “Just because you like my stuff doesn’t mean I owe you anything.”
Adverts during compilation; the future for gcc and llvm?
Many of the larger open source projects have most of their manpower supplied by commercial companies. Companies pay developers to work on open source projects because it is in their interest to do so. The current level of funding will not last forever and some open source projects will either have to significantly slim down their operations or find other revenue streams.
For the last few years (and probably the next few) Mozilla obtained most of its funding from Google through a licensing agreement (Google is the default search engine in the search box). No company wants to be dependent on a single source for a large chunk of its income and Mozilla is no exception. But where are the review streams for open source companies? Training and consulting are the obvious choices for technical products, but web browsers are supposed to user friendly, not technical. Another option is advertising and Mozilla has indicated an intent to go down this path.
How are open source compilers funded? A lot of the work on gcc used to be done by the folk at Code Sourcery, which is not owned by Mentor Graphics, and I was told their income primarily came from companies interested in ports to new processors and platforms. I have no idea how the gcc group is funded inside Mentor Graphics, but the long term prognosis does not look good; there is a long history of large tech companies buying compiler outfits and closing them down some years later (because the income they produce is not worth the hassle). The LLVM project, I’m told, gets most of its funding from Apple and one of my predictions for 2009 was that this funding would go away and LLVM would die; ok I was wrong about the year, but eventually Apple will stop funding this project.
Advertising is a possible revenue stream for compiler vendors; compilers could show adverts while compiling. Anybody who has used a commercial compiler will be familiar with the copyright notices that appear at the start of every compilation, so having a text message appear at the start of every compile is not new. Advertising could take the form of product placement “This version of gcc is brought to you by Wizzo Wash” or display material downloaded during compilation.
Adverts during compilation are not going to be popular with developers. One solution is to offer a subscription service for an ads free version of the compiler. It will certainly be necessary to make it much more difficult to build the compiler from source.
This form of revenue generation will have to be sold to developers; a group not known for its willingness to pay for tools (new tool vendors quickly learn to sell to management and ignore developers) combined with compiler writers not being known for having any selling ability.
Testing compiler semantics with minimal manual input
The 2011 revision of the C++ Standard added lots of new constructs to the language and in the past few months both the GCC and LLVM teams have been claiming that the next release of their C++ compilers will fully support the 2011 Standard. How true are these claims? One way of answering this question is to run both compilers over an extensive test suite. There are commercial C++ compiler test suites available, but I don’t have access to them and if I did the license agreement would probably not allow me to talk in detail about the results. Writing compiler tests cases requires a very detailed knowledge of the language; I have done it often enough in previous lives to know that more than a year or so of my time would be needed just to get my head around the semantics of the new C++ features, before I could produce anything half decent.
Is there a way of automating the generation of test cases for language semantics? Automated statement/expression generation is very effective at finding problems with optimizers and code generators. Can this technique be applied to check the semantic requirements of a language?
Having concocted various elaborate schemes over the years I recently realised that life would be a lot simpler if I was willing to accept a very high percentage of erroneous test programs (the better manually written test suites usually contain around as many test cases that intended to fail to compile as tests that pass, i.e., intended to compile correctly; the not so good ones have few failing tests).
If two or more compilers are available the behavior of each of them on a given source file can be compared: differential testing. If both compile a file or fail to compile it, they may both be right or wrong; either way this shared behavior is not interesting, but is likely to be the common case. The interesting case is if one compiles a file and the other fails to compile it; this could be a fault in one of them, or one of those cases where the Standard permits compilers to do their own thing.
I hereby jump to the conclusion that behavior differences is a good proxy for compiler conformance to the language Standard (actually developers are often more interested in all compilers they are likely to use having the same external behavior than conforming to a Standard).
Lets implement this (source code here)!
First we need to generate lots of test cases. The process I used is based on program templates, such as the following (lines starting with ! are places where various constructs can be inserted):
int v; ! declare_id 2 int main(void) { ! declare_id 2 ! ref_id 2 } |
the identifier after the ! is the name of a file containing lines to be inserted at the given location (the number after the identifier is the maximum number of lines that can be inserted at that point; default 1 if no number given). The following is example file contents for the above template:
declare_id
int i; enum {i, j}; enum i {x, y}; struct i {int f;}; typedef int i; |
ref_id
enum i ev_i; struct i sv_i; typedef i tv_i; v=i; |
It is then simply a matter of permuting through all of the possible combinations of lines that can be inserted in the program template, creating a stand alone file for each possibility (18,000 of them in the above example); I used the Python Natural Language Toolkit to do the heavy lifting.
A shell script compiles each source file and compares the compiler exit codes. For the above example there were 16,366 failures, 1,634 passes and no differences (this example contains well established C constructs and any difference would have been surprising).
Next, a feature new in C++11, lambda functions!
Here is the template used:
! declare_xy 2 int main(void) { ! declare_xy 2 auto foo_bar = ! define_lambda ; return 0; } |
I cut and pasted some examples from the Standard to create the following optional lines:
define_lambda
[](float a, float b) { return a + b; } [=](float a, float b) { return a + b; } [=,x](float a, float b) { return a + b; } [y](float a, float b) { return a + b; } [=]()->int { return operator()(this->x + y); } [&, i]{ } [=] { decltype(x) y1; decltype((x)) y2 = y1; decltype(y) r1 = y1; decltype((y)) r2 = y2; } |
which generated 6,300 source files of which 5,865 failed, 396 passed and 39 were treated differently by the compilers (g++ version 4.7.2, clang version 3.3).
How should the percentages be calculated? If we take the human written numbers for well written test suites containing (roughly) equal numbers of pass/fail tests, then we have around 800 tests of which (say) 40 gave different behavior, giving us a 5% fault rate. Do we share that 5% equally between both compilers or assign 3% for both being wrong and 1% for each being uniquely wrong?
Submitting a bug report to both compiler teams pointing out that their behavior is different from the other’s is a sure fire way to make myself unpopular. Any suggestions for how to resolve this issue, that does not involve me having to study the tiresomely long and convoluted C++ Standard, welcome.
Impact of compiler optimization level on recovery from a hardware error
I have previously written about cosmic-ray induced faults in cpus and some of the compiler research being done to recover from such hardware faults. If your program is executing in an environment where radiation may cause hardware bit-flips to occur and you don’t have access to a research compiler providing some level of recovery, is it better to compile with high or low levels of optimization?
Short answer: Using gcc with optimization options O2 or O3 reduces the probability that a bit-flip will change the external behavior of a program, compared to option O0.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Software masking of hardware faults
Like all hardware cpus are subject to intermittent faults, these faults may flip the value of a bit in a program visible register, a bit in an executable instruction or some internal processor state (causes include cosmic rays, and electrical wear of the material from which circuits are built).
If a bit-flip randomly occurs at some point during a program’s execution, is it less likely to effect external program behavior when the code has been built with high levels of compiler optimization or built with optimization disabled or at a low level?
- many optimizations reduce the number of instructions executed (reducing execution time reduces the probability of encountering a bit-flip) and makes more efficient use of registers (e.g., keeping needed values in registers over longer periods of time and reducing the time intervals when a registers is not in use; which increases the probability that a bit-flip will propagate to external behavior),
- fewer compiler optimizations is likely to result in an increased number of instructions executed (increasing the probability that a bit-flip will occur during program execution) and results in lower register usage efficiency (e.g., longer periods of time between the last use of register contents and a new value being loaded; increasing the probability that a bit-flip will modify a value that is never used again).
A study by Cook and Zilles flipped one bit in an executing program (100 evenly distributed points in the program were chosen and 100 instructions from each of those points were used as fault injection points, giving a total of 10,000 individual tests to be run) and monitored the impact on subsequent execution; this process was repeated between 32 and 244 times for each injection point, once for every bit in the 32-bit instruction, zero, one or two of its 64-bit input registers and one possible 64-bit output result register (i.e., the bit-flip only involved the current instruction and its input/output, not the contents of any other register or main memory).
The monitoring process consisted of two parallel executions containing the modified processor state and the unmodified processor state. The behavior of the two executions were compared to see if the fault did not propagate (a passing trial, e.g., a bit-wise AND of a register with 0xff when a bit-flip has been applied to one of the top 24 bits of the register, also the values in a branch not-equal are usually not-equal and a bit-flip is likely to maintain that state), caused a failure (either due to a compulsory event caused by a hardware trap such as an invalid instruction or an incorrectly aligned memory access, or what was called an error model event such as a control flow mismatch or writing a different value to storage), or is inconclusive (pass/fail did not occur within 10,000 executed instructions of the fault injection point).
Data
The available data consists of the normalised number of program executions having one of the behaviors pass, fail (compulsory), fail (error model, broken down into control flow and store related cases) or inconclusive for nine programs from the SPEC2000 integer benchmark compiled using gcc version 4.0.2 and the DEC C compiler (henceforth called O0, O2 and O3, for osf the O4 option was used.
There are nine measurements for each of the nine SPEC programs, repeated at 3 optimization levels for gcc and once for osf (the osf data is not analysed here).
Is the data believable?
Injecting bit-flip faults at all points in a program and monitoring for subsequence changes in external behavior would be an enormous task, sets of 100 instructions starting from 100 locations appears to be an unbiased sample.
The error model used checks for changes of control flow and different values being stored to memory, it does not check for actual changes in external program behavior. This model biases the measurements in favour of more bit-flips being counted as generating an error than would occur in practice.
Predictions made in advance
Does compiler optimization level change the probability that a bit-flip will cause a change in external program behavior?
No hypothesis is proposed suggesting that compiler optimization level will increase, decrease or have no effect on the probability of a bit-flip effecting external program behavior.
Applicable techniques
The data was originally a count of the number of instances and this has been normalised to a value between 0 and 100. The same number of programs were executed at all optimization levels.
Non-parametric techniques have to be used because nothing is known about the distribution of values.
The [Wilcoxon signed-rank test] is a test for two dependent samples while the [Mann-Whitney U test] is a test for two independent samples. To what extent does running gcc at different optimization levels make it a different compiler? Given that we are testing for the possibility that compiler optimizations do effect the results then it is necessary to treat the samples as being independent.
The function wilcox.test will perform a Mann-Whitney test if the parameter paired is FALSE (the default) and will generate a confidence interval if the parameter conf.int is TRUE (the default is FALSE).
Results
The Mann-Whitney test of the various measurements obtained using the O2 and O3 options finds no worthwhile difference between them. There are interesting differences in the values obtained using both of two options and the O0 option, as follows:
- Pass
-
Comparing percentage of pass behaviors for
O0andO2we see: p-values = 0.005 and 0.005
> wilcox.test(gcc.o0$pass.masked, gcc.o2$pass.masked, conf.int=TRUE)
Wilcoxon rank sum test with continuity correction
data: gcc.o0$pass.masked and gcc.o2$pass.masked
W = 8, p-value = 0.004697
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-15.449995 -2.020001
sample estimates:
difference in location
-7.480088
The wilcox.test function returns an estimate of the difference between the two means and a negative value occurs if the second argument (the higher optimization level in this case) has a greater mean than the first argument (which is always the O0 option in these results).
O0/O3 95% confidence interval: -15.579959 -1.909965, mean: -4.780058
- Fail (compulsory)
-
-
Memory protection fault: pvalues = 0.002 and 0.005
O0/O295%: 2.1 7.5, mean: 4.9
O0/O395%: 1.9 7.3, mean: 4.1 -
Invalid instruction: p-values = 0.045 and 0.053
O0/O295%: -8.0e-01 -4.9e-08, mean: -0.5
O0/O395%: -6.4e-01 5.1e-06, mean: -0.3
-
Memory protection fault: pvalues = 0.002 and 0.005
- Fail (error model)
-
-
Control flow: p-values = 0.0008 and 0.002
O0/O295%: -10.8 -3.8, mean: -7.0
O0/O395%: -10.5 -3.7, mean: -6.8 -
Store related: p-values = 0.002 and 0.003
O0/O295%: 4.78 22.02, mean: 11.24
O0/O395%: 4.93 18.78, mean: 10.51
-
Control flow: p-values = 0.0008 and 0.002
Discussion
O2 and O3 options differences
The issue of optimization performance differences between the gcc O2 and O3 options is covered in [another section] of this book. That analysis found that the only difference between the two options was an increase in code size with O3, probably because of function inlining.
If there is no significant difference in the code generated by the O2/O3 options then no difference in bit-flip behavior is expected, and none was seen.
Changes in failure rates
The results show a decrease in store related errors at high optimization levels and an increase in control flow related errors. Why is this?
Optimizing register usage is a very important optimization and one of its consequences is a reduction in the number of stores to memory and loads having a corrupted address triggering a protection fault . A reduction in the number of memory related instructions executed will feed through into a reduction in the number of failures classified as store related or memory protection faults and this is seen in the shift in mean value of fails between high and low optimization levels.
Keeping a value containing an injected bit-flip in a register for a longer period of program execution (rather than being stored to memory and loaded back later) provides the opportunity for it to work its way through subsequent instructions and either disappear (being counted as a pass) or cause a control flow failure. It is likely that some of the change stored values flagged by the error model do not an impact on external program behavior and the pass count at low optimization levels is lower than would occur in practice.
Changes in pass rate
The additional optimizations of register usage enabled by the O2/O3 options reduces memory accesses which leads to a reduction in memory protection errors, an unrecoverable fault under all circumstances. The numbers suggest that while this is a major factor in the increased pass rate, contributions are made by other sources, e.g., bit-flips not contributing to the result calculated by an instruction; the data is not sufficiently detailed to enable a reliable estimate of this contribution to be made.
The pass rate is likely to be an underestimate because the error model classifies storing a different value as a failure, however the different value might not result in a change of external program behavior, e.g., the value stored might never be used again. Some of the stores classified as errors for the O0 option have no lasting affect in practice (and being kept in registers for O2/O3 had the opportunity to be masked out). No data is available for enable an estimate to be made for the percentage of these bit-flips have no lasting affect.
The average pass rate for gcc using the O0 option was 28% and this increased to around 36% when the O2/O3 options were used.
Other processors
How likely is it that the bit-flip pass rates seen on the Alpha (average of 36% for high optimization, 28% for low) would also occur on other processors?
The Alpha registers contain 64-bit and instructions operating on just 32 or 16 of those bits are supported. A study by Loh of the Alpha running SPEC2000 programs found that 48% of executed instructions operated on 64-bits, 24% on 32-bits and 28% on 16-bits. Based on these numbers 33% of single bit-flips of a 64-bit register would not be expected to affect the result of an instruction (the table below gives the percentages measured by Cook et al).
| injection site | O3 | O2 | O0 |
|---|---|---|---|
|
instruction
|
28.2
|
29.2
|
21.3
|
|
input register1
|
49.0
|
50.0
|
40.5
|
|
input register2
|
26.5
|
28.5
|
17.9
|
|
output register
|
39.6
|
41.9
|
34.7
|
A lot of software is based on using 32-bit integers and it might be expected that a much lower percentage of register bit-flips would result in pass behavior, compared to a 64-bit processor (where most operations that access 64 bits involve addresses). However, 32-bit processors usually contain instructions for operating on just 8-bits of a register and use of these instructions creates more opportunities for bit-flips to have no lasting consequences.
The measurements of Cook and Zilles have shown how interrelated instruction set interactions are. Without measurements from 32-bit processors it is not possible to estimate the extent to which bit-flips will impact external program behavior.
Conclusion
Compiling source using high levels of compiler optimization reduces the likelihood that a randomly occurring bit-flip during program execution will effect external program behavior. For processors that perform memory access checks the largest decrease in bit-flip induced faults is a reduction in memory protection faults.
Optimization generally reduces the number of instructions executed by a program, reducing the probability that a bit-flip will occur between the start and end of execution, further increasing the advantage of optimized code over non-optimized.
Changes in optimization performance of gcc over time
The SPEC benchmarks came out a year after the first release of gcc (in fact gcc was and still is one of the programs included in the benchmark). Compiling the SPEC programs using the gcc option -O2 (sometimes -O3) has always been the way to measure gcc performance, but after 25 years does this way of doing things tell us anything useful?
The short answer: No
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Changes in optimization performance of gcc over time
The GNU Compiler Collection <book gcc-man_12> (GCC) is under active development with its most well known component, the C compiler gcc, now over 25 years old. After such a long period of development is the quality of code generated by gcc still improving and if so at what rate? The method typically used to measure compiler performance is to compile the [SPEC] benchmarks with a small set of optimization options switched on (e.g., the O2 or O3 options) and this approach is used for the analysis performed here.
Data
Vladimir N. Makarow measured the performance of 9 releases of gcc, occurring between 2003 and 2010, on the same computer using the same benchmark suite (SPEC2000); this data is used in the following analysis.
The data contains the [SPEC number] (i.e., runtime performance) and code size measurements on 12 integer programs (11 in C and one in C+\+) from SPEC2000 compiled with gcc versions 3.2.3, 3.3.6, 3.4.6, 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0 at optimization levels O2 and O3 (the mtune=pentium4 option was also used) 32-bit for the Intel Pentium 4 processor.
The same integer programs and 14 floating-point programs (10 in Fortran and 4 in C) were compiled for 64-bits, again with the O2 and O3 options (the mpc64 floating-point option was also used), using gcc versions 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0.
Is the data believable?
The following are two fitness-for-purpose issues associated with using programs from SPEC2000 for these measurements:
-
the benchmark is designed for measuring processor performance not
compiler performance, -
many of its programs have been used for compiler benchmarking for
many years and it is likely that gcc has already been tuned to do
well on this benchmark.
The runtime performance measurements were obtained by running each programs once, SPEC requires that each program be run three times and the middle one chosen. Multiple measurements of each program would have increased confidence in their accuracy.
Predictions made in advance
Developers continue to make improvements to gcc and it is hoped that its optimization performance is increasing, knowing that performance is at a steady state or decreasing performance is also of interest.
No hypothesis is proposed for how optimization performance, as measured by the O2 and O3 options, might change between releases of gcc over the period 2003 to 2010.
The gcc documentation says that using the O3 option causes more optimizations to be performed than when the O2 option is used and therefore we would expect better performance for programs compiled with O3.
Applicable techniques
Modelling individual O2 and O3 option performance
One technique for modelling changes in optimization performance is to build a linear model that fits the gcc version (i.e., version is the predictor variable) to the average performance of the code it generate, calculating the averaged performance over each of the programs measured with the corresponding version of gcc. The problem with this approach is that by calculating an average it is throwing away information that is available about the variation in performance across different programs.
Building a [mixed-effects] model would make use of all the data when fitting a relationship between two quantities where there is a recurring random component (i.e., the SPEC program used). The optimizations made are likely to vary between different SPEC programs, we could treat the performance variations caused by difference in optimization as being random and having an impact on the mean performance value of all programs.
Programs differ in the magnitude of their SPEC number and code size, the measurements were converted to the percentage change compared against the values obtained using the earliest version of gcc in the measurement set.
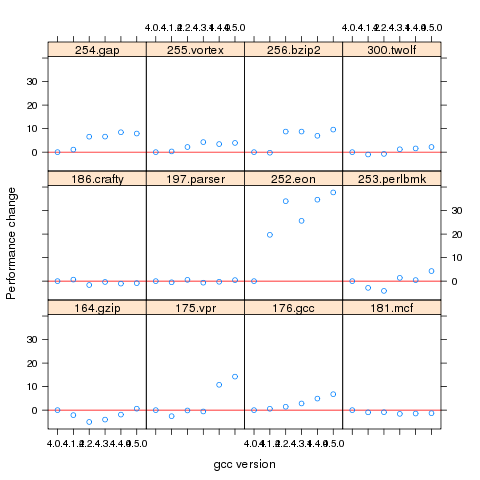
Figure 1. Percentage change in SPEC number (relative to version 4.0.4) for 12 programs compiled using 6 different versions of gcc (compiling to 64-bits with the O3 option).
Fitting a linear model requires at least two sets of [interval data]. The gcc version numbers are [ordinal values] and the following are two possible ways of mapping them to interval values:
-
there have been over 150 different released versions of gcc and a
particular version could be mapped to its place in this sequence. -
the date of release of a version can be mapped to the number of
days since the first release.
If version releases are organized around new functionality added then it makes sense to use version sequence number. If the performance of a new optimization was proportional to the amount of effort (e.g., man days) that went into its implementation then it would make sense to use days between releases.
The versions tested by Makarow were each from a different secondary release within a given primary version line and at roughly yearly intervals (two years separated the first pair and one month another pair).
There have been approximately 25 secondary releases in the 25 year project and using a release version sequence number starting at 20 seems like a reasonable choice.
Internally a compiler optimizer performs many different kinds of optimizations (gcc has over 160 different options for controlling machine independent optimization behavior). While the implementation of a new optimization is a gradual process involving many days of work, from the external user perspective it either exists and does its job when a given optimization level is supported or it does not exist.
What is the shape of the performance/release-version relationship? In the first few years of a compilers development it is to be expected that all the known major (i.e., big impact) optimization will be implemented and thereafter newly added optimizations have a progressively smaller impact on overall performance. Given gcc’s maturity it looks reasonable to assume that new releases contain a few additional improvement that have an incremental impact, i.e., the performance/release-version relationship is assumed to be linear (no other relationship springs out of a plot of the data).
A mixed-effects model can be created by calling the R function lme from the package nlme. The only difference between the following call to lme and a call to lm is the third argument specifying the random component.
t.lme=lme(value ~ variable, data=lme.O2, random = ~ 1 | Name) |
The argument random = ~ 1 | Name specifies that the random component effects the mean value of the result (when building a model this translates to an effect on the value of the intercept of the fitted equation) and that Name (of the program) is the grouped variable.
To specify that the random effect applies to the slope of the equation rather than its intercept the call is as follows:
t.lme=lme(value ~ variable, data=lme.O2, random = ~ variable -1 | Name) |
To specify that both the slope and the intercept are effected the -1 is omitted (for this gcc data the calculation fails to converge when both can be effected).
Since the measurements are about different versions of gcc it is to be expected that the data format has a separate column for each version of gcc (the format that would be used to pass data lm) as follows:
Name v3.2.3 v3.3.6 v3.4.6 v4.0.4 v4.1.2 v4.2.4 v4.3.1 v4.4.0 v4.5.0 1 164.gzip 933 932 957 922 933 939 917 969 955 2 175.vpr 562 561 577 576 586 585 576 589 588 3 176.gcc 1087 1084 1159 1135 1133 1102 1146 1189 1211 |
The relationship between the three variables in the call to lme is more complicated and the data needs to be reorganize so that one column contains all of the values, one the gcc version numbers and another column the program names. The function melt from package reshape2 can be used to restructure the data to look like:
Name variable value 11 256.bzip2 v3.2.3 0.000000 12 300.twolf v3.2.3 0.000000 13 SPECint2000 v3.2.3 0.000000 14 164.gzip v3.3.6 -0.107181 15 175.vpr v3.3.6 -0.177936 16 176.gcc v3.3.6 -0.275989 17 181.mcf v3.3.6 0.148810 |
Comparing O2 and O3 option performance
When comparing two samples the [Wilcoxon signed-rank test] and the [Mann-Whitney U test] spring to mind. However, some of the expected characteristics of the data violate some of the properties that these tests assume hold (e.g., every release include new/updated optimizations which is likely to result in the performance of each release having a different mean and variance).
The difference in performance between the two optimization levels could be treated as a set of values that could be modelled using the same techniques applied above. If the resulting model have a line than ran parallel with the x-axis and was within the appropriate confidence bounds we could claim that there was no measurable difference between the two options.
Results
The following is the output produced by summary for a mixed-effect model, with the random variation assumed to effect the value of intercept, created from the SPEC numbers for the integer programs compiled for 64-bit code at optimization level O2:
Linear mixed-effects model fit by REML
Data: lme.O2
AIC BIC logLik
453.4221 462.4161 -222.7111
Random effects:
Formula: ~1 | Name
(Intercept) Residual
StdDev: 7.075923 4.358671
Fixed effects: value ~ variable
Value Std.Error DF t-value p-value
(Intercept) -29.746927 7.375398 59 -4.033264 2e-04
variable 1.412632 0.300777 59 4.696612 0e+00
Correlation:
(Intr)
variable -0.958
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-4.68930170 -0.45549280 -0.03469526 0.31439727 2.45898648
Number of Observations: 72
Number of Groups: 12
|
and the following summary output is from a linear model built from an average of the data used above.
Call:
lm(formula = value ~ variable, data = lmO2)
Residuals:
13 26 39 52 65 78
0.16961 -0.32719 0.47820 -0.47819 -0.01751 0.17508
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -28.29676 2.22483 -12.72 0.000220 ***
variable 1.33939 0.09442 14.19 0.000143 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.395 on 4 degrees of freedom
Multiple R-squared: 0.9805, Adjusted R-squared: 0.9756
F-statistic: 201.2 on 1 and 4 DF, p-value: 0.0001434
|
The biggest difference is that the fitted values for the Intercept and slope (the column name, variable, gives this value) have a standard error that is 3+ times greater for the mixed-effects model compared to the linear model based on using average values (a similar result is obtained if the mixed-effects random variation is assumed to effect the slope and the calculation fails to converge if the variation is on both intercept and slope). One consequence of building a linear model based on averaged values is that some of the variations present in the data are smoothed out. The mixed-effects model is more accurate in that it takes all variations present in the data into account.
For integer programs compiled for 32-bits there is much less difference between the mixed-effects models and linear models than is seen for 64-bit code.
-
For SPEC performance the created models show:
-
for the integer programs a rate of increase of around 0.6% (sd
0.2) per release forO2andO3options on 32-bit code
and an increase of 1.4% (sd 0.3) for 64-bit code, -
for floating-point, C programs only, a rate of increase per
release of 12% (sd 5) at 32-bits and 1.4% (sd 0.7) at 64-bits, with
very little difference between theO2andO3options.
-
for the integer programs a rate of increase of around 0.6% (sd
-
For size of generated code the created models show:
-
for integer programs 32-bit code built using
O2size is
decreasing at the rate of 0.6% (sd 0.1) per release, while for both
64-bit code andO3the size is increasing at between 0.7% (sd
0.2) and 2.5% (sd 0.4) per release, -
for floating-point, C programs only, 32-bit code built using
O2had an unacceptable p-value, while for both 64-bit code
andO3the size is increasing at between 1.6% (sd 0.3) and
9.3 (sd 1.1) per release.
-
for integer programs 32-bit code built using
Comparing O2 and O3 option performance
The intercept and slope values for the models built for the SPEC integer performance difference had p-values way too large to be of interest (a ballpark estimate of the values would suggest very little performance difference between the two options).
The program size change models showed O3 increasing, relative to O2, at 1.4% to 1.7% per release.
Discussion
The average rate of increase in SPEC number is very low and does not appear to be worth bothering about, possible reasons for this include:
-
a lot of effort has already been invested in making sure that gcc
performs well on the SPEC programs and the optimizations now being
added to gcc are aimed at programs having other kinds of
characteristics, -
gcc is a mature compiler that has implemented all of the worthwhile
optimizations and there are no more major improvements left to be
made, -
measurements based on just setting the
O2orO3
options might not provide a reliable guide to gcc optimization
performance. The command
gcc -c -Q -O2 --help=optimizers
shows that for gcc version 4.5.0 theO2option enables 91 of
the possible 174 optimization options and theO3option
enables 7 more. Performing some optimizations together sometimes
results in poorer quality code than if a subset of those
optimizations had been applied (genetic programming is being
researched as one technique for selecting the best optimizations
options to use for a given program and up to 13% improvements have
been obtained over gcc’s -O options <book Bashkansky_07>). The
percentage performance change figure above shows
that for some programs performance decreases on some releases.Whole program optimization is a major optimization area that has been addressed in recent versions of gcc, this optimizations is not enabled by the
Ooptions.
The percentage differences in SPEC integer performance between the O2 and O3 options were very small, but varied too much to be able to build a reliable linear model from the values.
For SPEC program code size there is a significant different between the O2 and O3 options. This is probably explained by function inlining being one of the seven additional optimization enabled by O3 (inlining multiple calls to the same function often increases code size <book inlining> and changes to the inlining optimization over releases could result in more functions being inlined).
Conclusion
Either the optimizations added to gcc between 2003 and 2010 have not made any significant difference to the performance of the generated code or the established method of measuring gcc optimization performance (i.e., the SPEC benchmarks and the O2 or O3 compiler options) is no longer a reliable indicator.
Undefined behavior can travel back in time
The committee that produced the C Standard tried to keep things simple and sometimes made very short general statements that relied on compiler writers interpreting them in a ‘reasonable’ way. One example of this reliance on ‘reasonable’ behavior is the definition of undefined behavior; “… erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The wording in the Standard permits a compiler to process the following program:
int main(int argc, char **argv) { // lots of code that prints out useful information 1 / 0; // divide by zero, undefined behavior } |
to produce an executable that prints out “yah boo sucks”. Such behavior would probably be surprising to the developer who expected the code printing the useful information to be executed before the divide by zero was encountered. The phrase quality of implementation is heard a lot in committee discussions of this kind of topic, but this phrase does not appear in any official document.
A modern compiler is essentially a sophisticated domain specific data miner that happens to produce machine code as output and compiler writers are constantly looking for ways to use the information extracted to minimise the code they generate (minimal number of instructions or minimal amount of runtime). The following code is from the Linux kernel and its authors were surprised to find that the “division by zero” messages did not appear when arg2 was 0, in fact the entire if-statement did not appear in the generated code; based on my earlier example you can probably guess what the compiler has done:
if (arg2 == 0) ereport(ERROR, (errcode(ERRCODE_DIVISION_BY_ZERO), errmsg("division by zero"))); /* No overflow is possible */ PG_RETURN_INT32((int32)arg1 / arg2); |
Yes, it figured out that when arg2 == 0 the divide in the call to PG_RETURN_INT32 results in undefined behavior and took the decision that the actual undefined behavior in this instance would not include making the call to ereport which in turn made the if-statement redundant (smaller+faster code, way to go!)
There is/was a bug in Linux because of this compiler behavior. The finger of blame could be pointed at:
- the developers for not specifying that the function
ereportdoes not return (this would enable the compiler to deduce that there is no undefined behavior because the divide is never execute whenarg2 == 0), - the C Standard committee for not specifying a timeline for undefined behavior, e.g., program behavior does not become undefined until the statement containing the offending construct is encountered during program execution,
- the compiler writers for not being ‘reasonable’.
In the coming years more and more developers are likely to encounter this kind of unexpected behavior in their programs as compilers do more and more data mining and are pushed to improve performance. Other examples of this kind of behavior are given in the paper Undefined Behavior: Who Moved My Code?
What might be done to reduce the economic cost of the fallout from this developer ignorance/standard wording/compiler behavior interaction? Possibilities include:
- developer education: few developers are aware that a statement containing undefined behavior can have an impact on the execution of code that occurs before that statement is executed,
- change the wording in the Standard: for many cases there is no reason why the undefined behavior be allowed to reach back in time to before when the statement executing it is executed; this does not mean that any program output is guaranteed to occur, e.g., the host OS might delete any pending output when a divide by zero exception occurs.
- paying gcc/llvm developers to do front end stuff: nearly all gcc funding is to do code generation work (I don’t know anything about llvm funding) and if the US Department of Homeland security are interested in software security they should fund related front end work in gcc and llvm (e.g., providing developers with information about suspicious usage in the code being compiled; the existing
-Wallis a start).
Recent Comments