Archive
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
Functions reduce the need to remember lots of variables
What, if any, are the benefits of adding bureaucracy to a program by organizing a file’s source code into multiple function/method definitions (rather than a single function)?
Having a single copy of a sequence of statements that need to be executed at multiple points in a program reduces implementation effort, and any updates only need to be made once (reducing coding mistakes by removing the need to correctly make duplicate changes). A function/method is the container for this sequence of statements.
Why break code up into separate functions when each is only called once and only likely to ever be called once?
The benefits claimed from splitting code into functions include: making it easier to understand, test, debug, maintain, reuse, and scale development (i.e., multiple developers working on the same program). Our LLM overlords also make these claims, and hallucinate references to published evidence (after three iterations of pointing out the hallucinated references, I gave up asking for evidence; my experience with asking people is that they usually remember once reading something but cannot remember the source).
Regular readers will not be surprised to learn that there is little or no evidence for any of the claimed benefits. I’m not saying that the benefits don’t exist (I think there are some), simply that there have not been any reliable studies attempting to measure the benefits (pointers to such studies welcome).
Having decided to cluster source code into functions, for whatever reason, are there any organizational rules of thumb worth following?
Rules of thumb commonly involve function length (it’s easy to measure) and desirable semantic characteristics of distinct functions (it’s very hard to measure semantic characteristics).
Claims for there being an optimal function length (i.e., lines of code that minimises coding mistakes) turned out to be driven by a mathematical artifact of the axis used when plotting (miniscule) datasets.
Semantic rules of thumb such as: group by purpose, do one thing, and Single-responsibility principle are open to multiple interpretations that often boil down to personal preferences and experience.
One benefit of using functions that is rarely studied is the restricted visibility of local variables defined within them, i.e., only visible within the function body.
When trying to figure out what code does, readers have to keep track of the information contained in all the variables accessed. Having to track more variables not only increases demands on reader memory, it also increases the opportunities for making mistakes.
A study of C source found that within a function, the number of local variables is proportional to the square root of the number of statements (code+data). Assuming the proportionality constant is one, a function containing 100 statements might be expected to define 10 local variables. Splitting this function up into, say, four functions containing 25 statements, each is expected to define 5 local variables. The number of local variables that need to be remembered at the same time, when reading a function definition, has halved, although the total number of local variables that need to be remembered when processing those 100 statements has doubled. Some number of global variables and function parameters need to be added to create an overall total for the number of variables.
The plot below shows the number of locals defined in 36,617 C functions containing a given number of statements, the red line is a fitted regression model having the form:  (code+data):
(code+data):
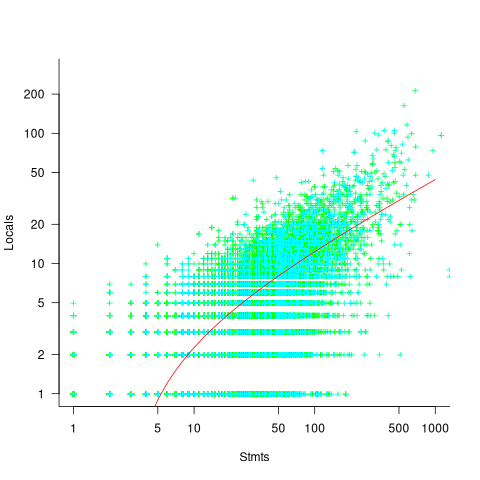
My experience with working with recently self-taught developers, especially very intelligent ones, is that they tend to write monolithic programs, i.e., everything in one function in one file. This minimal bureaucracy approach minimises the friction of a stream of thought development process for adding new code, and changing existing code as the program evolves. Most of these programs are small (i.e., at most a few hundred lines). Assuming that these people continue to code, one of two events teaches them the benefits of function bureaucracy:
- changes to older programs becomes error-prone. This happens because the developer has forgotten details they once knew, e.g., they forget which variables are in use at particular points in the code,
- the size of a program eventually exceeds their ability to remember all of it (very intelligent people can usually remember much larger programs than the rest of us). Coding mistakes occur because they forget which variables are in use at particular points in the code.
Some data on the size of Cobol programs/paragraphs
Before the internet took off in the 1990s, COBOL was the most popular language, measured in lines of code in production use. People who program in Cobol often have a strong business focus, and don’t hang out on sites used aggregated by surveys of programming language use; use of the language is almost completely invisible to those outside the traditional data processing community. So who knows how popular Cobol is today.
Despite the enormous quantity of Cobol code that has been written, very little Cobol source is publicly available (Open source or otherwise; the NIST compiler validation suite is not representative). The reason for the sparsity of source code is that Cobol programs are used to process business data, and the code is useless without the appropriate data (even with the data, the output is only likely to be of interest to a handful of people).
Program and function/method size (in LOC) are basic units of source code measurement. Until open source happened, published papers containing these measurements were based on small sample sizes and the languages covered was somewhat spotty. Cobol oriented research usually has a business orientation, rather than being programming oriented, and now there is a plentiful supply of source code written in non-Cobol languages.
I recently discovered appendix B of 1st Lt Richard E. Boone’s Master’s thesis An investigation into the use of software product metrics for COBOL systems (it’s post Rome period). Several days/awk scripts and editor macros later, LOC data for 178 programs containing 2,682 paragraphs containing 53,255 statements is now online (code+data).
A note on terminology: Cobol functions/methods are called paragraphs.
A paragraph is created by attaching a label to the first statement of the paragraph (there are no variables local to a paragraph; all variables are global). The statement PERFORM NAME-OF-PARAGRAPH ‘calls’ the paragraph labelled by NAME-OF-PARAGRAPH, somewhat like gosub number in BASIC.
It is possible to specify a sequence of paragraphs to be executed, in a PERFORM statement. The statement PERFORM NAME-OF-P1 THRU NAME-OF-P99 causes all paragraphs appearing textually in the code between the start of paragraph NAME-1 and the end of paragraph NAME-99 to be executed.
As far as I can tell, Boone’s measurements are based on individual paragraphs, not any sequences of paragraphs that are PERFORMed (it is likely that some labelled paragraphs are never PERFORMed in isolation).
Appendix B lists for each program: the paragraphs it contains, and for each paragraph the number of statements, McCabe’s complexity, maximum nesting, and Henry and Kafura’s Information flow metric
There are, based on naming, many EXIT paragraphs (711 or 26%); these are single statement paragraphs containing the statement EXIT. When encountered as the last paragraph of a PERFORM THU statement, the EXIT effectively acts like a procedure return statement; in other contexts, the EXIT statement acts like a continue statement.
In the following code the developer could have written PERFORM PARA-1 THRU PARA-4, but if a related paragraph was added between PARA-4 and PARA-END_EXIT all PERFORMs explicitly referencing PARA-4 would need to be checked to see if they needed updating to the new last paragraph.
START. PERFORM PARA-1 THRU PARA-END-EXIT. PARA-1. DISPLAY 'PARA-1'. PARA-2. DISPLAY 'PARA-2'. PARA-3. DISPLAY 'PARA-3'. P3-EXIT. EXIT. PARA-4. DISPLAY 'PARA-4'. PARA-END-EXIT. EXIT. |
The plot below shows the number of paragraphs containing a given number of statements, the red dot shows the count with EXIT paragraphs are ignored (code+data):

How does this distribution compare with that seen in C and Java? The plot below shows the Cobol data (in black, with frequency scaled-up by 1,000) superimposed on the same counts for C and Java (C/Java code+data):
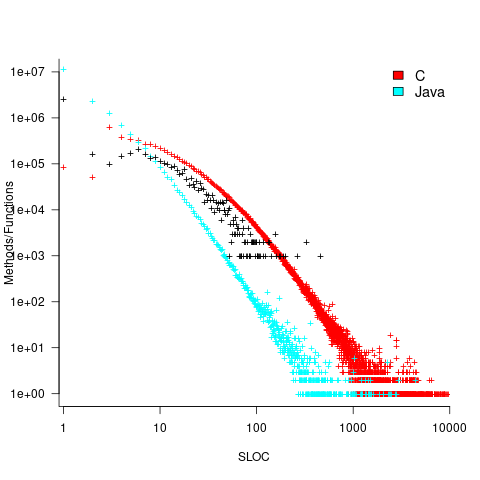
The distribution of statements per paragraph/function distribution for Cobol/C appears to be very similar, at least over the range 10-100. For less than 10-LOC the two languages have very different distributions. Is this behavior particular to the small number of Cobol programs measured? As always, more data is needed.
How many paragraphs does a Cobol program contain? The plot below shows programs ranked by the number of paragraphs they contain, including and excluding EXIT statements (code+data):
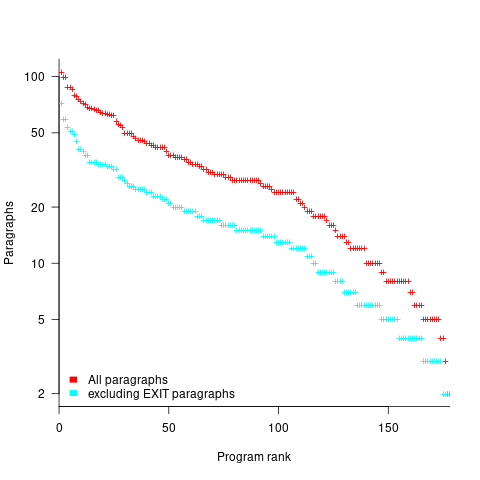
If you squint, it’s possible to imagine two distinct exponential declines, with the switch happening around the 100th program.
It’s tempting to draw some conclusions, but the sample size is too small.
Pointers to large quantities of Cobol source welcome.
Clustering source code within functions
The question of how best to cluster source code into functions is a perennial debate that has been ongoing since functions were first created.
Beginner programmers are told that clustering code into functions is good, for a variety of reasons (none of the claims are backed up by experimental evidence). Structuring code based on clustering the implementation of a single feature is a common recommendation; this rationale can be applied at both the function/method and file/class level.
The idea of an optimal function length (measured in statements) continues to appeal to developers/researchers, but lacks supporting evidence (despite a cottage industry of research papers). The observation that most reported fault appear in short functions is a consequence of most of a program’s code appearing in short functions.
I have had to deal with code that has not been clustered into functions. When microcomputers took off, some businessmen taught themselves to code, wrote software for their line of work and started selling it. If the software was a success, more functionality was needed, and the businessman (never encountered a woman doing this) struggled to keep on top of things. A common theme was a few thousand lines of unstructured code in one function in a single file (keeping everything in one file is also a trait of highly focus developers).
Adding structural bureaucracy (e.g., functions and multiple files) reduced the effort needed to maintain and enhance the code.
The problem with ‘born flat’ source is that the code for unrelated functionality is often intermixed, and global variables are freely used to communicate state. I have seen the same problems in structured function code, but instances are nowhere near as pervasive.
When implementing the same program, do different developers create functions implementing essentially the same functionality?
I am aware of two datasets relating to this question: 1) when implementing the same small specification (average length program 46.3 lines), a surprising number of variants (6,301) are created, 2) an experiment that asked developers to reintroduce functions into ‘flattened’ code.
The experiment (Alexey Braver’s MSc thesis) took an existing Python program, ‘flattened’ it by inlining functions (parameters were replaced by the corresponding call arguments), and asked subjects to “… partition it into functions in order to achieve what you consider to be a good design.”
The 23 rows in the plot below show the start/end (green/brown delimited by blue lines) of each function created by the 23 subjects; red shows code not within a function, and right axis is percentage of each subjects’ code contained in functions. Blue line shows original (currently plotted incorrectly; patched original code+data):
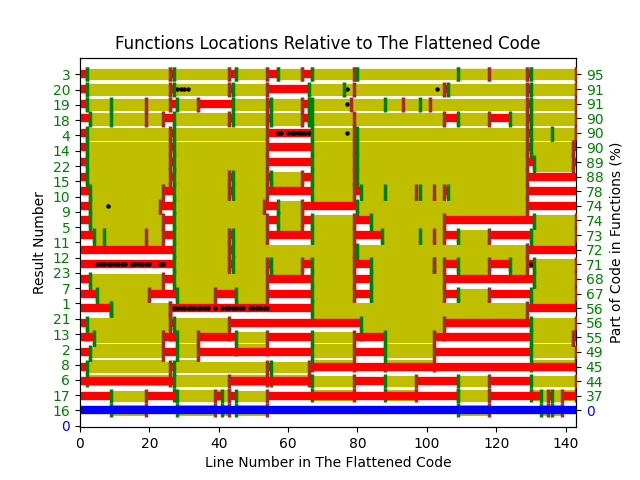
There are many possible reasons for the high level of agreement between subjects, including: 1) the particular example chosen, 2) the code was already well-structured, 3) subjects were explicitly asked to create functions, 4) the iterative process of discovering code that needs to be written did not occur, 5) no incentive to leave existing working code as-is.
Given that most source has a short and lonely existence, is too much time being spent bike-shedding function contents?
Given how often lower level design time happens at code implementation time, perhaps discussion of function contents ought to be viewed as more about thinking how things fit together and interact, than about each function in isolation.
Analyzing each function in isolation can create perverse incentives.
Impact of function size on number of reported faults
Are longer functions more likely to contain more coding mistakes than shorter functions?
Well, yes. Longer functions contain more code, and the more code developers write the more mistakes they are likely to make.
But wait, the evidence shows that most reported faults occur in short functions.
This is true, at least in Java. It is also true that most of a Java program’s code appears in short methods (in C 50% of the code is contained in functions containing 114 or fewer lines, while in Java 50% of code is contained in methods containing 4 or fewer lines). It is to be expected that most reported faults appear in short functions. The plot below shows, left: the percentage of code contained in functions/methods containing a given number of lines, and right: the cumulative percentage of lines contained in functions/methods containing less than a given number of lines (code+data):
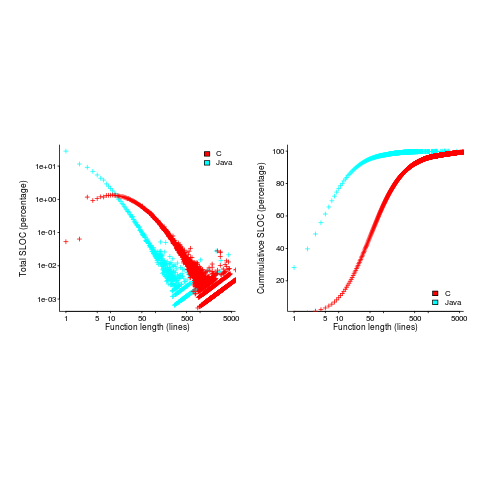
Does percentage of program source really explain all those reported faults in short methods/functions? Or are shorter functions more likely to contain more coding mistakes per line of code, than longer functions?
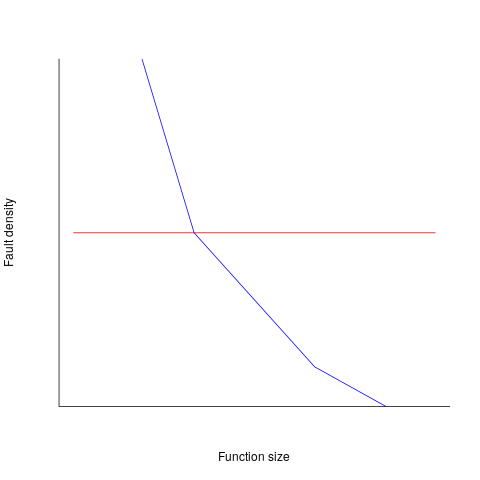
Reported faults per line of code is often referred to as: defect density.
If defect density was independent of function length, the plot of reported faults against function length (in lines of code) would be horizontal; red line below. If every function contained the same number of reported faults, the plotted line would have the form of the blue line below.
Two things need to occur for a fault to be experienced. A mistake has to appear in the code, and the code has to be executed with the ‘right’ input values.
Code that is never executed will never result in any fault reports.
In a function containing 100 lines of executable source code, say, 30 lines are rarely executed, they will not contribute as much to the final total number of reported faults as the other 70 lines.
How does the average percentage of executed LOC, in a function, vary with its length? I have been rummaging around looking for data to help answer this question, but so far without any luck (the llvm code coverage report is over all tests, rather than per test case). Pointers to such data very welcome.
Statement execution is controlled by if-statements, and around 17% of C source statements are if-statements. For functions containing between 1 and 10 executable statements, the percentage that don’t contain an if-statement is expected to be, respectively: 83, 69, 57, 47, 39, 33, 27, 23, 19, 16. Statements contained in shorter functions are more likely to be executed, providing more opportunities for any mistakes they contain to be triggered, generating a fault experience.
Longer functions contain more dependencies between the statements within the body, than shorter functions (I don’t have any data showing how much more). Dependencies create opportunities for making mistakes (there is data showing dependencies between files and classes is a source of mistakes).
The previous analysis makes a large assumption, that the mistake generating a fault experience is contained in one function. This is true for 70% of reported faults (in AspectJ).
What is the distribution of reported faults against function/method size? I don’t have this data (pointers to such data very welcome).
The plot below shows number of reported faults in C++ classes (not methods) containing a given number of lines (from a paper by Koru, Eman and Mathew; code+data):
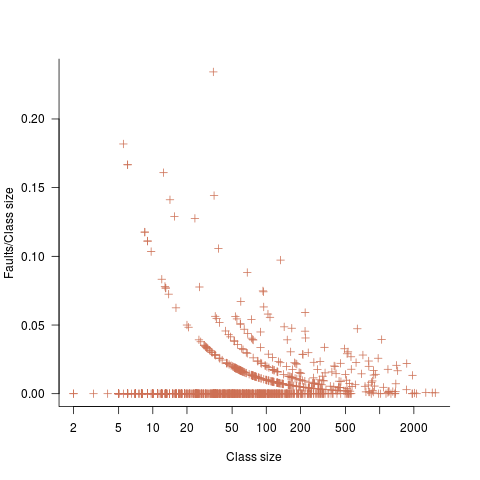
It’s tempting to think that those three curved lines are each classes containing the same number of methods.
What is the conclusion? There is one good reason why shorter functions should have more reported faults, and another good’ish reason why longer functions should have more reported faults. Perhaps length is not important. We need more data before an answer is possible.
Recent Comments