Archive
Modeling program LOC growth with recurrence equations
Models predicting the growth, in lines of code, of a program are based on the assumption that future growth follows the same pattern of behavior as past growth. One such model is the recurrence relation:
 , where:
, where:  is LOC at time
is LOC at time  ,
,  is the LOC carried over from release
is the LOC carried over from release  , and
, and  is the LOC added after release .
is the LOC added after release .
The solution to this recurrence relation is: }/{1-a}+a^n*L_0") , where:
, where:  is the LOC at time
is the LOC at time  .
.
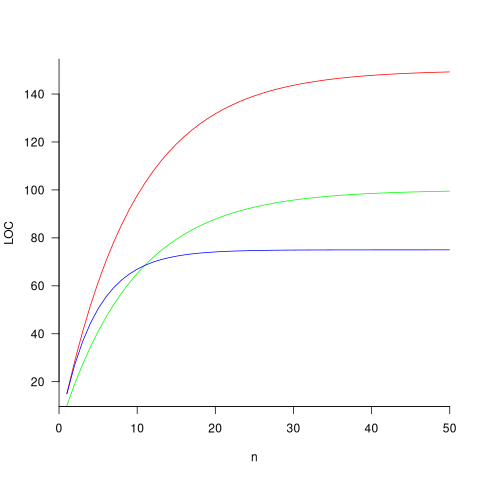
The plot below shows the growth predicted by this model, for various values of  and (code+data):
and (code+data):
How close is the fit between this model and actual project growth? The plot below shows the growth in LOC for FreeBSD between 1993 and 2006, data from Herraiz; the red line shows the above equation fitted using non-linear regression, with the blue line showing a fitted linear regression model of the form  (code+data):
(code+data):
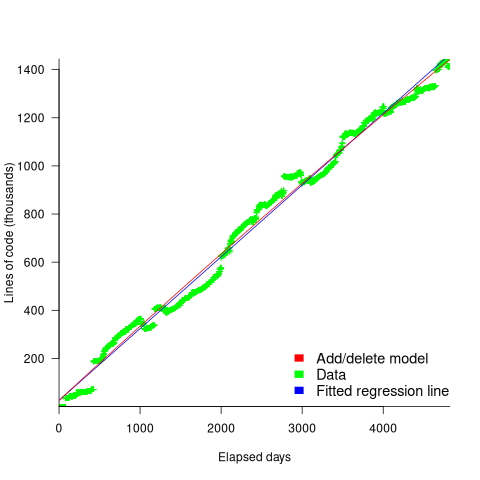
Plugging the fitted coefficients into the recurrence equation when  gives a prediction for the final maximum LOC in FreeBSD of:
gives a prediction for the final maximum LOC in FreeBSD of:
}/{1-a} = 0.3124766/(1-0.9999750) = 12,477 KLOC")
The FreeBSD growth is unusual in not having a slow start to its growth, or rather no data is available prior to 1993.
Long-lived, successful projects usually attract new developers, and over time some developers leave. The size of a project, and the predispositions of those involved, can limit the number of active core developers. The above model can be applied to the growth in the number of active developers, i.e.,
 , where:
, where:  is active developers at time ,
is active developers at time ,  is the developers ceasing to be active , and
is the developers ceasing to be active , and  is the number of new active developers at . The solution is:
is the number of new active developers at . The solution is:
}/{1-c}+c^n*P_0")
Adding the developer growth equation in to the LOC model, we get:
 , where is now multiplied by the number of developers at time
, where is now multiplied by the number of developers at time  , i.e.,
, i.e.,  . The solution to these recurrence equations is somewhat involved (note: if you are using an LLM to check the answers, ChatGPT makes multiple mistakes, but the Grok response contains just one algebra mistake); when
. The solution to these recurrence equations is somewhat involved (note: if you are using an LLM to check the answers, ChatGPT makes multiple mistakes, but the Grok response contains just one algebra mistake); when  the equation is:
the equation is:
-d)/{c(1-c)}-b*d/{(1-c)(1-a)})*a^n+{b*(P_0*(1-c)-d)/{c(1-c)}}*c^{n-1}+b*d/{(1-c)(1-a)}")
Checking this more complicated model against another project, the plot below shows the growth of the GNU C library between 1990 and 2011, data from Gonzalez-Barahona, Robles, Herraiz and Ortega; the red line is the fitted equation /935}}") (code+data):
(code+data):
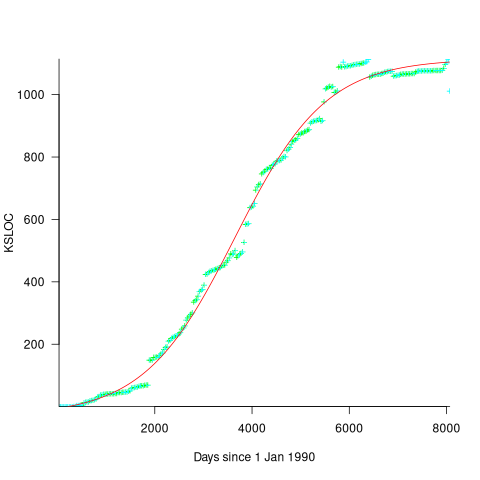
Unsurprisingly, I was not able to fit the more complicated growth model, using non-linear least squares, to the glibc LOC data. The problem was not being able to mimic the slow initial growth rate. I suspect that the developer growth model might be just wrong. Development work on a project does not last forever, and the number of developers will start decreasing at some point. For large projects, the Rayleigh distribution has been found to approximate staffing levels.
Data on project developer numbers over time is rare. The Linux kernel data shows an exponential developer growth rate, but I suspect that this is mostly caused by many one-time only developer contributing towards a new device driver (which are responsible for much of the Kernel growth).
Median system cpu clock frequency over last 15 years
We are all familiar with graphs showing the growth of cpu clock frequency over time. The data for these plots is based on vendor announcements listing the characteristics of their latest products, and invariably focuses on the product which is the fastest or contains the most transistors or the lowest power consumption.
Some customers buy the cpu with the highest/most/lowest, but many are happy to pay less for, for good enough. What does a graph of average customer cpu clock frequency over time look like?
Vendors sometimes publish general sales figures, but I have never seen one broken down by clock frequency. However, a few sites collect user system data, including:
- A subset of the Linux Counter project data is available. This does not contain explicit date information, but a must-be-later-than date can be inferred from the listed Linux kernel version,
- Hardware for BSD has data going back to December 2014, but there is no obvious way to extract it (I have not tried that hard),
- the BSDstats project (variable website availability) has been collecting data on machines running some derivative of BSD since August 2008; it contains around 200 times more cpu data than the known Linux Counter data. While the raw data is not available, approximately monthly reports are available on the Wayback Machine.
A BSDstats cpu history was obtained using waybackpack to download the available stored cpu summary pages, followed by html2text, and an awk script to extract the cpu frequency/count data.
BSDstats obtains the cpu information via a call to the sysctl command. For many Intel processors, but not AMD processors, the returned string includes the frequency (to see your cpu information on Linux systems type: more /proc/cpu), for instance:
Celeron(R) CPU 2.80GHz | 336 Pentium(R) 4 CPU 3.00GHz | 258 Pentium(R) 4 CPU 2.40GHz | 170 Athlon(tm) 64 Processor 3000+ | 43 Athlon(tm) 64 X2 Dual Core Processor 4200+ | 28 Athlon(tm) 64 Processor 3500+ | 27 |
For simplicity, only those rows containing frequency information were used in this analysis; 67% of the strings explicitly included a frequency (this saved me having to build a table to map AMD cpu strings to their corresponding frequency).
The plot below shows median cpu frequency (in red), along with the top/bottom 10% cpu frequencies, based on the Wayback Machine’s copy of the webpage on a given date, for a total of 2,304,446 cpu identities (code+data):
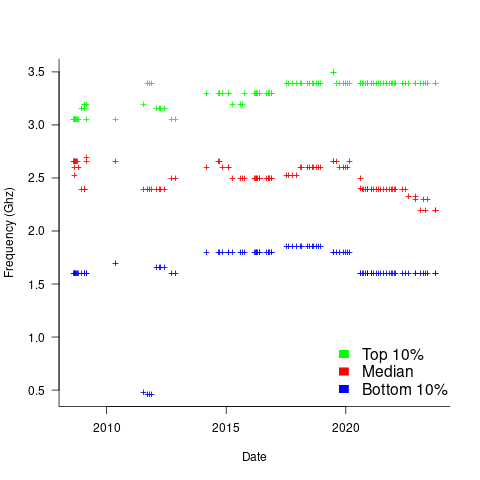
Broadly, the plot shows that cpu frequencies have essentially remained unchanged since 2008, with systems running BSD having a median frequency of 2.5 GHz, with 10% of systems having a frequency over 3.5 GHz, and 10% of systems a frequency below 1.5 GHz.
I was surprised at how many different frequencies were present in the data; often over 50. A look at the large number of different versions of Intel x86 cpus suggests that this is to be expected.
How representative is this sample of BSD systems, compared to the many more systems running Linux and Windows?
This begs the question of what kinds of environments are being compared. Are these desktop systems, local or hosted clusters, cloud systems?
The plot below shows the total number of cpus summarised on each Wayback Machine snapshot (code+data):

A few thousand systems are likely to be personal desktop systems, while the tens of thousands are likely to be clusters or small cloud providers.
Pointers to more data, particularly pre-2000, most welcome.
Licensing to decide the result of gcc vs llvm?
I was not surprised to hear today that Nvidia are halting development of their in-house C/C++ compiler and switching to one of the Open Source compilers. It is a lot cheaper to have one or two people looking after a company’s interests in a compiler developed by somebody else than having an in-house development group. It will be interesting to see how much longer Intel continues to fund their in-house compiler.
Nvidia chose llvm and gave a variety of technical reasons why this was the best choice over gcc.
One advantage (from Nvidia’s point of view) not mentioned is that llvm is licensed under a BSD style agreement. This means Nvidia don’t have to release the source code of any modifications or additions they make (they said these will be kept closed source); gcc is licensed under the GNU General Public License which requires source to be released. Arch rivals AMD (well, the ATI bit of AMD that does graphics hardware) also promote llvm, and I’m sure Nvidia does not want to help them in any way.
The licensing difference between gcc and llvm has the potential to make a big difference to the finances of both development teams.
My understanding of gcc funding is that most of it comes from back-end work (i.e., a company pays to have gcc work or do a better job on some [I imagine their] processor). Given a choice, would these companies rather release the source they paid to have written/modified or keep it closed? Some probably don’t care and hope that by making the source available others will help find and fix problems (i.e., there is a benefit to making it available), on the other hand companies introducing processors with fancy new features will want to minimise any technology that competitors can get for free.
In the years to come, it is possible that gcc will loose a significant amount of this back-end income to llvm because of licensing.
PhD projects are the life-blood of new compiler optimization techniques and for many years source code from them has often ended up as the experimental version of a new optimization phase of gcc. Many students are firm believers in making source freely available and shy away from being involved in non-GPL projects. Will this deter them from using llvm in their research (there may be a growing trend favoring llvm over gcc in research, or the llvm people may be better than the gcc folk at marketing {not hard})?
If llvm does not get the new fancy optimizations for ‘free’ they are going to have to spend money doing the implementing themselves or have their performance slowly fall behind that of gcc. Will this cost be more or less than the additional income from closed source customers?
We are unlikely to know the impact that licensing has on the fortunes of both compilers until the end of this decade. Perhaps designing and building a new processor will not be economically worthwhile in 10 years, perhaps all the worthwhile optimizations will be done. We will have to wait and see.
Update 4 Jan 2012: Video (235M) of talk on status of effort to make llvm the default compiler in FreeBSD at LLVM 2011 Developer’s meeting.
Recent Comments