Archive
February 2012 news in the programming language standard’s world
Yesterday I was at the British Standards Institute for a meeting of the programming languages committee. Some highlights and commentary:
- The first Technical Corrigendum (bug fixes, 47 of them) for Fortran 2008 was approved.
- The Lisp Standard working group was shutdown, through long standing lack of people interested in taking part; this happened at the last SC22 meeting, the UK does not have such sole authority.
- WG14 (C Standard) has requested permission to start a new work item to create a new annex to the standard containing a Secure Coding Standard. Isn’t this the area of expertise of WG23 (Language vulnerabilities)? Well, yes; but when the US Department of Homeland Security is throwing money at cyber security increasing the number of standards’ groups working on the topic creates more billable hours for consultants.
- WG21 (C++ Standard) had 73 people at their five day meeting last week (ok, it was in Hawaii). Having just published a 1,300+ page Standard which no compiler yet comes close to implementing they are going full steam ahead creating new features for a revised standard they aim to publish in 2017. Does the “Hear about the upcoming features in C++” blogging/speaker circuit/consulting gravy train have that much life left in it? We will see.
The BSI building has new lifts (elevators in the US). To recap, lifts used to work by pressing a button to indicate a desire to change floors, a lift would arrive, once inside one or more people needed press buttons specifying destination floor(s). Now the destination floor has to be specified in advance, a lift arrives and by the time you have figured out there are no buttons to press on the inside of the lift the doors open at the desired floor. What programming language most closely mimics this new behavior?
Mimicking most languages of the last twenty years the ground floor is zero (I could not find any way to enter a G). This rules out a few languages, such as Fortran and R.
A lift might be thought of as a function that can be called to change floors. The floor has to be specified in advance and cannot be changed once in the lift, partial specialization of functions and also the lambda calculus springs to mind.
In a language I just invented:
// The lift specified a maximum of 8 people lift = function(p_1, p_2="", p_3="", p_4="", p_5="", p_6="", p_7="", p_8="") {...} // Meeting was on the fifth floor first_passenger_5th_floor = function lift(5); second_passenger_4th_floor = function first_passenger_fifth_floor(4); |
the body of the function second_passenger_4th_floor is a copy of the body of lift with all the instances of p_1 and p_2 replaced by the 5 and 4 respectively.
Few languages have this kind of functionality. The one that most obviously springs to mind is Lisp (partial specialization of function templates in C++ does not count because they are templates that are still in need of an instantiation). So the ghost of the Lisp working group lives on at BSI in their lifts.
Optimizing floating-point expressions for accuracy
Floating-point arithmetic is one topic that most compiler writers tend to avoid as much as possible. The majority of programs don’t use floating-point (i.e., low customer demand), much of the analysis depends on the range of values being operated on (i.e., information not usually available to the compiler) and a lot of developers don’t understand numerical methods (i.e., keep the compiler out of the blame firing line by generating code that looks like what appears in the source).
There is a scientific and engineering community whose software contains lots of floating-point arithmetic, the so called number-crunchers. While this community is relatively small, many of the problems it works on attract lots of funding and some of this money filters down to compiler development. However, the fancy optimizations that appear in these Fortran compilers (until the second edition of the C standard in 1999 Fortran did a much better job of handling the minutia of floating-point arithmetic) are mostly about figuring out how to distribute the execution of loops over multiple functional units (i.e., concurrent execution).
The elephant in the floating-point evaluation room is result accuracy. Compiler writers know they have to be careful not to throw away accuracy (e.g., optimizing out what appear to be redundant operations in the Kahan summation algorithm), but until recently nobody had any idea how to go about improving the accuracy of what had been written. In retrospect one accuracy improvement algorithm is obvious, try lots of possible combinations of the ways in which an expression can be written and pick the most accurate.
There are lots of ways in which the operands in an expression can be paired together to be operated on; some of the ways of pairing the operands in a+b+c+d include (a+b)+(c+d), a+(b+(c+d)) and (d+a)+(b+c) (unless the source explicitly includes parenthesis compilers for C, C++, Fortran and many other languages (not Java which is strictly left to right) are permitted to choose the pairing and order of evaluation). For n operands (assuming the operators have the same precedence and are commutative) the number is combinations is  where
where  is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands
is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands  of which
of which  are unique.
are unique.
A recent study by Langlois, Martel and Thévenoux analysed the accuracy achieved by all unique permutations of ten operands on four different data sets. People within the same umbrella project are now working on integrating this kind of analysis into a compiler. This work is another example of the growing trend in compiler research of using the processing power provided by multiple cores to use algorithms that were previously unrealistic.
Over the last six years or so there has been lot of very interesting floating-point work going on in France, with gcc and llvm making use of the MPFR library (multiple-precision floating-point) for quite a while. Something very new and interesting is RangeLab which, given the lower/upper bounds of each input variable to a program (a simple C-like language) computes the range of the outputs as well as ranges for the roundoff errors (the tool assumes IEEE floating-point arithmetic). I now know that over the range [800, 1000] the expression x*(x+1) is a lot more accurate than x*x+x.
Update: See comment from @Eric and my response below.
Memory capacity and commercial compiler development
When I started out in the compiler business in the 80s, many commercial compilers were originally written by one person. A very good person who dedicated himself (I have never heard of a woman doing this) to the job (i.e., minimal social life) could produce a commercially viable product for a non-huge language (e.g., Fortran, Pascal, C, etc, but not C++, Ada, etc) in 12-18 months. Companies who decide to develop a compiler in-house tend to use a team of people, and take longer, because that is how they work, and they don’t want to depend on one person, and anyway such a person might not be available to them.
Commercially viable compiler development stayed within the realm of an individual effort until sometime in the early 90s. What put the single individual out of business was the growth in computer memory capacity into the hundreds of megabytes and beyond. Compilers have to be able to run within the limits of developer machines; you won’t sell many compilers that require 100M of memory if most of your customers don’t have machines with 100M+ of memory.
Code optimizers eat memory, and this prevented many optimizations that had been known about for years appearing in commercial products. Once the machines used for software development commonly contained 100M+ of memory, compiler vendors could start to incorporate these optimizations into their products.
Improvements in processor speed also helped. But developers are usually willing to let the compiler take a long time to optimize the code going into a final build, provided development compiles run at a reasonable speed.
The increase in memory capacity created the opportunity for compilers to improve, and when some did improve they made it harder for others to compete. Suddenly an individual had to spend that 12-18 months, plus many more months implementing fancy optimizations; developing a commercially viable compiler outgrew the realm of individual effort.
Some people claim that the open source model was the primary driver in killing off commercial C compiler development. I disagree. My experience of licensing compiler source was that companies preferred a commercial model they were familiar with, and reacted strongly against the idea of having to make available any changes they made to the code of an open source program. GCC (and recently llvm) succeeded because many talented people contributed fancy optimizations and these could be incorporated because developer machines contained lots of memory. If storage had not dramatically increased, gcc would probably not be the market leader it is today.
ISO Standards, the beauty and the beast
Standards is one area where a monopoly can provide a worthwhile benefit. After all the primary purpose of a standard for something is having just the one document for everybody to follow (having multiple standards because they are so useful is not a good idea). However, a common problem with monopolies is that charge a very inflated price for their product.
Many years ago the International Standard Organization settled on a pricing scheme for ISO Standards based on document page count. Most standards are very short and have a very small customer base, so there is commercial logic to having a high cost per page (especially since most are bought by large companies who need a copy if they do business in the corresponding application domain). Programming language standards do not fit this pattern, often being very long and potentially having a very large customer base.
With over 18,500 standards in their catalogue ISO might be forgiven for overlooking the dozen or so language standards, or perhaps they figured there is as much profit in charging a few hundred pounds on a few sales as charging less on more sales.
How does the move to electronic distribution effect prices? For a monopoly electronic distribution is an opportunity to make more profit, not to reduce prices. The recently published revision of the Fortran Standard is available for 338 Swiss francs (around £232) from ISO and £356 from BSI (at $351 the price from ANSI in the US is similar to ISO’s). Many years ago, at the dawn of the Internet, members of the US C Standard committee were able to convince ANSI to sell electronic copies at a reasonable rate ($30) and this practice has continued ever since (and now includes C++).
The market for the C and C++ Standards is sufficiently large that a commercial publisher (Wiley) was willing to take the risk of publishing them in book form (after some prodding and leg work by the likes of Francis Glassborow). It will be interesting to see if a publisher is willing to take a chance on a print run of the revised C Standard due out in a few years (I think the answer for the revised C++ Standard is more obvious).
Don’t Standards bodies care about computer languages? Unfortunately we are thorn in their side and they would be happy to be rid of us (but their charter’s do not allow them to do this). Our standards take much longer to produce than other standards, they are large and sales are almost non-existent (at ISO/BSI prices). What is more many of those involved in creating these standards actively subvert ISO/BSI sales by making draft documents, that are very close to the final copyrighted versions, freely available over the Internet.
In a sense ISO programming language standards exist because the organizational structure requires them to accept our work proposals and what we do does not have a large enough impact within the standards world for them to try and be rid of those tiresome people whose work is so far removed from what everybody else does.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
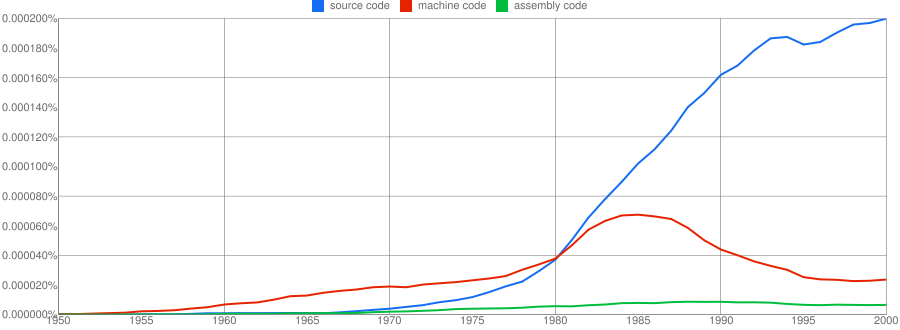
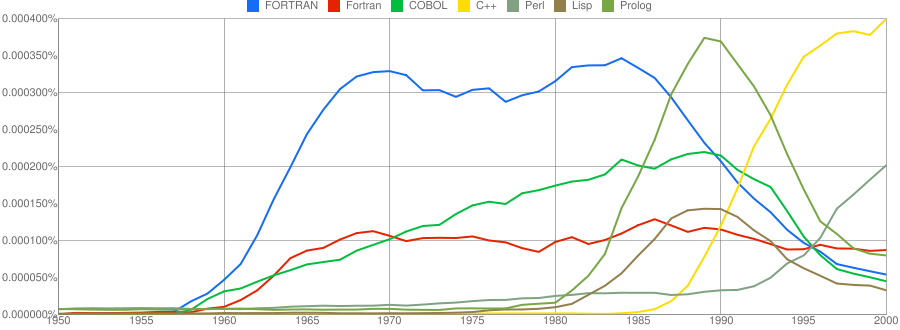
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
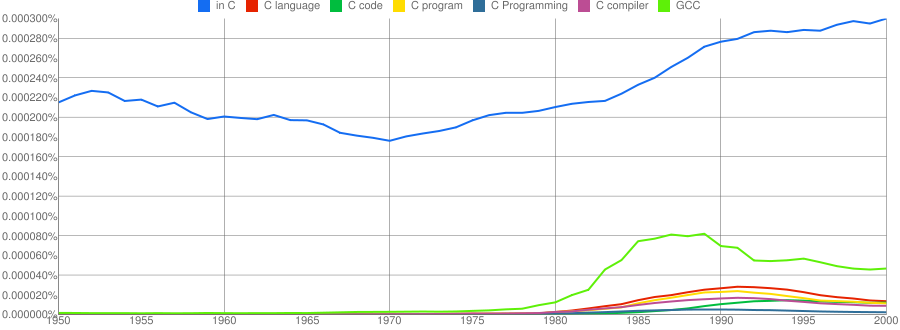
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
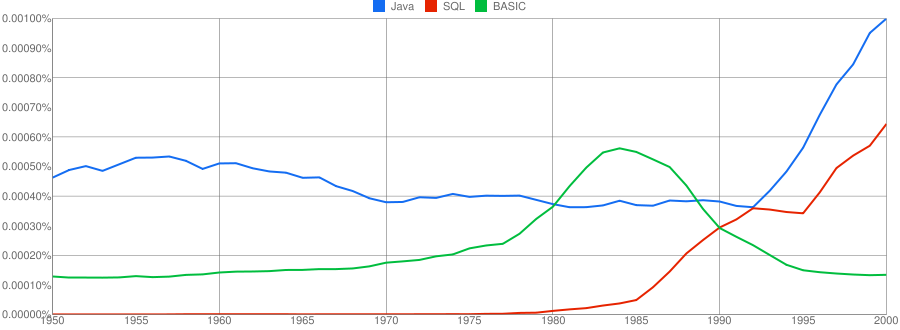
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
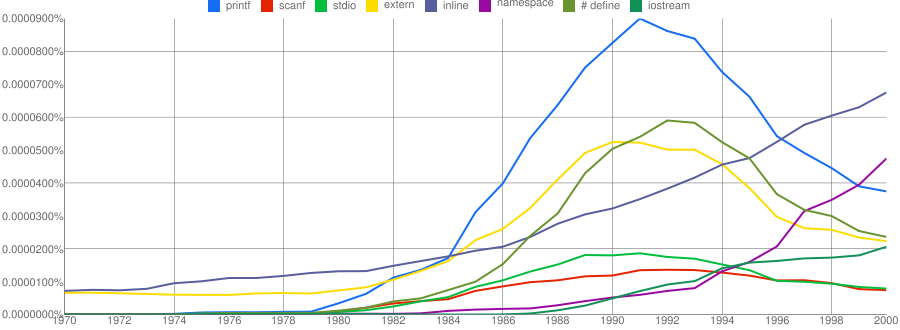
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
What language was an executable originally written in?
Apple have recently added an unusual requirement to the iPhone developer agreement “Applications must be originally written in Objective-C, C, C++, or JavaScript …”. As has been pointed out elsewhere the real purpose is stop third party’s from acquiring any control over application development on Apple’s products; the banning of other languages is presumably regarded as acceptable collateral damage.
Is it possible to tell by analyzing an executable what language it was originally written in?
There are two ways in which executables contain source language ‘signatures’. Detecting these signatures requires knowledge of specific compiler behavior, i.e., a database of information about the behavior of compilers capable of creating the executables is needed.
Runtime library. Most compilers make use of a language specific runtime library, rather than generating inline code for some kinds of functionality. For instance, setjmp/longjmp in C and vtables in C++.
The presence of a known C runtime library does not guarantee that the application was originally written in C; it could have been written in Java and converted to C source.
The absence of a known C runtime library could mean that the source was compiled by a C compiler using a runtime system unknown to the analyzer.
The presence of a known Java, for instance, runtime library would suggest that the original source contained some Java. This kind of analysis would obviously require that the runtime library database not restrict itself to the ‘C’ languages.
Compiler behavior patterns. There is usually more than one way in which a source language construct can be translated to machine code and a compiler has to pick one of them. The perfect optimizing compiler would always make the optimal choice, but real compilers follow a fixed pattern of code generation for at least some language constructs (e.g., initialization of registers on function entry).
The presence of known code patterns in an executable is evidence that a particular compiler has been used; how much depends on the likelihood it could have been generated by other means and how many other patterns suggest the same compiler. In the case of the GNU Compiler Collection the source language might also be Fortran, Java or Ada; I don’t know enough about the behavior of GCC to provide an informed estimate of whether it is possible to recognize the source language from the translated form of constructs shared by several languages, I suspect not.
The fact that an executable can be decompiled to C is not a guarantee that it was originally written in C.
Some languages support source language constructs whose corresponding machine code is unlikely to ever be generated by source from another language. The Fortran computed goto allows constructs to be written that have no equivalent in the other languages supported by GCC (none of them allow statement labels appearing in a multi-way jump to appear before the jump test):
10 I=I+1 20 J=J+1 goto (10, 20, 30, 40) J 30 I=I+3 40 I=I*2 |
The presence of a compiled form of this kind of construct in the executable would be very suggestive of Fortran source.
Apple are famously paranoid and control freakery. It will be very interesting to see what level of compliance checking they decide to perform on executables submitted to the App Store.
On another note: What does “originally written” mean? For instance, many of the mathematical functions (e.g., sine, log, gamma, etc) contained in R were originally written in Fortran and translated to C for use in R; this C source is what is now maintained. Does this historical implementation decision mean that R cannot be legally ported to the iPhone?
Variations in the literal representation of Pi
The numbers system I am developing attempts to match numeric literals contained in a file against a database of interesting numbers. One of the things I did to quickly build a reasonably sized database of reliable values was to extract numeric literals from a few well known programs that I thought I could trust.
R is a widely used statistical package, and Maxima is a computer algebra system with a long history. Both contain a great deal of functionality and are actively maintained.
To my surprise, the source code of both packages contain a large variety of different literal values for  , or to be exact, the number of digits contained in the literals varied by more than I expected. In the following table, the value to the left of the representation is the number of occurrences; values listed in increasing literal order:
, or to be exact, the number of digits contained in the literals varied by more than I expected. In the following table, the value to the left of the representation is the number of occurrences; values listed in increasing literal order:
Maxima R
2 3.14159
14 3.141592
1 3.1415926
1 3.14159265 2 3.14159265
3 3.1415926535
4 3.14159265358979
14 3.141592653589793
3 3.1415926535897932385 3 3.1415926535897932385
9 3.14159265358979324
1 3.14159265359
1 3.1415927
1 3.141593
The comments in the Maxima source led me to believe that some thought had gone into ensuring that the numerical routines were robust. Over 3/4 of the literal representations of have a precision comparable to at least that of 64-bit floating-point (I’m assuming an IEEE 754 representation in this post).
In the R source, approximately 2/3 of the literal representations of have a precision comparable to that of 32-bit floating-point.
Closer examination of the source suggests one reason for this difference. Both packages make heavy use of existing code (translated from Fortran to Lisp for Maxima and from Fortran to C for R); using existing code makes good sense and because of its use in scientific and engineering applications many numerical libraries have been written in Fortran. Maxima has adapted the slatec library, whereas the R developers have used a variety of different libraries (e.g., specfun).
How important is variation in the representation of Pi?
- A calculation based on a literal that is only accurate to 32-bits is likely to be limited to that level of accuracy (unless errors cancel out somewhere).
- Inconsistencies in the value used to represent Pi are a source of error. These inconsistencies may be implicit, for instance literals used to denote a value derived from such as
 often seem to be based on more precise values of Pi than appear in the code.
often seem to be based on more precise values of Pi than appear in the code.
The obvious solution to this representation issue of creating a file containing definitions of all the frequently used literal values has possible drawbacks. For instance, numerical accuracy is a strange beast, and increasing the precision of one literal without doing the same for other literals appearing in a calculation can sometimes reduce the accuracy of the final result.
Pulling together existing libraries to build a package is often very cost-effective, but numerical accuracy is a slippery beast, and this inconsistent usage of literals suggests that developers from these two communities have not addressed the system level consequences of software reuse.
Update 6 April: After further rummaging around in the R source distribution, I found that things are not as bad as they first appear. Only two of the single precision instances of listed above occur in the C or Fortran source code, the rest appear in support files (e.g., m4 scripts and R examples).
Parsing Fortran 95
I have been looking at doing some dimensional analysis of the Climategate code and so needed a Fortran parser.
The last time I used Fortran in anger the modern compilers were claiming conformance to the 1977 standard and since then we have had Fortran 90 (with a minor revision in 95) and Fortran 03. I decided to take the opportunity to learn something about the new features by writing a Fortran parser that did not require a symbol table.
The Eli project had a Fortran 90 grammar that was close to having a form acceptable to bison and a few hours editing and debugging got me a grammar containing 6 shift/reduce conflicts and 1 reduce/reduce conflict. These conflicts looked like they could all be handled using glr parsing. The grammar contained 922 productions, somewhat large, but I was only interested in actively making use of parts of it.
For my lexer I planned to cut and paste an existing C/C++/Java lexer I have used for many projects. Now this sounds like a fundamental mistake, these languages treat whitespace as being significant while Fortran does not. This important difference is illustrated by the well known situation where a Fortran lexer needs to lookahead in the character stream to decide whether the next token is the keyword do or the identifier do5i (if 1 is followed by a comma it must be a keyword):
do 5 i = 1 , 10 do 5 i = 1 . 10 ! assign 1.10 to do5i 5 continue |
In my experience developers don’t break up literals or identifier names with whitespace, and so I planned to mostly ignore the whitespace issue (it would simplify things if some adjacent keywords were merged to create a single keyword).
In Fortran the I/O is specified in the language syntax, while in C like languages it is a runtime library call involving a string whose contents are interpreted at runtime. I decided to ignore I/O statements by skipping to the end of line (Fortran is line oriented).
Then the number of keywords hit me, around 190. Even with the simplifications, I had made writing a Fortran lexer look like it would be a lot of work; some of the keywords only had this status when followed by a = and I kept uncovering new issues. Cutting and pasting somebody else’s lexer would probably also involve a lot of work.
I went back and looked at some of the Fortran front ends I had found on the Internet. The GNU Fortran front-end was a huge beast and would need serious cutting back to be of use. moware was written in Fortran and used the traditional six character abbreviated names seen in ‘old-style’ Fortran source and not a lot of commenting. The Eli project seemed a lot more interested in the formalism side of things, and Fortran was just one of the languages they claimed to support.
The Open Fortran Parser looked very interesting. It was designed to be used as a parsing skeleton that could be used to produce tools that processed source, and already contained hooks that output diagnostic output when each language production was reduced during a parse. Tests showed that it did a good job of parsing the source I had, although there was one vendor extension used quite often (and not documented in their manual). The tool source, in Java, looked straightforward to follow, and it was obvious where my code needed to be added. This tool was exactly what I needed 🙂
Dimensional analysis of source code
The idea of restricting the operations that can be performed on a variable based on attributes appearing in its declaration is actually hundreds of years old and is more widely known as dimensional analysis. Readers are probably familiar with the concept of type checking where, for instance, a value having a floating-point type is not allowed to be added to a value having a pointer type. Unfortunately, many of those computer languages that support the functionality I am talking about (e.g., Ada) also refer to it as type checking and differentiate it from the more common usage by calling it strong typing. The concept would be much easier for people to understand if a different term were used, e.g., unit checking or even dimension checking.
Dimensional analysis, as used in engineering and the physical sciences, relies on the fact that quantities are often expressed in terms of a small number of basic attributes, e.g., mass, length and time; velocity is calculated by dividing a length by a time,  and area is calculated by multiplying two lengths,
and area is calculated by multiplying two lengths,  . Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,
. Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,  , can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
, can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
Dimensional analysis can be used to check a calculation involving physical quantities for internal consistency and as a method for trying to deduce the combinations of quantities that an unknown equation might contain based on the physical units the result is known to be represented in.
The frink language has units of measure checking built into it.
How might dimensional analysis be used to check source code for internal consistency? Consider the following code:
x = a / b; c = a; y = c / b; if (x + y ... ... z = x + b; |
c is assigned a‘s value and is therefore assumed to have the same units of measurement. The value assigned to y is calculated by dividing c by b and the train of reasoning leading to the assumption that it has the same units of measurement as x is easy to follow. Based on this analysis, there is nothing suspicious about adding x and y, but adding x and b looks wrong (it would be perfectly ok if all of the variables in this code were dimensionless).
A number of tools have been written to check source code expressions for internal consistency e.g., Fortran (Automated computation and consistency checking of physical dimensions and units in scientific programs), C++ (Applied Template Metaprogramming in SI units) and C (Annotation-less Unit Type Inference for C), but so far only one PhD.
Providing a mechanism for developers to add unit information to variable declarations would enable compilers to perform consistency checks and reduce the likelihood of false positives being reported (because dimensionless values can generally be combined in any way). It is too late in the day for such a major feature to be added to the next revision of the C++ standard; the C standard is also being revised, but the committee is currently being very conservative and insists that any proposed new constructs already be implemented in at least one compiler.
Does the Climategate code produce reliable output?
The source of several rather important commercial programs have been made public recently, or to be more exact programs whose output is important (i.e., the Sequoia voting system and code and data from the Climate Research Unit at University of East Anglia the so called ‘Climategate’ leak). While many technical commentators have expressed amazement at how amateurish the programming appears to be, apparently written with little knowledge of good software engineering practices or knowledge of the programming language being used, those who work on commercial projects know that low levels of software engineering/programming competence is the norm.
The emails included in the Climategate leak provide another vivid example, if one were needed, of why scientific data should be made publicly available; scientists are human and are sometimes willing to hide data that does not fit their pet theory or even fails to validate their theory at all.
The Climategate source has only only recently become available and existing technical commentary has been derived from embarassing comments and the usual complaint about not using the right programming language (Fortran is actually a good choice of language for this problem, it is widely used by climatology researchers and a non-professional programmer is probably makes best of their time by using the one language they know tolerably well rather than attempting to use a new language that nobody else in the research group knows).
An important quality indicator of the leaked software was what was not there, test cases (at least I could not find any). How do we know that a program’s output is correct? One way to gain some confidence in a program’s correctness is to process data for which the correct output is known. This blindness to the importance of program level correctness testing is something that I often encounter in people who are subject area experts rather than professional programmers; they believe that if the output has the form they are expecting it must be correct and will sometimes add ‘faults’ to ‘fix’ output that deviates from what they are expecting.
A quick visual scan through the source showed a tale of two worlds, one of single letter identifier names and liberal use of goto, and the other of what looks like meaningful names, structured code and a non-trivial number of comments. The individuals who have contributed to the code base obviously have very different levels of coding ability. Not having written any Fortran in anger for over 15 years my ability to estimate the impact of more subtle coding practices has atrophied.
What kind of faults might a code review look for in these programs? Common coding errors such as using uninitialized variables and incorrect argument passing are obvious choices and their are tools available to check for these kinds of error. A much more insidious kind of error, which requires people with the mathematical expertise to spot, is created by the approximate nature of floating-point arithmetic.
The source is not huge, but not small either, consisting of around 64,000 lines of Fortran and 16,000 lines of IDL (a language designed for interactive data analysis which to my untrained eye looks a lot like MATLAB). There was no obvious support for building the source included within the leaked files (e.g., no makefiles) and my attempt to manually compile using the GNU Fortran compiler failed miserably. So I cannot say anything reliable about the compiler output warnings.
To me the complete lack of test cases implies that the Climategate code does not produce reliable output. Comments in the code such as
***** APPLIES A VERY ARTIFICIAL CORRECTION FOR DECLINE*********suggests that the authors were willing to patch the code to produce output that matched their expectations; this is the mentality of somebody for whom code correctness is not an important issue and if they don’t believe their code is correct then I don’t either.Source code in itself is rarely that important, although it might have been expensive to create. The real important information in the leaked files is the climate data. Now that this is available others can apply their analysis skills to provide an interpretation to what, if anything statistically reliable, it is telling us.