Archive
Changing development culture and practices: LLM edition
The popular perception of creating software systems is that it mainly involves writing code. In the 1950s, management treated writing code as a clerical task that just mapped the detailed requirements specified by someone with knowledge of the problem to something a computer could execute. Job titles reflected this division of labour, e.g., coder/programmer, systems analyst (the Wikipedia entry lists implementation as part of the job, this eventually became true in theory and for many was probably true in practice since the early days).
Using Large Language Models to write code based on the requirements contained in a prompt appears to take software development back to the process mandated by the managers of early software projects.
A major economic incentive for the creation of software systems is enabling more efficient work processes, with the collateral damage of decimated employment in some work functions. This happened to clerical workers and non-software engineering workers. Now it’s happening to software developers.
Hardware designers did not cease to exist once Computer-aided design became available. Technical drawing skills (larger schools once had a room full of drawing boards for teaching young teenagers) has ceased to be a job requirement (image from Wikipedia).

Software developer will remain as a job category, perhaps with reduced numbers or with reduced average pay. But the use of LLMs will change the culture and practices of software development.
The shift from using assembly language to high level languages suggests a few ideas about the kinds of changes. Using assembly language requires being reasonably familiar with the cpu architecture, e.g., register names/widths/instruction-restrictions and instruction timings. General developer chat about cpu architectures was still a thing in the 1980s, less so in the 1990s, and very rarely today (people do blog about it). Several decades from now, what will no longer be a general topic of developer conversation? Data types, perhaps; like registers, bit pattern representation is a low level detail. Since most developers don’t know much about the languages they use, it may be difficult to measure the impact of LLM usage on language knowledge.
High-level languages increase developer productivity by reducing the number of details that need to be thought about, at the cost of less efficient code. But for many applications, machine time is cheaper than human time.
LLMs increase developer productivity by reducing the need to lookup details (e.g., spelling of method names and their parameters). As confidence grows in the accuracy of LLM suggested code, developers will start accepting, whatever. What counts is whether the code works, not whether the average developer would have written something faster/smaller/idiomatic.
The early languages have a straightforward mapping from statements/declarations to machine code. Over time, languages were created that allowed developers to think less and less about implementation details, at the cost of supporting constructs that could introduce lots of hidden overhead. I expect that customer demand will incentivize LLM functionality that reduces what developers need to think about.
A real danger of LLM usage is that it will, eventually, result in programs a lot more bloated than humans have managed to achieve. There are physical constraints restricting what hardware designers can do, and these constraints show up in patterns of behavior, e.g., Rent’s rule relating the number of external connections in a logic block to the number of logic gates in the block. There are common usage patterns in existing code, but no theory suggesting they are desirable, or not, in any sense. I await having enough LLM generated production code to make statistically significant measurements.
I suspect that these days most developers are writing glue code, or short programs, and in the near term I expect that most LLM code will fill this need. Unfortunately, there is very little research/measurement on glue code/short program, so there are no known developer usage patterns to compare LLMs against.
Employment in the software business: we know nothing
Tens of millions of people get paid to work on the creation and maintenance of software systems, by companies employing thousands of developers to those employing a single developer (in the UK there are almost 300K registered software companies; 5% of registered companies).
This huge ecosystem is almost completely ignored by the software engineering research community. Academics in computing/software are more interested in technical issue, and industry is an ecosystem they rarely interact with (some claim that student employment keeps them in contact with industry).
There are researchers in business and economics departments who study employment, e.g., careers, organization of workers and companies. The scientific study of work started at the beginning of the 1900s, originally focused on the manufacturing and included office work as that grew to employ a significant percentage of the workforce. Until recently, the percentage of the workforce employed to create/maintain software was not large enough to attract the attention of these researchers, and even now it’s often lumped together with other jobs that mostly involve some form of intellectual activity.
Employee related issues of interest to those involved in managing work on software systems are heavily influenced by the characteristics of the business ecosystem in which they work. The software driven business ecosystems are continually changing, with companies growing, merging and going bust as new markets emerge, grow, saturate, and sometime disappear. This constant change creates employment uncertainty, and lots of opportunities for competent people (creating a staff retention problem). For more stable industries, it’s possible for researchers to model employee start/promotion/leaving transitions using Markov models (example of ChatGPT 1o-preview solving a recurrence model of the staffing relationships in a 3-level employment hierarchy). The book “Stochastic Models for Social Processes” by D. J. Bartholomew gives a practical introduction to the use of Markov models for this kind of analysis.
The evolution and constant introduction of new technologies can make it difficult to find people with the appropriate skills. Companies may tune the wording of job adverts to give the impress of using ‘modern’ technologies, or post fake job adverts (to increase their attractiveness and suggest a feeling of growth), and people tune their CV to appeal to employers (some out right lie about their skills; many managers have told me that around 90% of applicants don’t have the primary skill sought by the employer). Well paid jobs can attract lots of applicants, filtering/interviewing can be an expensive process (not least because the same job title can denote different seniority in different companies). Matching CVs to job requirements sounds like the perfect use case for LLMs. I suspect that LLM tuning of CVs/adverts will just increase costs/uncertainty.
The constant churn of technologies forces employees to make decisions about whether to happily spend many years being well paid to become an expert in a niche with decreasing industry demand, or to invest in starting again as a non-expert doing something new (and initially less well paid).
What is the best to organize engineering employees at a company-wide scale? Matrix management was once the standard answer, but these days, scaled agile is a fashionable answer. An evidence-based answer will have to wait until the lawyers in a large organization allow somebody with the necessary skills access to the appropriate data.
With the contents of job sites being scraped, along with LinkedIn, I’m optimistic that some meaningful employment data will slowly become available. Will the analysis of this data uncover patterns of practical use (other than interesting blog posts) to employers/employees? We will have to wait and see.
Software engineering as a hedonistic activity
My discussions with both managers and developers on software development processes invariably end up on the topic of developer happiness. Managers want to keep their development teams happy, and there is a longstanding developer culture of entitlement to work that they find interesting.
Companies in general want to keep their employees happy, irrespective of the kind of work they do. What makes developers different, from management’s perspective, is that demand for good software developers far outstrips supply.
Many developers approach software engineering as a hedonistic activity; yes, there are those who only do it for the money.
The huge quantity of open source software, much of it written out of personal interest rather than paid employment, provides evidence for there being many people willing to create software because of the pleasure they get from doing it.
Software developers only get to indulge in hedonistic development activities (e.g., choosing which tools to use, how to structure their code, and not having to provide estimates) because of the relative ease with which competent developers can obtain another job. Replacing developers is time-consuming and expensive, which gives existing employees a lot of bargaining power with management.
Some of the consequences of managements’ desire to keep developers happy, or at least not unhappy include:
- Not pushing too hard for an estimate of the likely time needed to complete a task,
- giving developers a lot of say in which languages/tools/packages they use. This creates a downstream need to support a wider variety of development ecosystems than might otherwise have been necessary, and further siloing development teams,
- allowing developers to spend time beautifying their code to meet personal opinions about the visual appearance of source.
The balance of power that facilitates hedonism driven development is determined by the relative size of the employment market in the supply and demand for software developers. Once demand falls below the available supply, finding a new job becomes more difficult, shifting the balance of power away from developers to managers.
I am not expecting supply to exceed demand any time soon. While International computer companies have been laying off lots of staff, demand from small companies appears to be strong (based on the ever-present ‘We’re hiring’ slides I regularly see at London meetups), but things may change. Tools such as ChatGPT are far from good enough to replace developers in the near term.
Overview of broad US data on IT job hiring/firing and quitting
Software developers are employed by organizations and people change jobs, either voluntarily or not; every year a new batch of people join the workforce, e.g., new graduates. Governments track employment activities for a variety of reasons, e.g., tax collection, and monitoring labour supply and demand (for the purposes of planning).
The US Bureau of Labor Statistics’ publishes a monthly summary of their Job Openings and Labor Turnover Survey. What can be learned about software development employment from this data (description)?
The data starts in December 2000, with each row contains a monthly count of Job Openings, Hires, Quits, Layoffs and Discharges, and totals, along with one of 21 major non-farm industry codes or one of the 5 government codes (the counts are broken out by State). I’m guessing that software developers are assigned the Information code (i.e., 510000), but who is to say that some have not been classified with the code for, say, Construction or Education and health services. The Information code will cover a lot more than just software developers; I’m trading off broad IT coverage for monthly details on employment turnover (software developer specific information is available, but it comes without the turnover information). The Bureau of Labor Statistics make available a huge quantity of information, and understanding how it all fits together would probably require me to spend several months learning my way around (I have already spent a week or two over the years), so I’m sticking with a prebuilt dataset.
The plot below shows the aggregated monthly counts (i.e., all states) of Job Openings, Hires, Quits, Layoffs and Discharges for the Information industry code (code+data):
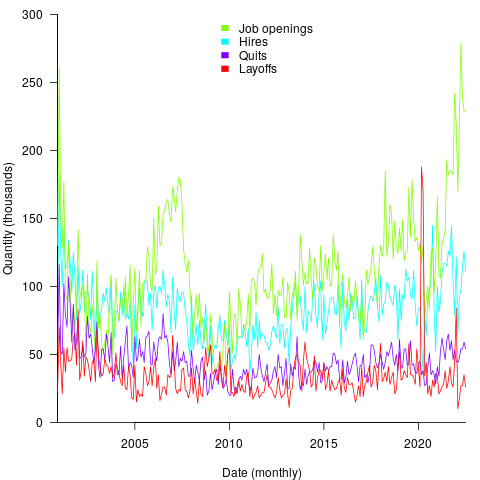
The general trend follows the ups and downs of the economy, there is a huge spike in layoffs in early 2020 (the start of COVID), and Job Openings often exceeding Hires (which I did not expect).
These counts have the form of a time-series, which leads to the questions about repeating patterns in the sequence of values? The plot below shows the autocorrelation of the four employment counts (code+data):

The spike in Hires at 12-months is too large to be just be new graduates entering the workforce; perhaps large IT employers have annual reviews for all employees at the same time every year, causing some people to quit and obtain new jobs (Quits has a slightly larger spike at 12-months). Why is there a regular 3-month cycle for Job Openings? The negative correlation in Layoffs at one & two months is explained by companies laying off a batch of workers one month, followed by layoffs in the following two months being lower than usual.
I don’t know much about employment practices, so I won’t speculate any more. Comments welcome.
Are there any interest cross-correlations between the pairs of time-series?
The plot below shows four pairs of cross correlations (code+data):

Hires & Layoffs shows a scattered pattern of Hires preceding Layoffs (to be expected), and the bottom left shows there is a pattern of Quits preceding Layoffs (are people searching for steadier employment when layoffs loom?). Top right shows a pattern of Job Openings following Hires (I’m clutching at straws for this; is Hires a proxy for Quits, the cross correlation of Job Openings & Quits does have Job Openings leading), the bottom right shows the pattern of Hires leading Quits.
Nothing in this analysis surprised me, but then it is rather basic and broad brush. These results are the start of an analysis of the IT employment ecosystem; one that probably won’t progress far because of a lack of data and interest on my part.
A new career in software development: advice for non-youngsters
Lately I have been encountering non-young people looking to switch careers, into software development. My suggestions have centered around the ageism culture and how they can take advantage of fashions in software ecosystems to improve their job prospects.
I start by telling them the good news: the demand for software developers outstrips supply, followed by the bad news that software development culture is ageist.
One consequence of the preponderance of the young is that people are heavily influenced by fads and fashions, which come and go over less than a decade.
The perception of technology progresses through the stages of fashionable, established and legacy (management-speak for unfashionable).
Non-youngsters can leverage the influence of fashion’s impact on job applicants by focusing on what is unfashionable, the more unfashionable the less likely that youngsters will apply, e.g., maintaining Cobol and Fortran code (both seriously unfashionable).
The benefits of applying to work with unfashionable technology include more than a smaller job applicant pool:
- new technology (fashion is about the new) often experiences a period of rapid change, and keeping up with change requires time and effort. Does somebody with a family, or outside interests, really want to spend time keeping up with constant change at work? I suspect not,
- systems depending on unfashionable technology have been around long enough to prove their worth, the sunk cost has been paid, and they will continue to be used until something a lot more cost-effective turns up, i.e., there is more job security compared to systems based on fashionable technology that has yet to prove their worth.
There is lots of unfashionable software technology out there. Software can be considered unfashionable simply because of the language in which it is written; some of the more well known of such languages include: Fortran, Cobol, Pascal, and Basic (in a multitude of forms), with less well known languages including, MUMPS, and almost any mainframe related language.
Unless you want to be competing for a job with hordes of keen/cheaper youngsters, don’t touch Rust, Go, or anything being touted as the latest language.
Databases also have a fashion status. The unfashionable include: dBase, Clarion, and a whole host of 4GL systems.
Be careful with any database that is NoSQL related, it may be fashionable or an established product being marketed using the latest buzzwords.
Testing and QA have always been very unsexy areas to work in. These areas provide the opportunity for the mature applicants to shine by highlighting their stability and reliability; what company would want to entrust some young kid with deciding whether the software is ready to be released to paying customers?
More suggestions for non-young people looking to get into software development welcome.
NoEstimates panders to mismanagement and developer insecurity
Why do so few software development teams regularly attempt to estimate the duration of the feature/task/functionality they are going to implement?
Developers hate giving estimates; estimating is very hard and estimates are often inaccurate (at a minimum making the estimator feel uncomfortable and worse when management treats an estimate as a quotation). The future is uncertain and estimating provides guidance.
Managers tell me that the fear of losing good developers dissuades them from requiring teams to make estimates. Developers have told them that they would leave a company that required them to regularly make estimates.
For most of the last 70 years, demand for software developers has outstripped supply. Consequently, management has to pay a lot more attention to the views of software developers than the views of those employed in most other roles (at least if they want to keep the good developers, i.e., those who will have no problem finding another job).
It is not difficult for developers to get a general idea of how their salary, working conditions and practices compares with other developers in their field/geographic region. They know that estimating is not a common practice, and unless the economy is in recession, finding a new job that does not require estimation could be straight forward.
Management’s demands for estimates has led to the creation of various methods for calculating proxy estimate values, none of which using time as the unit of measure, e.g., Function points and Story points. These methods break the requirements down into smaller units, and subcomponents from these units are used to calculate a value, e.g., the Function point calculation includes items such as number of user inputs and outputs, and number of files.
How accurate are these proxy values, compared to time estimates?
As always, software engineering data is sparse. One analysis of 149 projects found that  , with the variance being similar to that found when time was estimated. An analysis of Function point calculation data found a high degree of consistency in the calculations made by different people (various Function point organizations have certification schemes that require some degree of proficiency to pass).
, with the variance being similar to that found when time was estimated. An analysis of Function point calculation data found a high degree of consistency in the calculations made by different people (various Function point organizations have certification schemes that require some degree of proficiency to pass).
Managers don’t seem to be interested in comparing estimated Story points against estimated time, preferring instead to track the rate at which Story points are implemented, e.g., velocity, or burndown. There are tiny amounts of data comparing Story points with time and Function points.
The available evidence suggests a relationship connecting Function points to actual time, and that Function points have similar error bounds to time estimates; the lack of data means that Story points are currently just a source of technobabble and number porn for management power-points (send me Story point data to help change this situation).
Burger flippers with STEM degrees
There continues to be a lot of fuss over the shortage of STEM staff (Science, technology, engineering, and mathematics). But analysis of the employment data suggests there is no STEM shortage.
One figure than jumps out is the unemployment rate for computing graduates, why is this rate of so consistently much higher than other STEM graduates, 12% vs. under 9% for the rest?
Based on my somewhat limited experience of sitting on industrial panels in university IT departments (the intended purpose of such panels is to provide industry input, but in practice we are there to rubber stamp what the department has already decided to do) and talking with recent graduates, I would explain the situation described above was follows:
The dynamics from the suppliers’ side (i.e., the Universities) is that students want a STEM degree, students are the customer (i.e., they are paying) and so the university had better provide degrees that the customer can pass (e.g., minimise the maths content and make having to learn how to program optional on computing courses). Students get a STEM degree, but those taking the ‘easy’ route are unemployable in STEM jobs.
There is not a shortage of people with STEM degrees, but there is a shortage of people with STEM degrees who can walk the talk.
Today’s burger flippers have STEM degrees that did not require students to do any serious maths or learn to program.
Recent Comments