Archive
Predicted impact of LLM use on developer ecosystems
LLMs are not going to replace developers. Next token prediction is not the path to human intelligence. LLMs provide a convenient excuse for companies not hiring or laying off developers to say that the decision is driven by LLMs, rather than admit that their business is not doing so well
Once the hype has evaporated, what impact will LLMs have on software ecosystems?
The size and complexity of software systems is limited by the human cognitive resources available for its production. LLMs provide a means to reduce the human cognitive effort needed to produce a given amount of software.
Using LLMs enables more software to be created within a given budget, or the same amount of software created with a smaller budget (either through the use of cheaper, and presumably less capable, developers, or consuming less time of more capable developers).
Given the extent to which companies compete by adding more features to their applications, I expect the common case to be that applications contain more software and budgets remain unchanged. In a Red Queen market, companies want to be perceived as supporting the latest thing, and the marketing department needs something to talk about.
Reducing the effort needed to create new features means a reduction in the delay between a company introducing a new feature that becomes popular, and the competition copying it.
LLMs will enable software systems to be created that would not have been created without them, because of timescales, funding, or lack of developer expertise.
I think that LLMs will have a large impact on the use of programming languages.
The quantity of training data (e.g., source code) has an impact on the quality of LLM output. The less widely used languages will have less training data. The table below lists the gigabytes of source code in 30 languages contained in various LLM training datasets (for details see The Stack: 3 TB of permissively licensed source code by Kocetkov et al.):
Language TheStack CodeParrot AlphaCode CodeGen PolyCoder HTML 746.33 118.12 JavaScript 486.2 87.82 88 24.7 22 Java 271.43 107.7 113.8 120.3 41 C 222.88 183.83 48.9 55 C++ 192.84 87.73 290.5 69.9 52 Python 190.73 52.03 54.3 55.9 16 PHP 183.19 61.41 64 13 Markdown 164.61 23.09 CSS 145.33 22.67 TypeScript 131.46 24.59 24.9 9.2 C# 128.37 36.83 38.4 21 GO 118.37 19.28 19.8 21.4 15 Rust 40.35 2.68 2.8 3.5 Ruby 23.82 10.95 11.6 4.1 SQL 18.15 5.67 Scala 14.87 3.87 4.1 1.8 Shell 8.69 3.01 Haskell 6.95 1.85 Lua 6.58 2.81 2.9 Perl 5.5 4.7 Makefile 5.09 2.92 TeX 4.65 2.15 PowerShell 3.37 0.69 FORTRAN 3.1 1.62 Julia 3.09 0.29 VisualBasic 2.73 1.91 Assembly 2.36 0.78 CMake 1.96 0.54 Dockerfile 1.95 0.71 Batchfile 1 0.7 Total 3135.95 872.95 715.1 314.1 253.6 |
The major companies building LLMs probably have a lot more source code (as of July 2023, the Software Heritage had over  unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
unique source code files); this table gives some idea of the relative quantities available for different languages, subject to recency bias. At the moment, companies appear to be training using everything they can get their hands on. Would LLM performance on the widely used languages improve if source code for most of the 682 languages listed on Wikipedia was not included in their training data?
Traditionally, developers have had to spend a lot of time learning the technical details about how language constructs interact. For the first few languages, acquiring fluency usually takes several years.
It’s possible that LLMs will remove the need for developers to know much about the details of the language they are using, e.g., they will define variables to have the appropriate type and suggest possible options when type mismatches occur.
Removing the fluff of software development (i.e., writing the code) means that developers can invest more cognitive resources in understanding what functionality is required, and making sure that all the details are handled.
Removing a lot of the sunk cost of language learning removes the only moat that some developers have. Job adverts could stop requiring skills with particular programming languages.
Little is currently known about developer career progression, which means it’s not possible to say anything about how it might change.
Since they were first created, programming languages have fascinated developers. They are the fashion icon of software development, with youngsters wanting to program in the latest language, or at least not use the languages used by their parents. If developers don’t invest in learning language details, they have nothing language related to discuss with other developers. Programming languages will cease to be a fashion icon (cpus used to be a fashion icon, until developers did not need to know details about them, such as available registers and unique instructions). Zig could be the last language to become fashionable.
I don’t expect the usage of existing language features to change. LLMs mimic the characteristics of the code they were trained on.
When new constructs are added to a popular language, it can take years before they start to be widely used by developers. LLMs will not use language constructs that don’t appear in their training data, and if developers are relying on LLMs to select the appropriate language construct, then new language constructs will never get used.
By 2035 things should have had time to settle down and for the new patterns of developer behavior to be apparent.
Studying the lifetime of Open source
A software system can be said to be dead when the information needed to run it ceases to be available.
Provided the necessary information is available, plus time/money, no software ever has to remain dead, hardware emulators can be created, support libraries can be created, and other necessary files cobbled together.
In the case of software as a service, the vendor may simply stop supplying the service; after which, in my experience, critical components of the internal service ecosystem soon disperse and are forgotten about.
Users like the software they use to be actively maintained (i.e., there are one or more developers currently working on the code). This preference is culturally driven, in that we are living through a period in which most in-use software systems are actively maintained.
Active maintenance is perceived as a signal that the software has some amount of popularity (i.e., used by other people), and is up-to-date (whatever that means, but might include supporting the latest features, or problem reports are being processed; neither of which need be true). Commercial users like actively maintained software because it enables the option of paying for any modifications they need to be made.
Software can be a zombie, i.e., neither dead or alive. Zombie software will continue to work for as long as the behavior of its external dependencies (e.g., libraries) remains sufficiently the same.
Active maintenance requires time/money. If active maintenance is required, then invest the time/money.
Open source software has become widely used. Is Open source software frequently maintained, or do projects inhabit some form of zombie state?
Researchers have investigated various aspects of the life cycle of open source projects, including: maintenance activity, pull acceptance/merging or abandoned, and turnover of core developers; also, projects in niche ecosystems have been investigated.
The commits/pull requests/issues, of circa 1K project repos with lots of stars, is data that can be automatically extracted and analysed in bulk. What is missing from the analysis is the context around the creation, development and apparent abandonment of these projects.
Application areas and development tools (e.g., editor, database, gui framework, communications, scientific, engineering) tend to have a few widely used programs, which continue to be actively worked on. Some people enjoy creating programs/apps, and will start development in an area where there are existing widely used programs, purely for the enjoyment or to scratch an itch; rarely with the intent of long term maintenance, even when their project attracts many other developers.
I suspect that much of the existing research is simply measuring the background fizz of look-alike programs coming and going.
A more realistic model of the lifecycle of Open source projects requires human information; the intent of the core developers, e.g., whether the project is intended to be long-term, primarily supported by commercial interests, abandoned for a successor project, or whether events got in the way of the great things planned.
Ecology as a model for the software world
Changing two words in the Wikipedia description of Ecology gives “… the study of the relationships between software systems, including humans, and their physical environment”; where physical environment might be taken to include the hardware on which software runs and the hardware whose behavior it controls.
What do ecologists study? Wikipedia lists the following main areas; everything after the first sentence, in each bullet point, is my wording:
- Life processes, antifragility, interactions, and adaptations.
Software system life processes include its initial creation, devops, end-user training, and the sales and marketing process.
While antifragility is much talked about, it is something of a niche research topic. Those involved in the implementations of safety-critical systems seem to be the only people willing to invest the money needed to attempt to build antifragile software. Is N-version programming the poster child for antifragile system software?
Interaction with a widely used software system will have an influence on the path taken by cultures within associated microdomains. Users adapt their behavior to the affordance offered by a software system.
A successful software system (and even unsuccessful ones) will exist in multiple forms, i.e., there will be a product line. Software variability and product lines is an active research area.
- The movement of materials and energy through living communities.
Is money the primary unit of energy in software ecosystems? Developer time is needed to create software, which may be paid for or donated for free. Supporting a software system, or rather supporting the needs of the users of the software is often motivated by a salary, although a few do provide limited free support.
What is the energy that users of software provide? Money sits at the root; user attention sells product.
- The successional development of ecosystems (“… succession is the process of change in the species structure of an ecological community over time.”)
Before the Internet, monthly computing magazines used to run features on the changing landscape of the computer world. These days, we have blogs/podcasts telling us about the latest product release/update. The Ecosystems chapter of my software engineering book has sections on evolution and lifespan, but the material is sparse.
Over the longer term, this issue is the subject studied by historians of computing.
Moore’s law is probably the most famous computing example of succession.
- Cooperation, competition, and predation within and between species.
These issues are primarily discussed by those interested in the business side of software. Developers like to brag about how their language/editor/operating system/etc is better than the rest, but there is no substance to the discussion.
Governments have an interest in encouraging effective competition, and have enacted various antitrust laws.
- The abundance, biomass, and distribution of organisms in the context of the environment.
These are the issues where marketing departments invest in trying to shift the distribution in their company’s favour, and venture capitalists spend their time trying to spot an opportunity (and there is the clickbait of language popularity articles).
The abundance of tools/products, in an ecosystem, does not appear to deter people creating new variants (suggesting that perhaps ambition or dreams are the unit of energy for software ecosystems).
- Patterns of biodiversity and its effect on ecosystem processes.
Various kinds of diversity are important for biological systems, e.g., the mutual dependencies between different species in a food chain, and genetic diversity as a resource that provides a mechanism for species to adapt to changes in their environment.
It’s currently fashionable to be in favour of diversity. Diversity is so popular in ecology that a 2003 review listed 24 metrics for calculating it. I’m sure there are more now.
Diversity is not necessarily desired in software systems, e.g., the runtime behavior of source code should not depend on the compiler used (there are invariably edge cases where it does), and users want different editor command to be consistently similar.
Open source has helped to reduce diversity for some applications (by reducing the sales volume of a myriad of commercial offerings). However, the availability of source code significantly reduces the cost/time needed to create close variants. The 5,000+ different cryptocurrencies suggest that the associated software is diverse, but the rapid evolution of this ecosystem has driven developers to base their code on the source used to implement earlier currencies.
Governments encourage competitive commercial ecosystems because competition discourages companies charging high prices for their products, just because they can. Being competitive requires having products that differ from other vendors in a desirable way, which generates diversity.
Open source: the goody bag for software infrastructure
For 70 years there has been a continuing discovery of larger new ecosystems for new software to grow into, as well as many small ones. Before Open source became widely available, the software infrastructure (e.g., compilers, editors and libraries of algorithms) for these ecosystems had to be written by the pioneer developers who happened to find themselves in an unoccupied land.
Ecosystems may be hardware platforms (e.g., mainframes, minicomputers, microcomputers and mobile phones), software platforms (e.g., Microsoft Windows, and Android), or application domains (e.g., accounting and astronomy)
There are always a few developers building some infrastructure project out of interest, e.g., writing a compiler for their own or another language, or implementing an editor that suites them. When these projects are released, they have to compete against the established inhabitants of an ecosystem, along with other newly released software clamouring for attention.
New ecosystems have limited established software infrastructure, and may not yet have attracted many developers to work within them. In such ‘virgin’ ecosystems, something new and different faces less competition, giving it a higher probability of thriving and becoming established.
Building from scratch is time-consuming and expensive. Adapting existing software systems speeds things up and reduces costs; adaptation also has the benefit of significantly reducing the startup costs when recruiting developers, i.e., making it possible for experienced people to use the skills acquired while working in other ecosystems. By its general availability, Open source creates competition capable of reducing the likelihood that some newly created infrastructure software will become established in a ‘virgin’ ecosystem.
Open source not only reduces startup costs for those needing infrastructure for a new ecosystem, it also reduces ongoing maintenance costs (by spreading them over multiple ecosystems), and developer costs (by reducing the need to learn something different, which happened to be created by developers who built from scratch).
Some people will complain that Open source is reducing diversity (where diversity is viewed as unconditionally providing benefits). I would claim that reducing diversity in this case is a benefit. Inventing new ways of doing things based on the whims of those doing the invention is a vanity project. I have nothing against people investing their own resources on their own vanity projects, but let’s not pretend that the diversity generated by such projects is likely to provide benefits to others.
By providing the components needed to plug together a functioning infrastructure, Open source reduces the cost of ecosystem ‘invasion’ by software. The resources which might have been invested building infrastructure components can be directed to building higher level functionality.
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
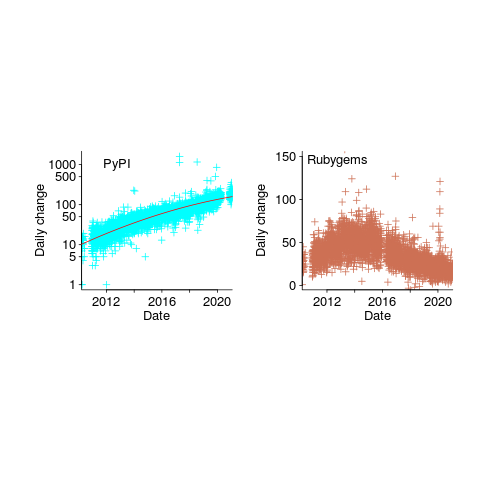
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
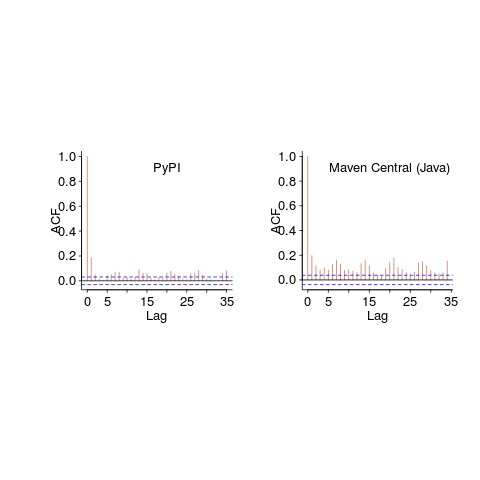
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Memory capacity growth: a major contributor to the success of computers
The growth in memory capacity is the unsung hero of the computer revolution. Intel’s multi-decade annual billion dollar marketing spend has ensured that cpu clock frequency dominates our attention (a lot of people don’t know that memory is available at different frequencies, and this can have a larger impact on performance that cpu frequency).
In many ways memory capacity is more important than clock frequency: a program won’t run unless enough memory is available but people can wait for a slow cpu.
The growth in memory capacity of customer computers changed the structure of the software business.
When memory capacity was limited by a 16-bit address space (i.e., 64k), commercially saleable applications could be created by one or two very capable developers working flat out for a year. There was no point hiring a large team, because the resulting application would be too large to run on a typical customer computer. Very large applications were written, but these were bespoke systems consisting of many small programs that ran one after the other.
Once the memory capacity of a typical customer computer started to regularly increase it became practical, and eventually necessary, to create and sell applications offering ever more functionality. A successful application written by one developer became rarer and rarer.
Microsoft Windows is the poster child application that grew in complexity as computer memory capacity grew. Microsoft’s MS-DOS had lots of potential competitors because it was small (it was created in an era when 64k was a lot of memory). In the 1990s the increasing memory capacity enabled Microsoft to create a moat around their products, by offering an increasingly wide variety of functionality that required a large team of developers to build and then support.
GCC’s rise to dominance was possible for the same reason as Microsoft Windows. In the late 1980s gcc was just another one-man compiler project, others could not make significant contributions because the resulting compiler would not run on a typical developer computer. Once memory capacity took off, it was possible for gcc to grow from the contributions of many, something that other one-man compilers could not do (without hiring lots of developers).
How fast did the memory capacity of computers owned by potential customers grow?
One source of information is the adverts in Byte (the magazine), lots of pdfs are available, and perhaps one day a student with some time will extract the information.
Wikipedia has plenty of articles detailing cpu performance, e.g., Macintosh models by cpu type (a comparison of Macintosh models does include memory capacity). The impact of Intel’s marketing dollars on the perception of computer systems is a PhD thesis waiting to be written.
The SPEC benchmarks have been around since 1988, recording system memory capacity since 1994, and SPEC make their detailed data public 🙂 Hardware vendors are more likely to submit SPEC results for their high-end systems, than their run-of-the-mill systems. However, if we are looking at rate of growth, rather than absolute memory capacity, the results may be representative of typical customer systems.
The plot below shows memory capacity against date of reported benchmarking (which I assume is close to the date a system first became available). The lines are fitted using quantile regression, with 95% of systems being above the lower line (i.e., these systems all have more memory than those below this line), and 50% are above the upper line (code+data):
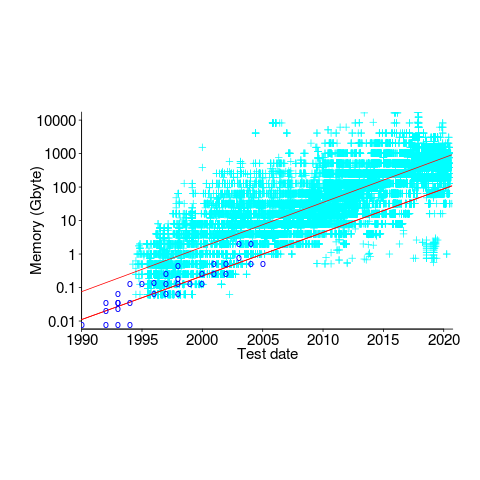
The fitted models show the memory capacity doubling every 845 or 825 days. The blue circles are memory that comes installed with various Macintosh systems, at time of launch (memory doubling time is 730 days).
How did applications’ minimum required memory grow over time? I have a patchy data for a smattering of products, extracted from Wikipedia. Some vendors probably required customers to have a fairly beefy machine, while others went for a wider customer base. Data on the memory requirements of the various versions of products launched in the 1990s is very hard to find. Pointers very welcome.
Learning useful stuff from the Ecosystems chapter of my book
What useful, practical things might professional software developers learn from the Ecosystems chapter in my evidence-based software engineering book?
This week I checked the ecosystems chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader would conclude that software engineering ecosystems involved lots of topics, with little or no theory connecting them. I had great plans for the connecting theories, but lack of detailed data, time and inspiration means the plans remain in my head (e.g., modelling the interaction between the growth of source code written in a particular language and the number of developers actively using that language).
For managers, the usefulness of this chapter is the strategic perspective it provides. How does what they and others are doing relate to everything else, and what patterns of evolution are to be expected?
Software people like to think that everything about software is unique. Software is unique, but the activities around it follow patterns that have been followed by other unique technologies, e.g., the automobile and jet engines. There is useful stuff to be learned from non-software ecosystems, and the chapter discusses some similarities I have learned about.
There is lots more evidence of the finite lifetime of software related items: lifetime of products, Linux distributions, packages, APIs and software careers.
Some readers might be surprised by the amount of discussion about what is now historical hardware. Software needs hardware to execute it, and the characteristics of the hardware of the day can have a significant impact on the characteristics of the software that gets written. I suspect that most of this discussion will not be that useful to most readers, but it provides some context around why things are the way they are today.
Readers with a wide knowledge of software ecosystems will notice that several major ecosystems barely get a mention. Embedded systems is a huge market, as is Microsoft Windows, and very many professional developers use C++. However, to date the focus of most research has been around Linux and Android (because its use of Java, a language often taught in academia), and languages that have a major package repository. So the ecosystems chapter presents a rather blinkered view of software engineering ecosystems.
What did I learn from this chapter?
Software ecosystems are bigger and more complicated that I had originally thought.
Readers might have a completely different learning experience from reading the ecosystems chapter. What useful things did you learn from the ecosystems chapter?
Ecosystems chapter of “evidence-based software engineering” reworked
The Ecosystems chapter of my evidence-based software engineering book has been reworked (I have given up on the idea that this second pass is also where the polishing happens; polishing still needs to happen, and there might be more material migration between chapters); download here.
I have been reading books on biological ecosystems, and a few on social ecosystems. These contain lots of interesting ideas, but the problem is, software ecosystems are just very different, e.g., replication costs are effectively zero, source code does not replicate itself (and is not self-evolving; evolution happens because people change it), and resources are exchanged rather than flowing (e.g., people make deals, they don’t get eaten for lunch). Lots of caution is needed when applying ecosystem related theories from biology, the underlying assumptions probably don’t hold.
There is a surprising amount of discussion on the computing world as it was many decades ago. This is because ecosystem evolution is path dependent; understanding where we are today requires knowing something about what things were like in the past. Computer memory capacity used to be a big thing (because it was often measured in kilobytes); memory does not get much publicity because the major cpu vendor (Intel) spends a small fortune on telling people that the processor is the most important component inside a computer.
There are a huge variety of software ecosystems, but you would not know this after reading the ecosystems chapter. This is because the work of most researchers has been focused on what used to be called the desktop market, which over the last few years the focus has been shifting to mobile. There is not much software engineering research focusing on embedded systems (a vast market), or supercomputers (a small market, with lots of money), or mainframes (yes, this market is still going strong). As the author of an evidence-based book, I have to go where the data takes me; no data, then I don’t have anything to say.
Empirical research (as it’s known in academia) needs data, and the ‘easy’ to get data is what most researchers use. For instance, researchers analyzing invention and innovation invariably use data on patents granted, because this data is readily available (plus everybody else uses it). For empirical research on software ecosystems, the readily available data are package repositories and the Google/Apple Apps stores (which is what everybody uses).
The major software ecosystems barely mentioned by researchers are the customer ecosystem (the people who pay for everything), the vendors (the companies in the software business) and the developer ecosystem (the people who do the work).
Next, the Projects chapter.
Changes in the shape of code during the twenties?
At the end of 2009 I made two predictions for the next decade; Chinese and Indian developers having a major impact on the shape of code (ok, still waiting for this to happen), and scripting languages playing a significant role (got that one right, but then they were already playing a large role).
Since this blog has just entered its second decade, I will bring the next decade’s predictions forward a year.
I don’t see any new major customer ecosystems appearing. Ecosystems are the drivers of software development, and no new ecosystems has several consequences, including:
- No major new languages: Creating a language is a vanity endeavour. Vanity project can take off if they are in the right place at the right time. New ecosystems provide opportunities for new languages to become widely used by being in at the start and growing with the ecosystem. There is another opportunity locus; it is fashionable for companies that see themselves as thought-leaders to have their own language, e.g., Google, Apple, and Mozilla. Invent your language at the right time, while working for a thought-leader company and your language could become well-known enough to take-off.
I don’t see any major new ecosystems appearing, and all the likely companies already have their own language.
Any new language also faces the problem of not having a large collection packages.
- Software will be more thoroughly tested: When an ecosystem is new, the incentives drive early and frequent releases (to build a customer base); software just has to be good enough. Once a product is established, companies can invest in addressing issues that customers find annoying, like faulty behavior; the incentive change results in more testing.
There are other forces at work around testing. Companies are experiencing some very expensive faults (testing may be expensive, but not testing may be more expensive) and automatic test generation is becoming commercially usable (i.e., the cost of some kinds of testing is decreasing).
The evolution of widely used languages.
- I think Fortran and C will have new features added, with relatively little fuss, and will quietly continue to be widely used (to the dismay of the fashionista).
-
There is a strong expectation that C++ and Java should continue to evolve:
- I expect the ISO C++ work to implode, because there are too many people pulling in too many directions. It makes sense for the gcc and llvm teams to cooperate in taking C++ in a direction that satisfies developers’ needs, rather than the needs of bored consultants. What are Microsoft’s views? They only have their own compiler for strategic reasons (they make little if any profit selling compilers, compilers are an unnecessary drain on management time; who cares what happens to the language).
- It is going to be interesting watching the impact of Oracle’s move to charging for runtimes. I have no idea what might happen to Java.
In terms of code volume, the future surely has to be scripting languages, and in particular Python, Javascript and PHP. Ten years from now, will there be a widely used, single language? People have been predicting, for many years, that web languages will take over the world; perhaps there will be a sudden switch and I will see that the choice is obvious.
Moore’s law is now dead, which means researchers are going to have to look for completely new techniques for building logic gates. If photonic computers happen, then ternary notation may reappear again (it was used in at least one early Russian computer); I’m not holding my breath for this to occur.
Recent Comments