Archive
Algorithm complexity and implementation LOC
As computer functionality increases, it becomes easier to write programs to handle more complicated problems which require more computing resources; also, the low-hanging fruit has been picked and researchers need to move on. In some cases, the complexity of existing problems continues to increase.
The Linux kernel is an example of a solution to a problem that continues to increase in complexity, as measured by the number of lines of code.
The distribution of problem complexities will vary across application domains. Treating program size as a proxy for problem complexity is more believable when applied to one narrow application domain.
Since 1960, the journal Transactions on Mathematical Software has been making available the source code of implementations of the algorithms provided with the papers it publishes (before the early 1970s they were known as the Collected Algorithms of the ACM, and included more general algorithms). The plot below shows the number of lines of code in the source of the 893 published implementations over time, with fitted regression lines, in black, of the form  before 1994-1-1, and
before 1994-1-1, and  after that date (black dashed line is a LOESS regression model; code+data).
after that date (black dashed line is a LOESS regression model; code+data).
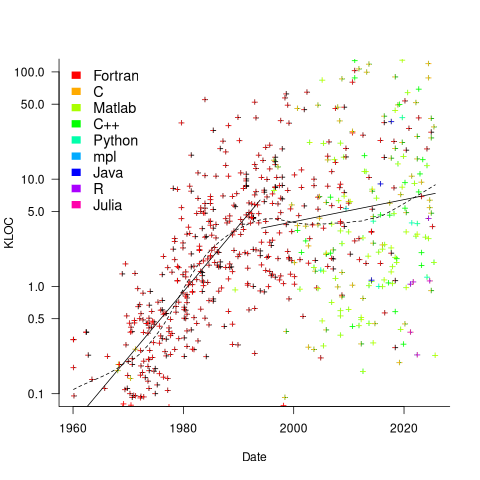
The two immediately obvious patterns are the sharp drop in the average rate of growth since the early 1990s (from 15% per year to 2% per year), and the dominance of Fortran until the early 2000s.
The growth in average implementation LOC might be caused by algorithms becoming more complicated, or because increasing computing resources meant that more code could be produced with the same amount of researcher effort, or another reason, or some combination. After around 2000, there is a significant increase in the variance in the size of implementations. I’m assuming that this is because some researchers focus on niche algorithms, while others continue to work on complicated algorithms.
An aim of Halstead’s early metric work was to create a measure of algorithm complexity.
If LLMs really do make researchers more productive, then in future years LOC growth rate should increase as more complicated problems are studied, or perhaps because LLMs generate more verbose code.
The table below shows the primary implementation language of the algorithm implementations:
Language Implementations
Fortran 465
C 79
Matlab 72
C++ 24
Python 7
R 4
Java 3
Julia 2
MPL 1 |
If algorithms are becoming more complicated, then the papers describing/analysing them are likely to contain more pages. The plot below shows the number of pages in the published papers over time, with fitted regression line of the form  (0.38 pages per year; red dashed line is a LOESS regression model; code+data).
(0.38 pages per year; red dashed line is a LOESS regression model; code+data).
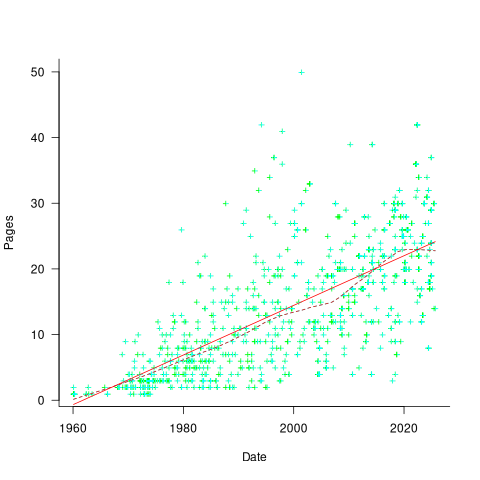
Unlike the growth of implementation LOC, there is no break-point in the linear growth of page count. Yes, page count is influence by factors such as long papers being less likely to be accepted, and being able to omit details by citing prior research.
It would be a waste of time to suggest more patterns of behavior without looking at a larger sample papers and their implementations (I have only looked at a handful).
When the source was distributed in several formats, the original one was used. Some algorithms came with build systems that included tests, examples and tutorials. The contents of the directories: CALGO_CD, drivers, demo, tutorial, bench, test, examples, doc were not counted.
Learning R as a language
Books written to teach a general purpose programming language are usually organized according to the features of the language and examples often show how a particular language feature is interpreted by a compiler. Books about domain specific languages are usually organized in a way that makes sense in the corresponding application domain and examples usually illustrate how a particular domain problem can be solved using the language.
I have spent a lot of time using R over the last year and by dint of reading lots of R code and various introductions to the language I have managed to piece together a model of the language. I rarely have any trouble learning a general purpose language from its reference manual, but users of domain specific languages are rarely interested in language details and so these reference manuals are usually only intended to be read by people who know the language well (another learning problem is that domain specific languages often contain quirky features rarely seen in other languages; in the case of R I was not lucky enough to know enough other languages to cover all its quirky features).
I managed to one introduction to R written from the perspective of the programming language (and not the application domain): the original The Art of R Programming by Norman Matloff has been expanded and is now available as a book.
Summary. If you know another language and want to quickly learn about the languages features of R I recommend this book. I have not taught raw beginners for over 30 years and have no idea if this book would be of any use to them.
This book does not attempt to teach you to think ‘R’, it is not about the art of R programming. The value of this book is as a single source for a broad coverage of lots of language features explained using lots of examples. Yes, more time could have been spent on the organization and fixing inconsistencies in the layout; these are not show stoppers.
Some people might tell you to buy “Software for Data Analysis” by John Chambers. Don’t; if you are a fan of Finnegans Wake and are nostalgic for the mainframe world of the 1970s you might like to give it a go. (I think Bertrand Meyer’s “Object-oriented Software Construction” is still the best book about the design of a language).
Meanderings. What books are good examples of “The Art of …” writing for domain specific languages? Two that spring to mind are: “Algorithms in Snobol 4” by James Gimpel (still spotted from time to time on second hand book sites) and more recently “SQL For Smarties: Advanced SQL Programming” by Joe Celko.
Yes, I know that R is not really a domain specific language but a language that is primarily used in one domain. Frink is an example of a language containing a major behavior feature that is specific to its intended application domain. I cannot think of any major language feature of R that is specific to statistics.
Recent Comments