Archive
My 2022 search for software engineering data
At the start of this year, 2022, I announced a crowdsourced search for software engineering data, in May, as part of this search I created the evidenceSE account on Twitter, once a week, on average, I attended an in-person Meetup somewhere in London, I gave one talk and a handful of lightening talks.
What software engineering data did all this effort uncover?
Thanks to Diomidis Spinellis the crowdsource search did not have a zero outcome (the company who provided some data has been rather busy, so progress on iterating on the data analysis has been glacial).
My time spent of Twitter did not even come close to finding a decent sized dataset (a couple of tiny ones were found). When I encountered a tweet claiming to involve evidence in software engineering, I replied asking for a reference to the evidence. Sometimes the original tweet was deleted, sometimes the user blocked me, and sometimes an exchange on the difficulty of obtaining data ensued.
I am a member of 87 meetup groups; essentially any software related group holding an in-person event in London in 2022, plus pre-COVID memberships. Event cadence was erratic, dramatically picking up before Christmas, and I’m expecting it to pick up again in the New Year. I learned some interesting stuff, and spoke to many interesting people, mostly working at large companies (i.e., they have lawyers, so little chance of obtaining data). The idea of an evidence-based approach to software engineering was new to a surprising number of people; the non-recent graduates all agreed that software engineering was driven by fashion/opinions/folklore. I spoke to several people who planned to spend time researching software development in 2023, and one person who ticked all the boxes as somebody who has data and might be willing to release it.
My ‘tradition’ method of finding data (i.e., reading papers and blogs) has continued to uncover new data, but at a slower rate than previous years. Is this a case of diminishing returns (my 2020 book does claim to discuss all the publicly available data), my not reading as many papers as in previous years, or the collateral damage from COVID?
Interesting sources of general data that popped-up in 2022.
- After years away, Carlos returned with his weekly digest Data Machina (now on substack),
- I discovered Data Is Plural, a weekly newsletter of useful/curious datasets.
Twitter and evidence-based software engineering
This year’s quest for software engineering data has led me to sign up to Twitter (all the software people I know, or know-of, have been contacted, and discovery through articles found on the Internet is a very slow process).
@evidenceSE is my Twitter handle. If you get into a discussion and want some evidence-based input, feel free to get me involved. Be warned that the most likely response, to many kinds of questions, is that there is no data.
My main reason for joining is to try and obtain software engineering data. Other reasons include trying to introduce an evidence-based approach to software engineering discussions and finding new (to me) problems that people want answers to (that are capable of being answered by analysing data).
The approach I’m taking is to find software engineering tweets discussing a topic for which some data is available, and to jump in with a response relating to this data. Appropriate tweets are found using the search pattern: (agile OR software OR "story points" OR "story point" OR "function points") (estimate OR estimates OR estimating OR estimation OR estimated OR #noestimates OR "evidence based" OR empirical OR evolution OR ecosystems OR cognitive). Suggestions for other keywords or patterns welcome.
My experience is that the only effective way to interact with developers is via meaningful discussion, i.e., cold-calling with a tweet is likely to be unproductive. Also, people with data often don’t think that anybody else would be interested in it, they have to convinced that it can provide valuable insight.
You never know who has data to share. At a minimum, I aim to have a brief tweet discussion with everybody on Twitter involved in software engineering. At a minute per tweet (when I get a lot more proficient than I am now, and have workable templates in place), I could spend two hours per day to reach 100 people, which is 35,000 per year; say 20K by the end of this year. Over the last three days I have managed around 10 per day, and obviously need to improve a lot.
How many developers are on Twitter? Waving arms wildly, say 50 million developers and 1 in 1,000 have a Twitter account, giving 50K developers (of which an unknown percentage are active). A lower bound estimate is the number of followers of popular software related Twitter accounts: CompSciFact has 238K, Unix tool tips has 87K; perhaps 1 in 200 developers have a Twitter account, or some developers have multiple accounts, or there are lots of bots out there.
I need some tools to improve the search process and help track progress and responses. Twitter has an API and a developer program. No need to worry about them blocking me or taking over my business; my usage is small fry and I’ not building a business to take over. I was at Twitter’s London developer meetup in the week (the first in-person event since Covid) and the youngsters present looked a lot younger than usual. I suspect this is because the slightly older youngsters remember how Twitter cut developers off at the knee a few years ago by shutting down some useful API services.
The Twitter version-2 API looks interesting, and the Twitter developer evangelists are keen to attract developers (having ‘wiped out’ many existing API users), and I’m happy to jump in. A Twitter API sandbox for trying things out, and there are lots of example projects on Github. Pointers to interesting tools welcome.
Join a crowdsourced search for software engineering data
Software engineering data, that can be made publicly available, is very rare; most people don’t attempt to collect data, and when data is collected, people rarely make any attempt to hang onto the data they do collect.
Having just one person actively searching for software engineering data (i.e., me) restricts potential sources of data to be English speaking and to a subset of development ecosystems.
This post is my attempt to start a crowdsourced campaign to search for software engineering data.
Finding data is about finding the people who have the data and have the authority to make it available (no hacking into websites).
Who might have software engineering data?
In the past, I have emailed chief technology officers at companies with less than 100 employees (larger companies have lawyers who introduce serious amounts of friction into releasing company data), and this last week I have been targeting Agile coaches. For my evidence-based software engineering book I mostly emailed the authors of data driven papers.
A lot of software is developed in India, China, South America, Russia, and Europe; unless these developers are active in the English-speaking world, I don’t see them.
If you work in one of these regions, you can help locate data by finding people who might have software engineering data.
If you want to be actively involved, you can email possible sources directly, alternatively I can email them.
If you want to be actively involved in the data analysis, you can work on the analysis yourself, or we can do it together, or I am happy to do it.
In the English-speaking development ecosystems, my connection to the various embedded ecosystems is limited. The embedded ecosystems are huge, there must be software data waiting to be found. If you are active within an embedded ecosystem, you can help locate data by finding people who might have software engineering data.
The email template I use for emailing people is below. The introduction is intended to create a connection with their interests, followed by a brief summary of my interest, examples of previous analysis, and the link to my book to show the depth of my interest.
By all means cut and paste this template, or create one that you feel is likely to work better in your environment. If you have a blog or Twitter feed, then tell them about it and why you think that evidence-based software engineering is important.
Be responsible and only email people who appear to have an interest in applying data analysis to software engineering. Don’t spam entire development groups, but pick the person most likely to be in a position to give a positive response.
This is a search for gold nuggets, and the response rate will be very low; a 10% rate of reply, saying sorry not data, would be better than what I get. I don’t have enough data to be able to calculate a percentage, but a ballpark figure is that 1% of emails might result in data.
My experience is that people are very unsure that anything useful will be found in their data. My response has been that I am always willing to have a look.
I always promise to anonymize their data, and not release it until they have agreed; but working on the assumption that the intent is to make a public release.
I treat the search as a background task, taking months to locate and email, say, 100-people considered worth sending a targeted email. My experience is that I come up with a search idea or encounter a blog post that suggests a line of enquiry, that may result in sending half-a-dozen emails. The following week, if I’m lucky, the same thing might happen again (perhaps with fewer emails). It’s a slow process.
If people want to keep a record of ideas tried, the evidence-based software engineering Slack channel could do with some activity.
Hello, A personalized introduction, such as: I have been reading your blog posts on XXX, your tweets about YYY, your youtube video on ZZZ. My interest is in trying to figure out the human issues driving the software process. Here are two detailed analysis of Agile estimation data: https://arxiv.org/abs/1901.01621 and https://arxiv.org/abs/2106.03679 My book Evidence-based Software Engineering discusses what is currently known about software engineering, based on an analysis of all the publicly available data. pdf+code+all data freely available here: http://knosof.co.uk/ESEUR/ and I'm always on the lookout for more software data. This email is a fishing request for software engineering data. I offer a free analysis of software data, provided an anonymised version of the data can be made public.
Estimate variability for the same task
If 100 people estimate the time needed to implement a feature, in software, what is the expected variability in the estimates?
Studies of multiple implementations of the same specification suggest that standard deviation of the mean number of lines across implementations is 25% of the mean (based on data from 10 sets of multiple implementations, of various sizes).
The plot below shows lines of code against the number of programs (implementing the 3n+1 problem) containing that many lines (red line is a Normal distribution fitted by eye, code and data):
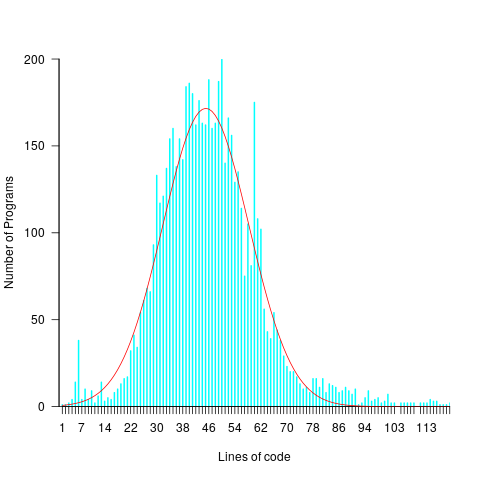
Might any variability in the estimates for task implementation be the result of individuals estimating their own performance (which is variable)?
To the extent that an estimate is based on a person’s implementation experience, a developer’s past performance will have some impact on their estimate. However, studies have found a great deal of variability between individual estimates and their corresponding performance.
One study asked 14 companies to bid on implementing a system (four were eventually chosen to implement it; see figure 5.2 in my book). The estimated elapsed time varied by a factor of ten. Until the last week this was the only study of this question for which the data was available (and may have been the only such study).
A study by Alhamed and Storer investigated crowd-sourcing of effort estimates, structured by use of planning poker. The crowd were workers on Amazon’s Mechanical Turk, and the tasks estimated came from the issue trackers of JBoss, Apache and Spring Integration (using issues that had been annotated with an estimate and actual time, along with what was considered sufficient detail to make an estimate). An initial set of 419 issues were whittled down to 30, which were made available, one at a time, as a Mechanical Turk task (i.e., only one issue was available to be estimated at any time).
Worker estimates were given using a time-based category (i.e., the values 1, 4, 8, 20, 40, 80), with each value representing a unit of actual time (i.e., one hour, half-day, day, half-week, week and two weeks, respectively).
Analysis of the results from a pilot study were used to build a model that detected estimates considered to be low quality, e.g., providing a poor justification for the estimate. These were excluded from any subsequent iterations.
Of the 506 estimates made, 321 passed the quality check.
Planning poker is an iterative process, with those making estimates in later rounds seeing estimates made in earlier rounds. So estimates made in later rounds are expected to have some correlation with earlier estimates.
Of the 321 quality check passing estimates, 153 were made in the first-round. Most of the 30 issues have 5 first-round estimates each, one has 4 and two have 6.
Workers have to pick one of five possible value as their estimate, with these values being roughly linear on a logarithmic scale, i.e., it is not possible to select an estimate from many possible large values, small values, or intermediate values. Unless most workers pick the same value, the standard deviation is likely to be large. Taking the logarithm of the estimate maps it to a linear scale, and the plot below shows the mean and standard deviation of the log of the estimates for each issue made during the first-round (code+data):

The wide spread in the standard deviations across a spread of mean values may be due to small sample size, or it may be real. The only way to find out is to rerun with larger sample sizes per issue.
Now it has been done once, this study needs to be run lots of times to measure the factors involved in the variability of developer estimates. What would be the impact of asking workers to make hourly estimates (they would not be anchored by experimenter specified values), or shifting the numeric values used for the categories (which probably have an anchoring effect)? Asking for an estimate to fix an issue in a large software system introduces the unknown of all kinds of dependencies, would estimates provided by workers who are already familiar with a project be consistently shifted up/down (compared to estimates made by those not familiar with the project)? The problem of unknown dependencies could be reduced by giving workers self-contained problems to estimate, e.g., the 3n+1 problem.
The crowdsourcing idea is interesting, but I don’t think it will scale, and I don’t see many companies making task specifications publicly available.
To mimic actual usage, research on planning poker (which appears to have non-trivial usage) needs to ensure that the people making the estimates are involved during all iterations. What is needed is a dataset of lots of planning poker estimates. Please let me know if you know of one.
Recent Comments