Archive
Naming convergence in a network of pairwise interactions
While naming and categorizing things are perhaps the two most contentious issues in software engineering, there is often a great deal of similarity in the names and categorizes used by unconnected groups. These characteristics of naming and categorization are general observed behaviors across cultures and languages, with software engineering being a particular example.
Studies have found that a particular name for a thing is likely to become adopted by a group, if around 25% of its members actively promote the use of the name. The terms tipping point and critical mass have been applied to the 25% quantity.
What factors could cause 25% of the members of a group to select a particular name, and why does a tipping point occur at around this percentage?
The paper Experimental evidence for scale-induced category convergence across populations by Douglas Guilbeault (PhD thesis behind the paper), Andrea Baronchelli, and Damon Centola experimentally investigated factors that can cause a name to be adopted by 25% of a group’s members, and the researchers proposed a model that exhibits behavior similar to the experimental results (the supplement contains the technical details).
The experiment asked subjects to play the “Grouping Game”. The 1,480 online subjects were divided into networks containing either 2, 6, 8, 24 or 50 members. The interaction between members of a network only occurred via randomly selected pairs (the same pair for the network of two), with one person designated as the speaker and the other as the hearer. A pair saw three randomly selected images, such as the one below. For the speaker only, one of the images was highlighted, and they had to give a name containing at most six characters to the image. The hearer saw the name given by the speaker to one of the images, and had 30 seconds to choose the image they considered to have been named. If the image selected by the hearer was the one named by the speaker, both received a small payment, otherwise an even smaller amount was deducted from their final payment. Each subject played 100 rounds with the randomly chosen members of their network.

The images were created as a series of 50+ distinct patterns whose shape slowly morphed along a continuum, as in the following image:

The experimental results were that larger networks converged to a consistent, within group, naming of the images (using a few names), while smaller groups rarely converged and used many different names. The researchers proposed that as the network size grew, common names were encountered more often than rarer names, increasing the likelihood of reaching a tipping point. This behavior is similar to the birthday paradox, where there is a 50% probability that in a room of 23 people, two people will share the same birthday.
In the experiment, some networks included confederates trained to use a small subset of names, i.e., the researchers created a common set of names. It was hypothesized built-in human preferences would produce common patterns in the real world that, for larger groups, would cause tipping points to occur, amplifying the more common patterns to become group norms.
The supplement to the paper develops a theoretical model based on the probability of  identical items being contained in a sample of
identical items being contained in a sample of  items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
items, when sampling without replacement. The solution involves the hypergeometric distribution, which is difficult to deal with analytically, so simulation is needed. The results show a tipping point at around 25%.
The plot below shows a density plot for one 50-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 14 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
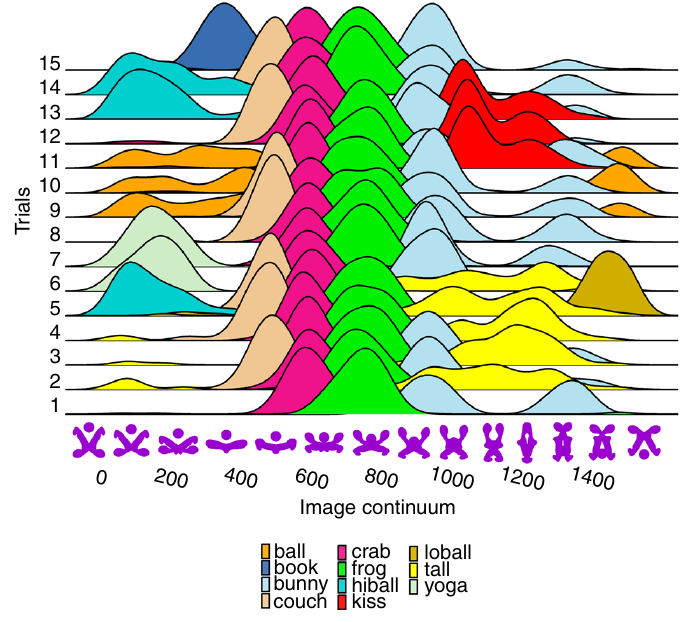
This plot shows that the same name is often used across trials, and naming boundaries between some images.
The plot below shows a density plot for one 2-subject network over 15 trials (after 100 rounds of pairwise interaction), with each color denoting one of the 72 chosen names (height of the curve denotes likelihood of the same name being chosen for that image; code and data):
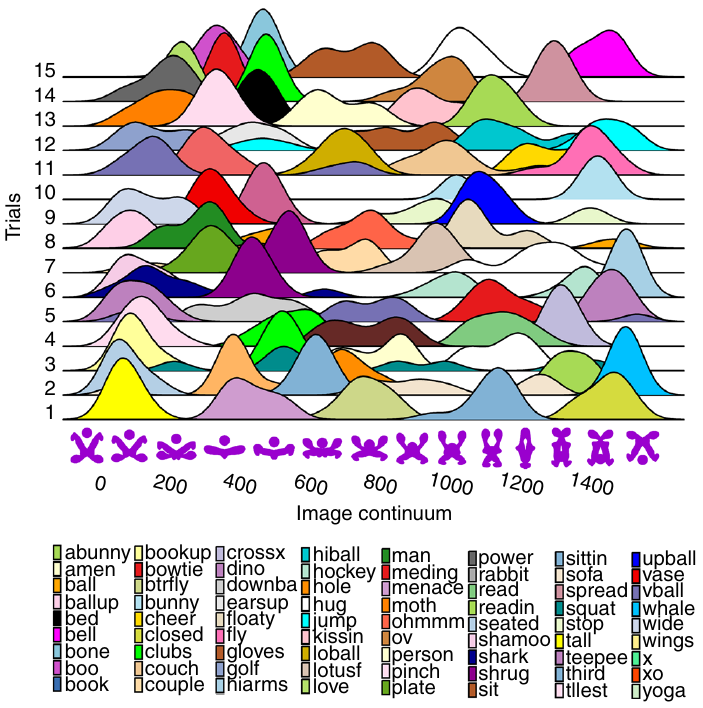
Here there is no consistent naming across trials, a much greater diversity of names appearing, and no obvious naming boundaries between images.
Recent Comments