Archive
Estimation accuracy in the (building|road) construction industry
Lots of people complain about software development taking longer than estimated. Are estimates in other industries more accurate, and do they contain patterns similar to those seen in software task estimates?
Readers will probably not be surprised to learn that obtaining estimate/actual data is as hard for other industries as it is for software.
Software engineering sometimes gets compared with building construction, in the sense that building construction is perceived as being straightforward and predictable. My tiny experience with building construction is that it is not as straightforward and predictable as outsiders think, a view echoed by the few people in the building industry I have spoken to.
I have found two building datasets, the supplementary material from: Forecasting the Project Duration Average and Standard Deviation from Deterministic Schedule Information (the 101 rows also include some service projects), and Ballesteros-Pérez kindly sent me the data for Duration and Cost Variability of Construction Activities: An Empirical Study which included 746 rows of road construction estimate/actual data from an unknown source. This data is for large projects, where those involved had to bid to get the work.
The following plot reminds us of how effort vs actual often looks like for short software tasks; it includes a fitted regression model and prediction intervals at one standard deviation (68.3%) and two standard deviations (95%); the faint grey line shows Estimate == Actual (post discussing the analysis and linking to code+data):
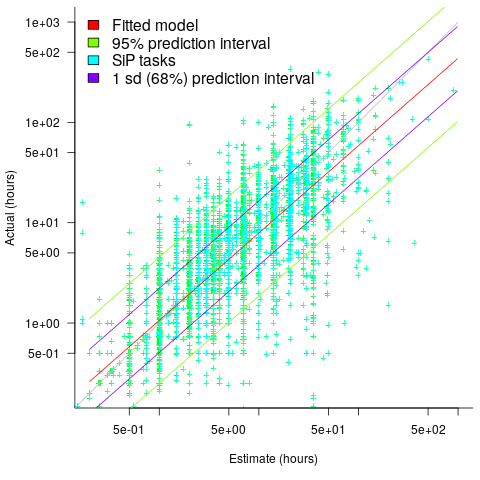
The data in the above plot is for small tasks, which did not involve bidding for the work.
The following plot shows estimated vs actual duration for 101 construction projects. The red line has the form:  , i.e., average estimate is 9% lower than actual duration (blue line shows
, i.e., average estimate is 9% lower than actual duration (blue line shows  ; code+data).
; code+data).
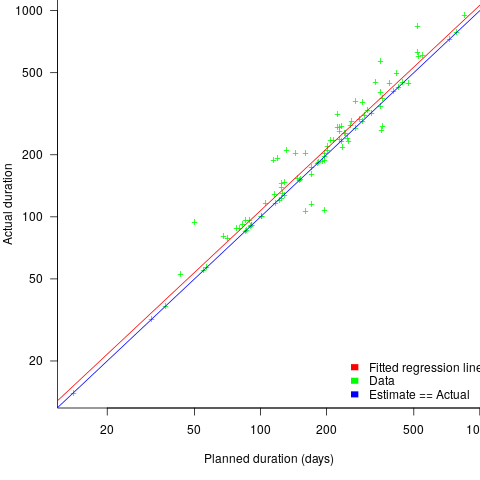
The obvious differences are that the fitted line shows consistent underestimation (hardly surprising when bidding for work; 16% of estimates are greater than the actual), that the variance of project estimate/actual about the line is much smaller for building construction, and that the red/blue lines are essentially parallel (the exponent for software tasks is consistently around 0.85, rather than 1)
The following plot shows estimated vs actual for 746 road construction projects. The red line has the form:  , i.e., average estimate is 24% lower than actual duration (blue line shows ; code+data):
, i.e., average estimate is 24% lower than actual duration (blue line shows ; code+data):
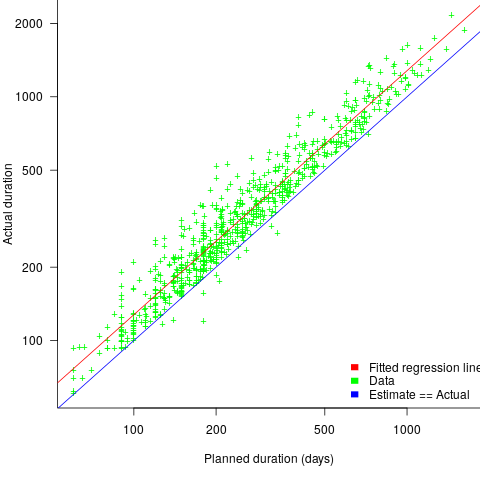
Again there is a consistent average underestimate (project bidding was via an auction process), the red/blue lines are essentially parallel, and while the estimate/actual variance is larger than for building construction only 1.5% estimates are greater than the actual.
Consistent underestimating is not surprising for external projects awarded via a bidding process.
The unpredicted differences are the much smaller estimate/actual variance (compared to software), and the fitted line running parallel to .
A Wikihouse hackathon
I was at the Wikihouse hackathon on Wednesday. Wikihouse is an open-source project involving prefabricated house designs and building processes.
Why is a software guy attending what looks like a very non-software event? The event organizers listed software developer as one of the attendee skill sets. Also, I have been following the blog Construction Physics, where Brian Potter has been trying to work out why the efficiency of building construction has not significantly improved over many decades; the approach is wide-ranging, data driven and has parallels with my analysis of software engineering. I counted four software people at the event, out of 30’ish attendees; Sidd I knew from previous hacks.
Building construction shares some characteristics with software development. In particular, projects are bespoke, but constructed using subcomponents that are variations on those used in most other projects of the same kind of building, e.g., walls±window frames, floors/ceilings.
The Wikihouse design and build process is based around a collection of standardised, prefabricated subcomponents, called blocks; these are made from plywood, slotted together, and held in place using butterfly/bow-tie joints (wood has a negative carbon footprint). A library of blocks is available, with the page for each block including a DXF cutting file, assembly manual, 3-D model, and costing; there is a design kit for building a house, including a spreadsheet for costing, and a variety of How-Tos. All this is available under an open source license. The Open Systems Lab is implementing building design software and turning planning codes into code.
Not knowing anything about building construction, I have no way of judging the claims made during the hackathon introductory presentations, e.g., cost savings, speed of build, strength of building, expected lifetime, etc.
Constructing lots of buildings using Wikihouse blocks could produce an interesting dataset (provided those doing the construction take the time to record things). Questions such as: how does construction time vary by team composition (self-build is possible) and experience, and by number of rooms and their size spring to mind (no construction time/team data was recorded during the construction of the ‘beta test’ buildings).
The morning was taken up with what was essentially a product pitch, then we got shown around the ‘beta test’ buildings (they feel bigger on the inside), lunch and finally a few hours hacking. The help they wanted from software people was in connecting together some of the data/tools they had created, but with only a few hours available there was little that could be done (my input was some suggestions on construction learning curves and a few people/groups I knew doing construction data analysis)
Will an open source approach enable the Wikihouse project to succeed with its prefabricated approach to building construction, where closed source companies have failed when using this approach, e.g., Katerra?
Part of the reason that open source software succeeded was that it provided good enough functionality to startup projects/companies who could not afford to pay for software (in some cases the open source tools provided superior functionality). Some of these companies grew to be significant players, convincing others that open source was viable for production work. Source code availability allows developers to use it without needing to involve management, and plenty of managers have been surprised to find out how embedded open source software is within their group/organization.
Buildings are not like software, lots of people with some kind of power notice when a new building appears. Buildings need to be connected to services such as water, gas and electricity, and they have a rateable value which the local council is keen to collect. Land is needed to build on, and there are a whole host of permissions and certificates that need to be obtained before starting to build and eventually moving in. Doing it, and telling people later is not an option, at least in the UK.
Finding patterns in construction project drawing creation dates
I took part in Projecting Success‘s 13th hackathon last Thursday and Friday, at CodeNode (host to many weekend hackathons and meetups); around 200 people turned up for the first day. Team Designing-Success included Imogen, Ryan, Dillan, Mo, Zeshan (all building construction domain experts) and yours truly (a data analysis monkey who knows nothing about construction).
One of the challenges came with lots of real multi-million pound building construction project data (two csv files containing 60K+ rows and one containing 15K+ rows), provided by SISK. The data contained information on project construction drawings and RFIs (request for information) from 97 projects.
The construction industry is years ahead of the software industry in terms of collecting data, in that lots of companies actually collect data (for some, accumulate might be a better description) rather than not collecting/accumulating data. While they have data, they don’t seem to be making good use of it (so I am told).
Nearly all the discussions I have had with domain experts about the patterns found in their data have been iterative, brief email exchanges, sometimes running over many months. In this hack, everybody involved is sitting around the same table for two days, i.e., the conversation is happening in real-time and there is a cut-off time for delivery of results.
I got the impression that my fellow team-mates were new to this kind of data analysis, which is my usual experience when discussing patterns recently found in data. My standard approach is to start highlighting visual patterns present in the data (e.g., plot foo against bar), and hope that somebody says “That’s interesting” or suggests potentially more interesting items to plot.
After several dead-end iterations (i.e., plots that failed to invoke a “that’s interesting” response), drawings created per day against project duration (as a percentage of known duration) turned out to be of great interest to the domain experts.
Building construction uses a waterfall process; all the drawings (i.e., a kind of detailed requirements) are supposed to be created at the beginning of the project.
Hmm, many individual project drawing plots were showing quite a few drawings being created close to the end of the project. How could this be? It turns out that there are lots of different reasons for creating a drawing (74 reasons in the data), and that it is to be expected that some kinds of drawings are likely to be created late in the day, e.g., specific landscaping details. The 74 reasons were mapped to three drawing categories (As built, Construction, and Design Development), then project drawings were recounted and plotted in three colors (see below).
The domain experts (i.e., everybody except me) enjoyed themselves interpreting these plots. I nodded sagely, and occasionally blew my cover by asking about an acronym that everybody in the construction obviously knew.
The project meta-data includes a measure of project performance (a value between one and five, derived from profitability and other confidential values) and type of business contract (a value between one and four). The data from the 97 projects was combined by performance and contract to give 20 aggregated plots. The evolution of the number of drawings created per day might vary by contract, and the hypothesis was that projects at different performance levels would exhibit undesirable patterns in the evolution of the number of drawings created.
The plots below contain patterns in the quantity of drawings created by percentage of project completion, that are: (left) considered a good project for contract type 1 (level 5 are best performing projects), and (right) considered a bad project for contract type 1 (level 1 is the worst performing project). Contact the domain experts for details (code+data):
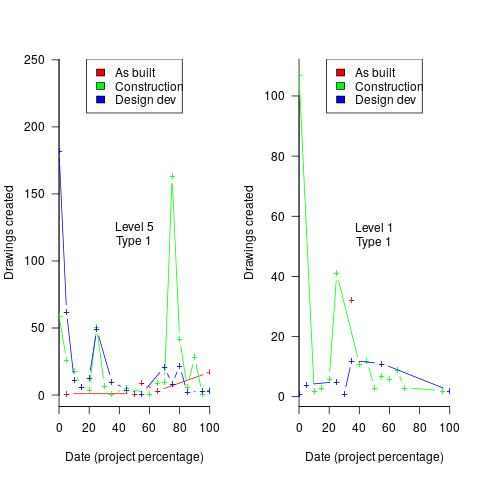
The path to the above plot is a common one: discover an interesting pattern in data, notice that something does not look right, use domain knowledge to refine the data analysis (e.g., kinds of drawing or contract), rinse and repeat.
My particular interest is using data to understand software engineering processes. How do these patterns in construction drawings compare with patterns in the software project equivalents, e.g., detailed requirements?
I am not aware of any detailed public data on requirements produced using a waterfall process. So the answer is, I don’t know; but the rationales I heard for the various kinds of drawings sound as-if they would have equivalents in the software requirements world.
What about the other data provided by the challenge sponsor?
I plotted various quantities for the RFI data, but there wasn’t any “that’s interesting” response from the domain experts. Perhaps the genius behind the plot ideas will be recognized later, or perhaps one of the domain experts will suddenly realize what patterns should be present in RFI data on high performance projects (nobody is allowed to consider the possibility that the data has no practical use). It can take time for the consequences of data analysis to sink in, or for new ideas to surface, which is why I am happy for analysis conversations to stretch out over time. Our presentation deck included some RFI plots because there was RFI data in the challenge.
What is the software equivalent of construction RFIs? Perhaps issues in a tracking system, or Jira tickets? I did not think to talk more about RFIs with the domain experts.
How did team Designing-Success do?
In most hackathons, the teams that stay the course present at the end of the hack. For these ProjectHacks, submission deadline is the following day; the judging is all done later, electronically, based on the submitted slide deck and video presentation. The end of this hack was something of an anti-climax.
Did team Designing-Success discover anything of practical use?
I think that finding patterns in the drawing data converted the domain experts from a theoretical to a practical understanding that it was possible to extract interesting patterns from construction data. They each said that they planned to attend the next hack (in about four months), and I suggested that they try to bring some of their own data.
Can these drawing creation patterns be used to help monitor project performance, as it progressed? The domain experts thought so. I suspect that the users of these patterns will be those not closely associated with a project (those close to a project are usually well aware of that fact that things are not going well).
Recent Comments