Archive
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
C compiler conformance testing: with ChatGPT assistance
How can developers check that a compiler correctly implements all the behavior requirements contained in the corresponding language specification?
An obvious approach is to write lots of test cases for each distinct behavior; such a collection of tests is known as a validation suite, when used by a standard’s organization to test compilers/OS interfaces/etc. The extent to which a compiler’s behavior, when fed these tests, matches that listed in the language specification is a measure of its conformance.
In a world of many compilers with significant differences in behavior (i.e., pre-Open source), it makes economic sense for governments to sponsor the creation of validation suites, and/or companies to offer such suites commercially (mainly for C and C++). The spread of Open source compilers decimated compiler diversity, and compiler validation is fading into history.
New features continue to be added to Cobol, Fortran, C, and C++ by their respective ISO Standard’s committee. If governments are no longer funding updates to validation suites and the cost of commercial suites is too high for non-vendors (my experience is that compiler vendors find them to be cost-effective), how can developers check that a compiler conforms to the behavior specified by the Standard?
How much effort is required to create some minimal set of compiler conformance tests?
C is the language whose requirements I am most familiar with. The C Standard specifies that a conforming compiler issue a diagnostic for a violation of a requirement appearing in a Constraint clause, e.g., “For addition, either both operands shall have arithmetic type, or …”
There are 80 such clauses, containing around 530 non-blank lines, in N3301, the June 2024 draft. Let’s say 300+ distinct requirements, requiring a minimum of one test each. Somebody very familiar with the C Standard might take, say, 10 minutes per test, which is 3,000 minutes, or 50 hours, or 6.7 days; somebody slightly less familiar might take, say, at least an hour, which is 300+ hours, or 40+ days.
Lots of developers are using LLMs to generate source code from a description of what is needed. Given Constraint requirements in the C Standard, can an LLM generate tests that do a good enough job checking a compiler’s conformance to the C Standard?
Simply feeding the 157 pages from the Language chapter of the C Standard into an LLM, and asking it to generate tests for each Constraint requirement does not seem practical with the current state of the art; I’m happy to be proved wrong. A more focused approach might produce the desired tests.
Negative tests are likely to be the most challenging for an LLM to generate, because most publicly available source deals with positive cases, i.e., it is syntactically/semantically correct. The wording of Constraints sometimes specifies what usage is not permitted (e.g., clause 6.4.5.3 “A floating suffix df, dd, dl, DF, DD, or DL shall not be used in a hexadecimal floating literal.”), other times specifies what usage is permitted (e.g., clause 6.5.3.4 “The first operand of the . operator shall have an atomic, qualified, or unqualified structure or union type, and the second operand shall name a member of that type.”), or simply specifies a requirement (e.g., clause 6.7.3.2 “A member declaration that does not declare an anonymous structure or anonymous union shall contain a member declarator list.”).
I took the text from the 80 Constraint clauses, removed footnote numbers and rejoined words split at line-breaks. The plan was to prefix the text of each Constraint with instructions on the code requires. After some experimentation, the instructions I settled on were:
Write a sequence of very short programs which tests that a C compiler correctly flags each violation of the requirements contained in the following excerpt from the latest draft of the C Standard: |
Initially, excerpt was incorrectly spelled as except, but this did not seem to have any effect. Perhaps this misspelling is sufficiently common in the training data, that LLM weights support the intended association.
Experiments using Grok and ChatGPT 4o showed that both generated technically correct tests, but Grok generated code that was intended to be run (and was verbose), while the ChatGPT 4o output was brief and to the point; it did such a good job that I did not try any other LLMs. For this extended test, use of the web interface proved to be an effective approach. Interfacing via the API is probably more practical for larger numbers of requirements.
After some experimentation, I submitted the text from 31 Constraint clauses (I picked the non-trivial ones). The complete text of the questions and ChatGPT 4o responses (text files).
ChatGPT sometimes did not generate tests for all the requirements, when these were presented as they appeared in the Constraint, but did generate tests when the containing sentence was presented in isolation from other requirement sentences. For instance, the following sentence from clause 6.5.5 Cast Operators:
Conversions that involve pointers, other than where permitted by the constraints of 6.5.17.2, shall be specified by means of an explicit cast. |
was ignored when included as part of the complete Constraint, but when presented in isolation, reasonable tests were generated.
The responses never contained more than 10 test cases. I am guessing that this is the result of limits on response cpu time/length. Dividing the text of longer Constraints should solve this issue.
Some assumptions made by ChatGPT 4o about the implementation can be deduced from its responses, e.g., it appears to treat the type short as containing fewer than 32-bits (it assumes that a bit-field defined as a short containing 32-bits will be treated as a Constraint violation). This is not surprising, given the volume of public C source targeting the Intel x86.
I was impressed by the quality of the 242 test cases generated by ChatGPT 4o, which often included multiple tests for the same requirement (text files).
While it sometimes failed to produce a test for a requirement, I did not spot any incorrect tests (as in, not correctly testing for a violation of a listed requirement); the subset of tests feed through behaved as claimed), and I eventually found a prompt that appears to be creating a downloadable zip file of all the tests (most prompts resulted in a zip file containing some collection of 10 tests); the creation process is currently waiting for available cpu time. I now know that downloading a zip file containing one file per test, after each user prompt, is the more reliable option.
How useful are automatically generated compiler tests?
Over the last decade, testing compilers using automatically generated source code has been a popular research topic (for those working in the compiler field; Csmith kicked off this interest). Compilers are large complicated programs, and they will always contain mistakes that lead to faults being experienced. Previous posts of mine have raised two issues on the use of automatically generated tests: a financial issue (i.e., fixing reported faults costs money {most of the work on gcc and llvm is done by people working for large companies}, and is intended to benefit users not researchers seeking bragging rights for their latest paper), and applicability issue (i.e., human written code has particular characteristics and unless automatically generated code has very similar characteristics the mistakes it finds are unlikely to commonly occur in practice).
My claim that mistakes in compilers found by automatically generated code are unlikely to be the kind of mistakes that often lead to a fault in the compilation of human written code is based on the observations (I don’t have any experimental evidence): the characteristics of automatically generated source is very different from human written code (I know this from measurements of lots of code), and this difference results in parts of the compiler that are infrequently executed by human written code being more frequently executed (increasing the likelihood of a mistake being uncovered; an observation based on my years working on compilers).
An interesting new paper, Compiler Fuzzing: How Much Does It Matter?, investigated the extent to which fault experiences produced by automatically generated source are representative of fault experiences produced by human written code. The first author of the paper, Michaël Marcozzi, gave a talk about this work at the Papers We Love workshop last Sunday (videos available).
The question was attacked head on. The researchers instrumented the code in the LLVM compiler that was modified to fix 45 reported faults (27 from four fuzzing tools, 10 from human written code, and 8 from a formal verifier); the following is an example of instrumented code:
warn ("Fixing patch reached"); if (Not.isPowerOf2()) { if (!(C-> getValue().isPowerOf2() // Check needed to fix fault && Not != C->getValue())) { warn("Fault possibly triggered"); } else { /* CODE TRANSFORMATION */ } } // Original, unfixed code |
The instrumented compiler was used to build 309 Debian packages (around 10 million lines of C/C++). The output from the builds were (possibly miscompiled) built versions of the packages, and log files (from which information could be extracted on the number of times the fixing patches were reached, and the number of cases where the check needed to fix the fault was triggered).
Each built package was then checked using its respective test suite; a package built from miscompiled code may successfully pass its test suite.
A bitwise compare was run on the program executables generated by the unfixed and fixed compilers.
The following (taken from Marcozzi’s slides) shows the percentage of packages where the fixing patch was reached during the build, the percentages of packages where code added to fix a fault was triggered, the percentage where a different binary was generated, and the percentages of packages where a failure was detected when running each package’s tests (0.01% is one failure):
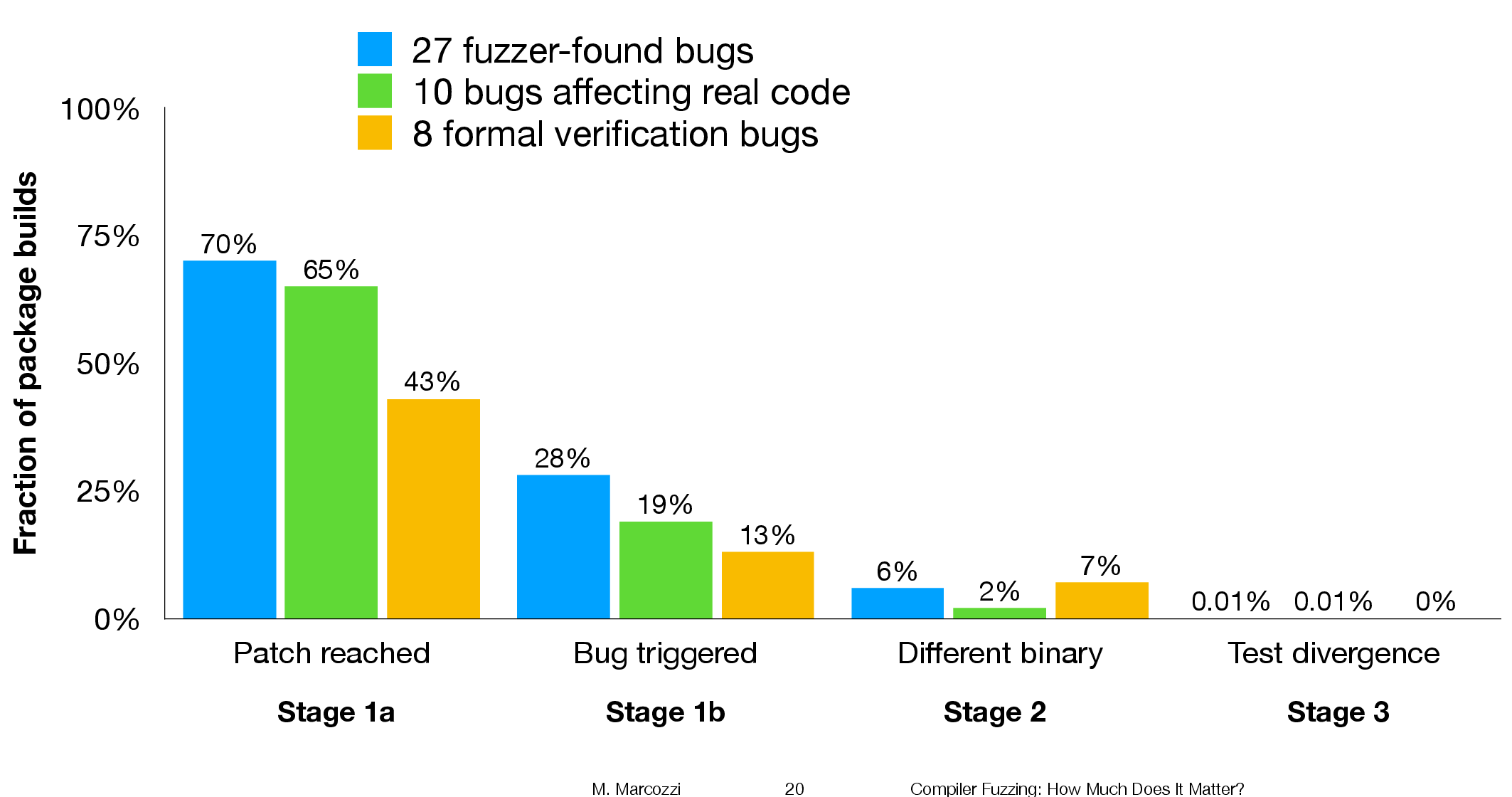
The takeaway from the above figure is that many packages are affected by the coding mistakes that have been fixed, but that most package test suites are not affected by the miscompilations.
To find out whether there is a difference, in terms of impact on Debian packages, between faults reported in human and automatically generated code, we need to compare the number of occurrences of “Fault possibly triggered”. The table below shows the break-down by the detector of the coding mistake (i.e., Human and each of the automated tools used), and the number of fixed faults they contributed to the analysis.
Human, Csmith and EMI each contributed 10-faults to the analysis. The fixes for the 10-fault reports in human generated code were triggered 593 times when building the 309 Debian packages, while each of the 10 Csmith and EMI fixes were triggered 1,043 and 948 times respectively; a lot more than the Human triggers :-O. There are also a lot more bitwise compare differences for the non-Human fault-fixes.
Detector Faults Reached Triggered Bitwise-diff Tests failed Human 10 1,990 593 56 1 Csmith 10 2,482 1,043 318 0 EMI 10 2,424 948 151 1 Orange 5 293 35 8 0 yarpgen 2 608 257 0 0 Alive 8 1,059 327 172 0 |
Is the difference due to a few packages being very different from the rest?
The table below breaks things down by each of the 10-reported faults from the three Detectors.
Ok, two Human fault-fix locations are never reached when compiling the Debian packages (which is a bit odd), but when the locations are reached they are just not triggering the fault conditions as often as the automatic cases.
Detector Reached Triggered
Human
300 278
301 0
305 0
0 0
0 0
133 44
286 231
229 0
259 40
77 0
Csmith
306 2
301 118
297 291
284 1
143 6
291 286
125 125
245 3
285 16
205 205
EMI
130 0
307 221
302 195
281 32
175 5
122 0
300 295
297 215
306 191
287 10 |
It looks like I am not only wrong, but that fault experiences from automatically generated source are more (not less) likely to occur in human written code (than fault experiences produced by human written code).
This is odd. At best, I would expect fault experiences from human and automatically generated code to have the same characteristics.
Ideas and suggestions welcome.
Update: the morning after
I have untangled my thoughts on how to statistically compare the three sets of data.
The bootstrap is based on the idea of exchangeability; which items being measured might we consider to be exchangeable, i.e., being able to treat the measurement of one as being the equivalent to measuring the other.
In this experiment, the coding mistakes are not exchangeable, i.e., different mistakes can have different outcomes.
But we might claim that the detection of mistakes is exchangeable; that is, a coding mistake is just as likely to be detected by source code produced by an automatic tool as source written by a Human.
The bootstrap needs to be applied without replacement, i.e., each coding mistake is treated as being unique. The results show that for the sum of the Triggered counts (code+data):
- treating Human and Csmith as being equally likely to detect the same coding mistake, there is a 18% change of the Human results being lower than 593.
- treating Human and EMI as being equally likely to detect the same coding mistake, there is a 12% change of the Human results being lower than 593.
So the likelihood of the lower value, 593, of Human Triggered events is expected to occur quite often (i.e., 12% and 18%). Automatically generated code is not more likely to detect coding mistakes than human written code (at least based on this small sample set).
Compiler validation is now part of history
Compiler validation makes sense in a world where there are many different hardware platforms, each with their own independent compilers (third parties often implemented compilers for popular platforms, competing against the hardware vendor). A large organization that spends hundreds of millions on a multitude of computer systems (e.g., the U.S. government) wants to keep prices down, which means the cost of porting its software to different platforms needs to be kept down (or at least suppliers need to think it will not cost too much to switch hardware).
A crucial requirement for source code portability is that different compilers be able to compile the same source, generating code that produces the same behavior. The same behavior requirement is an issue when the underlying word-size varies or has different alignment requirements (lots of code relies on data structures following particular patterns of behavior), but management on all sides always seems to think that being able to compile the source is enough. Compilers vendors often supported extensions to the language standard, and developers got to learn they were extensions when porting to a different compiler.
The U.S. government funded a conformance testing service, and paid for compiler validation suites to be written (source code for what were once the Cobol 85, Fortran 78 and SQL validation suites). While it was in business, this conformance testing service was involved C compiler validation, but it did not have to fund any development because commercial test suites were available.
The 1990s was the mass-extinction decade for companies selling non-Intel hardware. The widespread use of Open source compilers, coupled with the disappearance of lots of different cpus (porting compilers to new vendor cpus was always a good money spinner, for the compiler writing cottage industry), meant that many compilers disappeared from the market.
These days, language portability issues have been essentially solved by a near monoculture of compilers and cpus. It’s the libraries that are the primary cause of application portability problems. There is a test suite for POSIX and Linux has its own tests.
There are companies selling compiler C/C++ test suites (e.g., Perennial and PlumHall); when maintaining a compiler, it’s cost-effective to have a set of third-party tests designed to exercise all the language.
The OpenGroup offer to test your C compiler and issue a brand certificate if it passes the tests.
Source code portability requires compilers to have the same behavior and traditionally the generally accepted behavior has been defined by an ISO Standard or how one particular implementation behaved. In an Open source world, behavior is defined by what needs to be done to run the majority of existing code. Does it matter if Open source compilers evolve in a direction that is different from the behavior specified in an ISO Standard? I think not, it makes no difference to the majority of developers; but be careful, saying this can quickly generate a major storm in a tiny teacup.
Testing compiler semantics with minimal manual input
The 2011 revision of the C++ Standard added lots of new constructs to the language and in the past few months both the GCC and LLVM teams have been claiming that the next release of their C++ compilers will fully support the 2011 Standard. How true are these claims? One way of answering this question is to run both compilers over an extensive test suite. There are commercial C++ compiler test suites available, but I don’t have access to them and if I did the license agreement would probably not allow me to talk in detail about the results. Writing compiler tests cases requires a very detailed knowledge of the language; I have done it often enough in previous lives to know that more than a year or so of my time would be needed just to get my head around the semantics of the new C++ features, before I could produce anything half decent.
Is there a way of automating the generation of test cases for language semantics? Automated statement/expression generation is very effective at finding problems with optimizers and code generators. Can this technique be applied to check the semantic requirements of a language?
Having concocted various elaborate schemes over the years I recently realised that life would be a lot simpler if I was willing to accept a very high percentage of erroneous test programs (the better manually written test suites usually contain around as many test cases that intended to fail to compile as tests that pass, i.e., intended to compile correctly; the not so good ones have few failing tests).
If two or more compilers are available the behavior of each of them on a given source file can be compared: differential testing. If both compile a file or fail to compile it, they may both be right or wrong; either way this shared behavior is not interesting, but is likely to be the common case. The interesting case is if one compiles a file and the other fails to compile it; this could be a fault in one of them, or one of those cases where the Standard permits compilers to do their own thing.
I hereby jump to the conclusion that behavior differences is a good proxy for compiler conformance to the language Standard (actually developers are often more interested in all compilers they are likely to use having the same external behavior than conforming to a Standard).
Lets implement this (source code here)!
First we need to generate lots of test cases. The process I used is based on program templates, such as the following (lines starting with ! are places where various constructs can be inserted):
int v; ! declare_id 2 int main(void) { ! declare_id 2 ! ref_id 2 } |
the identifier after the ! is the name of a file containing lines to be inserted at the given location (the number after the identifier is the maximum number of lines that can be inserted at that point; default 1 if no number given). The following is example file contents for the above template:
declare_id
int i; enum {i, j}; enum i {x, y}; struct i {int f;}; typedef int i; |
ref_id
enum i ev_i; struct i sv_i; typedef i tv_i; v=i; |
It is then simply a matter of permuting through all of the possible combinations of lines that can be inserted in the program template, creating a stand alone file for each possibility (18,000 of them in the above example); I used the Python Natural Language Toolkit to do the heavy lifting.
A shell script compiles each source file and compares the compiler exit codes. For the above example there were 16,366 failures, 1,634 passes and no differences (this example contains well established C constructs and any difference would have been surprising).
Next, a feature new in C++11, lambda functions!
Here is the template used:
! declare_xy 2 int main(void) { ! declare_xy 2 auto foo_bar = ! define_lambda ; return 0; } |
I cut and pasted some examples from the Standard to create the following optional lines:
define_lambda
[](float a, float b) { return a + b; } [=](float a, float b) { return a + b; } [=,x](float a, float b) { return a + b; } [y](float a, float b) { return a + b; } [=]()->int { return operator()(this->x + y); } [&, i]{ } [=] { decltype(x) y1; decltype((x)) y2 = y1; decltype(y) r1 = y1; decltype((y)) r2 = y2; } |
which generated 6,300 source files of which 5,865 failed, 396 passed and 39 were treated differently by the compilers (g++ version 4.7.2, clang version 3.3).
How should the percentages be calculated? If we take the human written numbers for well written test suites containing (roughly) equal numbers of pass/fail tests, then we have around 800 tests of which (say) 40 gave different behavior, giving us a 5% fault rate. Do we share that 5% equally between both compilers or assign 3% for both being wrong and 1% for each being uniquely wrong?
Submitting a bug report to both compiler teams pointing out that their behavior is different from the other’s is a sure fire way to make myself unpopular. Any suggestions for how to resolve this issue, that does not involve me having to study the tiresomely long and convoluted C++ Standard, welcome.
C compiler validation is 21 today!
Today, 1 September 2011, is the 21th anniversary of the first formally validated C compilers. The three ‘equal first’ validated compilers were the Model Implementation C Checker from Knowledge Software, Topspeed C from JPI (run by the people who created Turbo Pascal) and the INMOS C compiler (derived from the Norcroft C compiler written by Alan Mycroft+others, the author of the longest response document seen during the review of the C89 draft standard).
Back in the day the British Standards Institution testing group run by John Souter were the world leaders in compiler validation and were very proactive in adding support for a new language. NIST, the equivalent US body, did not offer such a service until a few years later. Those companies in a position to have their compilers validated (i.e., the compiler passed the validation suite) were pressing BSI to be first; the ‘who is first’ issue was resolved by giving all certificates the same date (the actual validation process of a person from BSI, Neil Martin now Director of Test in the Winterop Team at Microsoft, turning up to ‘witness’ the compiler passing the tests happened several weeks earlier).
Testing C compilers was different from other language compilers in that sufficient demand existed to support commercial production and maintenance of test suites (the production of validation suites for previous language compilers had been government funded). After a review of the available test suites BSI chose to use the Plum Hall suite; after a similar review NIST chose to use the Perennial suite (I got involved in trying to figure out for NIST how well this suite covered the requirements contained in the C Standard).
For a while C compiler validation was big business (as in big fish, very small pond). But the compiler validation market is dependent on there being lots of compilers, which requires market fragmentation and to a lesser extent lots of different OSs and hardware platforms (each needing a separate validation). The 1990s saw market consolidation, gcc becoming good enough for commercial use and a shift of developer mind share to C++. Dwindling revenue resulted in BSI’s compiler validation group being shut down after a few years and NIST’s followed in 1998.
Is compiler validation relevant today? When the first C Standard was published a lot of compilers in common use had some significant behavioural differences compared to what the Standard specified. Over time these compilers have either disappeared or been upgraded (a potential customer once asked me the benefits I saw in them licensing the Knowledge Software front end and the reply to one of my responses, “you can tell your customers that the compiler is standard’s compliant”, was that this was not a benefit as they had been claiming this for years). Improvements in Intel’s x86 processor also had a hand in improving compiler Standard’s conformance; the various memory models used by the x86 processor was a huge headache for compiler writers whose products often behaved very differently under different memory models; the arrival of the Pentium with its flat 32-bit address space meant this issue disappeared over time.
These days I suspect that the major compilers targeting platforms where portability is expected (portability is often not a big expectation in the embedded world) are sufficiently compatible that developers are willing to overlook small differences with the Standard. Differences in third party libraries, GUIs and other frameworks have been the big headache for many years now.
Would the ‘platform portability’ compilers, that’s probably gcc, Microsoft, products using EDG’s front end, and perhaps llvm in the coming years, pass the latest version of the PlumHall and Perennial suites?
- The gcc team do not have access to either company’s suite. The gcc regression tests are a poor substitute for a proper compiler validation suite (even though they cost many thousands of dollars commercial compiler writers often buy both companies products because they are good value for money as a testing resource {the Fortran 78 validation suite source gives some idea of how much work is actually involved). I would expect gcc to fail some of the tests but have no idea how many or serious the failures would be.
- Microsoft have said they don’t have plans to support C99 (it took a lot of prodding to get them interested in formally validating against C90).
- I think the llvm team are in the same position as gcc, but perhaps somebody at Apple has access to one or more of the commercial suites (I don’t know).
- EDG are into standard’s conformance and I would expect them to pass both suites.
The certificate is printed on high quality, slightly yellow paper; the template wording is in a subdued gray ink while the customer information is in a very bold black ink. I don’t know whether this is to make life difficult for counterfeiters, but I could not get any half decent photographs and the color scanner had to be switched to black&white.
Validation was good for one year and I saw no worthwhile benefit in paying BSI £5,000 to renew for another year. Few people knew about the one year rule and I did not enlighten them. In the Ada compiler market the one year rule was a major problem, but lets leave that for another time.

Estimating the reliability of compiler subcomponent
Compiler stress testing can be used for more than finding bugs in compilers, it can also be used to obtain information about the reliability of individual components of a compiler. A recent blog post by John Regehr, lead investigator for the Csmith project, covered a proposal to improve an often overlooked aspect of automated compiler stress testing (removing non-essential code from a failing test case so it is small enough to be acceptable in a bug report; attaching 500 lines of source to a report in a sure fire way for it to be ignored) triggered this post. I hope that John’s proposal is funded and it would be great if the researchers involved also received funding to investigate component reliability using the data they obtain.
One process for estimating the reliability of the components of a compiler, or any other program, is:
- divide the compiler into a set of subcomponents. These components might be a collection of source files obtained through cluster analysis of the source, obtained from a functional analysis of the implementation documents or some other means,
- count the number of times each component executes correctly and incorrectly (this requires associating bugs with components by tracing bug fixes to the changes they induce in source files; obtaining this information will consume the largest amount of the human powered work) while processing lots of source. The ratio of these two numbers, for a given component, is an estimate of the reliability of that component.
How important is one component to the overall reliability of the whole compiler? This question can be answered if the set of components is treated as a Markov chain and the component transition probabilities are obtained using runtime profiling (see Large Empirical Case Study of Architecture–based Software Reliability by Goševa-Popstojanova, Hamill and Perugupalli for a detailed discussion).
Reliability is a important factor in developers’ willingness to enable some optimizations. Information from a component reliability analysis could be used to support an option that only enabled optimization components having a reliability greater than a developer supplied value.
The one big threat to validity of this approach is that stress tests are not representative of typical code. One possibility is to profile the compiler processing lots of source (say of the order of a common Linux distribution) and merge the transition probabilities, probably weighted, to those obtained from stress tests.
Estimating the quality of a compiler implemented in mathematics
How can you tell if a language implementation done using mathematical methods lives up to the claims being made about it, without doing lots of work? Answers to the following questions should give you a good idea of the quality of the implementation, from a language specification perspective, at least for C.
- How long did it take you to write it? I have yet to see any full implementation of a major language done in less than a man year; just understanding and handling the semantics, plus writing the test cases will take this long. I would expect an answer of at least several man years
- Which professional validation suites have you tested the implementation against? Many man years of work have gone into the Perennial and PlumHall C validation suites and correctly processing either of them is a non-trivial task. The gcc test suite is too light-weight to count. The C Model Implementation passed both
- How many faults have you found in the C Standard that have been accepted by WG14 (DRs for C90 and C99)? Everybody I know who has created a full implementation of a C front end based on the text of the C Standard has found faults in the existing wording. Creating a high quality formal definition requires great attention to detail and it is to be expected that some ambiguities/inconsistencies will be found in the Standard. C Model Implementation project discoveries include these and these.
- How many ‘rules’ does the implementation contain? For the C Model Implementation (originally written in Pascal and then translated to C) every if-statement it contained was cross referenced to either a requirement in the C90 standard or to an internal documentation reference; there were 1,327 references to the Environment and Language clauses (200 of which were in the preprocessor and 187 involved syntax). My C99 book lists 2,043 sentences in the equivalent clauses, consistent with a 70% increase in page count over C90. The page count for C1X is around 10% greater than C99. So for a formal definition of C99 or C1X we are looking for at around 2,000 language specific ‘rules’ plus others associated with internal housekeeping functions.
- What percentage of the implementation is executed by test cases? How do you know code/mathematics works if it has not been tested? The front end of the C Model Implementation contains 6,900 basic blocks of which 87 are not executed by any test case (98.7% coverage); most of the unexecuted basic blocks require unusual error conditions to occur, e.g., disc full, and we eventually gave up trying to figure out whether a small number of them were dead code or just needed the right form of input (these days genetic programming could be used to help out and also to improve the quality of coverage to something like say MC/DC, but developing on a PC with a 16M hard disc does limit what can be done {the later arrival of a Sun 4 with 32M of RAM was mind blowing}).
Other suggested questions or numbers applicable to other languages most welcome. Some forms of language definition do not include a written specification, which makes any measurement of implementation conformance problematic.
Finding the ‘minimum’ faulty program
A few weeks ago I received an inquiry about running a course/workshop on compiler writing. This does not does not happen very often and it reminded me that many years ago the ACCU asked if I would run a mentored group on compiler writing, I was busy writing a book at the time. The inquiry got me thinking it would be fun to run a compiler writing mentored group over a 6-9 month period and I emailed the general ACCU reflector asking if anybody was interested in joining such a group (any reader wanting to join the group has to be a member of the ACCU).
Over the weekend I had a brainwave for a project, automatic compiler test generation coupled with a program source code minimizer (I need a better name for this bit). Automatic test generation sounds great in theory but in practice whittling down the source code of those programs that result in a fault being exhibited, to create a usable sized test case that is practical for debugging purposes can be a major effort. What is needed is a tool to automatically do the whittling, i.e., a test case minimizer.
A simple algorithm for whittling down the source of a large test program is to continually throw away that half/third/quarter of the code that is not needed for the fault to manifest itself. A compiler project that took as input source code, removed half/third/quarter of the code and generated output that could be compiled and executed is realistic. The input/reduce/output process could be repeated until the generated source was considered to have reached some minima. Ok, this will soak up some cpu time, but computers are cheap and people are expensive.
Where does the test source code come from? Easy, it is generated from the same yacc grammar that the compiler, written by the mentored group member, uses to parse its input. Fortunately such a generation tool is available and ready to use.
The beauty is using the same grammar to generate tests and parse input. This means there is no need to worry about which language subset to use initially and support for additional language syntax can be added incrementally.
Experience shows that automatically generated test programs quickly uncover faults in production compilers, even when working with language subsets. Compiler implementors are loath to spend time cutting down a large program to find the statement/expression where the fault lies, this project will produce a tool that does the job for them.
So to recap, the mentored group is going to write one or more automatic source code generators that will be used to stress test compilers written by other people (e.g., gcc and Microsoft). Group members will also write their own compiler that reads in this automatically generated source code, throws some of it away and writes out syntactically/semantically correct source code. Various scripts will be be written to glue this all together.
Group members can pick the language they want to work with. The initial subset could just include supports for integer types, if-statements and binary operators.
If you had trouble making any sense all this, don’t join the group.
Recent Comments