Archive
Fortran & Cobol in the USAF over the years 1955-1986
I recently discovered a new dataset from Rome’s golden age, going back to 1955. Who knew that in 1955 the US Air Force took delivery of 133,075 lines of Cobol? The plot below shows lines of code against year, broken down by major languages used.
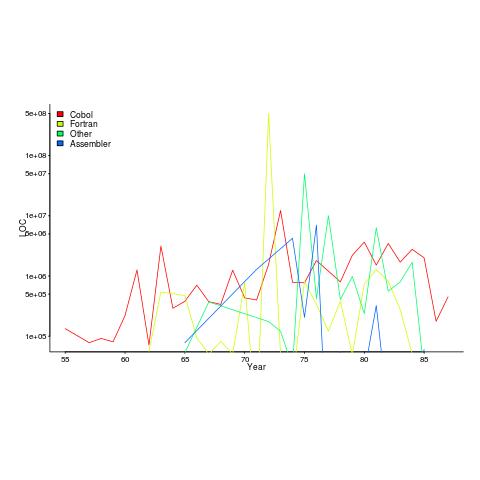
I got the data from the Master’s thesis of Captain NeSmith II (there is probably more software engineering data to be found in US Air Force officers’ Master’s thesis than all published academic papers before 2005). Captain NeSmith got his data from the Information Systems Designator (ISD) database maintained by the Standard Information Systems Center (SISC); the data does not include classified project and embedded systems. This database contained more data than appeared in the thesis, but I cannot find it anywhere.
Given the spiky nature of the data I’m guessing that LOC and development costs are counted in the year a project is delivered. Maintenance costs are through to financial year 1984.
The big question that jumps out of the data is “What project delivered 0.5 billion lines of Fortran in 1972?”
The LOC for Assemble suspiciously does not occur before 1965.
In the 1980s people were always talking about the billion+ lines of Cobol in use by the US Government. Over the 31 year span of this USAF data, 46 million lines of Cobol were delivered at a cost of $0.5 billion. Did another 50 arms of the government produce similar amounts of Cobol? Is the USAF under/over representative of Cobol?
The plot below shows yearly LOC against development cost, plus fitted regression lines.
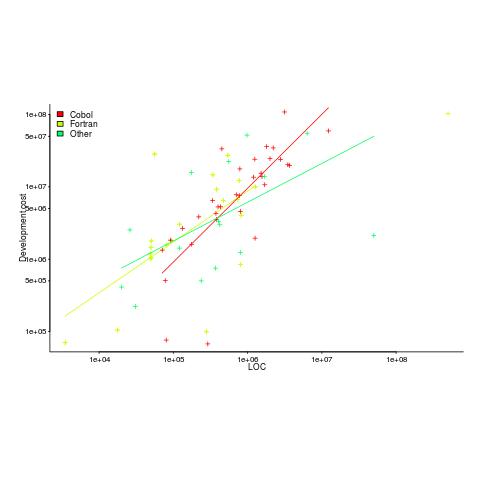
Using development cost as a proxy for effort, the coefficients of the fitted lines were close to those I fitted to Boehm’s embedded data (i.e., the exponents were lower than those listed by Boehm); Fortran 0.7, Cobol 1 and Other 0.5 (the huge Fortran outlier was excluded).
Adding Year to the regression model shows than Fortran development cost decreased by around 8% per year. Cobol may have been around 1% per year, depending on which model is chosen.
The maintenance costs can be plotted, but there is just too much uncertainty about them to say anything sensible (was inflation taken into account, how heavily used were the programs {more usage find more faults and demand for more features}, etc.).
NeSmith’s thesis contains a lot more data. The reproduction quality is not great, so the numbers have to be typed in. If you find any bugs in my data+code, please let me know and if you type in any of the other tables I would love a copy.
Actively maintained production compilers for middle-age languages
The owners of the Borland C++ compiler have stopped maintaining it. So we are now down to, by my counting, three four different production quality C++ compilers still being actively maintained (Visual C++ {the command line c1.exe, not the interactive IDE compiler}, GCC, LLVM and EDG); lots of companies repackage EDG and don’t talk about it.
How many production compilers for other middle-age languages are still being actively maintained?
Ada I think is now down to one (GNAT; I’m not sure of the status of what was the Intermetrics compiler).
Cobol has two+ (I’m not sure how many internal compilers IBM has, some of which are really Microfocus) that I know of (Microfocus and Fujitsu {was ACUCobol}).
Fortran probably needs more than one hand to count its compilers. Nothing like having large engineering applications using the languages features supported by your compiler to keep the maintenance fees rolling in.
C still has lots of compilers (a C validation suite vendor told me many years ago that they had over 150 customers). Embedded processors can be a very tough target for the general purpose algorithms used in GCC and LLVM, so vendors with hand crafted compilers can still eek out a living.
Perl has one (which I find surprising).
R has one, but like Cobol it is not a fashionable language in compiler writing circles. Over the last couple of years there have been a few ‘play’ implementations and rumors of people creating a new production quality implementation.
Lisp has one or millions, depending on how you view dialects or there could be a million people with a different view on the identity of the 1.
Snobol-4 still has one (yes, I am a fan of this language).
There are lots of languages which have not yet reached middle-age, so its too soon to start counting how many actively supported compilers they still have in production use.
2015 in the programming language standard’s world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the programming languages committee.
My suggestion that the Cobol 2014 standard may be the last revision of that language appears to be coming true; there has been a steep decline in membership of the US Cobol committee (this is where all the work is done, with the rest of the world joining this committee or rubber stamping what comes out of it), and nobody has expressed interest in being involved in new work items.
Fortran appears to be going strong, with a revised standard planned for 2017.
In October C++ are rectifying the fact that they have not meet in Hawaii for three years. In fairness I ought to point out that the Fortran committee, when hosted by INCITS/PL22.3, regularly hold meetings in Las Vegas (I’m told its because the hotel rooms are cheap; Nevada is where US underground atom bomb tests were located and lots of super-computers executing programs written in Fortran were involved, or perhaps readers can think of an alternative explanation that does not invoke secret government organizations).
I found out that PL/1 is still an ISO Standard.
Work on the C and Ada standards continues.
Prolog has a new convenor, Ulrich Neumerkel. There was a meeting during April in Dresden, Germany but no minutes have been published. Did anybody attend?
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard is almost 10 years behind the specification published by the organization who actually does the work. Some voices have expressed an interest in updating the ISO document. What does ISO’s version of the Linux Standard Base have to do with the committee responsible for programming languages?
Well, a long time ago in a galaxy far away, or the late 1980s in London, some people decided to set up a committee that specified O/S related library functions callable from C programs. SC22, programming languages, was the existing ISO committee having the closest fit with this new working group; initially it produced a specification that went under the name POSIX. Jump forward 15 years and Linux was the big POSIX success story (ok, the Linux people might see things differently) and dare I suggest that one of the motivations for creating ISO/IEC 23360-1:2006 might have been to bask in the reflected success of Linux. I understand the motivation of people involved in the standard’s process for wanting to published an update that reflects the current state of play (seriously out of date standards degrade the brand), but I don’t see why the Linux Foundation would be interested in going through the hassle of making this happen (unless they are having a mid-life crisis and are seeking approval of their work from an authority figure). Watch this blog for a 2016 status update.
Cobol 2014, perhaps the definitive final version of the language…
Look what arrived in the post this morning, a complementary copy of the new Cobol Standard (the CD on top of a paper copy of the 1985 standard).

In the good old days, before the Internet, members of IST/5 received a complementary copy of every new language standard in comforting dead tree form (a standard does not feel like a standard until it is weighed in the hand; pdfs are so lightweight); these days we get complementary access to pdfs. I suspect that this is not a change of policy at British Standards, but more likely an excessive print run that they need to dispose of to free up some shelf space. But it was nice of them to think of us workers rather than binning the CDs (my only contribution to Cobol 2014 was to agree with whatever the convener of the committee proposed with regard to Cobol).
So what does the new 955-page standard have to say for itself?
“COBOL began as a business programming language, but its present use has spread well beyond that to a general purpose programming language. Significant enhancements in this International Standard include:
— Dynamic-capacity tables
— Dynamic-length elementary items
— Enhanced locale support in functions
— Function pointers
— Increased size limit on alphanumeric, boolean, and national literals
— Parametric polymorphism (also known as method overloading)
— Structured constants
— Support for industry-standard arithmetic rules
— Support for industry-standard date and time formats
— Support for industry-standard floating-point formats
— Support for multiple rounding options”
I guess those working with Cobol will find these useful, but I don’t see them being enough to attract new users from other languages.
I have heard tentative suggestions of the next revision appearing in the 2020s, but with membership of the Cobol committee dying out (literally in some cases and through retirement in others) perhaps this 2014 publication is the definitive final version of Cobol.
Why is Cobol still popular in Japan?
Rummaging around the web for empirical software engineering data, I found a survey of programming language usage in Japan. This survey (based on 505 projects in 24 companies) has Cobol in the number two slot for 2012, a bit higher than I would have expected (it very rarely appears at all in US/UK ‘popularity’ lists):
Language Projects Java 822 28.2% COBOL 464 15.9% VB 371 12.7% C 326 11.2% Other languages 208 7.1% C++ 189 6.5% Visual Basic.NET 136 4.7% Visual C++ 105 3.6% C# 101 3.5% PL/SQL 57 2.0% Pro*C 23 0.8% Excel(VBA) 18 0.6% Developer2000 17 0.6% ABAP 15 0.5% HTML 14 0.5% Delphi 11 0.4% PL/I 10 0.3% Perl 10 0.3% PowerBuilder 7 0.2% Shell 7 0.2% XML 6 0.2%
A quick overview of Cobol for those readers who have never encountered it.
Cobol is a domain specific language ideally suited for business data processing in the 1960/70/80/90s. During this period computer memory was often measured in kilobytes, data came in an unbelievably wide range of different formats, operations on data mostly involved sorting and basic arithmetic, and output data format was/is very important. By “unbelievably wide range” think of lots of point-of-sale vendors deciding how their devices would write data to punch cards/paper tape/magnetic tape, just handling the different encodings that have been used for the plus/minus sign can make the head spin; combine the requirement that programs handle different data formats with tiny computer memory capacity, and you get data structure overlays that make C programmers look like rank amateurs, all the real action in Cobol programs occurs in the DATA DIVISION.
So where are we today? Companies use computers to solve a wider range of problems don’t they (so even if Cobol usage stayed the same its percentage usage should be low)? If point-of-sale terminals still produce a wide range of weird and wonderful data formats, isn’t it easy enough to write the appropriate libraries to convert (and we have much more storage these days)?
Why might Cobol still be so popular in Japan (and perhaps elsewhere, if anybody over 25 was included in the survey)? Some ideas:
- Cobol is still the best language to use for business data processing,
- the sample is not representative of the Japanese software development industry. As a government body perhaps the Information-Technology Promotion Agency primarily deals with large well established companies; the data came from a relatively small number of companies (i.e., 24),
- the Japanese are known for being conservative and maintaining traditions. Change is almost considered a necessity here in the West, this has led to the use of way too many programming languages in industry (I have previously written about what a mistake it is to invent a new language).
The oldest compiler still in production use is?
What is the oldest compiler still in production use?
A CHILL compiler I worked on a long time ago has probably been in production use for 30 years now.
Code gets added and deleted from production software all the time, how might ‘oldest’ be measured? I propose using the mean age of every line of code, including comments, where the age of a line is reset to zero when it is modified in any way (excluding code formatting).
The following are two environmental factors that enable a production compiler to get very old:
- a relatively obscure language: popular languages have new compilers written for them (compiler death through competition) or have new features added to them (requiring new lines of code which could even displace ‘aged’ code),
- a very long-lived application associated with the language: obscure languages tend to be very quickly abandoned in the dust of history unless they have a symbiotic relationship with an important application,
- very long-lived host hardware and target processor: changing either often requires substantial new code or a move to a newer compiler. For ancient the only candidate is the IBM 370 and just really old the Intel 80×80, Zilog Z80.
Virtual machines provide a mechanism to be host hardware independent. The Micro Focus Cobol had a rewrite in the early 1990s (it might have had others since) and I don’t think UCSD Pascal I.5 is still used for production work.
Fortran is an evolving language and very popular in some application domains. I doubt there are any (mean age) old Fortran compilers in production use.
Why do I put forward the ITT (in its International Telephone & Telegraph days, these bits subsequently sold off) CHILL compiler as potentially the oldest compiler currently in production use?
- Obscure language and long-lived application (telephone switching software),
- host hardware was IBM 370 family, target processor Intel 8086 (later updated to support 80386),
- large development team and very small support team (i.e., lots of old code and small changes over the years),
- single customer, i.e., no push to add features to attract new customers or keep existing ones.
My last conversation with anybody associated with this compiler was a chance meeting over 10 years ago, so I might be a bit out of date.
30+ year old source code for compilers can be downloaded (e.g., the original PDP 11 C compiler) but these compilers are not in production use (forgotten about military installations anybody?)
I welcome other proposals for the oldest compiler currently in production use.
O Cobol, Cobol! wherefore art thou Cobol?
Programming language popularity has been in the news again and as always Cobol is nowhere to be seen in the rankings. Even back in the day, when people in the know generally considered Cobol to be the most widely used language it often failed to appear, or appeared very low down, in language rankings. I think Cobol’s unrepresentative rankings occur because users of Cobol are assumed to hang out in the same places as users of other programming languages. The letters bo in the name is the clue, business oriented people are not usually interested in technical stuff and tend not to read the magazines (and these days web sites) that users of the other popular languages read.
Cobol is very business domain specific and does not contain functionality that makes it a reasonable choice for writing applications in other domains (it is possible to write a compiler in Cobol, for instance the Micro Focus compiler is written in Cobol). It has very sophisticated languages constructs for handling data having the most convoluted formats imaginable, essential in the business world which has to process data whose format has evolved over the years into a tangled mess (developers have to deal with spaghetti code, business has to deal with spaghetti data formats). Cobol’s control flow and code structuring facilities are primitive (all variables are global and the perform statement is very similar to the gosub statement found in Basic’s that are line number based) because business data processing tends to be relatively simple and programs to handle them are generally small (the large Cobol programs of legend are invariably made up of lots of small programs run in series with complicated data format dependencies between them).
I started to realise just how different Cobol is when working on my first Cobol code generator (yes it was written in Cobol). If a processor has lots of registers it is usually worthwhile to dedicate one to holding the value zero (of the 32 registers supported by most RISC processors, often only 31 can hold different values, one is dedicated to returning zero when read from and ignores any value written to it), in the case of Cobol it is considered worthwhile to dedicate a register to hold 0x20202020 (four space characters) rather than zero.
Is Cobol still the most widely used language today? No, I don’t think so. Business people love spreadsheets which means developers have switched to writing pre/post data format processing code, previously in Cobol, in Visual Basic (to convert input data into a form accepted by the spreadsheet and then print the results of the spreadsheet calculations in a presentable format); this Visual Basic source can often have a Cobol-like feel to it. This spreadsheet usage also resulted in the comma separated list becoming a widely used format for data representation, eroding Cobol’s unique selling point of sophisticated input/output data format processing.
What does language popularity mean? Does using a language you don’t like count towards it being popular? There are several languages I like and very rarely get to use, does this mean I don’t get to contribute to their popularity?
In these tough financial times the number of job adverts requiring knowledge of a specified language is probably of more interest than number of posts to web sites. One job search site lists 3,032 Cobol jobs and counting job ad hits for the top languages listed in a recent popularity poll puts Cobol at the bottom end of the cluster of highest ranked languages.
On mainframes I think Cobol is likely to still be No. 1; it is probably impossible to replace the dominant language in a niche market.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
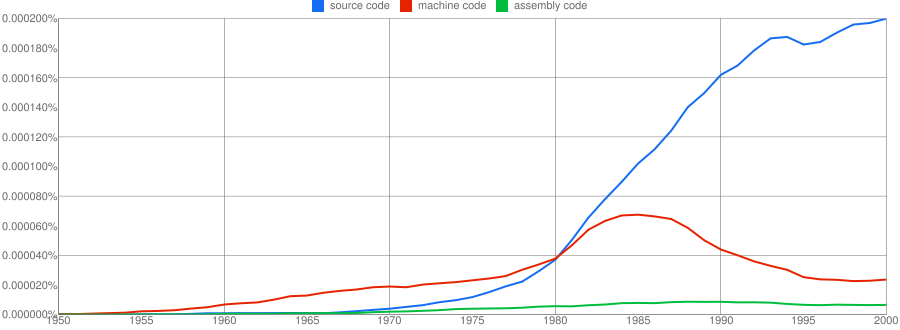
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
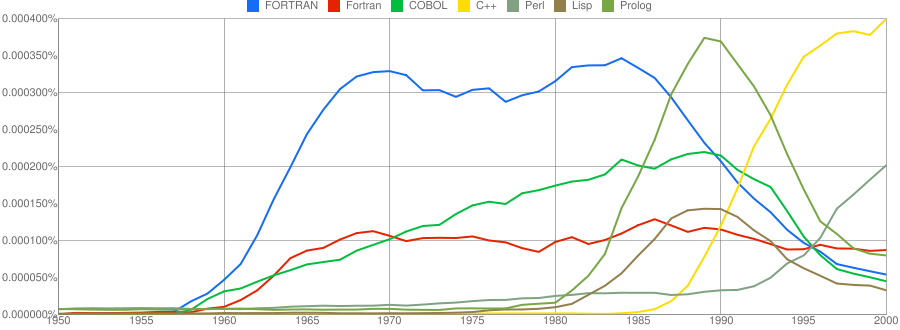
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
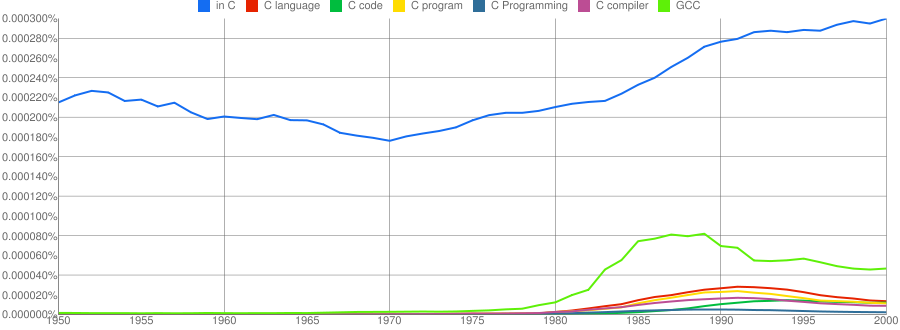
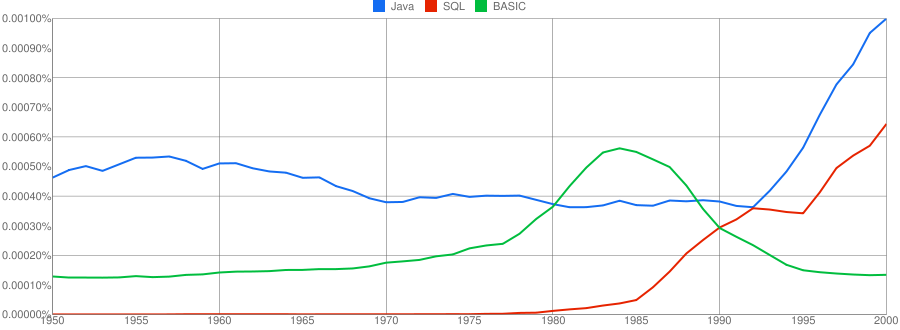
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
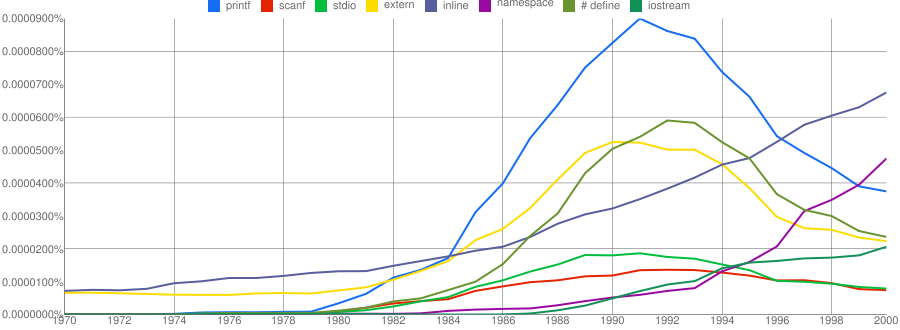
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Register vs. stack based VMs
Traditionally the virtual machine architecture of choice has been the stack machine; benefits include simplicity of VM implementation, ease of writing a compiler back-end (most VMs are originally designed to host a single language) and code density (i.e., executables for stack architectures are invariably smaller than executables for register architectures).
For a stack architecture to be an effective solution, two conditions need to be met:
- The generated code has to ensure that the top of stack is kept in sync with where the next instruction expects it to be. For instance, on its return a function cannot leave stuff lying around on the stack like it can leave values in registers (whose contents can simply be overwritten).
- Instruction execution needs to be generally free of state, so an add-two-integers instruction should not have to consult some state variable to find out the size of integers being added. When the value of such state variables have to be saved and restored around function calls, they effectively become VM registers.
Cobol is one language where it makes more sense to use a register based VM. I wrote one and designed two machine code generators for the MicroFocus Cobol VM and always find it difficult to explain to people what a very different kind of beast it is compared to the VMs usually encountered.
Parrot, the VM designed as the target for compiled PERL, is register based. A choice driven, I suspect, by the difficulty of ensuring a consistent top-of-stack and perhaps the dynamic typing of the language.
On register based cpus with 64k of storage, the code density benefits of a stack based VM are usually sufficient to cancel out the storage overhead of the VM interpreter and support a more feature rich application (provided speed of execution is not crucial).
If storage capacity is not a significant issue and a VM has to be used, what are the runtime performance differences between a register and stack based VM? Answering this question requires compiling and executing the same set of applications for the two kinds of VM. Something that until 2001 nobody had done, or at least not published the results.
A comparison of the Java (stack based) VM with a register VM (The Case for Virtual Register Machines) found that while the stack based code was more compact, fewer instructions needed to be executed on the register based VM.
Most VM instructions are very simple and take relatively little time to execute. When hosted on a pipelined processor the main execution time overhead of a VM is the instruction dispatch (Optimizing Indirect Branch Prediction Accuracy in Virtual Machine Interpreters) and reducing the number of VM instructions executed, even if they are larger and more complicated, can produce a worthwhile performance improvement.
Google has chosen a register based VM for its Android platform. While licensing issues may have been a consideration, there are a number of technical advantages to this decision:
- A register VM is likely to have an intrinsic performance advantage over a stack VM when hosted on a pipelined processor.
- Byte code verification is likely to be faster on a register VM (i.e., faster startup times) because stack height integrity checks will be greatly simplified.
- A register VM will be more forgiving of incorrect code (in the VM, generated by the compiler, code corrupted during program transmission or storage attacked by malware) than a stack VM.
Recent Comments