Archive
Optimal sizing of a product backlog
Developers working on the implementation of a software system will have a list of work that needs to be done, a to-do list, known as the product backlog in Agile.
The Agile development process differs from the Waterfall process in that the list of work items is intentionally incomplete when coding starts (discovery of new work items is an integral part of the Agile process). In a Waterfall process, it is intended that all work items are known before coding starts (as work progresses, new items are invariably discovered).
Complaints are sometimes expressed about the size of a team’s backlog, measured in number of items waiting to be implemented. Are these complaints just grumblings about the amount of work outstanding, or is there an economic cost that increases with the size of the backlog?
If the number of items in the backlog is too low, developers may be left twiddling their expensive thumbs because they have run out of work items to implement.
A parallel is sometimes drawn between items waiting to be implemented in a product backlog and hardware items in a manufacturer’s store waiting to be checked-out for the production line. Hardware occupies space on a shelf, a cost in that the manufacturer has to pay for the building to hold it; another cost is the interest on the money spent to purchase the items sitting in the store.
For over 100 years, people have been analyzing the problem of the optimum number of stock items to order, and at what stock level to place an order. The economic order quantity gives the optimum number of items to reorder,  (the derivation assumes that the average quantity in stock is
(the derivation assumes that the average quantity in stock is  ), it is given by:
), it is given by:
 , where
, where  is the quantity consumed per year,
is the quantity consumed per year,  is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),
is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),  is the annual holding cost per item.
is the annual holding cost per item.
What is the likely range of these values for software?
- is around 1,000 per year for a team of ten’ish people working on multiple (related) projects; based on one dataset,
- is the cost associated with the time taken to gather the requirements, i.e., the items to add to the backlog. If we assume that the time taken to gather an item is less than the time taken to implement it (the estimated time taken to implement varies from hours to days), then the average should be less than an hour or two,
- : While the cost of a post-it note on a board, or an entry in an online issue tracking system, is effectively zero, there is the time cost of deciding which backlog items should be implemented next, or added to the next Sprint.
If the backlog starts with
 items, and it takes
items, and it takes  seconds to decide whether a given item should be implemented next, and
seconds to decide whether a given item should be implemented next, and  is the fraction of items scanned before one is selected: the average decision time per item is:
is the fraction of items scanned before one is selected: the average decision time per item is: /2}*t") seconds. For example, if
seconds. For example, if  , pulling some numbers out of the air,
, pulling some numbers out of the air,  , and
, and  , then
, then  , or 5.4 minutes.
, or 5.4 minutes.The Scrum approach of selecting a subset of backlog items to completely implement in a Sprint has a much lower overhead than the one-at-a-time approach.
If we assume that  , then
, then  .
.
An ‘order’ for 45 work items might make sense when dealing with clients who have formal processes in place and are not able to be as proactive as an Agile developer might like, e.g., meetings have to be scheduled in advance, with minutes circulated for agreement.
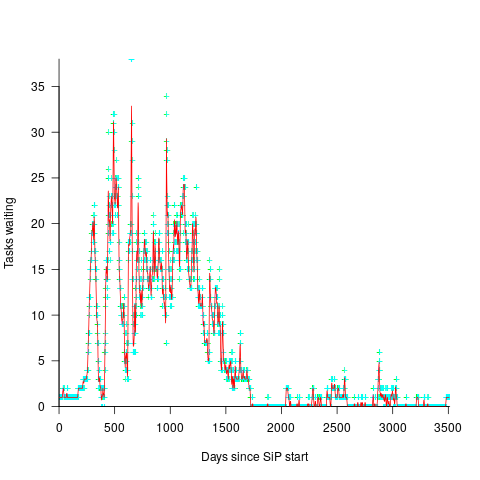
In a more informal environment, with close client contacts, work items are more likely to trickle in or appear in small batches. The SiP dataset came from such an environment. The plot below shows the number of tasks in the backlog of the SiP dataset, for each day (blue/green) and seven-day rolling average (red) (code+data):
Task backlog waiting times are power laws
Once it has been agreed to implement new functionality, how long do the associated tasks have to wait in the to-do queue?
An analysis of the SiP task data finds that waiting time has a power law distribution, i.e.,  , where
, where  is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
Queueing theory analyses the properties of systems involving the arrival of tasks, one or more queues, and limited implementation resources.
A basic result of queueing theory is that task waiting time has an exponential distribution, i.e., not a power law. What software task implementation behavior is sufficiently different from basic queueing theory to cause its waiting time to have a power law?
As always, my first line of attack was to find data from other domains, hopefully with an accompanying analysis modelling the behavior. It’s possible that my two samples are just way outside the norm.
Eventually I found an analysis of the letter writing response time of Darwin, Einstein and Freud (my email asking for the data has not yet received a reply). Somebody writes to a famous scientist (the scientist has to be famous enough for people to want to create a collection of their papers and letters), the scientist decides to add this letter to the pile (i.e., queue) of letters to reply to, eventually a reply is written. What is the distribution of waiting times for replies? Yes, it’s a power law, but with an exponent of -1.5, rather than -1.
The change made to the basic queueing model is to assign priorities to tasks, and then choose the task with the highest priority (rather than a random task, or the one that has been waiting the longest). Provided the queue never becomes empty (i.e., there are always waiting tasks), the waiting time is a power law with exponent -1.5; this behavior is independent of queue length and distribution of priorities (simulations confirm this behavior).
However, the exponent for my software data, and other data, is not -1.5, it is -1. A 2008 paper by Albert-László Barabási (detailed analysis) showed how a modification to the task selection process produces the desired exponent of -1. Each of the tasks currently in the queue is assigned a probability of selection, this probability is proportional to the priority of the corresponding task (i.e., the sum of the priorities/probabilities of all the tasks in the queue is assumed to be constant); task selection is weighted by this probability.
So we have a queueing model whose task waiting time is a power law with an exponent of -1. How well does this model map to software task selection behavior?
One apparent difference between the queueing model and waiting software tasks is that software tasks are assigned to a small number of priorities (e.g., Critical, Major, Minor), while each task in the model queue has a unique priority (otherwise a tie-break rule would have to be specified). In practice, I think that the developers involved do assign unique priorities to tasks.
Why wouldn’t a developer simply select what they consider to be the highest priority task to work on next?
Perhaps each developer does select what they consider to be the highest priority task, but different developers have different opinions about which task has the highest priority. The priority assigned to a task by different developers will have some probability distribution. If task priority assignment by developers is correlated, then the behavior is effectively the same as the queueing model, i.e., the probability component is supplied by different developers having different opinions and the correlation provides a clustering of priorities assigned to each task (i.e., not a uniform distribution).
If this mapping is correct, the task waiting time for a system implemented by one developer should have a power law exponent of -1.5, just like letter writing data.
The number of sprints that a story is assigned to, before being completely implemented, is a power law whose exponent varies around -3. An explanation of this behavior based on priority queues looks possible; we shall see…
The queueing models discussed above are a subset of the field known as bursty dynamics; see the review paper Bursty Human Dynamics for human behavior related aspects.
Recent Comments