What is the error rate for published mathematical proofs?
Mathematical proofs are sometimes cited as the gold standard against which software quality should be compared. At school we rarely get to hear about proofs that turn out to be wrong and are inculcated with the prevailing wisdom that all mathematical proofs are correct.
There are many technical and social issues involved in believing a published proof and well known established mathematicians have no trouble pointing out that “… it is impossible to write out a very long and complicated argument without error, …”
Examples of incorrect published proofs include Wiles’ first proof of Fermat’s Last Theorem and an serious error found in a proof of a message signing scheme.
A question on mathoverflow contains a list of rather interesting false proofs.
Then, of course, there are always those papers that appear in journals that get written about more frequently on Retraction Watch than others.
What is the error rate for published mathematical proofs? I have not been able to find any collection of mathematical proof error data.
Several authors have expressed the view that because there so many diverse mathematical topics being studied these days there are very few domain experts available to check proofs. A complicated proof of a not particularly interesting result is unlikely to attract the attention needed to check it thoroughly. It should come as no surprise that the number of known errors in such proofs is equal to the number of known errors in programs that have never been executed.
Proofs are different from programs in that one error can be enough to ‘kill-off’ a proof, while a program can contain many errors and still be useful. Do errors in programs get talked about more than errors in proofs? I rarely get to socialize with working mathematicians and so cannot make any judgment call on this question.
Every non-trivial program is likely to contain many errors; can the same be said for long mathematical proofs? Are many of these errors as trivial (in the sense that they are easily fixed) as errors in programs?
One commonly used error rate for programs is errors per line of code; how should the rate be expressed for proofs? Errors per page, per line, per definition?
Lots of questions and I’m hoping one of my well informed readers will be able to provide some answers or at least cite a reference that does.
Testing compiler semantics with minimal manual input
The 2011 revision of the C++ Standard added lots of new constructs to the language and in the past few months both the GCC and LLVM teams have been claiming that the next release of their C++ compilers will fully support the 2011 Standard. How true are these claims? One way of answering this question is to run both compilers over an extensive test suite. There are commercial C++ compiler test suites available, but I don’t have access to them and if I did the license agreement would probably not allow me to talk in detail about the results. Writing compiler tests cases requires a very detailed knowledge of the language; I have done it often enough in previous lives to know that more than a year or so of my time would be needed just to get my head around the semantics of the new C++ features, before I could produce anything half decent.
Is there a way of automating the generation of test cases for language semantics? Automated statement/expression generation is very effective at finding problems with optimizers and code generators. Can this technique be applied to check the semantic requirements of a language?
Having concocted various elaborate schemes over the years I recently realised that life would be a lot simpler if I was willing to accept a very high percentage of erroneous test programs (the better manually written test suites usually contain around as many test cases that intended to fail to compile as tests that pass, i.e., intended to compile correctly; the not so good ones have few failing tests).
If two or more compilers are available the behavior of each of them on a given source file can be compared: differential testing. If both compile a file or fail to compile it, they may both be right or wrong; either way this shared behavior is not interesting, but is likely to be the common case. The interesting case is if one compiles a file and the other fails to compile it; this could be a fault in one of them, or one of those cases where the Standard permits compilers to do their own thing.
I hereby jump to the conclusion that behavior differences is a good proxy for compiler conformance to the language Standard (actually developers are often more interested in all compilers they are likely to use having the same external behavior than conforming to a Standard).
Lets implement this (source code here)!
First we need to generate lots of test cases. The process I used is based on program templates, such as the following (lines starting with ! are places where various constructs can be inserted):
int v; ! declare_id 2 int main(void) { ! declare_id 2 ! ref_id 2 } |
the identifier after the ! is the name of a file containing lines to be inserted at the given location (the number after the identifier is the maximum number of lines that can be inserted at that point; default 1 if no number given). The following is example file contents for the above template:
declare_id
int i; enum {i, j}; enum i {x, y}; struct i {int f;}; typedef int i; |
ref_id
enum i ev_i; struct i sv_i; typedef i tv_i; v=i; |
It is then simply a matter of permuting through all of the possible combinations of lines that can be inserted in the program template, creating a stand alone file for each possibility (18,000 of them in the above example); I used the Python Natural Language Toolkit to do the heavy lifting.
A shell script compiles each source file and compares the compiler exit codes. For the above example there were 16,366 failures, 1,634 passes and no differences (this example contains well established C constructs and any difference would have been surprising).
Next, a feature new in C++11, lambda functions!
Here is the template used:
! declare_xy 2 int main(void) { ! declare_xy 2 auto foo_bar = ! define_lambda ; return 0; } |
I cut and pasted some examples from the Standard to create the following optional lines:
define_lambda
[](float a, float b) { return a + b; } [=](float a, float b) { return a + b; } [=,x](float a, float b) { return a + b; } [y](float a, float b) { return a + b; } [=]()->int { return operator()(this->x + y); } [&, i]{ } [=] { decltype(x) y1; decltype((x)) y2 = y1; decltype(y) r1 = y1; decltype((y)) r2 = y2; } |
which generated 6,300 source files of which 5,865 failed, 396 passed and 39 were treated differently by the compilers (g++ version 4.7.2, clang version 3.3).
How should the percentages be calculated? If we take the human written numbers for well written test suites containing (roughly) equal numbers of pass/fail tests, then we have around 800 tests of which (say) 40 gave different behavior, giving us a 5% fault rate. Do we share that 5% equally between both compilers or assign 3% for both being wrong and 1% for each being uniquely wrong?
Submitting a bug report to both compiler teams pointing out that their behavior is different from the other’s is a sure fire way to make myself unpopular. Any suggestions for how to resolve this issue, that does not involve me having to study the tiresomely long and convoluted C++ Standard, welcome.
Ways of obtaining empirical data in software engineering
For as long as I can remember I have been a collector of empirical data. Writing a book that involves analysis of empirical lots of data has added some focus to my previous scatter gun approach. I have been using three methods to obtain data relating to a recently read paper+one other approach:
- Download from researchers website,
- Emailing the author requesting a copy of the data,
- Reverse engineering numbers from the original paper (using tools like WebPlotDigitizer).
- Roll my sleeves up and do the experiment, write the extraction tool or convince a company to make its data available.
A sea change in attitudes to making data available seems to be underway. Until recently it was rare to find a researcher who provided a link for downloading data; in the last 12 months there has been a noticeable increase in the number of researchers making data, associated with a paper, available for download. I hope this increase continues and making data freely available becomes the accepted norm.
I regularly (once or twice a week) email the authors of a paper asking if I can have a copy of their data, typical responses include:
- Yes, here it is,
- Yes, but you cannot share it with anybody else (i.e., everybody has to get it from the original author). I have said “Thanks, but no thanks” in these cases since I make all the data I use freely available for download,
- I no longer have a copy of the data (changed jobs, lost in a computer crash, etc). In one case an established repository at a university lost funding and has gone dark.
- Data is confidential,
- Plan to write more papers based on the data, will release it when done (obtaining good data can be very time consuming and I can appreciate researchers wanting to maximize their return on investment),
- No response.
I have run a few experiments and have been luck enough to obtain data from one company.
When analysing data the most common ‘mistake’ I encounter is researchers failing to get the most out of the data they have. An example of this is two researchers who made some structural changes to the way a Java library worked and then ran a thorough before/after benchmark to investigate the impact; their statistical analysis consisted of reducing the extensive data down to mean+variance and comparing these across before/after (I built a regression model that makes a much stronger case for their claims).
Of course the usual incorrect use of statistical techniques does occur, but I have not spotted anything major. However, one study found: Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results, based on 49 papers published in two major psychology journals. Since I am concentrating on papers where the data is available I am probably painting an overly rosy picture of not getting things wrong.
As always, if anybody knows of ways of obtaining data that I have not mentioned (e.g., a twitter account to follow) do please let me know.
Programming using genetic algorithms: isn’t that what humans already do ;-)
Some time ago I wrote about the use of genetic programming to fix faults in software (i.e., insertion/deletion of random code fragments into an existing program). Earlier this week I was at a lively workshop, Genetic Programming for Software Engineering, with some of the very active researchers in this new subfield.
The genetic algorithm works by having a population of different programs, selecting X% of the best (as measured by some fitness function), making random mutations to those chosen and/or combining bits of programs with other programs; these modified programs are fed back to the fitness function and the whole process iterates until an acceptable solution is found (or a maximum iteration limit is reached).
There are lots of options to tweak; the fitness function gets to decide who has children and is obviously very important, but it can only work with what get generated by the genetic mutations.
The idea I was promoting, to anybody unfortunate enough to be standing in front of me, was that the pattern of usage seen in human written code provides lots of very useful information for improving the performance of genetic algorithms in finding programs having the desired characteristics.
I think that the pattern of usage seen in human written code is driven by the requirements of the problems being solved and regular occurrence of the same patterns is an indication of the regularity with which the same requirements need to be met. As a representation of commonly occurring requirements these patterns are pre-tuned templates for genetic mutation and information to help fitness functions make life/death decisions (i.e., doesn’t look human enough, die!)
There is some noise in existing patterns of code usage, generated by random developer habits and larger fluctuations caused by many developers following the style in some popular book. I don’t have a good handle on estimating the signal to noise ratio.
There has been some work comparing the human maintainability of patches that have been written by genetic algorithms/humans. One of the driving forces behind this work is the expectation that the final patch will still be controlled by humans; having a patch look human-written like is thought to increase the likelihood of it being ‘accepted’ by developers.
Genetic algorithms are also used to improve the runtime performance of programs. Bill Langdon reported that the authors of a program ‘he’ had speeded up by a factor of 70 had not responded to his emails. This may be a case of the authors not knowing how to handle something somewhat off the beaten track; it took a while for Linux developers to start responding to batches of fault reports generated as part of software analysis projects by academic research groups.
One area where human-like might not always be desirable is test case generation. It is easy to find faults in compilers by generating random source code (the syntax/semantics of the randomness follows the rules of the language standard). This approach results in an unmanageable number of fault. Is it worth fixing a fault generated by code that looks like it would never be written by a person? Perhaps the generator should stick to producing test cases that at least look like the code might be written by a person.
Single-quote as a digit separator soon to be in C++
At the C++ Standard’s meeting in Chicago last week agreement was finally reached on what somebody in the language standards world referred to as one of the longest bike-shed controversies; the C++14 draft that goes out for voting real-soon-now will include support for single-quotation-mark as a digit separator. Assuming the draft makes it through ISO voting you could soon be writing (Compiler support assumed) 32'767 and 0.000'001 and even 1'2'3'4'5'6'7'8'9 if you so fancied, in your conforming C++ programs.
Why use single-quote? Wouldn’t underscore have been better? This issue has been on the go since 2007 and if you feel really strongly about it the next bike-shed C++ Standard’s meeting is in Issaquah, WA at the start of next year.
Changing the lexical grammar of a language is fraught with danger; will there be a change in the behavior of existing code? If the answer is Yes, then the next question is how many people will be affected and how badly? Let’s investigate; here are the lexical details of the proposed change:
pp-number: digit . digit pp-number digit pp-number ' digit pp-number ' nondigit pp-number identifier-nondigit pp-number e sign pp-number E sign pp-number . |
Ideally the change of behavior should cause the compiler to generate a diagnostic, when code containing it is encountered, so the developer gets to see the problem and do something about it. The following conforming C++ code will upset a C++14 compiler (when I write C++ I mean the C++ Standard as it exists in 2013, i.e., what was called C++11 before it was ratified):
#define M(x) #x // stringize the macro argument char *p=M(1'2,3'4); |
At the moment the call to the macro M contains one argument, the sequence of three tokens {1}, {'2,3'} and {4} (the usual convention is to bracket the characters making up one token with matching curly braces).
In C++14 the call to M will contain the two arguments {1'2} and {3,4}. conforming compiler is required to complain when the number of arguments to a macro invocation don’t match the definition…. Unless the macro is defined to accept a variable number of arguments:
#define M(x, ...) __VA_ARGS__ int x[2] = { M(1'2,3'4) }; // C++11: int x[2] = {}; // C++14: int x[2] = { 3'4 }; |
This is the worst kind of change in behavior, known as a silent change, the existing code compiles without complaint but has different behavior.
How much existing code contains either of these constructs? I suspect very very little human written code, maybe even none. This is the sort of stuff that is more likely to be produced by automatic code generators. But how much more likely? I have no idea.
How much benefit does the new feature provide? It certainly looks useful, but coming up with a number for the benefit is hard. I guess it has the potential to shave a fraction of a second off of the attention a developer has to pay when reading code, after they have invested in learning about the construct (which is lots of seconds). Multiplied over many developers and not that many instances (the majority of numeric literals contain a single digit), we could be talking a man year or two per year of worldwide development effort?
All of the examples I have seen require the ‘assistance’ of macros, here is another (courtesy of Jeff Snyer):
#define M(x) A ## x #define A0xb int operator "" _de(char); int x = M(0xb'c'_de); |
Are there any examples of a silent change that don’t involve the preprocessor?
How many ways of programming the same specification?
How many different ways are there of writing a program to implement a given specification? Non-trivial specifications probably have an enormous number of possible programming solutions. What about really simple specifications, say something based on the 3n+1 problem (write a programs that takes a list of integers and outputs their ‘3n+1’ length; ‘3n+1’ length algorithm: for integer  , if is even divide it by
, if is even divide it by  and assign the result to , otherwise is odd, multiply it by
and assign the result to , otherwise is odd, multiply it by  and add
and add  to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
I can think of a dozen or so (slightly) different ways that I might write a program to solve this problem. If I really had to I could probably come up with a few hundred different solutions, but I think the source code of these programs would not look like something I would normally write. If I was to run a competition how many different answers might I get? If you twisted my arm I might have said 500. What do you think?
Meine van der Meulen studied the N-version programing for his PhD thesis (N groups independently write a program to the same specification, compare the output of the N programs and select the ‘best’ answer; cannot find a copy of the thesis online). This was empirical work and van der Meulen posted the above 3n+1 problem to a programming competition website and used the 95,497 submitted solutions for his analysis; he also kindly sent me a copy of the solutions (11,674 solutions were written in Pascal, the rest were in C).
Not all the solutions correctly solve the problem. I ignored this ‘detail’. There are also many duplicates (as in identical source code).
I am interested in differently coded solutions. I defined different as the sequence of operators/punctuators making up the program being different (or at least having a different MD5 checksum), so identifiers and comments are ignored. Should permutations in the order of independent adjacent statements really be counted as different? For the sack of keeping my life simple they current are. This definition of differently coded reduces the original 63,823 C programs down to 6,301. Wow, how are 6k+ different programs possible?
The original specification did not mention performance, but lots of developers did all sorts of weird and wonderful stuff to improve runtime performance. The most common optimization technique used (apart from some inventive ways of checking for odd/even) was to cache previous answers along with the solution for all the intermediate steps that were passed through on the way to 1 (the path from the starting value to 1 is very erratic and sometimes goes through values greater than the starting value) and check this cache to see whether it contains the current value of.
A common measure of program size is lines of code. What is the size distribution, in LOC, for these 6,301 programs? One program has been labeled an outlier and excluded from the analysis (most of its 8,345 lines were taken up with initializing a data structure with precomputed solutions).
The following plots lines of code against the number of programs containing that many lines (download code and data).
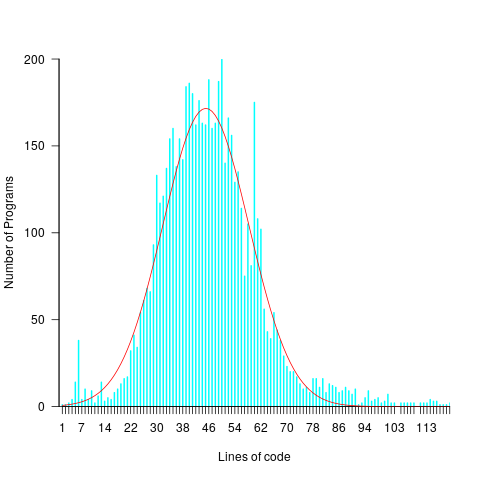
The mean program length is 46.3 lines, standard deviations 15.4. The red curve is a Normal distribution whose mean/sd has been tweaked to give a better visual fit (a Shapiro-Wilk test dispels any hope tht the distribution might be Normal). There is no reason to think that the data will be fitted by any known distribution and I’m not going to overfit on one data-point. If pushed I will wave my arms and describe the distribution as Normalish with added spikes and a fat right tail.
That spike around 60 lines is interesting. Is this group of solutions all doing the same thing but with different statement orderings? I have previously written about how gcc/llvm do a good job of turning the core of the algorithm into the same machine code. Perhaps a future version of these compilers will be able to tell us whether the programs clumping around 60 LOC are doing the same thing.
Software engineering: A great discipline for an academic fraudster
I am a sporadic reader of In the Pipeline, a blog covering drug discovery and the pharma industry, subjects about which I have no real interest but the author is a no nonsense guy whose writing I enjoy reading. A topic that regularly crops up is retraction of a published paper (i.e., effectively saying “ignore that paper we published way back when”). Reasons for retraction include a serious mistake, plagiarism of somebody else’s work or outright fabrication of data.
Retraction of papers published in software engineering journals is rare, why is that? I don’t think software engineering researchers are more/less honest than researchers in other fields. I could not find any entries on Retraction Watch.
Plagiarism certainly occurs and every now and again a paper is retracted for this reason.
Corrections to previously published papers certainly occur on a regular basis, but I don’t recall seeing a retraction because of a serious error (but then I rarely get to gossip around the coffee table in university departments and am not that well up on such goings on).
Researchers are certainly not above using the subset of a benchmark that shines the most favorable light on their work, or simply performing misleading comparisons. Researchers who do such things are seem more as an embarrassment than a threat to academic integrity, they are certainly not in the same league as those who fabricate data
Fabrication of data in software engineering? I’m sure it goes on, but unless the people responsible own up I think it is unlikely to be detected (unless the claims are truely over the top). There is no culture of replication in software engineering or of building on other peoples’ work (everybody is into doing their own thing); two very serious problems, but not the topic of this discussion.
In fact software engineering is the ideal discipline for an academic fraudster: replication is very rare, everyone doing their own thing, a culture of poor/nonexistent record keeping and experimental data is rarely kept past the replacement of the machine on which it sits (I am regularly told this when I email authors asking for a copy of their raw data for my book). Even in disciplines whose characteristics are at the other end of the culture scale, it can take a long time for fraud to be uncovered.
From time to time authors I contact tell me that the numbers appearing in the published paper are incorrect; often there is an offer of the correct numbers and sometimes a vague recollection of what they might be. Sometimes authors don’t reply to my email, is the data fake or is talking to me not worth their time (I have received replies to this effect)?
Am I worried about fraud in software engineering research? No, incorrect data in published work is more likely to occur because of clerical mistakes, laziness or incompetence.
2013 in the programming language standards’ world
Yesterday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming languages. Things have been rather quiet since I last wrote about IST/5, 18 months ago. Of course lots of work has been going on (WG21 meetings, C++ Standard, are attracting 100+ people, twice a year, to spend a week trying to reach agreement on new neat features to add; I’m not sure how the ability to send email is faring these days ;-).
Taken as a whole programming languages standards work, at the ISO level, has been in decline over the last 10 years and will probably decline further. IST/5 used to meet for a day four times a year and now meets for half a day twice a year. Chairman of particular language committees, at international and national levels, are retiring and replacements are thin on the ground.
Why is work on programming language standards in decline when there are languages in widespread use that have not been standardised (e.g., Perl and PHP do not have a non-source code specification)?
The answer is low hardware/OS diversity and Open source. These two factors have significantly reduced the size of the programming language market (i.e., there are far fewer people making a living selling compilers and language related tools). In the good old-days any computer company worth its salt had its own cpu and OS, which of course needed its own compiler and the bigger vendors had third parties offering competing compilers; writing a compiler was such a big undertaking that designers of new languages rarely gave the source away under non-commercial terms, even when this happened the effort involved in a port was heroic. These days we have a couple of cpus in widespread use (and unlikely to be replaced anytime soon), a couple of OSs and people are queuing up to hand over the source of the compiler for their latest language. How can a compiler writer earn enough to buy a crust of bread let alone attend an ISO meeting?
Creating an ISO language standard, through the ISO process, requires a huge amount of work (an estimated 62-person years for C99; pdf page 20). In a small market, few companies have an incentive to pay for an employee to be involved in the development process. Those few languages that continue to be worked on at the ISO level have niche markets (Fortran has supercomputing and C had embedded systems) or broad support (C and now C++) or lots of consultants wanting to be involved (C++, not so much C these days).
The new ISO language standards are coming from national groups (e.g., Ruby from Japan and ECMAscript from the US) who band together to get the work done for local reasons. Unless there is a falling out between groups in different nations, and lots of money is involved, I don’t see any new language standards being developed within ISO.
Cloning research needs a new mantra
The obvious answer to software engineering researchers who ask why their findings are not applied within industry is that their findings provide no benefits to industry. Anyone who digs into the published research finds that in fact there is lots of potentially useful stuff in there, the problem is that researchers often take too narrow a perspective.
A good example of a research area that is generally ignored by industry but has potential for widespread benefits is software cloning; that is chunks of source code that are duplicated within the same application (a chunk may be as little as five lines or may be more, and the definition of duplicate varies from exactly the same character sequence, through semantic equivalence to chilling out with a certain percentage of lines being the same {with various definitions for ‘same’}). (This is not about duplication of code in multiple versions of the same product, we all know how nasty that can be to maintain).
Researchers regard cloning as bad, while I suspect many developers are neutral on the subject or even in favor of creating and using duplicate code.
Clone research will be ignored by industry while researchers continue to push the mantra “clones are bad”. It just does not gel with industry’s view.
Developers are under pressure to deliver working software; if they can save time by (legally) making use of existing code then there is an immediate benefit to them and their employer. The researchers’ argument is that clones increase maintenance costs (a fault being fixed in one of the duplicates but not the other(s) is often cited as the killer case for all clones being bad). What developers know is that most code is never maintained (e.g., is is rewritten, or never used again or works fine and does not need to be changed).
Do company’s that own software care about it containing clones? They are generally more interested in meeting deadlines and being first to market. If a product is a success it will be worth paying its maintenance costs; why risk spending extra time/money on creating a beautifully written product when most products don’t well well enough to be worth maintaining? If the software is bespoke, for in-house use or by a client, then increased maintenance costs are good for those involved in writing the software (i.e., they get paid to maintain it).
The new clone research mantra should be that clones have benefits and costs, and the research results help increase benefits and decrease costs. How does this increase/decrease work? You’re the researchers, you tell me.
My own experience with clones is that they do sometimes multiply costs (i.e., work has to be done more than once) but overall their creation and use is very cost effective, as for ‘missed’ fault fixes clones are a small subset of this use case.
I have heard of projects where there has been rampant copying, plus minor modification, of code within the project. If such projects fail then the issue is one of project management and control, with cloning being one of the consequences.
The number of clones usually found in a large software system is surprisingly high; . If you want to check out the clones in your own code CCFinder is well worth a look. The most common use for such tools is plagiarism detection.
A local CS reading group
Paper Cup, a reading group for computer science papers recently started, based about 30 minutes from me I decided to go along to the first meeting to see what it was like.
The paper under discussion was: Dynamo: Amazon’s Highly Available Key-value Store. I don’t know much about databases and and have never written code that uses a key-store, but since the event was hosted by guys at ebay/PayPal I figured there would be somebody in the room who knew what they were talking about.
The idea behind a paper reading group is that everybody agrees to read a paper before the meeting, then turns up at the meeting and discusses it.
The list of authors takes up three lines and their affiliation is simply listed as Amazon.com. As a subject matter outsider who probably reads several hundred papers a year my overall impression was that this paper was relatively information free and was more or less a puff-piece for Amazon. On the other hand it currently has 1,562 citations, a lot more than would be expected for a puff-piece paper published in 2007. I was obviously missing something.
Around 10 people showed up, with a handful sounding very knowledgeable and one person working on a new ‘Dynamo like’ implementation. Several replies to my question of what was so good about this paper, that appeared relatively content free to me, gave the reason that they were inspired by it. Wow, very few scientific papers ever inspire anybody.
The group worked its way through the paper and I tried to nod intelligently at the right time. This is one of those papers that requires lots of reading between the lines, an activity that requires lots of background knowledge and hands-on experience (as an outsider I was only reading the surface text).
I asked if one of the reasons this paper was considered to be important was because it described a commercial implementation rather than a research project. Any design team is much more likely to use techniques outlined in a paper describing a working commercial system than techniques operating in some toy academic environment (papers on Cassandra were appearing at about the same time). I’m not sure the relatively young attendees understood the importance of this point.
The take-away interesting snippet of information: Dynamo gives preference to performance over consistency, if a customer’s shopping basket key-value store becomes inconsistent then information on items added to the basket take precedence over items deleted from the basket (a sensible choice for a retailer such as Amazon).
If you live near west London and are interested in discussing CS paper do join the Paper Cup meetup group, the more the merrier.
Recent Comments