Changes in the API/non-API method call ratio with program size
Amount of code is the fundamental metric of software engineering. How do things change as the amount of code changes and often just as interestingly what does not change with code size?
Most languages include some kind of base library functionality. Languages such as Java and C++ not only include a very large library but also a huge, widely used, collection of third-party libraries.
Let’s count every method call in lots of Java programs and for each program divide these calls into two groups, calls to methods in well-known libraries (call these the API methods) and all other method calls (i.e., calls to methods written by the developers who wrote each of the programs measured; call these the non-API methods).
I would expect the ratio of API to non-API method calls to be independent of program size.
Yes, the number of possible different API calls is fixed while the number of possible non-API calls increases with program size, but I don’t see why a changing ratio of unique calls should change the ratio of total calls.
Yes, larger programs are likely to contain more architectural stuff whose code is more likely to contain calls to non-API methods, but the percentage of architectural code is very small and unlikely to have much impact on the overall numbers.
The authors of the paper: Large-scale, AST-based API-usage analysis of open-source Java projects made their data available and so I got to check out my thinking 🙂
The plot below shows everything going to plan until around 10,000 method calls (about 50,000 lines of code). Why that sudden kink in the line (code and data)?
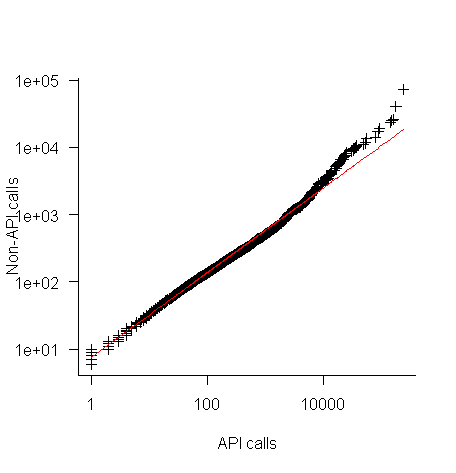
One possibility is that once a program gets to a size of around 50,000 lines the developers decide to invest in one or more wrapper packages which create a purpose built interface to an API (programs often have their own requirements and needs that existing an existing API interface does not quite meet); this would cause API calls to decrease and non-API calls to increase. If this pattern of usage occurred there would be a permanent change in the API/non-API ratio, and in practice the ratio change appears to be temporary.
I’m a bit stumped by this behavior. Suggestions on possible mechanisms welcome.
I wish I had the time to investigate, but I have a book to finish.
A prediction for 2014
When I first started writing this blog I used to make prediction for the coming year. After a couple of years I stopped doing this, the world of computer languages changes very slowly, i.e., I was mostly proved wrong.
I recently realised that Facebook had not yet launched their own general programming language; such an event must be a sure fire prediction for 2014.
Stop trying to argue that the world does not need a new programming language. The reason companies launch their own language is self image (in the way Hollywood superstars launch their own perfumes and fashion lines).
Back in the day IBM launched PL/1, we had Ada from the US DOD, C# and F# from Microsoft, Google has Go and Mozilla has Rust.
Facebook has a software platform and I’m sure they feel something is missing. It must really gall their engineers to hear people from Google, Mozilla and even that old fogy Microsoft talking about ‘their’ language.
New languages are easy to invent, PhD students do it all the time. Implementing them is also cheap, a good engineer can put together a compiler and interpreter in about a year; these days, thanks to LLVM, the cost of building a machine code generator for a new language has dropped significantly (GCC is still intimidating). Libraries, where a large percentage of the work used to go, can be copied from a multitude of places (not a problem if everything is open sourced, which new language implementations tend to be these days).
One end of year tit-bit is that Google now seem to be taking Dart more seriously than just techy swagger.
Converting graphs in pdf files to csv format
Looking at a graph displayed as part of a pdf document is so tantalizing; I want that data as a csv!
One way to get the data is to email the author(s) and ask for it. I do this regularly and sometimes get the apologetic reply that the data is confidential. But I can see the data! Yes, but we only got permission to distribute the paper. I understand their position and would give the same reply myself; when given access to a company’s confidential data, explicit permission is often given about what can and cannot be made public with lists of numbers being on the cannot list.
The Portable Document Format was designed to be device independent, which means it contains a description of what to display rather than a bit-map of pixels (ok, it can contain a bit-map of pixels (e.g., a photograph) but this rather defeats the purpose of using pdf). It ought to be possible to automatically extract the data points from a graph and doing this has been on my list of things to do for a while.
I was mooching around the internals of a pdf last night when I spotted the line: /Producer (R 2.8.1); the authors had used R to generate the graphs and I could look at the R source code to figure out what was going on :-). I suspected that each line of the form: /F1 1 Tf 1 Tr 6.21 0 0 6.21 135.35 423.79 Tm (l) Tj 0 Tr was a description of a circle on the page and the function PDF_Circle in the file src/library/grDevices/src/devPS.c told me what the numbers meant; I was in business!
I also managed to match up other lines in the pdf file to the output produced by the functions PDF_Line and PDFSimpleText; it looked like the circles were followed by the axis tick marks and the label on each tick mark. Could things get any easier?
In suck-it-and-see projects like this it is best to use very familiar tools, this allows cognition to be focused on the task at hand. For me this meant using awk to match lines in pdf files and print out the required information.
Running the pdf through an awk script produced what looked like sensible x/y coordinates for circles on the page, the stop/start end-points of lines and text labels with their x/y coordinates. Now I needed to map the page x/y coordinates to within graph coordinate points.
After the circle coordinates in the output from the script were a series of descriptions of very short lines which looked like axis tick marks to me, especially since they were followed by coordinates of numbers that matched what appeared in the pdf graphs. This information is all that is needed to map from page coordinates to within graph coordinates. The graph I was interested in (figure 6) used logarithmic axis, so things were made a bit complicated by the need to perform a log transform.
Running the output (after some cut and pasting to removed stuff associated with other graphs in the pdf) from the first script through another awk script produced a csv file that could be fed into R’s plot to produce a graph that looked just like the original!
I would say it is possible to extract the data points from any graph, generated using R producing pdf or ps, contained within a pdf file.
The current scripts are very specific to the figure I was interested in, this is more to do with my rough and ready approach to solving the problem which makes assumptions about that is in the data; a more sophisticated version could handle common variations on the theme and with a bit of elbow grease point-and-click might be made to work.
It is probably also possible to extract data points in graphs produced by other tools, ‘all’ that is needed is information on the encoding used.
Extracting data from graphs generated to an image format such as png or jpg are going to need image processing software such as that used to extract data from images of tables.
Variable naming based on lengths of existing variable names
Over the years I have spent a lot of time studying variable names and I sometimes encounter significant disbelief when explaining the more unusual developer variable name selection algorithms.
The following explanation from Rasmus Lerdorf, of PHP fame, provides a useful citable source for a variant on a common theme (i.e., name length).
“… Back when PHP had less than 100 functions and the function hashing mechanism was strlen(). In order to get a nice hash distribution of function names across the various function name lengths names were picked specifically to make them fit into a specific length bucket. This was circa late 1994 when PHP was a tool just for my own personal use and I wasn’t too worried about not being able to remember the few function names.”
Pointers to other admissions of youthful folly welcome.
How to use intellectual property tax rules to minimise corporation tax
I recently bought the book Valuing Intellectual Capital by Gio Wiederhold because I thought it might provide some useful information for a book I am working on. A better title for the book might have been “How to use intellectual property tax rules to minimise corporation tax”, not what I was after but a very interesting read none the less.
If you run a high-tech company that operates internationally, don’t know anything about finance, and want to learn about the various schemes that can be used to minimise the tax your company pays to Uncle Sam this book is for you.
This book is also an indispensable resource for anybody trying to unravel the financial structure of an international company.
On the surface this book is a detailed and readable how-to on using IP tax rules to significantly reduce the total amount of corporation tax an international company pay on their profits, but its real message is the extent to which companies have to distort their business and engage in ‘unproductive’ activities to achieve this goal.
Existing tax rules are spaghetti code and we all know how much effect tweaking has on this kind of code. Gio Wiederhold’s recommended rewrite (chapter 10) is the ultimate in simplicity: set corporation tax to zero (the government will get its cut by taxing the dividends paid out to shareholders).
Software developers will appreciate the “here’s how to follow the rules to achieve this effect” approach; this book could also be read as an example of how to write good software documentation.
Unreliable cpus and memory: The end result of Moore’s law?
Where is the evolution of commodity cpu and memory chips going to take its customers? I think the answer is cheap and unreliable products (just like many household appliances are priced low and have a short expected lifetime).
We have had the manufacturer-customer win-win phase of Moore’s law and I think we are now entering the win-loose phase.
The reason chip manufacturers, such as Intel, invest so heavily on continually shrinking dies is the same reason all companies invest, they expect to get a good return on their investment. The cost of processing the wafer from which individual chips are cut is more or less constant, reducing the size of a chip enables more to fitted on the same wafer, giving more product to sell for more or less the same wafer processing cost.
The fact that dies with smaller feature sizes have reduce power consumption and can run at faster clock speeds (up until around 10 years ago) is a secondary benefit to manufacturers (it created a reason for customers to replace what they already owned with a newer product); chip manufacturers would still have gone down the die shrink path if these secondary benefits had not existed, but perhaps at a slower rate. Customers saw, or were marketed, this strinkage story as one of product improvement for their benefit rather than as one of unit cost reduction for Intel’s benefit (Intel is the end-customer facing company that pumped billions into marketing).
Until recently both manufacturer and customer have benefited from die shrinks through faster cpus/lower power consumption and lower unit cost.
A problem that was rarely encountered outside of science fiction a few decades ago is now regularly encountered by all owners of modern computers, cosmic rays (plus more local source of ‘rays’) altering the behavior of running programs (4 GB of RAM is likely to experience a single bit-flip once every 33 hours of operation). As die shrink continues this problem will get worse. Another problem with ever smaller transistors is their decreasing mean time to failure (very technical details); we have seen expected chip lifetimes drop from 10 years to 7 and now less and decreasing.
Decreasing chip lifetimes is actually good for the manufacturer, it creates a reason for customers to buy a new product. Buying a new computer every 2-3 years has been accepted practice for many years (because the new ones were much better). Are we, the customer, in danger of being led to continue with this ‘accepted practice’ (because computers reliability is poor)?
Surely it is to the customer’s advantage to not buy devices that contain chips with even smaller features? Is it only the manufacturer that will obtain a worthwhile benefit from future die shrinks?
Street cred has no place in guidelines for nuclear power stations
The UK Government recently gave the go ahead to build a new nuclear power station in the UK. On Friday I spotted the document COMPUTER BASED SAFETY SYSTEMS published by the UK’s Office for Nuclear Regulation.
This document does a good job of enumerating all of the important software engineering issues in short, numbered, sentences, until sentence 54 of Appendix 1; “A1.54 The coding standards should prohibit the following practices:-“. Why-o-why did the committee of authors choose to stray from the approach of providing a high level overview of all the major issues? I suspect they wanted to prove their street cred as real software developers. As usually happens in such cases the end result looks foolish and dated (1970-80s in this case).
The nuclear industry takes it procedures a lot more seriously than most other industries, which means some poor group of developers are going to have to convince a regulator with minimal programming language knowledge that they are following this rather nebulous list of prohibitions.
What does the following mean? “5 Multiple use of variables – variables should not be used for more than one function;”. It could be read to mean no use of global variables, but is probably intended to cover something like the role of variables idea.
How is ‘complicated’ calculated in the following? “9 Complicated calculation of indexes;”
Here is my favorite: “15 Direct memory manipulation commands – for example, PEEK and POKE in BASIC;”. More than one committee member obviously had a BBC Micro or Sinclair Spectrum as a teenager.
What should A1.54 say? Something like: “A coding guideline document listing the known problematic areas of the language(s) used along with details of how to handle each area will be written. All staff will be given training on the use of these guidelines.”
The regulator needs to let the staff hired following A1.4 do their job: “A1.4 Only reputable companies should be used in all stages of the lifecycle of computer based protection systems. Each should have a demonstrably good track record in the appropriate field. Such companies should only use staff with the appropriate qualifications and training for the activities in which they are engaged. Evidence that this is the case should be provided.”
After A1.54 has been considerably simplified, A1.55 needs to be deleted: “A1.55 The coding standards should encourage the following:-“. Either require it or not. I suspect the author of “6 Explicit initialising of all variables;” had one of a small number of languages in mind, those that support implicit initialization with a defined value: many don’t, illustrating how language specific coding guidelines need to be.
Following the links in the above document led to: Verification and Validation of Software Related to Nuclear Power Plant Instrumentation and Control which contained some numbers about Sizewell B I had not seen before in public documents: “The total size of the source code for the reactor protection functions, excluding comments, support software for the autotesters and communications to other systems, is around 100 000 unique lines. A typical processor contains between 10 000 and 40 000 lines of source code, of which about half are typically from common functions, and the remainder form application code. In addition to the executable code, the PPS incorporates around 100 000 lines of configuration and calibration data per guardline associated with the reactor protection functions.”
Ordinary Least Squares is dead to me
Most books that discuss regression modeling start out and often finish with Ordinary Least Squares (OLS) as the technique to use; Generalized Linear ModelLeast Squares (GLMS) sometimes get a mention near the back. This is all well and good if the readers’ data has the characteristics required for OLS to be an applicable technique. A lot of data in the social sciences has these characteristics, or so I’m told; lots of statistics books are written for social science students, as a visit to a bookshop will confirm.
Software engineering datasets often range over several orders of magnitude or involve low value count data, not the kind of data that is ideally suited for analysis using OLS. For this kind of data GLMS is probably the correct technique to use (the difference in the curves fitted by both techniques is often small enough to be ignored for many practical problems, but the confidence bounds and p-values often differ in important ways).
The target audience for my book, Empirical Software Engineering with R, are working software developers who have better things to do that learn lots of statistics. However, there is no getting away from the fact that I am going to have to make extensive use of GLMS, which means having to teach readers about the differences between OLS and GLMS and under what circumstances OLS is applicable. What a pain.
Then I had a brainwave, or a moment of madness (time will tell). Why bother covering OLS? Why not tell readers to always use GLMS, or rather use the R function that implements it, glm. The default glm behavior is equivalent to lm (the R function that implements OLS); the calculation is not being done by hand but by a computer (i.e., who cares if it is more complicated).
Perhaps there is an easy way to explain this to software developers: glm is the generic template that can handle everything and lm is a specialized template that is tuned to handle certain kinds of data (the exact technical term will need tweaking for different languages).
There is one user interface issue, models built using glm do not come with an easy to understand goodness of fit number (lm has the R-squared value). AIC is good for comparing models but as a single (unbounded) number it is not that helpful for the uninitiated. Will the demand for R-squared be such that I will be forced for tell readers about lm? We will see.
How do I explain the fact that so many statistics books concentrate on OLS and often don’t mention GLMS? Hey, they are for social scientists, software engineering data requires more sophisticated techniques. I will have to be careful with this answer as it plays on software engineers’ somewhat jaded views of social scientists (some of whom have made very major contribution to CRAN).
All the software engineering data I have seen is small enough that the performance difference between glm/lm is not a problem. If performance is a real issue then readers will search the net and find out about lm; sorry guys but I want to minimise what the majority of readers need to know.
R now has its own shelf in Dillons
I was in Dillons, the one opposite University College London, at the start of the week and what did I spy there?

There is now a bookshelf devoted to R (right, second from top) in the programming languages section. The shelf would be a lot fuller if O’Reilly did not have a complete section devoted to their books.
A trolley of C/C++ books was waiting to refill the shelves near the door.

Being adjacent to a university means that programming language books make up a much larger percentage of software books.

And there is O’Reilly in the corner with two stacks of shelves.

And yes, this is a big bookshop, the front is a complete block; computing/mathematics/physics/chemistry/engineering/medicine are in the basement. You can buy skeletons and stethoscopes in the medical section a few rooms down from computing; a stethoscope is useful for locating strange noises in computer cases without having to open them.

Readers a bit younger than me probably know this shop as Waterstones.
What is the error rate for published mathematical proofs?
Mathematical proofs are sometimes cited as the gold standard against which software quality should be compared. At school we rarely get to hear about proofs that turn out to be wrong and are inculcated with the prevailing wisdom that all mathematical proofs are correct.
There are many technical and social issues involved in believing a published proof and well known established mathematicians have no trouble pointing out that “… it is impossible to write out a very long and complicated argument without error, …”
Examples of incorrect published proofs include Wiles’ first proof of Fermat’s Last Theorem and an serious error found in a proof of a message signing scheme.
A question on mathoverflow contains a list of rather interesting false proofs.
Then, of course, there are always those papers that appear in journals that get written about more frequently on Retraction Watch than others.
What is the error rate for published mathematical proofs? I have not been able to find any collection of mathematical proof error data.
Several authors have expressed the view that because there so many diverse mathematical topics being studied these days there are very few domain experts available to check proofs. A complicated proof of a not particularly interesting result is unlikely to attract the attention needed to check it thoroughly. It should come as no surprise that the number of known errors in such proofs is equal to the number of known errors in programs that have never been executed.
Proofs are different from programs in that one error can be enough to ‘kill-off’ a proof, while a program can contain many errors and still be useful. Do errors in programs get talked about more than errors in proofs? I rarely get to socialize with working mathematicians and so cannot make any judgment call on this question.
Every non-trivial program is likely to contain many errors; can the same be said for long mathematical proofs? Are many of these errors as trivial (in the sense that they are easily fixed) as errors in programs?
One commonly used error rate for programs is errors per line of code; how should the rate be expressed for proofs? Errors per page, per line, per definition?
Lots of questions and I’m hoping one of my well informed readers will be able to provide some answers or at least cite a reference that does.
Recent Comments