Archive
February 2012 news in the programming language standard’s world
Yesterday I was at the British Standards Institute for a meeting of the programming languages committee. Some highlights and commentary:
- The first Technical Corrigendum (bug fixes, 47 of them) for Fortran 2008 was approved.
- The Lisp Standard working group was shutdown, through long standing lack of people interested in taking part; this happened at the last SC22 meeting, the UK does not have such sole authority.
- WG14 (C Standard) has requested permission to start a new work item to create a new annex to the standard containing a Secure Coding Standard. Isn’t this the area of expertise of WG23 (Language vulnerabilities)? Well, yes; but when the US Department of Homeland Security is throwing money at cyber security increasing the number of standards’ groups working on the topic creates more billable hours for consultants.
- WG21 (C++ Standard) had 73 people at their five day meeting last week (ok, it was in Hawaii). Having just published a 1,300+ page Standard which no compiler yet comes close to implementing they are going full steam ahead creating new features for a revised standard they aim to publish in 2017. Does the “Hear about the upcoming features in C++” blogging/speaker circuit/consulting gravy train have that much life left in it? We will see.
The BSI building has new lifts (elevators in the US). To recap, lifts used to work by pressing a button to indicate a desire to change floors, a lift would arrive, once inside one or more people needed press buttons specifying destination floor(s). Now the destination floor has to be specified in advance, a lift arrives and by the time you have figured out there are no buttons to press on the inside of the lift the doors open at the desired floor. What programming language most closely mimics this new behavior?
Mimicking most languages of the last twenty years the ground floor is zero (I could not find any way to enter a G). This rules out a few languages, such as Fortran and R.
A lift might be thought of as a function that can be called to change floors. The floor has to be specified in advance and cannot be changed once in the lift, partial specialization of functions and also the lambda calculus springs to mind.
In a language I just invented:
// The lift specified a maximum of 8 people lift = function(p_1, p_2="", p_3="", p_4="", p_5="", p_6="", p_7="", p_8="") {...} // Meeting was on the fifth floor first_passenger_5th_floor = function lift(5); second_passenger_4th_floor = function first_passenger_fifth_floor(4); |
the body of the function second_passenger_4th_floor is a copy of the body of lift with all the instances of p_1 and p_2 replaced by the 5 and 4 respectively.
Few languages have this kind of functionality. The one that most obviously springs to mind is Lisp (partial specialization of function templates in C++ does not count because they are templates that are still in need of an instantiation). So the ghost of the Lisp working group lives on at BSI in their lifts.
O Cobol, Cobol! wherefore art thou Cobol?
Programming language popularity has been in the news again and as always Cobol is nowhere to be seen in the rankings. Even back in the day, when people in the know generally considered Cobol to be the most widely used language it often failed to appear, or appeared very low down, in language rankings. I think Cobol’s unrepresentative rankings occur because users of Cobol are assumed to hang out in the same places as users of other programming languages. The letters bo in the name is the clue, business oriented people are not usually interested in technical stuff and tend not to read the magazines (and these days web sites) that users of the other popular languages read.
Cobol is very business domain specific and does not contain functionality that makes it a reasonable choice for writing applications in other domains (it is possible to write a compiler in Cobol, for instance the Micro Focus compiler is written in Cobol). It has very sophisticated languages constructs for handling data having the most convoluted formats imaginable, essential in the business world which has to process data whose format has evolved over the years into a tangled mess (developers have to deal with spaghetti code, business has to deal with spaghetti data formats). Cobol’s control flow and code structuring facilities are primitive (all variables are global and the perform statement is very similar to the gosub statement found in Basic’s that are line number based) because business data processing tends to be relatively simple and programs to handle them are generally small (the large Cobol programs of legend are invariably made up of lots of small programs run in series with complicated data format dependencies between them).
I started to realise just how different Cobol is when working on my first Cobol code generator (yes it was written in Cobol). If a processor has lots of registers it is usually worthwhile to dedicate one to holding the value zero (of the 32 registers supported by most RISC processors, often only 31 can hold different values, one is dedicated to returning zero when read from and ignores any value written to it), in the case of Cobol it is considered worthwhile to dedicate a register to hold 0x20202020 (four space characters) rather than zero.
Is Cobol still the most widely used language today? No, I don’t think so. Business people love spreadsheets which means developers have switched to writing pre/post data format processing code, previously in Cobol, in Visual Basic (to convert input data into a form accepted by the spreadsheet and then print the results of the spreadsheet calculations in a presentable format); this Visual Basic source can often have a Cobol-like feel to it. This spreadsheet usage also resulted in the comma separated list becoming a widely used format for data representation, eroding Cobol’s unique selling point of sophisticated input/output data format processing.
What does language popularity mean? Does using a language you don’t like count towards it being popular? There are several languages I like and very rarely get to use, does this mean I don’t get to contribute to their popularity?
In these tough financial times the number of job adverts requiring knowledge of a specified language is probably of more interest than number of posts to web sites. One job search site lists 3,032 Cobol jobs and counting job ad hits for the top languages listed in a recent popularity poll puts Cobol at the bottom end of the cluster of highest ranked languages.
On mainframes I think Cobol is likely to still be No. 1; it is probably impossible to replace the dominant language in a niche market.
Correlation between risk attitude and willingness to refer back
What is the connection between a software developer’s risk attitude and the faults they insert in code they write or fail to detect in code they review? This is a very complicated question and in an experiment performed at the 2011 ACCU conference I investigated one particular instance; the connection between risk attitude and recall of previously seen information.
The experiment consisted of a series of problems having the same format (the identifiers used varied between problems). Each problem involved remembering information on four assignment statements of the form:
p = 6 ; b = 4 ; r = 9 ; k = 8 ; |
performing some other unrelated task for a short time (hopefully long enough for them to forget some of the information they had previously seen) and then having to recognize the variables they had previously seen within a list containing five identifiers and recall the numeric value assigned to each variable.
When reading code developers have the option of referring back to previously read code and this option was provided to subject. Next to each identifier listed in the recall part of the problem was space to write the numeric value previously seen and a “would refer back” box. Subjects were told to tick the “would refer back” box if, in real life” they would refer back to the previously seen assignment statements rather than rely on their memory.
As originally conceived this experimental format is investigating the impact of human short term memory on recall of previously seen code. Every time I ran this kind of experiment there was a small number of subjects who gave a much higher percentage of “would refer back” answers than the other subjects. One explanation was that these subjects had a smaller short term memory capacity than other subjects (STM capacity does vary between people), another explanation is that these subjects are much more risk averse than the other subjects.
The 2011 ACCU experiment was designed to test the hypothesis that there was a correlation between a subject’s risk attitude and the percentage of “would refer back” answers they gave. The Domain-Specific Risk-Taking (DOSPERT) questionnaire was used to measure subject’s risk attitude. This questionnaire and the experimental findings behind it have been published and are freely available for others to use. DOSPERT measures risk attitude in six domains: social, recreation, gambling, investing health and ethical.
The following scatter plot shows each (of 30) subject’s risk attitude in the six domains (x-axis) plotted against percentage of “would refer back” answers (y-axis).
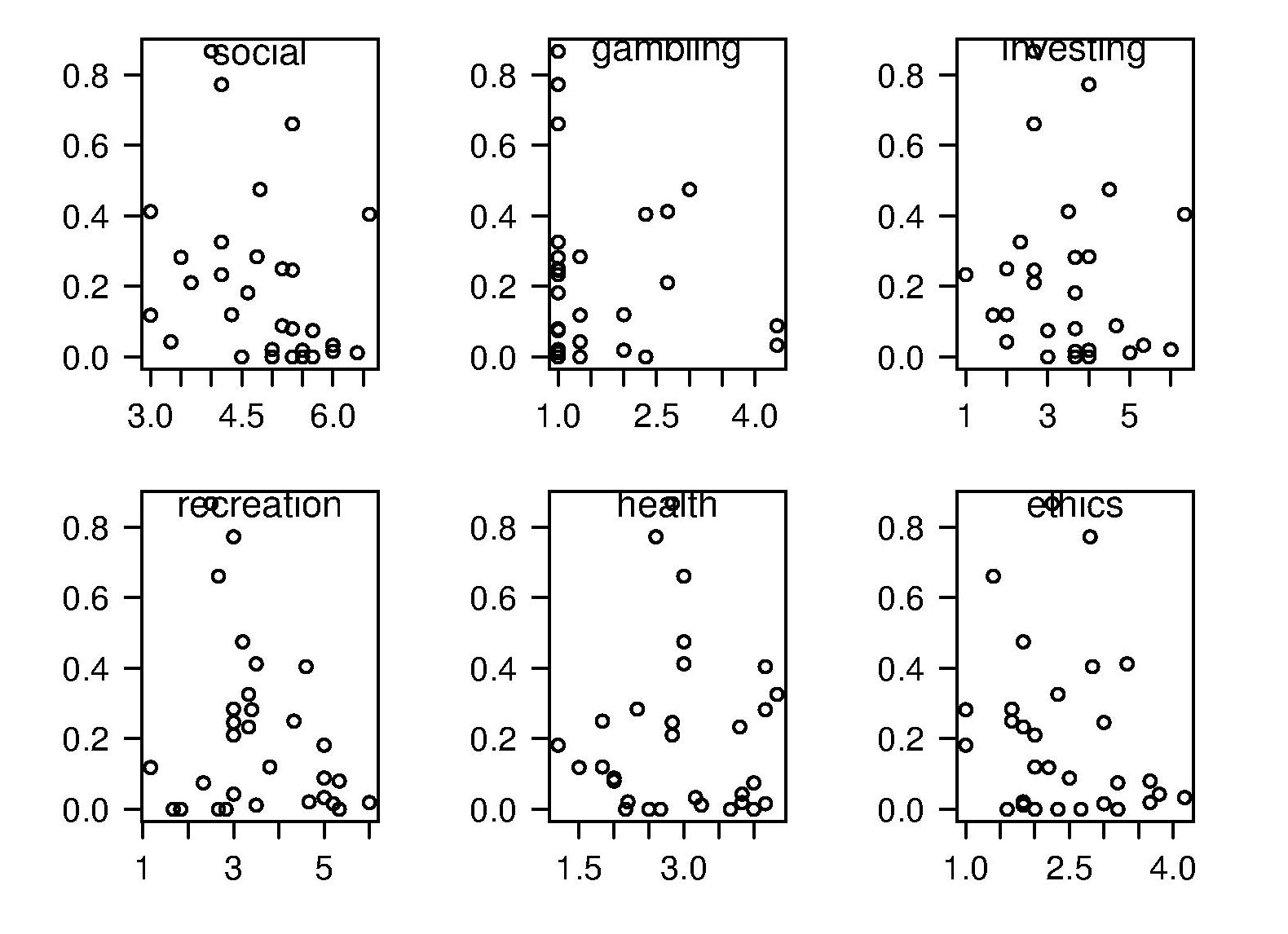
A Spearman rank correlation test confirms what is visibly apparent, there is no correlation between the two quantities. Scatter plots using percentage of correct answers and total number of questions answers show a similar lack of correlation.
The results suggest that risk attitude (at least as measured by DOSPERT) is not a measurable factor in subject recall performance. Perhaps the subjects that originally caught my attention (there were three in 2011) really do have a smaller STM capacity compared to other subjects. The organization of the experiment (one hour during a one lunchtime of the conference) does not allow for a more extensive testing of subject cognitive characteristics.
Relative spacing of operands affects perception of operator precedence
What I found most intriguing about Google Code Search (shutdown Nov 2011) was how quickly searches involving regular expressions returned matches. A few days ago Russ Cox, the implementor of Code Search not only explained how it worked but also released the source and some precompiled binaries. Google’s database of source code did not include the source of R, so I decided to install CodeSearch on my local machine and run some of my previous searches against the latest (v2.14.1) R source.
In 2007 I ran an experiment that showed developers made use of variable names when making binary operator precedence decisions. At about the same time two cognitive psychologists, David Landy and Robert Goldstone, were investigating the impact of spacing on operator precedence decisions (they found that readers showed a tendency to pair together the operands that were visibly closer to each other, e.g., a with b in a+b * c rather than b with c).
As somebody very interested in finding faults in code the psychologists research findings on spacing immediately suggested to me the possibility that ‘incorrectly’ spaced expressions were a sign of failure to write code that had the intended behavior. Feeding some rather complicated regular expressions into Google’s CodeSearch threw up a number of ‘incorrectly’ spaced expressions. However, this finding went no further than an interesting email exchange with Landy and Goldstone.
Time to find out whether there are any ‘incorrectly’ spaced expressions in the R source. cindex (the tool that builds the database used by csearch) took 3 seconds on a not very fast machine to process all of the R source (56M byte) and build the search database (10M byte; the Linux database is a factor of 5.5 smaller than the sources).
The search:
csearch "w(+|-)w +(*|/) +w" |
returned a few interesting matches:
... modules/internet/nanohttp.c: used += tv_save.tv_sec + 1e-6 * tv_save.tv_usec; modules/lapack/dlapack0.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack2.f: S = Z( 3 )*( Z( 2 ) / ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack4.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) |
There were around 15 matches of code like 1e-6 * var (because the pattern w is for alphanumeric sequences and that is not a superset of the syntax of floating-point literals).
The subexpression ONE+S / T is just the sort of thing I was looking for. The three instances all involved code that processed tridiagonal matrices in various special cases. Google search combined with my knowledge of numerical analysis was not up to the task of figuring out whether the intended usage was (ONE+S)/T or ONE+(S/T).
Searches based on various other combination of operator pairs failed to match anything that looked suspicious.
There was an order of magnitude performance difference for csearch vs. grep -R -e (real 0m0.167s vs. real 0m2.208s). A very worthwhile improvement when searching much larger code bases with more complicated patterns.
Initial impressions of RangeLab
I was rummaging around in the source of R looking for trouble, as one does, when I came across what I believed to be a less than optimally accurate floating-point algorithm (function R_pos_di in src/main/arithemtic.c). Analyzing the accuracy of floating-point code is notoriously difficult and those having the required skills tend to concentrate their efforts on what are considered to be important questions. I recently discovered RangeLab, a tool that seemed to be offering painless floating-point code accuracy analysis; here was an opportunity to try it out.
Installation went as smoothly as newly released personal tools usually do (i.e., some minor manual editing of Makefiles and a couple of tweaks to the source to comment out function calls causing link errors {mpfr_random and mpfr_random2}).
RangeLab works by analyzing the flow of values through a program to produce the set of output values and the error bounds on those values. Input values can be specified as a range, e.g., f = [1.0, 10.0] says f can contain any value between 1.0 and 10.0.
My first RangeLab program mimicked the behavior of the existing code in R_pos_di:
n=-10; f=[1.0, 10.0]; res = 1.0; if n < 0, n = -n; f = 1 / f; end while n ~= 0, if (n / 2)*2 ~= n, res = res * f; end n = n / 2; if n ~= 0, f = f*f; end end |
and told me that the possible range of values of res was:
res ans = float64: [1.000000000000001E-10,1.000000000000000E0] error: [-2.109423746787798E-15,2.109423746787799E-15] |
Changing the code to perform the divide last, rather than first, when the exponent is negative:
n=-10; f=[1.0, 10.0]; res = 1.0; is_neg = 0; if n < 0, n = -n; is_neg = 1 end while n ~= 0, if (n / 2)*2 ~= n, res = res * f end n = n / 2; if n ~= 0, f = f*f end if is_neg == 1, res = 1 / res end end |
and the error in res is now:
res ans = float64: [1.000000000000000E-10,1.000000000000000E0] error: [-1.110223024625156E-16,1.110223024625157E-16] |
Yea! My hunch was correct, moving the divide from first to last reduces the error in the result. I have reported this code as a bug in R and wait to see what the R team think.
Was the analysis really that painless? The Rangelab language is somewhat quirky for no obvious reason (e.g., why use ~= when everybody uses != these days and if conditionals must be followed by a character why not use the colon like Python does?) It would be real useful to be able to cut and paste C/C++/etc and only have to make minor changes.
I get the impression that all the effort went into getting the analysis correct and user interface stuff was a very distant second. This is the right approach to take on a research project. For some software to make the leap from interesting research idea to useful tool it is important to pay some attention to the user interface.
The current release does not deserve to be called 1.0 and unless you have an urgent need I would suggest waiting until the usability has been improved (e.g., error messages give some hint about what is wrong and a rough indication of which line the problem occurs on).
RangeLab has shown that there is simpler method of performing useful floating-point error analysis. With some usability improvements RangeLab would be an essential tool for any developer writing code involving floating-point types.
Update: The R team, in the form of Martin Maechler, resolved my report in just over 14 hours! The function R_pos_di is not called, the pow function from the C library (which takes two double arguments rather than a double and an int) has been found to be more accurate. Martin says this usage is not less accurate even for n=3, which I find surprising; I agree it should be more accurate for large values of n.
pow is one of the more complicated maths functions, involving finding a log, a multiply and then returning the exponent of this result. There are lots of boundary values that need to be checked and the code goes on for a while. I will wait for the usability of RangeLab to improve before attempting to compare its accuracy against the simpler algorithm for integer powers. Looking at the SunOracle library sources, if both arguments have integral values the ‘integer power’ algorithm is used (with the divide performed last).
Licensing to decide the result of gcc vs llvm?
I was not surprised to hear today that Nvidia are halting development of their in-house C/C++ compiler and switching to one of the Open Source compilers. It is a lot cheaper to have one or two people looking after a company’s interests in a compiler developed by somebody else than having an in-house development group. It will be interesting to see how much longer Intel continues to fund their in-house compiler.
Nvidia chose llvm and gave a variety of technical reasons why this was the best choice over gcc.
One advantage (from Nvidia’s point of view) not mentioned is that llvm is licensed under a BSD style agreement. This means Nvidia don’t have to release the source code of any modifications or additions they make (they said these will be kept closed source); gcc is licensed under the GNU General Public License which requires source to be released. Arch rivals AMD (well, the ATI bit of AMD that does graphics hardware) also promote llvm, and I’m sure Nvidia does not want to help them in any way.
The licensing difference between gcc and llvm has the potential to make a big difference to the finances of both development teams.
My understanding of gcc funding is that most of it comes from back-end work (i.e., a company pays to have gcc work or do a better job on some [I imagine their] processor). Given a choice, would these companies rather release the source they paid to have written/modified or keep it closed? Some probably don’t care and hope that by making the source available others will help find and fix problems (i.e., there is a benefit to making it available), on the other hand companies introducing processors with fancy new features will want to minimise any technology that competitors can get for free.
In the years to come, it is possible that gcc will loose a significant amount of this back-end income to llvm because of licensing.
PhD projects are the life-blood of new compiler optimization techniques and for many years source code from them has often ended up as the experimental version of a new optimization phase of gcc. Many students are firm believers in making source freely available and shy away from being involved in non-GPL projects. Will this deter them from using llvm in their research (there may be a growing trend favoring llvm over gcc in research, or the llvm people may be better than the gcc folk at marketing {not hard})?
If llvm does not get the new fancy optimizations for ‘free’ they are going to have to spend money doing the implementing themselves or have their performance slowly fall behind that of gcc. Will this cost be more or less than the additional income from closed source customers?
We are unlikely to know the impact that licensing has on the fortunes of both compilers until the end of this decade. Perhaps designing and building a new processor will not be economically worthwhile in 10 years, perhaps all the worthwhile optimizations will be done. We will have to wait and see.
Update 4 Jan 2012: Video (235M) of talk on status of effort to make llvm the default compiler in FreeBSD at LLVM 2011 Developer’s meeting.
Optimizing floating-point expressions for accuracy
Floating-point arithmetic is one topic that most compiler writers tend to avoid as much as possible. The majority of programs don’t use floating-point (i.e., low customer demand), much of the analysis depends on the range of values being operated on (i.e., information not usually available to the compiler) and a lot of developers don’t understand numerical methods (i.e., keep the compiler out of the blame firing line by generating code that looks like what appears in the source).
There is a scientific and engineering community whose software contains lots of floating-point arithmetic, the so called number-crunchers. While this community is relatively small, many of the problems it works on attract lots of funding and some of this money filters down to compiler development. However, the fancy optimizations that appear in these Fortran compilers (until the second edition of the C standard in 1999 Fortran did a much better job of handling the minutia of floating-point arithmetic) are mostly about figuring out how to distribute the execution of loops over multiple functional units (i.e., concurrent execution).
The elephant in the floating-point evaluation room is result accuracy. Compiler writers know they have to be careful not to throw away accuracy (e.g., optimizing out what appear to be redundant operations in the Kahan summation algorithm), but until recently nobody had any idea how to go about improving the accuracy of what had been written. In retrospect one accuracy improvement algorithm is obvious, try lots of possible combinations of the ways in which an expression can be written and pick the most accurate.
There are lots of ways in which the operands in an expression can be paired together to be operated on; some of the ways of pairing the operands in a+b+c+d include (a+b)+(c+d), a+(b+(c+d)) and (d+a)+(b+c) (unless the source explicitly includes parenthesis compilers for C, C++, Fortran and many other languages (not Java which is strictly left to right) are permitted to choose the pairing and order of evaluation). For n operands (assuming the operators have the same precedence and are commutative) the number is combinations is  where
where  is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands
is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands  of which
of which  are unique.
are unique.
A recent study by Langlois, Martel and Thévenoux analysed the accuracy achieved by all unique permutations of ten operands on four different data sets. People within the same umbrella project are now working on integrating this kind of analysis into a compiler. This work is another example of the growing trend in compiler research of using the processing power provided by multiple cores to use algorithms that were previously unrealistic.
Over the last six years or so there has been lot of very interesting floating-point work going on in France, with gcc and llvm making use of the MPFR library (multiple-precision floating-point) for quite a while. Something very new and interesting is RangeLab which, given the lower/upper bounds of each input variable to a program (a simple C-like language) computes the range of the outputs as well as ranges for the roundoff errors (the tool assumes IEEE floating-point arithmetic). I now know that over the range [800, 1000] the expression x*(x+1) is a lot more accurate than x*x+x.
Update: See comment from @Eric and my response below.
Christmas books for 2011
The following is my suggested list of books to consider buying somebody to celebrate Christmas or Isaac Newton’s birthday (in the Julian calendar which applied when he was born). To pad out the list I have added a few books from Christmas’s before I started this blog.
The Number sense by Stanislas Dehaene, the second edition is a significantly revised and expanded version of the 1997 first edition and is even better than the first. A very readable introduction to the brain structures involved in processing numbers along with lots of practical examples of how this processing effects our everyday handling of number related situations. If you regularly work with numbers you have to read this book.
Understanding Comics by Scott McCloud. Superficially about comics but really a master class on how to convey lots of information with the minimum of content. An indispensable read for anybody with an interest in writing source code or diagrams that can be understood by other people.
The Psychology of language by Trevor Harley (now in its third edition which I have not read, this recommendations applies to the second edition from 2001). This book is the perfect antidote to the Chomsky syntax/semantics nonsense that continues to permeate the software world. This book discusses linguistic behavior from the perspective of psychological processes elucidated from experimental evidence. Not such an easy read as my first two recommendations, but worth the investment.
R in a Nutshell by Joseph Adler. A handy quick reference to have sitting next to the keyboard. There is opportunity for improvement in this niche but in 2011 this is king of the hill.
Europe at War by Norman Davies. Broad brush view of World war II from a variety of perspectives. Lots of numbers and readable analysis. An eye-opener for anybody who thinks that Britain’s (and all other European allies) manpower contribution, in the overall scale of things, was significant.
Other suggestions welcome.
Learning R as a language
Books written to teach a general purpose programming language are usually organized according to the features of the language and examples often show how a particular language feature is interpreted by a compiler. Books about domain specific languages are usually organized in a way that makes sense in the corresponding application domain and examples usually illustrate how a particular domain problem can be solved using the language.
I have spent a lot of time using R over the last year and by dint of reading lots of R code and various introductions to the language I have managed to piece together a model of the language. I rarely have any trouble learning a general purpose language from its reference manual, but users of domain specific languages are rarely interested in language details and so these reference manuals are usually only intended to be read by people who know the language well (another learning problem is that domain specific languages often contain quirky features rarely seen in other languages; in the case of R I was not lucky enough to know enough other languages to cover all its quirky features).
I managed to one introduction to R written from the perspective of the programming language (and not the application domain): the original The Art of R Programming by Norman Matloff has been expanded and is now available as a book.
Summary. If you know another language and want to quickly learn about the languages features of R I recommend this book. I have not taught raw beginners for over 30 years and have no idea if this book would be of any use to them.
This book does not attempt to teach you to think ‘R’, it is not about the art of R programming. The value of this book is as a single source for a broad coverage of lots of language features explained using lots of examples. Yes, more time could have been spent on the organization and fixing inconsistencies in the layout; these are not show stoppers.
Some people might tell you to buy “Software for Data Analysis” by John Chambers. Don’t; if you are a fan of Finnegans Wake and are nostalgic for the mainframe world of the 1970s you might like to give it a go. (I think Bertrand Meyer’s “Object-oriented Software Construction” is still the best book about the design of a language).
Meanderings. What books are good examples of “The Art of …” writing for domain specific languages? Two that spring to mind are: “Algorithms in Snobol 4” by James Gimpel (still spotted from time to time on second hand book sites) and more recently “SQL For Smarties: Advanced SQL Programming” by Joe Celko.
Yes, I know that R is not really a domain specific language but a language that is primarily used in one domain. Frink is an example of a language containing a major behavior feature that is specific to its intended application domain. I cannot think of any major language feature of R that is specific to statistics.
Recent Comments