When writing in assembly language it is possible to operate on a sequence of bits as if it were an unsigned integer one moment and a floating-point number the next; it is the developer’s responsibility to ensure that a given sequence of bits is operated on in a consistent manner. The concept of type was initially introduced into computer languages to provide information to compilers, enabling them to generate the appropriate instructions for values having the specified type and where necessary to convert values from the representation used by one type to the representation used by a different type. At this early stage language designers tended to keep things simple and to think in terms of what made sense at the machine representation level when deciding which type conversions to permit (PL/1 was a notable exception and the convolutions that occurred to perform some type conversions are legendary).
It took around 10 years for high level languages to evolve to the point where developers had the ability to create their own named types; Pascal being an early, very well known and stand out example. Once developers could create their own types it became necessary to come up with general rules specifying when a compiler must treat two different types as compatible (i.e., be required to generate code to support some set of operations between variables having these two different types).
Most language designers chose the simple option; a type is compatible with another type if it has the same name (scoping/namespace/lookup rules effectively meant that “same name” was effectively the same as “same definition”). This simple option generally included various exceptions for the arithmetic types; developers did not like having to insert explicit casts for what they considered to be obvious conversions (languages such as Ada/CHILL provided a mechanism for developers to specify that a newly defined arithmetic type really was a completely new type that was not compatible with any other arithmetic type, an explicit cast could change this).
One of the few languages which took a non-simple approach to type compatibility was CHILL, a language for which I once spent over a year writing the semantics phase of a compiler. CHILL uses what is known as structural compatibility, i.e., essentially two types are compatible if they have the same layout in memory (the language definition actually uses the terms similar and equivalent rather than compatible and uses mode rather than type, here I will follow modern general terminology). This has obvious advantages when there is a need to overlay types used in different parts of a program onto the same location in storage (note, no requirements on the fields being the same). CHILL definitions look like a mixture of C and Pascal, unless you know PL/1 they can look odd to the uninitiated (I think I’ve got them right, my CHILL is very rusty), T_1 and T_2 are compatible:
T_1 = struct ( T_2 = struct (
f1 :int; f3 :int;
f2 :int; f4 :int;
); ); |
T_1 = struct ( T_2 = struct (
f1 :int; f3 :int;
f2 :int; f4 :int;
); );
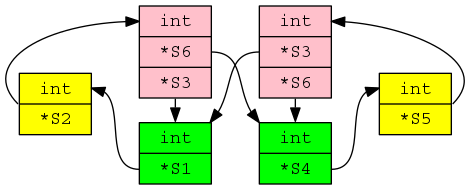
Structural compatibility enables the creation some rather unusual compatible types, such as the following three types all being pair-wise compatible (the keyword ref is use to specify pointer types):
T_3 = struct ( T_4 = struct ( T_5 = struct (
f1 :int; f4 :int; f7 :int;
f2 :ref T_3; f5 :ref T_4; f8 :ref T_5;
f3 :ref T_4; f6 :ref T_3; f9 :ref T_5;
); ); ); |
T_3 = struct ( T_4 = struct ( T_5 = struct (
f1 :int; f4 :int; f7 :int;
f2 :ref T_3; f5 :ref T_4; f8 :ref T_5;
f3 :ref T_4; f6 :ref T_3; f9 :ref T_5;
); ); );
Because types can be recursive it is possible for the compatibility checking code in the compiler to end up having to type check the type it is currently checking. The solution adopted by many CHILL compilers (not that there were ever many) was to associate an is_currently_being_checked flag with every type’s symbol table entry, if during compatibility checking this flag has value TRUE for both types then they are both compatible otherwise the flag is set to TRUE for both types and checking continues (all flags are set to FALSE at the end of compatibility checking).
To check T_3 and T_4 In the above code set the is_currently_being_checked flag to TRUE and iterate over the fields in each record. The first field pair have the same type, the second field pair are pointers to types we are already checking and therefore compatible, as are the third field pair, so the types are compatible. Checking T_3 and T_5 requires a second iteration through T_5 because of the pointer to T_4 which does not yet have its is_currently_being_checked flag set.
Yours truely discovered that one flag was not sufficient to do fully correct compatibility checking. It is necessary to maintain a stack of locations (e.g., the structure field or procedure parameter where compatibility checking has to recurse to check a user defined type) in the two types being compared in order to detect that some types were not compatible. In the following example (involving pointer to procedure types; which is longer than I remember the actual instance I first discovered being, but I had to create it again from vague memories and my CHILL expertise has faded; suggestions welcome) types A and B would be considered compatible using the is_currently_being_checked flag approach because by the time the last parameter is checked both symbol table flags have been set. You can see by inspection that types X and Y are not compatible (they have a different number of parameters to start with). Looking at the stack of previous compatibility checks for A/B would show that no X/Y compatibility check had yet been made and one would be needed for the third parameter (which would fail):
A = proc(X, Y, X);
B = proc(C, proc(A, int), Y);
C = proc(E);
D = proc(A);
E = proc(proc(X, proc(A, int), X));
X = proc(D);
Y = proc(A, int); |
A = proc(X, Y, X);
B = proc(C, proc(A, int), Y);
C = proc(E);
D = proc(A);
E = proc(proc(X, proc(A, int), X));
X = proc(D);
Y = proc(A, int);
The potential for complexity created by the use of structural compatibility is one reason why its use is rare. While it is possible to rationalize that CHILL was targeted at embedded telecommunication systems containing lots of code where memory costs can be significant, I suspect that those involved had a hardware mentality and a poor grasp of practical software engineering issues.
Incidentally, the design of the llvm type checking system relies on using an equality test to check for type equality. While this decision will increase the difficulty of integrating languages that use structural type compatibility into llvm, these languages are probably sufficiently rare that it is much more cost effective to make it simple to implement the more common languages.
Where did type compatibility go next? Well, over the last 20 years the juggernaut of object oriented design has pretty much excluded sophisticated non-OO type systems from mainstream languages (e.g., C++ and Java), but that is a topic for another article.
Recent Comments