Archive
The oldest compiler still in production use is?
What is the oldest compiler still in production use?
A CHILL compiler I worked on a long time ago has probably been in production use for 30 years now.
Code gets added and deleted from production software all the time, how might ‘oldest’ be measured? I propose using the mean age of every line of code, including comments, where the age of a line is reset to zero when it is modified in any way (excluding code formatting).
The following are two environmental factors that enable a production compiler to get very old:
- a relatively obscure language: popular languages have new compilers written for them (compiler death through competition) or have new features added to them (requiring new lines of code which could even displace ‘aged’ code),
- a very long-lived application associated with the language: obscure languages tend to be very quickly abandoned in the dust of history unless they have a symbiotic relationship with an important application,
- very long-lived host hardware and target processor: changing either often requires substantial new code or a move to a newer compiler. For ancient the only candidate is the IBM 370 and just really old the Intel 80×80, Zilog Z80.
Virtual machines provide a mechanism to be host hardware independent. The Micro Focus Cobol had a rewrite in the early 1990s (it might have had others since) and I don’t think UCSD Pascal I.5 is still used for production work.
Fortran is an evolving language and very popular in some application domains. I doubt there are any (mean age) old Fortran compilers in production use.
Why do I put forward the ITT (in its International Telephone & Telegraph days, these bits subsequently sold off) CHILL compiler as potentially the oldest compiler currently in production use?
- Obscure language and long-lived application (telephone switching software),
- host hardware was IBM 370 family, target processor Intel 8086 (later updated to support 80386),
- large development team and very small support team (i.e., lots of old code and small changes over the years),
- single customer, i.e., no push to add features to attract new customers or keep existing ones.
My last conversation with anybody associated with this compiler was a chance meeting over 10 years ago, so I might be a bit out of date.
30+ year old source code for compilers can be downloaded (e.g., the original PDP 11 C compiler) but these compilers are not in production use (forgotten about military installations anybody?)
I welcome other proposals for the oldest compiler currently in production use.
Writing language standards is a cottage industry
In the beginning programming language standards were written by one country’s National Standards body (e.g., ANSI did C/Cobol/Fortran for the USA and BSI did Pascal for the UK) and other countries were free to write their own version, adopt the existing work or do nothing (I don’t know of any country writing their own version, a few countries sometimes stuck their own front page on an existing document and the majority did nothing; update 4 Dec 2012, thanks to David Muxworthy for pointing out that around 1974 the UK, US, Japan and ECMA were all independently developing a standard for BASIC, by 1982 this had evolved to just ANSI and ECMA).
The UK people who created the Pascal Standard wanted the rest of the world (i.e., the US) to adopt it, and the way to do this was to have it adopted as an ISO Standard. The experience of making this happen convinced the folk at BSI that in future, language standards should be produced as an international effort within ISO (those pesky Americans wanted changes made to the document before they would vote for it).
During the creation of the first C Standard various people from Europe joined the ANSI committee, X3J11, so they could take part. Initially the US members were not receptive to the European request for a mechanism to handle keyboards that did not contain certain characters (e.g., left/right square brackets) but responded promptly on hearing that those (pesky) Europeans planned to publish an ISO C Standard that would contain those changes to the ANSI Standard needed to support trigraphs; the published ANSI Standard included support for trigraphs. The C ANSI committee were very receptive to the idea of future work being done at the ISO level; Bill Plauger/Tom Plum did a lot of good work to ensure it happened.
The C++ language came along and long story short an ISO committee was set up to create an ISO Standard for it, then Java came along and the Java Study Group failed to become an ISO committee and then various non-specific language committees happened.
A look at the SC22 website shows that ISO Standards exist for Forth and ECMAscript (it has not yet been updated to include Ruby) with no corresponding ISO committees. What is going on?
One could be cynical and say that special interests are getting a document of their choosing accepted by ECMA and then abusing the ISO fast track procedure to sidestep the need to set up an international committee that has the authority to create a document of its choosing. The reality is that unless a language is very widely used by lots of people (e.g., in the top five or so most commonly used languages) there are unlikely to be enough people (or employers) willing and able to commit the time and money needed to be actively involved in an ISO Standard committee.
Once a document has been fast tracked to become ISO Standard, any updates to it are supposed to be carried out under ISO rules (i.e., an ISO committee). In practice this is not happening with ECMAscript which continues to be very active (I don’t know what is happening with Forth or how the Ruby people plan to handle any updates), holding bi-monthly meetings; over the years they have fast tracked two revisions to the original fast tracked document (the UK did raise the issue during balloting but nothing came of it, I don’t think anybody really cares).
Would moving the ECMAscript development work from ECMA to ISO make a worthwhile difference? There might be a few people out there who would attend an ISO meeting who are not currently attending ECMA meetings (to join ECMA companies with five or fewer employees pay an annual fee of 3,500 Swiss francs {about the same number of US dollars} and larger companies pay a lot more) but I suspect the number would not be large enough to make up for the extra hassle of running an ISO committee (e.g., longer ISO balloting timescales).
Production of programming language standards is really a cottage industry that relies on friends in high places (e.g., companies with an existing membership of ECMA or connections into the local country standards’ body) for them to appear on the international stage.
My no loops in R hair shirt
Being professionally involved with analyzing source code, I get to work with a much larger number of programming languages than most people. There is a huge difference between knowing the intricate details of the semantics of a language and being able to fluently program in a language like a native developer. There are languages whose semantics I probably know better than nearly all its users and yet can only code in like a novice, and there are languages whose reference manual I might have read once and yet can write fluently.
I try not to learn new languages in which to write programs, they just clutter my brain. It can be very embarrassing having somebody sitting next to me while I write an example and not be able to remember whether the language I am using requires a then in its if-statement or getting the details of a print statement wrong; I am supposed to be a computer language expert.
Having decided to migrate from being a casual R user to being a native user (my current status is somebody who owns more than 10 books that make extensive use of R) I resolved to invest the extra time needed to learn how to write code the ‘R-way’ (eighteen months later I’m not sure that there is an ‘R way’ in the sense that could be said to exist in other languages, or if there is it is rather diffuse). One of my self-appointed R-way rules is that any operation involving every element of a vector should be performed using whole vector operations (i.e., no looping constructs).
Today I was analyzing the release history of the Linux kernel and wanted to get the list of release dates for the current version of the major branch; I had a list of dates for every release. The problem is that when a major release branch is started previous branches, now in support only mode, may continue to be maintained for some time, for instance after the version 2.3 branch was created the version 2.2 branch continued to have releases made for it for another five years.
The obvious solution to removing non-applicable versions from the release list is to sort on release date and then loop through the elements, removing those whose version number was less than the version appearing before them in the list. In the following excerpt the release of 2.3.0 causes the following 2.2.9 release to be removed from the list, also versions 2.0.37 and 2.2.10 should be removed.
Version Release_date 2.2.8 1999-05-11 2.3.0 1999-05-11 2.2.9 1999-05-13 2.3.1 1999-05-14 2.3.2 1999-05-15 2.3.3 1999-05-17 2.3.4 1999-06-01 2.3.5 1999-06-02 2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 2.3.8 1999-06-22 |
While this is an easy problem to solve using a loop, what is the R-way of solving it (use the xyz package would be the answer half said in jest)? My R-way rule did not allow loops, so a-head scratching I did go. On the assumption that the current branch version dates would be intermingled with releases of previous branches I decided to use simple pair-wise comparison (which could be coded up as a whole vector operation); if an element contained a version number that was less than the element before it, then it was removed.
Here is the code (treat step parameter was introduced later as part of the second phase tidy up; data here):
ld=read.csv("/usr1/rbook/examples/regression/Linux-days.csv") ld$Release_date=as.POSIXct(ld$Release_date, format="%d-%b-%Y") ld.ordered=ld[order(ld$Release_date), ] strip.support.v=function(version.date, step) { # Strip off the least significant value of the Version id v = substr(version.date$Version, 1, 3) # Build a vector of TRUE/FALSE indicating ordering of element pairs q = c(rep(TRUE, step), v[1:(length(v)-step)] <= v[(1+step):length(v)]) # Only return TRUE entries return (version.date[q, ]) } h1=strip.support.v(ld.ordered, 1) |
This pair-wise approach only partially handles the following sequence (2.2.10 is greater than 2.0.37 and so would not be removed).
2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 |
The no loops rule prevented me iterating over calls to strip.support.v until there were no more changes.
Would a native R speaker assume there would not be many extraneous Version/Release_date pairs and be willing to regard their presence as a minor data pollution problem? If so, I have some way to go before I might be able to behave as a native.
My next line of reasoning was that any contiguous sequence of non-applicable version numbers would probably be a remote island in a sea of applicable values. Instead of comparing an element against its immediate predecessor, it should be compared against an element step back (I chose a value of 5).
h2=strip.support.v(h1, 5) |
The original vector contained 832 rows, which was reduced to 745 and then down to 734 on the second step.
Are there any non-loop solutions that are capable of handling a higher density of non-applicable values? Do tell if you can think of one.
Update (a couple of days later)
Thanks to Charles Lowe, Wojtek and kaz_yos for their solutions using cummax, a function that I was previously unaware of. This was a useful reminder that what other languages do in the syntax/semantics R surprisingly often does via a function call (I’m still getting my head around the fact that a switch-statement is implemented via a function in R); as a wannabe native R speaker I need to remove my overly blinked language approach to problems and learn a lot more about the functions that come as part of the base system
Success does not require understanding
I took part in the second Data Science London Hackathon last weekend (also my second hackathon) and it was a very different experience compared to the first hackathon. Once again Carlos and his team really looked after us.
- The data was released 24 hours before the competition started and even though I had spent less than half an hour looking at it, at the start of the competition I did not feel under any time pressure; those 24 hours allowed me to get used to the data and come up with some useful looking ideas.
- The instructions for the first competition had suggested that people form teams of 3-5 and there was a lot of networking happening before the start time. There was no such suggestion this time and as I networked around looking for people to work with I was surprised by the number of people who wanted to work alone; Jonny and Kannappan were the only members from my previous team (the Outliers) who had entered this event, with Kannappan wanting to work alone and Jonny joining me to create a two person team.
- There was less community spirit this time, possible reasons include a lot more single person teams sitting in the corner doing their own thing, fewer people attending (it is the middle of the holiday season), fewer people staying over until the Sunday (perhaps single person teams got disheartened and left or the extra 24 hours of data access meant that teams ran out of ideas/commitment after 36 hours) or me being reduced to a single person team (Jonny had to leave at 20:00) meant I paid more attention to what was happening on the floor.
The problem was to predict what ratings different people would give to various music artists. We were given data involving 50 artists and 48,645 users (artists and users were anonymous) in five files (one contained the training dataset and another the test dataset).
A quick analysis of the data showed that while there were several thousand rows of data per artist there were only half a dozen rows per person, a very sparse dataset.
The most frequent technique I heard mentioned during my initial conversations with attendees was machine learning. In my line of work I am constantly trying to understand what is going on (the purpose of this understanding is to control and make things better) and consider anybody who uses machine learning as being clueless, dim witted or just plain lazy; the problem with machine learning is that it gives answers without explanations (ok decision trees do provide some insights). This insistence on understanding turned out to be my major mistake, the competition metric is based on correctness of answers and not on how well a competitor understands the problem domain. I had a brief conversation with a senior executive from EMI (who supplied the dataset and provided some of the sponsorship money) who showed up on Sunday morning and he had no problem with machine learning providing answers and not explanations.
Having been overly ambitious last time team Outliers went for extreme simplicity and started out with the linear model glm(Rating ~ AGE + GENDER...) being built for each artist (i.e., 50 models). For a small amount of work we got a score of just over 21 and a place of around 70th on the leader board, now we just needed to include information along the lines of “people who like Artist X also like Artist Y”. Unfortunately the only other member of my team (who did not share my view of machine learning and knew something about it) had a prior appointment and had to leave me consuming lots of cpu time on a wild goose chase that required me to have understanding.
The advantages of being in a team include getting feedback from other members (e.g., why are you wasting your time doing that, look how much better this approach is) and having access to different skill sets (e.g., knowing what magic pixie dust values to use for the optional parameters to machine learning routines). It was Sunday morning before I abandoned the ‘understanding’ approach and started thrashing around using various machine learning techniques, which told me that people demographics (e.g., age and gender) were not particularly good predictors compared to other data but did did not reduce my score to the 13-14 range that could be seen on the leader board’s top 20.
Realizing that seven hours was not enough time to learn how to drive R’s machine learning packages well enough to get me into the top ten, I switched tack and spent a lot more time wandering around chatting to people; those whose score was worse than mine were generally willing to chat. Some had gotten completely bogged down in data cleaning and figuring out how to handle missing data (a subject rarely covered in books but of huge importance in real life), I was surprised to find one team doing most of their coding in SQL (my suggestion to only consider Age+Gender improved their score from 35 to 22), I mocked the people using Clojure (people using a Lisp derived language think they have discovered the one true way and will suffer from self doubt if they are not mocked regularly). Afterwards it struck me that well over 50% of attendees were not British (based on their accents), was this yet another indicator of how far British Universities had dumbed down mathematics teaching that natives did not feel up to the challenge (well done to the Bristol undergraduate who turned up) or were the most gung-ho technical folk in London those who had traveled here to work from abroad?
The London winner was Dell Zhang, the only other person sitting at the table I was on (he sat opposite me throughout the competition), who worked quietly away for the whole 24 hours and seemed permanently unimpressed by the score he was achieving; he described his technique as “brute force random forest using Python (the source will be made available on the Data Science website).
Reading through posts made by competitors after the event was as interesting as last time. Factorization Machines seems to be the hot new technique for making predictions based on very sparse data and the libFM is the software I needed to know about last weekend (no R package providing an interface to this C++ code available yet).
Why does Coverity restrict who can see its tool output?
Coverity generate a lot of publicity from their contract (started under a contract with the US Department of Homeland Security, don’t know if things have changed) to scan large quantities of open source software with their static analysis tools and a while back I decided to have a look at the warning messages they produce. I was surprised to find that access to the output required singing a non-disclosure agreement, this has subsequently been changed to agreeing to a click-through license for the basic features and signing a NDA for access to advanced features. Were Coverity limiting access because they did not want competitors learning about new suspicious constructs to flag, or because they did not want potential customers seeing what a poor job their tool did?
The claim that access “… for most projects is permitted only to members of the scanned project, partially in order to ensure that potential security issues may be resolved before the public sees them.” does not really hold much water. Anybody interested in finding security problems in code could probably find hacked versions of various commercial static analysis tools to download. The SAMATE – Software Assurance Metrics And Tool Evaluation project runs yearly evaluations of static analysis tools and makes the results publicly available.
A recent blog post by Andy Chou, Coverity’s CTO, added weight to the argument that their Scan tool is rather run-of-the-mill. The post discussed a new check that had recently been added flagging occurrences of memcmp, and related standard library functions, that were being tested for equality (or inequality) with specific integer constants (these functions are defined to return a negative or positive value or 0, and while many implementations always return the negative value -1 and the positive value 1 a developer should always test for the property of being negative/positive and not specific values that have that property). Standards define library functions to have a wide variety of different properties, and tools that check for correct application of these properties have been available for over 15 years.
My experience of developer response, when told that some library function is required to return a negative value and some implementation might not return -1, is that they regard any implementation not returning -1 as being ‘faulty’ since all implementations in their experience return -1. I imagine that library implementors are aware of this expectation and try to meet it. However, optimizing compilers often try to automatically inline calls to memcpy and related copy/compare functions and will want to take advantage of the freedom to return any negative/positive value if it means not having to perform a branch test (a big performance killer on most modern processors).
Undefined behavior can travel back in time
The committee that produced the C Standard tried to keep things simple and sometimes made very short general statements that relied on compiler writers interpreting them in a ‘reasonable’ way. One example of this reliance on ‘reasonable’ behavior is the definition of undefined behavior; “… erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The wording in the Standard permits a compiler to process the following program:
int main(int argc, char **argv) { // lots of code that prints out useful information 1 / 0; // divide by zero, undefined behavior } |
to produce an executable that prints out “yah boo sucks”. Such behavior would probably be surprising to the developer who expected the code printing the useful information to be executed before the divide by zero was encountered. The phrase quality of implementation is heard a lot in committee discussions of this kind of topic, but this phrase does not appear in any official document.
A modern compiler is essentially a sophisticated domain specific data miner that happens to produce machine code as output and compiler writers are constantly looking for ways to use the information extracted to minimise the code they generate (minimal number of instructions or minimal amount of runtime). The following code is from the Linux kernel and its authors were surprised to find that the “division by zero” messages did not appear when arg2 was 0, in fact the entire if-statement did not appear in the generated code; based on my earlier example you can probably guess what the compiler has done:
if (arg2 == 0) ereport(ERROR, (errcode(ERRCODE_DIVISION_BY_ZERO), errmsg("division by zero"))); /* No overflow is possible */ PG_RETURN_INT32((int32)arg1 / arg2); |
Yes, it figured out that when arg2 == 0 the divide in the call to PG_RETURN_INT32 results in undefined behavior and took the decision that the actual undefined behavior in this instance would not include making the call to ereport which in turn made the if-statement redundant (smaller+faster code, way to go!)
There is/was a bug in Linux because of this compiler behavior. The finger of blame could be pointed at:
- the developers for not specifying that the function
ereportdoes not return (this would enable the compiler to deduce that there is no undefined behavior because the divide is never execute whenarg2 == 0), - the C Standard committee for not specifying a timeline for undefined behavior, e.g., program behavior does not become undefined until the statement containing the offending construct is encountered during program execution,
- the compiler writers for not being ‘reasonable’.
In the coming years more and more developers are likely to encounter this kind of unexpected behavior in their programs as compilers do more and more data mining and are pushed to improve performance. Other examples of this kind of behavior are given in the paper Undefined Behavior: Who Moved My Code?
What might be done to reduce the economic cost of the fallout from this developer ignorance/standard wording/compiler behavior interaction? Possibilities include:
- developer education: few developers are aware that a statement containing undefined behavior can have an impact on the execution of code that occurs before that statement is executed,
- change the wording in the Standard: for many cases there is no reason why the undefined behavior be allowed to reach back in time to before when the statement executing it is executed; this does not mean that any program output is guaranteed to occur, e.g., the host OS might delete any pending output when a divide by zero exception occurs.
- paying gcc/llvm developers to do front end stuff: nearly all gcc funding is to do code generation work (I don’t know anything about llvm funding) and if the US Department of Homeland security are interested in software security they should fund related front end work in gcc and llvm (e.g., providing developers with information about suspicious usage in the code being compiled; the existing
-Wallis a start).
Ternary radix will have to wait for photonic computers
Computer cpu economics suggest that a ternary radix representation rather than binary should be used for representing integer values. The economic cost of a cpu is is roughly proportional to  , where
, where  is the integer radix and
is the integer radix and  is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is
is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is  .
.
If we fix the maximum representable value  and ask which value of minimises , then we need to differentiate
and ask which value of minimises , then we need to differentiate  w.r.t. , giving
w.r.t. , giving ^2})") and this equals 0 when
and this equals 0 when  (the closest integer to
(the closest integer to  is 3).
is 3).
The following plot shows the maximum representable value (right point of horizontal line) that can be achieved for a given ‘cost’ when the radix is 2 and 3.
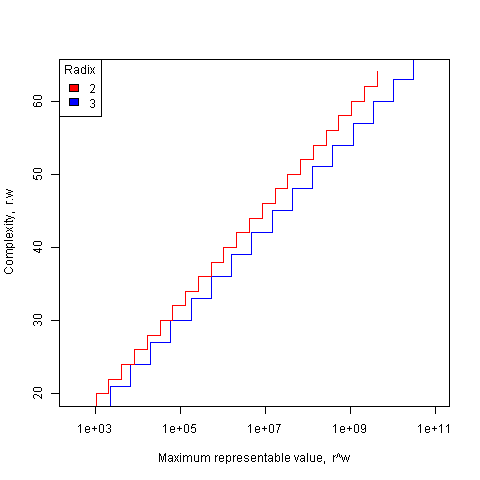
The reason binary is used in practice is purely to do with the characteristics of power consumption in electronic switching circuits (originally vacuum tube and then transistor based). Electrical power is proportional to voltage times current and a binary circuit can be implemented by switching between states where either the voltage or the current is very small, in either of these two states the power consumption is very low; it is only during the very short transition period switching between them, when the voltage and current have intermediate values, that the power consumed is relatively high. A 3-state switch would need a voltage/current combination denoting a state other than 0/1, and any such combination would consume non-trivial amounts of power (tri-state devices are used in some situations).
I have little idea about the complications of storing ternary values in memory systems, but I guess there will be complications.
In the 1960’s the Setun computer used a ternary radix and there has been the odd experimental systems since.
Are there any kinds of switching circuit whose use is not primarily dictated by device power characteristics and hence might be used to support a ternary radix? One possibility is a light based cpu (i.e., using photons rather than electrons), using polarization to specify state has been proposed. What about storage? Using Josephson junctions could provide the high speed and low power consumption required (we just need somebody to discover a room temperature superconductor).
The technology needed to build a practical cpu using a ternary radix appears to be some years in the future.
What about all the existing code containing a myriad of dependencies on the characteristics of two’s complement integer representation? If a photonic cpu became available that was ten times faster than existing cpus, or consumed 10 times less power or some combination thereof, then I’m sure here would be plenty of economic incentive to get software running on it. The problem is that 10 times better cpus are unlikely to just turn up, they will probably need to be developed in steps and the economics of progressing from step to step don’t look good.
While our civilization is likely to continue on down the binary rabbit hole, another one may have started down, or switched to, the ternary hole. I hope the SETI people are not to blinkered by the binary view of the universe.
Impact of hardware characteristics on detectable fault behavior
Preface. This is the first of what I hope will be many posts analysing experimental data, that will eventually end up in my empirical software engineering with R book (this experiment was chosen because it happens to be the one I am currently working on; having just switched to using Asciidoc I have a backlog of editing to do on previously written analysis, also I have to figure out a way to fix [bracketed words]).
Don’t worry if you don’t know anything about the statistics used. I am aiming to provide information to meet the needs of two audiences (whether or not I fail on both counts remains to be seen):
- Those who want to some idea of what facts are known about a particular software engineering topic. Hopefully reading the introduction+conclusion will enable these readers to form an opinion about the current state of knowledge (taking my statistical analysis on trust).
- Those who are looking for ideas that can be used to analyse a problem they are trying to solve. Hopefully, somewhere among my many analyses will be something that looks like it could be applied to the reader’s problem and motivates them to go off and learn something about the statistics (if they are not already familiar with it; once written the book will obviously help out here).
Forward. The following analysis produces a negative result, something that happens a lot in experiments in all fields of research. It has been included to illustrate the importance of checking the statistical power of an experiment, i.e., how likely the experiment will detect an effect if one is present; it is very easy to fall into the trap of thinking that because lots of tests were done any effect that exists will be detected.
The authors ran an interesting experiment which as far as I know is the only published empirical analysis of intermittent software faults (please let me know if you are aware of other work) and made some mistakes in their statistical analysis. I have made plenty of mistakes in experiments I have run, some of which have found there way into the published write up. The key attribute of an experimentalist is to learn and move on.
A fault does not always noticeably change the behavior of a program when it is executed, apparently correct program execution can occur in the presence of serious faults.
A study by Syed, Robinson and Williams <book Syed_10> investigated how the number of noticeable failures caused by known faults in Mozilla’s Firefox browser varied with processor speed, system memory, hard disc size and system load. A total of 11 known faults causing intermittent failure were selected and nine different hardware configurations were selected. The conditions required to exhibit each fault were replicated and Firefox was executed 10 times for each of hardware configuration, counting the number of noticeable program failures; the seven faults and nine hardware configurations listed in the table below generated a total of 10*7*9 = 630 different executions (four faults either always or never resulted in an observed failure during the 10 runs).
Data
The following table contains the observed number of failures of Firefox for the given fault number when run on the specified hardware configuration.
| Mhz-Mb-Gb | 124750 | 380417 | 410075 | 396863 | 494116 | 264562 | 332330 |
|---|---|---|---|---|---|---|---|
|
667-128-2.5 |
4 |
10 |
6 |
5 |
2 |
3 |
5 |
|
667-256-10 |
4 |
8 |
8 |
6 |
4 |
3 |
8 |
|
667-1000-2.5 |
4 |
7 |
3 |
4 |
3 |
1 |
8 |
|
1000-128-10 |
3 |
10 |
3 |
6 |
0 |
1 |
1 |
|
1000-256-2.5 |
3 |
9 |
0 |
6 |
0 |
1 |
2 |
|
1000-1000-10 |
2 |
9 |
4 |
5 |
0 |
0 |
1 |
|
2000-128-2.5 |
0 |
10 |
5 |
6 |
0 |
0 |
0 |
|
2000-256-10 |
2 |
8 |
5 |
7 |
0 |
0 |
0 |
|
2000-1000-10 |
1 |
7 |
3 |
5 |
0 |
0 |
0 |
Predictions made in advance
There is no prior theory suggesting how the selected hardware characteristics might influence the outcome from this experiment. The analysis is based on searching for a pattern in the results and so the significance level needs to be adjusted to take account of the number of possible patterns that could exist (e.g., using the [Bonferroni correction]).
If we simplify the failure counts by labelling them as one of Low/Medium/High, then there are two arrangements of the failure counts (i.e., low/medium/high and high/medium/low) that would result in a strong correlation for cpu_speed, two arrangements for memory and two for disc size; a total of 6 combinations that would result in a strong correlation being found.
The [Bonferroni correction] adjusts the significance level by dividing by the number of tests, in this case 0.05/6 = 0.0083.
If the failure counts occurred in a random order what is the probability of a strong correlation between failure count and one of the hardware attributes being found? Based on the Low/Medium/High labelling scheme there are 9!/(3! 3! 3!) = 1680 combinations of these counts over 9 slots, giving a 1 in 1680/6 = 280 chance of purely random behavior producing a strong correlation.
The experiment investigated the characteristics of 11 faults. If there is a 1 in 280 chance of finding a strong correlation when analyzing one fault there is approximately a 1 in 24 chance of finding at least one strong correlation when analysing 11 different faults.
Response variable
The response variable takes the form of a proportion whose value varies between 0 and 1, the number of failures out of 10 executions.
Applicable techniques
The following techniques might be used to analyse this data:
- [Factorial design]. This is a way of organizing experiment configurations that is designed to extract the most information for the total number of program runs made. It would be inefficient not to use the results from some hardware configurations just because they are not needed in the factorial design and no results are available for some configurations required by a factorial design (or a [Plackett-Burman] design).
-
Fitting the data using a linear model. A standard linear model, created using R’s lm function, would not be appropriate because of the following two problems:
- this kind of model is likely to make predictions that fall outside the range 0 to 1, something that cannot happen for proportional data,
- this approach assumes that the variance is constant across measurements and unless the proportions involved are very close to each other this requirement will not be met ([proportional data] from a [binomial distribution] has variance p(1-p)).
However, a generalised linear model would not suffer from these problems. There are several [link functions] that could be used:
- the Poisson distribution, is widely used for modelling faults but requires that the mean and variance have the same value, a property that does not apply to proportional data.
- the Binomial distribution, can handle data having the characteristics present here.
The proportional data is specified in the call to the glm function by having the response variable contain two columns, one containing the number of failures (that is what is being predicted in this case) and the other the number of non-failures. The code looks something like the following (see complete example and data):
y=cbind(fail_count, 10-fail_count) glm(y ~ cpu_speed+memory+disk_size, data=ff_data, family=binomial) |
In this kind of GLM it is assumed that the [residual deviance] is the same as the [residual degrees of freedom]. If the residual deviance is greater than the residual degrees of freedom then [overdispersion] has occurred, which happens for fault 380417. To handle overdispersion the family needs to be changed from binomial to quasibinomial, which in the case of fault 380417 changes the p-value of the fit from 0.0348 to 0.0749.
The analysis of each fault finds that only one of them, 332330, has a significance level within the specified acceptable bounds; this has a negative correlation with CPU speed (i.e., observed failures decrease with clock speed).
With only one faults found to have any significant hardware configuration effects we have to ask about the probability of this experiment finding an effect if one was present.
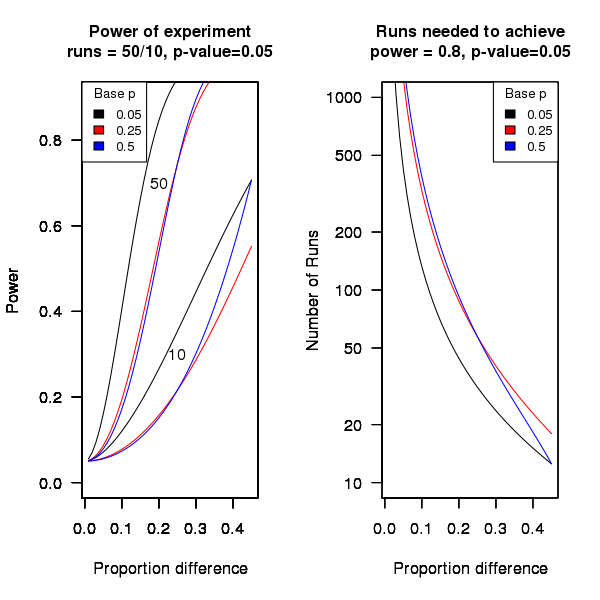
An analysis of the [statistical power] of an experiment investigating the difference between proportions for two hardware configurations (i.e., the percentage of observed failures) needs to know the value of those proportions, the number of runs (10 in this case) and the desired p-value (0.05); to simplify things the plot below is based on using the value of the lowest proportion and the difference between it and the higher proportion. The left plot shows the power achieved (y-axis) there does exist a given difference in proportions (x-axis), the three lowest proportions of 0.05, 0.25 and 0.5 are shown (the result is symmetric about 0.5 and so the plot for 0.75 and 0.95 would be the same as 0.25 and 0.05 respectively), and where there were 10 and 50 runs involving the same fault case.
It can be seen that unless a change in the hardware configuration causes a large change in the number of visible failures then the chance of a difference being detected in results from 10 runs is well below 0.5 (i.e., less than a 50% chance of detecting a difference at a p-value of 0.05 or better).
The right plot in the figure gives the number of runs that need to be made to have a 80% chance of detecting, between two different hardware configurations, the difference in proportion listed on the x-axis, at a significance of 0.05.
It can be seen that if hardware charactersitics account for only 10% of the difference in failure rate over 100 runs would be needed to detect it.
Conclusion
Faults in Firefox that caused intermittent failures were investigated looking for a correlation with system cpu speed, memory or disc size. One fault showed a strong correlation with cpu speed (there is a 1 in 24 chance that one of the investigated faults would have some kind of strong correlation). This experiment may not have found a significant correlation between observed failure rate and hardware configuration because the number of separate runs for each fault (i.e., 10) had [low power].
Trying to sell analysis tools to the Nuclear Regulatory Commission
Over the last few days there has been an interesting, and in places somewhat worrying, discussion going on in the Safety Critical mailing list about the US Nuclear Regulatory Commission. I thought I would tell my somewhat worrying story about dealing with the NRC.
In 1996 the NRC posted a request for information for a tool that I thought my company stood a reasonable chance of being able to meet (“NRC examines source code in nuclear power plant safety systems during the licensing process. NRC is interested in finding commercially available tools that can locate and provide information about the following programming practices…”). I responded, answered the questions on the form I received and was short listed to make a presentation to the NRC.
The presentation took place at the offices of National Institute of Standards and Technology, the government agency helping out with the software expertise.
From our brief email exchanges I had guessed that nobody at the NRC/NIST end knew much about C or static analysis. A typical potential customer occurrence that I was familiar with handling.
Turned up, four or so people from NRC+one(?) from NIST, gave a brief overview and showed how the tool detected the constructs they were interested in, based on test cases I had written after reading their requirements (they had not written any but did give me some code that they happened to have, that was, well, code they happened to have; a typical potential customer occurrence that I was familiar with handling).
Why did the tool produce all those messages? Well, those are the constructs you want flagged. A typical potential customer occurrence that I was familiar with handling.
Does any information have to be given to the tool, such as where to find header files (I knew that they had already seen a presentation from another tool vendor, these managers who appeared to know nothing about software development had obviously picked up this question from that presentation)? Yes, but it is very easy to configure this information… A typical potential customer occurrence that I was familiar with handling.
I asked how they planned to use the tool and what I had to do to show them that this tool met their requirements.
We want one of our inspectors to be able turn up at a reactor site and check their source code. The inspector should not need to know anything about software development and so the tool must be able to run automatically without any options being given and the output must be understandable to the inspector. Not a typical potential customer occurrence and I had no idea about how to handle it (I did notice that my mouth was open and had to make a conscious effort to keep it closed).
No, I would not get to see their final report and in fact I never heard from them again (did they find any tool vendor who did not stare at them in disbelief?)
The trip was not a complete waste of time, a few months earlier I had been at a Java study group meeting (an ISO project that ultimately failed to convince Sun to standarize Java through the ISO process) with some NIST folk who worked in the same building and I got to chat with them again.
A few hours later I realised that perhaps the question I should have asked was “What kind of software are people writing at nuclear facilities that needs an inspector to turn up and check?”
Background to my book project “Empirical Software Engineering with R”
This post provides background information that can be referenced by future posts.
For the last 18 months I have been working in fits and starts on a book that has the working title “Empirical Software Engineering with R”. The idea is to provide broad coverage of software engineering issues from an empirical perspective (i.e., the discussion is driven by the analysis of measurements obtained from experiments); R was chosen for the statistical analysis because it is becoming the de-facto language of choice in a wide range of disciplines and lots of existing books provide example analysis using R, so I am going with the crowd.
While my last book took five years to write I had a fixed target, a template to work to and a reasonably firm grasp of the subject. Empirical software engineering has only really just started, the time interval between new and interesting results appearing is quiet short and nobody really knows what statistical techniques are broadly applicable to software engineering problems (while the normal distribution is the mainstay of the social sciences a quick scan of software engineering data finds few occurrences of this distribution).
The book is being driven by the empirical software engineering rather than the statistics, that is I take a topic in software engineering and analyse the results of an experiment investigating that topic, providing pointers to where readers can find out more about the statistical techniques used (once I know which techniques crop up a lot I will write my own general introduction to them).
I’m assuming that readers have a reasonable degree of numeric literacy, are happy dealing with probabilities and have a rough idea about statistical ideas. I’m hoping to come up with a workable check-list that readers can use to figure out what statistical techniques are applicable to their problem; we will see how well this pans out after I have analysed lots of diverse data sets.
Rather than wait a few more years before I can make a complete draft available for review I have decided to switch to making available individual parts as they are written, i.e., after writing a draft discussion and analysis of each experiment I will published it on this blog (along with the raw data and R code used in the analyse). My reasons for doing this are:
- Reader feedback (I hope I get some) will help me get a better understanding of what people are after from a book covering empirical software engineering from a statistical analysis of data perspective.
- Suggestions for topics to cover. I am being very strict and only covering topics for which I have empirical data and can make that data available to readers. So if you want me to cover a topic please point me to some data. I will publish a list of important topics for which I currently don’t have any data, hopefully somebody will point me at the data that can be used.
- Posting here will help me stay focused on getting this thing done.
Links to book related posts
Distribution of uptimes for high-performance computing systems
Break even ratios for development investment decisions
Agreement between code readability ratings given by students
Changes in optimization performance of gcc over time
Descriptive statistics of some Agile feature characteristics
Impact of hardware characteristics on detectable fault behavior
Prioritizing project stakeholders using social network metrics
Preferential attachment applied to frequency of accessing a variable
Amount of end-user usage of code in Firefox
How many ways of programming the same specification?
Ways of obtaining empirical data in software engineering
What is the error rate for published mathematical proofs?
Changes in the API/non-API method call ratio with program size
Honking the horn for go faster memory (over go faster cpus)
How to avoid being a victim of Brooks’ law
Evidence for the benefits of strong typing, where is it?
Hardware variability may be greater than algorithmic improvement
Extracting the original data from a heatmap image
Entropy: Software researchers go to topic when they have no idea what else to talk about
Recent Comments