Archive
Academic recognition for creating and supporting software
A scientific paper is supposed to contain enough information that somebody skilled in the field can perform the experiment(s) described therein (issues around the money needed to obtain access to the necessary equipment tend to be side stepped). In addition to the skills generally taught within a field, every niche has its specific skill set, which for leading edge research may only be available in one lab.
Bespoke software has become an essential component of many research projects, and the ability to reimplement the necessary software is rarely considered to be a necessary skill. Some researchers consider software to be “just code” whose creation is not really a skill that is worth investing in acquiring.
There is a widespread belief in academic circles that the solution to the issues created by bespoke software is for researchers to release the source code of the software they create.
Experienced developers will laugh at the idea that once the source code is available, running it is straight forward. Figuring out how to run somebody else’s code can be a very time-consuming process, particularly when the person who wrote it is relatively inexperienced.
This post is about the social issues around the bespoke research code being made available, and not the technical issues likely to be encountered in building it on another researcher’s computer.
Lots of researchers do make their code available, without being asked, and some researchers actively promote the software they have written. In a few cases, active software ecosystems have sprung up around a research topic, e.g., Astropy and SunPy.
However, a lot of code never gets released. Based on my own experience of asking for code (in the last 10 years, most of my requests have been for data), reasons given by researchers for not making the code they have written available to others, include:
- not replying to email requests for the code,
- not sure that they still have the all code, which is taken as a reason for not sending what they have. This may also be a cover story for another reason they don’t want to admit to,
- they don’t want the hassle of supporting other users of the code. Having received some clueless requests for help on software I have released, I have sympathy for this position. Sometimes pointing out that I am an experienced developer who does not need support, works, other times it just changes the reason given,
- they think the code is poorly written, and that this poor of quality will make them look bad. Pointing out that research code is leading edge (rare true, it’s an attempt to stroke their ego), and not supposed to be polished, rarely works for me. Some people are just perfectionists, with a strong aversion to showing others anything that has not been polished to death,
- a large investment was made to create the software, and they want to reap all the benefits. I have a lot of sympathy with this position. Some research fields are very competitive, or sometimes the researcher just wants to believe that they really will get another grant to work on the subject.
Researchers who create and support research software complain that they don’t get any formal recognition for this work; which begs the question: why are you working on this software when you know that you are unlikely to receive any recognition?
How might researchers receive recognition for writing, supporting and releasing code?
Citations to published papers are a commonly used technique for measuring the worth of the work done by a researcher (this metric is used when evaluating people for promotion, awarding grants, and evaluating departments), and various organizations are promoting the use of citations for software.
Some software provides enough benefits that the authors can write a conventional paper about it, e.g., a paper on Astropy (which does not cite any of the third-party packages used in its own implementation). But a lot of research software does not have sufficient general appeal to warrant a paper.
Are citations for software a good idea?
An important characteristic of any evaluation metric is how hard it is to fake a good score.
Research papers are rated by the journal in which they are published, with each journal having its own rating (a short-term metric), and the number of times the paper is cited (a longer-term metric). Papers are reviewed, with many failing to be accepted (at least by the higher quality journals; there are so-called predatory journals that will publish anything for a fee).
While there are a few journals where source code may be an integral component of a paper, most research software is published on sites having minimal acceptance criteria, e.g., Github.
Will citations to software become as commonplace as citations to other papers?
I regularly read software papers that cites software packages, but this practice is a long way from being common.
Will those awarding job promotions and grants start to include software creation as having a status comparable to published papers? We will have to wait and see.
Will the lure of recognition via citations increase the quantity of source being released?
I don’t think it will have any impact until the benefits of software citations are seen to be worthwhile (which may be many years away).
Evidence-based SE groups doing interesting work, 2021 version
Who are the research groups currently doing interesting work in evidenced-base software engineering (academics often use the term empirical software engineering)? Interestingness is very subjective, in my case it is based on whether I think the work looks like it might contribute something towards software engineering practices (rather than measuring something to get a paper published or fulfil a requirement for an MSc or PhD). I last addressed this question in 2013, and things have changed a lot since then.
This post focuses on groups (i.e., multiple active researchers), and by “currently doing” I’m looking for multiple papers published per year in the last few years.
As regular readers will know, I think that clueless button pushing (a.k.a. machine learning) in software engineering is mostly fake research. I tend to ignore groups that are heavily clueless button pushing oriented.
Like software development groups, research groups come and go, with a few persisting for many years. People change jobs, move into management, start companies based on their research, new productive people appear, and there is the perennial issue of funding. A year from now, any of the following groups may be disbanded or moved on to other research areas.
Some researchers leave a group to set up their own group (even moving continents), and I know that many people in the 2013 survey have done this (many in the Microsoft group listed in 2013 are now scattered across the country). Most academic research is done by students studying for a PhD, and the money needed to pay for these students comes from research grants. Some researchers are willing to spend their time applying for grants to build a group (on average, around 40% of a group’s lead researcher’s time is spent applying for grants), while others are happy to operate on a smaller scale.
Evidence-based research has become mainstream in software engineering, but this is not to say that the findings or data have any use outside of getting a paper published. A popular tactic employed by PhD students appears to be to look for what they consider to be an interesting pattern in code appearing on Github, and write a thesis that associated this pattern with an issue thought to be of general interest, e.g., predicting estimates/faults/maintainability/etc. Every now and again, a gold nugget turns up in the stream of fake research.
Data is being made available via personal Github pages, figshare, osf, Zenondo, and project or personal University (generally not a good idea, because the pages often go away when the researcher leaves). There is no current systematic attempt to catalogue the data.
There has been a huge increase in papers coming out of Brazil, and Brazilians working in research groups around the world, since 2013. No major Brazilian name springs to mind, but that may be because I have not noticed that they are Brazilian (every major research group seems to have one, and many of the minor ones as well). I may have failed to list a group because their group page is years out of date, which may be COVID related, bureaucracy, or they are no longer active.
The China list is incomplete. There are Chinese research groups whose group page is hosted on Github, and I have failed to remember that they are based in China. Also, Chinese pages can appear inactive for a year or two, and then suddenly be updated with lots of recent information. I have not attempted to keep track of Chinese research groups.
Organized by country, groups include (when there is no group page available, I have used the principle’s page, and when that is not available I have used a group member page; some groups make no attempt to help others find out about their work):
Belgium (I cite the researchers with links to pdfs)
Brazil (Garcia, Steinmacher)
Canada (Antoniol, Data-driven Analysis of Software Lab, Godfrey and Ptidel, Robillard, SAIL; three were listed in 2013)
China (Lin Chen, Lu Zhang, Minghui Zhou)
Germany (Chair of Software Engineering, CSE working group, Software Engineering for Distributed Systems Group, Research group Zeller)
Greece (listed in 2013)
Italy (listed in 2013)
Japan (Inoue lab, Kamei Web, Kula, and Kusumoto lab)
Spain (the only member of the group listed in 2013 with a usable web page)
Sweden (Chalmers, KTH {Baudry and Monperrus, with no group page})
Switzerland (SCG and REVEAL; both listed in 2013)
USA (Devanbu, Foster, Maletic, Microsoft, PLUM lab, SEMERU, squaresLab, Weimer; two were listed in 2013)
Sitting here typing away, I have probably missed out some obvious candidates (particularly in the US). Suggestions for omissions welcome (remember, this is about groups, not individuals).
Looking for a measurable impact from developer social learning
Almost everything you know was discovered/invented by other people. Social learning (i.e., learning from others) is the process of acquiring skills by observing others (teaching is explicit formalised sharing of skills). Social learning provides a mechanism for skills to spread through a population. An alternative to social learning is learning by personal trial and error.
When working within an ecosystem that changes slowly, it is more cost-effective to learn from others than learn through trial and error (assuming that experienced people are available to learn from, and the learner is capable of identifying them); “Social Learning” by Hoppitt and Layland analyzes the costs and benefits of using social learning.
Since its inception, much of software engineering has been constantly changing. In a rapidly changing ecosystem, the experience of established members may suggest possible solutions that do not deliver the expected results in a changed world, i.e., social learning may not be a cost-effective way of building a skill set applicable within the new ecosystem.
Opportunities for social learning occur wherever developers tend to congregate.
When I started writing software people, developers would print out a copy of their code to take away and correct/improve/add-to (this was when 100+ people were time-sharing on a computer with 256K words of memory, running at 1 MHz). People would cluster around the printer, which ran sufficiently slowly that it was possible, in real-time, to read the code and figure out what was going on; it was possible to learn from others code (pointing out mistakes in programs that people planned to hand in was not appreciated). Then personal computers became available, along with low-cost printers (e.g., dot matrix), which were often shared, and did not print so fast that an experienced developer could not figure things out in real-time. Then laser printers came along, delivering a page at a time every 15 seconds, or so; experiencing the first print out from a Laser printer, I immediately knew that real-time code reading was a thing of the past (also, around this time, full-screen editors achieved the responsiveness needed to enthral developers, paper code listings could not compete). A regular opportunity for social learning disappeared.
Mentoring and retrospectives are intended as explicit (perhaps semi-taught) learning contexts, in which social learning opportunities may be available.
The effectiveness of social learning is dependent on being able to select a good enough source of expertise to learn from. Choosing the person with the highest prestige is a common social selection technique; selecting web pages appearing on the first page of a Google search is actually a form of conformist learning (i.e., selecting what others have chosen).
It is possible to point at particular instances of social learning in software engineering, but to what extent does social learning, other than explicit teaching, contribute to developer skills?
Answering this question requires enumerating all the non-explicitly taught skills a developer uses to get the job done, excluding the non-developer specific skills. A daunting task.
Is it even possible to consistently distinguish between social learning (implicit or taught) and individual learning?
For instance, take source code indentation. Any initial social learning is likely to have been subsequently strongly influenced by peer pressure, and default IDE settings.
Pronunciation of operator names is a personal choice that may only ever exist within a developer’s head. In my head, I pronounce the ^ operator as up-arrow, because I first encountered its use in the book Algorithms + Data Structures = Programs which used the symbol ↑, which appears as the ^ character on modern keyboards. I often hear others using the word caret, which I have to mentally switch over to using. People who teach themselves to program have to invent names for unfamiliar symbols, until they hear somebody speaking code (the widespread availability of teach-yourself videos will make it rare to need for this kind of individual learning; individual learning is giving way to social learning).
The problem with attempting to model social learning is that much of the activity occurs in private, and is not recorded.
One public source of prestigious experience is Stack Overflow. Code snippets included as part of an answer on Stack Overflow appear in around 1.8% of Github repositories. However, is the use of this code social learning or conformist transmission (i.e., copy and paste)?
Explaining social learning to people is all well and good, but having to hand wave when asked for a data-driven example is not good. Suggestions welcome.
Two failed software development projects in the High Court
When submitting a bid, to be awarded the contract to develop a software system, companies have to provide information on costs and delivery dates. If the costs are significantly underestimated, and/or the delivery dates woefully optimistic, one or more of the companies involved may resort to legal action.
Searching the British and Irish Legal Information Institute‘s Technology and Construction Court Decisions throws up two interesting cases (when searching on “source code”; I have not been able to figure out the patterns in the results that were not returned by their search engine {when I expected some cases to be returned}).
The estimation and implementation activities described in the judgements for these two cases could apply to many software projects, both successful and unsuccessful. Claiming that the system will be ready by the go-live date specified by the customer is an essential component of winning a bid, the huge uncertainties in the likely effort required comes as standard in the software industry environment, and discovering lots of unforeseen work after signing the contract (because the minimum was spent on the bid estimate) is not software specific.
The first case is huge (BSkyB/Sky won the case and EDS had to pay £200+ million): (1) BSkyB Limited (2) Sky Subscribers Services Limited: Claimants – and (1) HP Enterprise Services UK Limited (formerly Electronic Data Systems Limited) (2) Electronic Data systems LLC (Formerly Electronic Data Systems Corporation: Defendants. The amount bid was a lot less than £200 million (paragraph 729 “The total EDS “Sell Price” was £54,195,013 which represented an overall margin of 27% over the EDS Price of £39.4 million.” see paragraph 90 for a breakdown).
What can be learned from the judgement for this case (the letter of Intent was subsequently signed on 9 August 2000, and the High Court decision was handed down on 26 January 2010)?
- If you have not been involved in putting together a bid for a large project, paragraphs 58-92 provides a good description of the kinds of activities involved. Paragraphs 697-755 discuss costing details, and paragraphs 773-804 manpower and timing details,
- if you have never seen a software development contract, paragraphs 93-105 illustrate some of the ways in which delivery/payments milestones are broken down and connected. Paragraph 803 will sound familiar to developers who have worked on large projects: “… I conclude that much of Joe Galloway’s evidence in relation to planning at the bid stage was false and was created to cover up the inadequacies of this aspect of the bidding process in which he took the central role.” The difference here is that the money involved was large enough to make it worthwhile investing in a court case, and Sky obviously believed that they could only be blamed for minor implementation problems,
- don’t have the manager in charge of the project give perjured evidence (paragraph 195 “… Joe Galloway’s credibility was completely destroyed by his perjured evidence over a prolonged period.”). Bringing the law of deceit and negligent misrepresentation into a case can substantially increase/decrease the size of the final bill,
- successfully completing an implementation plan requires people with the necessary skills to do the work, and good people are a scarce resource. Projects fail if they cannot attract and keep the right people; see paragraphs 1262-1267.
A consequence of the judge’s finding of misrepresentation by EDS is a requirement to consider the financial consequences. One item of particular interest is the need to calculate the likely effort and time needed by alternative suppliers to implement the CRM System.
The only way to estimate, with any degree of confidence, the likely cost of implementing the required CRM system is to use a conventional estimation process, i.e., a group of people with the relevant domain knowledge work together for some months to figure out an implementation plan, and then cost it. This approach costs a lot of money, and ties up scarce expertise for long periods of time; is there a cheaper method?
Management at the claimant/defence companies will have appreciated that the original cost estimate is likely to be as good as any, apart from being tainted by the perjury of the lead manager. So they all signed up to using Tasseography, e.g., they get their respective experts to estimate the amount of code that needs to be produce to implement the system, calculate how long it would take to write this code and multiply by the hourly rate for a developer. I would loved to have been a fly on the wall when the respective IT experts, all experienced in provided expert testimony, were briefed. Surely the experts all knew that the ballpark figure was that of the original EDS estimate, and that their job was to come up with a lower/high figure?
What other interpretation could there be for such a bone headed approach to cost estimation?
The EDS expert based his calculation on the debunked COCOMO model (ok, my debunking occurred over six years later, but others have done it much earlier).
The Sky expert based his calculation on the use of function points, i.e., estimation function points rather than lines of code, and then multiply by average cost per function point.
The legal teams point out the flaws in the opposing team’s approach, and the judge does a good job of understanding the issues and reaching a compromise.
There may be interesting points tucked away in the many paragraphs covering various legal issues. I barely skimmed these.
The second case is not as large (the judgement contains a third the number of paragraphs, and the judgement handed down on 19 February 2021 required IBM to pay £13+ million): SCIS GENERAL INSURANCE LIMITED: Claimant – and – IBM UNITED KINGDOM LIMITED: Defendant.
Again there is lots to learn about how projects are planned, estimated and payments/deliveries structured. There are staffing issues; paragraph 104 highlights how the client’s subject matter experts are stuck in their ways, e.g., configuring the new system for how things used to work and not attending workshops to learn about the new way of doing things.
Every IT case needs claimant/defendant experts and their collection of magic spells. The IBM expert calculated that the software contained technical debt to the tune of 4,000 man hours of work (paragraph 154).
If you find any other legal software development cases with the text of the judgement publicly available, please let me know (two other interesting cases with decisions on the British and Irish Legal Information Institute).
Electronic Evidence and Electronic Signatures: book
Electronic Evidence and Electronic Signatures by Stephen Mason and Daniel Seng is not the sort of book that I would normally glance at twice (based on its title). However, at this start of the year I had an interesting email conversation with the first author, a commentator who worked for the defence team on the Horizon IT project case, and he emailed with the news that the fifth edition was now available (there’s a free pdf version, so why not have a look; sorry Stephen).
Regular readers of this blog will be interested in chapter 4 (“Software code as the witness”) and chapter 5 (“The presumption that computers are ‘reliable'”).
Legal arguments are based on precedent, i.e., decisions made by judges in earlier cases. The one thing that stands from these two chapters is how few cases have involved source code and/or reliability, and how simplistic the software issues have been (compared to issues that could have been involved). Perhaps the cases involving complicated software issues get simplified by the lawyers, or they look like they will be so difficult/expensive to litigate that the case don’t make it to court.
Chapter 4 provided various definitions of source code, all based around the concept of imperative programming, i.e., the code tells the computer what to do. No mention of declarative programming, where the code specifies the information required and the computer has to figure out how to obtain it (SQL being a widely used language based on this approach). The current Wikipedia article on source code is based on imperative programming, but the programming language article is not so narrowly focused (thanks to some work by several editors many years ago 😉
There is an interesting discussion around the idea of source code as hearsay, with a discussion of cases (see 4.34) where the person who wrote the code had to give evidence so that the program output could be admitted as evidence. I don’t know how often the person who wrote the code has to give evidence, but these days code often has multiple authors, and their identity is not always known (e.g., author details have been lost, or the submission effectively came via an anonymous email).
Chapter 5 considers the common law presumption in the law of England and Wales that ‘In the absence of evidence to the contrary, the courts will presume that mechanical instruments were in order. Yikes! The fact that this is presumption is nonsense, at least for computers, was discussed in an earlier post.
There is plenty of case law discussion around the accuracy of devices used to breath-test motorists for their alcohol level, and defendants being refused access to the devices and associated software. Now, I’m sure that the software contained in these devices contains coding mistakes, but was a particular positive the result of a coding mistake? Without replicating the exact conditions occurring during the original test, it could be very difficult to say. The prosecution and Judges make the common mistake of assuming that because the science behind the test had been validated, the device must produce correct results; ignoring the fact that the implementation of the science in software may contain implementation mistakes. I have lost count of the number of times that scientist/programmers have told me that because the science behind their code is correct, the program output must be correct. My retort that there are typos in the scientific papers they write, therefore there may be typos in their code, usually fails to change their mind; they are so fixated on the correctness of the science that possible mistakes elsewhere are brushed aside.
The naivety of some judges is astonishing. In one case (see 5.44) a professor who was an expert in mathematics, physics and computers, who had read the user manual for an application, but had not seen its source code, was considered qualified to give evidence about the operation of the software!
Much of chapter 5 is essentially an overview of software reliability, written by a barrister for legal professionals, i.e., it is not always a discussion of case law. A barristers’ explanation of how software works can be entertainingly inaccurate, but the material here is correct in a broad brush sense (and I did not spot any entertainingly inaccuracies).
Other than breath-testing, the defence asking for source code is rather like a dog chasing a car. The software for breath-testing devices is likely to be small enough that one person might do a decent job of figuring out how it works; many software systems are not only much, much larger, but are dependent on an ecosystem of hardware/software to run. Figuring out how they work will take multiple (expensive expert) people a lot of time.
Legal precedents are set when both sides spend the money needed to see a court case through to the end. It’s understandable why the case law discussed in this book is so sparse and deals with relatively simple software issues. The costs of fighting a case involving the complexity of modern software is going to be astronomical.
The Approximate Number System and software estimating
The ability to perform simple numeric operations can improve the fitness of a creature (e.g., being able to select which branch contains the most fruit), increasing the likelihood of it having offspring. Studies have found that a wide variety of creatures have a brain subsystem known as the Approximate Number System (ANS).
A study by Mechner rewarded rats with food, if they pressed a lever N times (with N taking one of the values 4, 8, 12 or 16), followed by pressing a second lever. The plot below shows the number of lever presses made before pressing the second lever, for a given required N; it suggests that the subject rat is making use of an approximate number system (code+data):
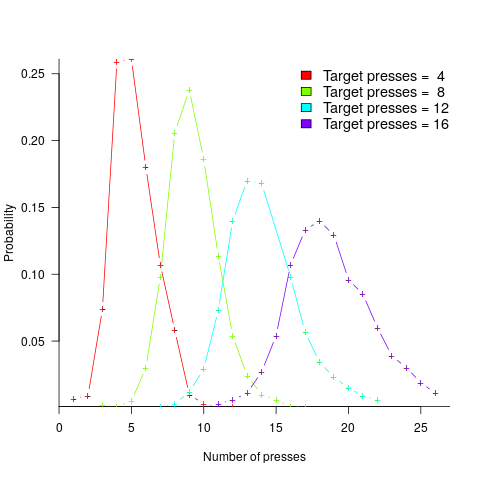
Humans have a second system for representing numbers, which is capable of exact representation, it is language. The Number Sense by Stanislas Dehaene was on my list of Christmas books for 2011.
One method used to study the interface between the two number systems, available to humans, involves subjects estimating the number of dots in a briefly presented image. While reading about one such study, I noticed that some of the plots showed patterns similar to the patterns seen in plots of software estimate/actual data. I emailed the lead author, Véronique Izard, who kindly sent me a copy of the experimental data.
The patterns I was hoping to see are those invariably seen in software effort estimation data, e.g., a power law relationship between actual/estimate, consistent over/under estimation by individuals, and frequent use of round numbers.
Psychologists reading this post may be under the impression that estimating the time taken to implement some functionality, in software, is a relatively accurate process. In practice, for short tasks (i.e., under a day or two) the time needed to form a more accurate estimate makes a good-enough estimate a cost-effective option.
This Izard and Dehaene study involved two experiments. In the first experiment, an image containing between 1 and 100 dots was flashed on the screen for 100ms, and subjects then had to type the estimated number of dots. Each of the six subjects participated in five sessions of 600 trials, with each session lasting about one hour; every number of dots between 1 and 100 was seen 30 times by each subject (for one subject the data contains 1,783 responses, other subjects gave 3,000 responses). Subjects were free to type any value as their estimate.
These kinds of studies have consistently found that subject accuracy is very poor (hardly surprising, given that subjects are not provided with any feedback to help calibrate their estimates). But since researchers are interested in patterns that might be present in the errors, very low accuracy is not an issue.
The plot below shows stimulus (number of dots shown) against subject response, with green line showing  , and red line a fitted regression model having the form
, and red line a fitted regression model having the form  (which explains just over 70% of the variance; code+data):
(which explains just over 70% of the variance; code+data):
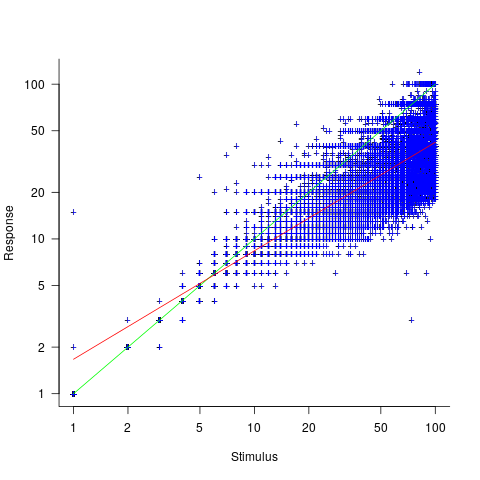
Just like software estimates, there is a good fit to a power law, and the only difference in accuracy performance is that software estimates tend not to be so skewed towards underestimating (i.e., there are a lot more low accuracy overestimates).
Adding subjectID to the model gives:  , with
, with  varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (code+data).
varying between 0.65 and 1.57; more than a factor of two difference between subjects (this model explains just under 90% of the variance). This is a smaller range than the software estimation data, but with only six subjects there was less chance of a wider variation (code+data).
The software estimation data finds shows that accuracy does not improve with practice. The experimental subjects were not given any feedback, and would not be expected to improve, but does the strain of answering so many questions cause them to get worse? Adding trial number to the model suggests a 12% increase in underestimation, over 600 trials. However, adding an interaction with SubjectID shows that the performance of two subjects remains unchanged, while two subjects experience a 23% increase in underestimation.
The plot below shows the number of times each response was given, combining all subjects, with commonly given responses in red (code+data):
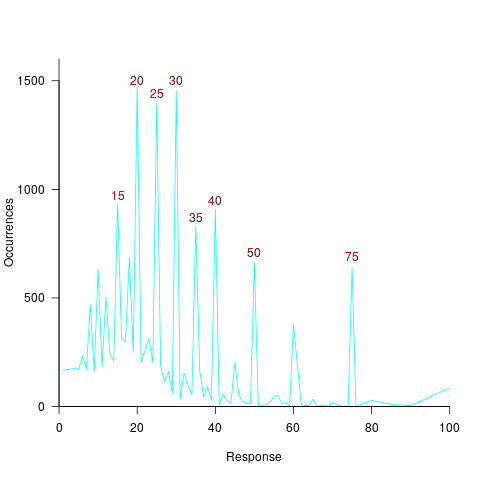
The commonly occurring values that appear in software estimation data are structured as fractions of units of time, e.g., 0.5 hours, or 1 hour or 1 day (appearing in the data as 7 hours). The only structure available to experimental subjects was subdivisions of powers of 10 (i.e., 10 and 100).
Analysing the responses by subject shows that each subject had their own set of preferred round numbers.
To summarize: The results from an experiment investigating the interface between the two human number systems contains three patterns seen in software estimation data, i.e., power law relationship between actual and estimate, individual differences in over/underestimating, and extensive use of round numbers.
Izard’s second experiment limited response values to prespecified values (i.e., one to 10 and multiples of 10), and gave a calibration example after each block of 46 trials. The calibration example improved performance, and the use of round numbers as prespecified response values had the effect of removing spikes from the response counts (which were relatively smooth; code+data)).
We now have circumstantial evidence that software developers are using the Approximate Number System when making software estimates. We will have to wait for brain images from a developer in an MRI scanner, while estimating a software task, to obtain more concrete proof that the ANS is involved in the process. That is, are the areas of the brain thought to be involved in the ANS (e.g., the intraparietal sulcus) active during software estimation?
The Shape of Code is moving
This blog is moving to a new’ish domain (shape-of-code.com), and hosting company (HostGator). The existing url (shape-of-code.coding-guidelines.com) will continue to work for at least a year, and probably longer.
A beta version of the new site is now running. If things check out (please let me know if you see any issues), https://shape-of-code.com will become the official home next weekend, and the DNS entry for shape-of-code.coding-guidelines.com will be changed to point to the new address.
The existing coding-guidelines.com website has been hosted by PowWeb since June 2005. These days few people will have heard of PowWeb, but in 2005 they often appeared in the list of top hosting sites. I have had a few problems over the years, but I suspect nothing that I would have experienced from other providers. Over time, the functionality provided by PowWeb has decreased, compared to what they used to offer and what others offer today. But since my site usage has been essentially hosting a blog, I have not had a reason to move.
While I have had a nagging feeling I ought to move to a major provider, it was not until a post caused the site to be taken off-line because of a page-views per-hour limit being exceeded, that I decided to move. The limit was exceeded because an article appeared on news.ycombinator and became more popular, more rapidly, than my previous article appearances on ycombinator (which have topped out at 20K+ hits). Customer support were very responsive and quickly reset the page counter, once I contacted them and explained the situation. But why didn’t they inform me (I rarely hear from them, apart from billing, and one false alarm about the site sending spam), and why no option to upgrade?
The screenshot below shows that the daily traffic is around 1K views (mostly from Google searches), with 20k+ daily peak views every few months (sometimes months after the article was posted):
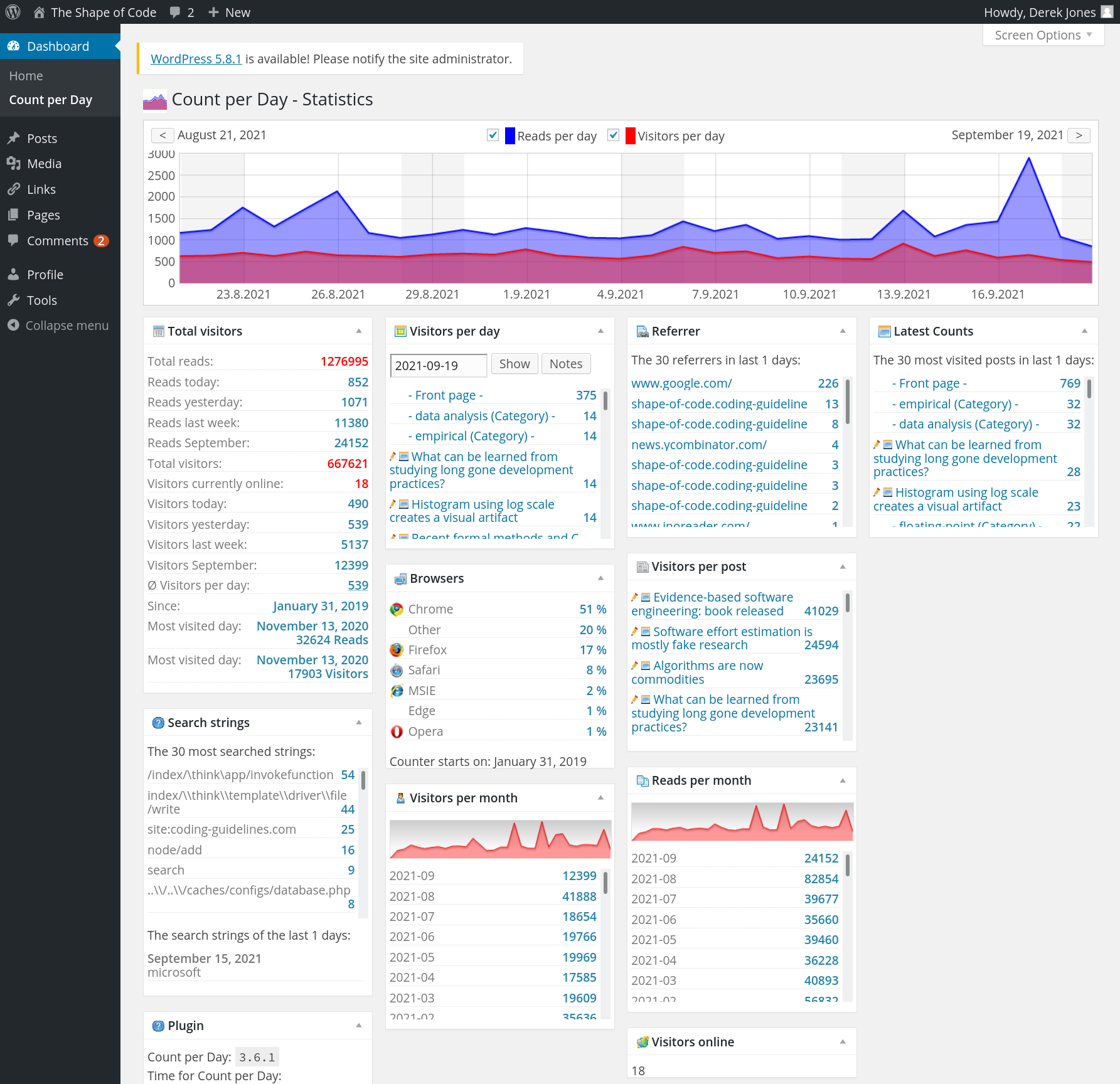
Eight months later, the annual fee is due; time for action. HostGator is highly rated by many hosting reviews, and offered site migration (never having migrated a website before, I did not know it was essentially ftp’ing the contents, and maybe some basic WordPress stuff). I signed up.
As you may have guessed, my approach to website maintenance is: If it’s not broken, don’t fix it. This meant the site was running the oldest version of WordPress (4.2.30) and PHP (5.2, which reached end-of-life 10 years ago) that PowWeb supported.
As I learned about website and WordPress migration, I thought: I can do that. My Plan B was to get HostGator to do it.
WordPress migration turned out to be straight forward:
- export blog contents. WordPress generates an xml file,
- edit the xml file, replacing all occurrences of
shape-of-code.coding-guidelines.combyshape-of-code.com, - create WordPress blog on HostGator (to minimise the chance of incompatibilities I stayed with version 4, HostGator offers 4.9.18), selected a few options, and installed a few basic add-ons,
- ftp directories containing images and code+data to new site,
- import contents of xml file (there is a 512M limit, my file was 5.5M).
It worked 🙂
I was not happy with the theme visually closest to the current blog (Twenty Sixteen), so I tried installing the existing theme (iNove). Despite not being maintained for eight years, it works well enough for me to decide to run with it.
I’m hoping that the new site will run with minimal input from me (apart from writing articles) for the next 10-years.
Mutation testing: its days in the limelight are over
How good a job does a test suite do in detecting coding mistakes in the program it tests?
Mutation testing provides one answer to this question. The idea behind mutation testing is to make a small change to the source code of the program under test (i.e., introduce a coding mistake), and then run the test suite through the mutated program (ideally one or more tests fail, as-in different behavior should be detected); rinse and repeat. The mutation score is the percentage of mutated programs that cause a test failure.
While Mutation testing is 50-years old this year (although the seminal paper did not get published until 1978), the computing resources needed to research it did not start to become widely available until the late 1980s. From then, until fuzz testing came along, mutation testing was probably the most popular technique studied by testing researchers. A collected bibliography of mutation testing lists 417 papers and 16+ PhD thesis (up to May 2014).
Mutation testing has not been taken up by industry because it tells managers what they already know, i.e., their test suite is not very good at finding coding mistakes.
Researchers concluded that the reason industry had not adopted mutation testing was that it was too resource intensive (i.e., mutate, compile, build, and run tests requires successively more resources). If mutation testing was less resource intensive, then industry would use it (to find out faster what they already knew).
Creating a code mutant is not itself resource intensive, e.g., randomly pick a point in the source and make a random change. However, the mutated source may not compile, or the resulting mutant may be equivalent to one created previously (e.g., the optimised compiled code is identical), or the program takes ages to compile and build; techniques for reducing the build overhead include mutating the compiler intermediate form and mutating the program executable.
Some changes to the source are more likely to be detected by a test suite than others, e.g., replacing <= by > is more likely to be detected than replacing it by < or ==. Various techniques for context dependent mutations have been proposed, e.g., handling of conditionals.
While mutation researchers were being ignored by industry, another group of researchers were listening to industry's problems with testing; automatic test case generation took off. How might different test case generators be compared? Mutation testing offers a means of evaluating the performance of tools that arrived on the scene (in practice, many researchers and tool vendors cite statement or block coverage numbers).
Perhaps industry might have to start showing some interest in mutation testing.
A fundamental concern is the extent to which mutation operators modify source in a way that is representative of the kinds of mistakes made by programmers.
The competent programmer hypothesis is often cited, by researchers, as the answer to this question. The hypothesis is that competent programmers write code/programs that is close to correct; the implied conclusion being that mutations, which are small changes, must therefore be like programmer mistakes (the citation often given as the source of this hypothesis discusses data selection during testing, but does mention the term competent programmer).
Until a few years ago, most analysis of fixes of reported faults looked at what coding constructs were involved in correcting the source code, e.g., 296 mistakes in TeX reported by Knuth. This information can be used to generate a probability table for selecting when to mutate one token into another token.
Studies of where the source code was changed, to fix a reported fault, show that existing mutation operators are not representative of a large percentage of existing coding mistakes; for instance, around 60% of 290 source code fixes to AspectJ involved more than one line (mutations usually involve a single line of source {because they operate on single statements and most statements occupy one line}), another study investigating many more fixes found only 10% of fixes involved one line, and similar findings for a study of C, Java, Python, and Haskell (a working link to the data, which is a bit disjointed of a mess).
These studies, which investigated the location of all the source code that needs to be changed, to fix a mistake, show that existing mutation operators are not representative of most human coding mistakes. To become representative, mutation operators need to be capable of making coupled changes across multiple lines/functions/methods and even files.
While arguments over the validity of the competent programmer hypothesis rumble on, the need for multi-line changes remains.
Given the lack of any major use-cases for mutation testing, it does not look like it is worth investing lots of resources on this topic. Researchers who have spent a large chunk of their career working on mutation testing will probably argue that you never know what use-cases might crop up in the future. In practice, mutation research will probably fade away because something new and more interesting has come along, i.e., fuzz testing.
There will always be niche use-cases for mutation. For instance, how likely is it that a random change to the source of a formal proof will go unnoticed by its associated proof checker (i.e., the proof checking tool output remains unchanged)?
A study based on mutating the source of Coq verification projects found that 7% of mutations had no impact on the results.
Testing rounded data for a circular uniform distribution
Circular statistics deals with analysis of measurements made using a circular scale, e.g., minutes past the hour, days of the week. Wikipedia uses the term directional statistics, the traditional use being measurements of angles, e.g., wind direction.
Package support for circular statistics is rather thin on the ground. R’s circular package is one of the best, and the book “Circular Statistics in R” provides the only best introduction to the subject.
Circular statistics has a few surprises for those new to the subject (apart from a few name changes, e.g., the von Mises distribution is effectively the ‘circular Normal distribution’), including:
- the mean value contains two components, a direction and a length, e.g., mean wind direction and strength,
- there are several definitions of variance, with angular variance having a value between 0 and 2, and circular variance having a value between 0 and 1. The circular standard deviation is not the square root of variance, but rather:
 , where
, where  is the mean length.
is the mean length.
The basic techniques used in circular statistics are still relatively new, compared to the more well known basic statistical techniques. For instance, it was recently discovered that having more measurements may reduce the reliability of the Rao spacing test (used to test whether a sample has a uniform circular distribution); generally, having more measurements improves the reliability of a statistical test.
The plot below shows Rose diagrams for the number of commits in each 3-hour period of a day for Linux and FreeBSD (mean direction and length in green; code+data):
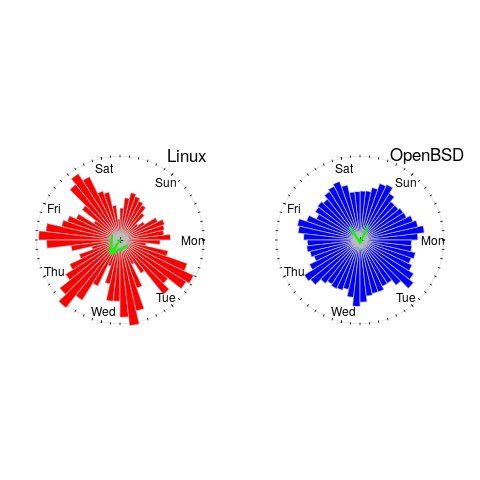
The Linux kernel source has far fewer commits at the weekend, compared to working days. Given the number of people whose job is to work on the Linux kernel, compared to the number of people doing it out of interest, this difference is not surprising. The percentage of people working on OpenBSD as a job is small, and there does not appear to be a big difference between weekends and workdays. There is a lot of variation in the number of commits during each 3-hour period of a day, but the number of commits per day does not vary so much; the number of OpenBSD commits per day of week is:
Mon Tue Wed Thu Fri Sat Sun
26909 26144 25705 25104 24765 22812 24304 |
Does this distribution of commits per day have a uniform distribution (to some confidence level)?
Like all measurements, those made on a circular scale are rounded to some number of digits. Measurements may also be rounded, or binned, to particular units of the scale, e.g., measured to the nearest degree, or nearest minute.
A recent paper, by Landler, Ruxton and Malkemper, found that for samples containing around five hundred or more measurements, rounding to the nearest degree was sufficient to cause the Rao spacing test to almost always report non-uniformity, i.e., for non-trivial samples the rounding was sufficient to cause the test to detect non-uniformity (things worked as expected for samples containing fewer than 100 measurements).
Landler et al found that adding a small amount of noise (drawn from a von Mises distribution) to the rounded measurements appeared to ‘fix’ the incorrect behavior, i.e., rejecting the hypothesis of a uniform distribution, when a uniform distribution may be present.
The rao.spacing.test function, in the circular package, rejected that null hypothesis that the OpenBSD daily data has a uniform distribution. However, when noise is added to each day value (i.e., adding a random fraction to the day values, using rvonmises(length(c_per_day), circular(0), 2.0), although runif(length(c_per_day)) is probably more appropriate {and produces essentially the same result}), the call to rao.spacing.test failed to reject the null hypothesis of uniformity at the 0.05 level (i.e., the daily distribution is probably uniform).
How many research results are affected by this discovery?
I very rarely encounter the use of circular statistics (even though they should probably have been used in places), but then I spend my time reading software engineering papers, whose use of statistics tends to be primitive. I plan to include a brief mention of the use of the Rao spacing test with binned data in the addendum to my Evidence-based software engineering book (which includes the above example).
Multiple estimates for the same project
The first question I ask, whenever somebody tells me that a project was delivered on schedule (or within budget), is which schedule (or budget)?
New schedules are produced for projects that are behind schedule, and costs get re-estimated.
What patterns of behavior might be expected to appear in a project’s reschedulings?
It is to be expected that as a project progresses, subsequent schedules become successively more accurate (in the sense of having a completion date and cost that is closer to the final values). The term cone of uncertainty is sometimes applied as a visual metaphor in project management, with the schedule becoming less uncertain as the project progresses.
The only publicly available software project rescheduling data, from Landmark Graphics, is for completed projects, i.e., cancelled projects are not included (121 completed projects and 882 estimates).
The traditional project management slide has some accuracy metric improving as work on a project approaches completion. The plot below shows the percentage of a project completed when each estimate is made, against the ratio  ; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
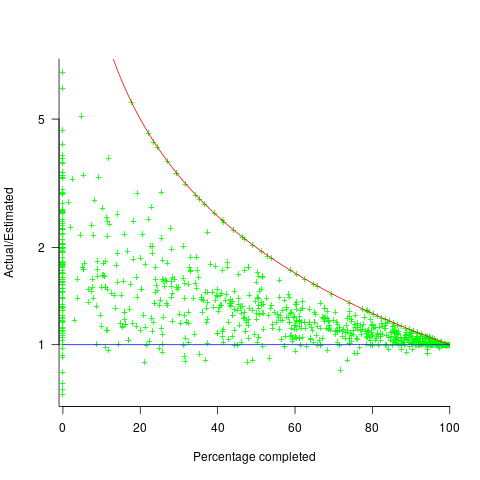
The closer a point to the blue line, the more accurate the estimate. The red line shows maximum underestimation, i.e., estimating that the project is complete when there is still more work to be done. A new estimate must be greater than (or equal) to the work already done, i.e.,  , and
, and  .
.
Rearranging, we get:  (plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
(plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
In theory there is no limit on overestimating (i.e., points appearing below the blue line), but in practice management are under pressure to deliver as early as possible and to minimise costs. If management believe they have overestimated, they have an incentive to hang onto the time/money allocated (the future is uncertain).
Why does management invest time creating a new schedule?
If information about schedule slippage leaks out, project management looks bad, which creates an incentive to delay rescheduling for as long as possible (i.e., let’s pretend everything will turn out as planned). The Landmark Graphics data comes from an environment where management made weekly reports and estimates were updated whenever the core teams reached consensus (project average was eight times).
The longer a project is being worked on, the greater the opportunity for more unknowns to be discovered and the schedule to slip, i.e., longer projects are expected to acquire more re-estimates. The plot below shows the number of estimates made, for each project, against the initial estimated duration (red/green) and the actual duration (blue/purple); lines are loess fits (code+data):
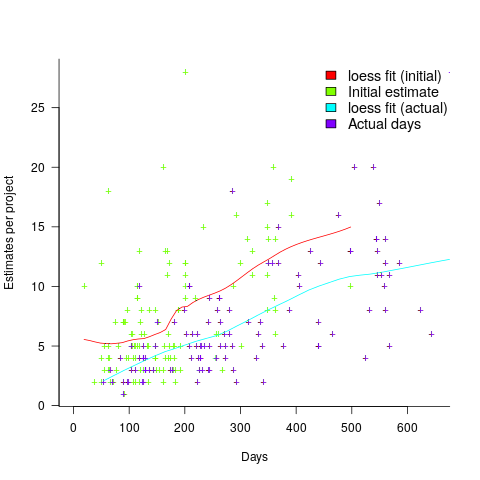
What might be learned from any patterns appearing in this data?
When presented with data on the sequence of project estimates, my questions revolve around the reasons for spending time creating a new estimate, and the amount of time spent on the estimate.
A lot of time may have been invested in the original estimate, but how much time is invested in subsequent estimates? Are later estimates simply calculated as a percentage increase, a politically acceptable value (to the stakeholder funding for the project), or do they take into account what has been learned so far?
The information needed to answer these answers is not present in the data provided.
However, this evidence of the consistent provision of multiple project estimates drives another nail in to the coffin of estimation research based on project totals (e.g., if data on project estimates is provided, one estimate per project, were all estimates made during the same phase of the project?)
Recent Comments