Lifetime of coding mistakes in the Linux kernel
What is the lifetime of coding mistakes in the Linux kernel? Some coding mistakes result in fault reports (some of which are fixed), while many are removed when the source that contains them is deleted/changed during ongoing development.
After fixing the coding mistake(s) in the kernel that generated a reported fault, developer(s) log the commit that introduced the coding mistake, along with the commit that fixed it. This logging started in 2013, and I only found out about it this week. To be exact, I discovered the repo: A dataset of Linux Kernel commits created by Maes Bermejo, Gonzalez-Barahona, Gallego, and Robles.
The log contains the commit hashes for the 90,760 fixes made to the 63 mainline kernel versions from 3.12 to 6.13. The complete log of 1,233,421 commits has to be searched to extract the details, e.g., date, lines added, etc.
The kernel development process involves regular release cycles of around 80 days. Developers submit the code they want to be included in the next release, this goes through a series of reviews, with Linus making the final decision.
The following analysis is based on the coding mistakes introduced between successive kernel releases, e.g., version 3.13 coding mistakes are those introduced into the source between 4 Nov 2013 (the day after version 3.12 was released) and 19 Jan 2014 (when version 3.13 was released). Code will have been worked on, and mistakes created/fixed, before it reached the kernel, which ensures some level of maturity.
The number of people working with pre-release code is likely to be tiny, compared to the number running released kernels. Consequently, the characteristics of coding mistake lifetime is expected to be different pre/post release, if only because more users are likely to report more faults.
The plot below shows the pre-release daily mistake fixed density against days since start of work on the current release, the red line is a fitted regression line mapped to density (fitted regression is a biexponential; code and data):
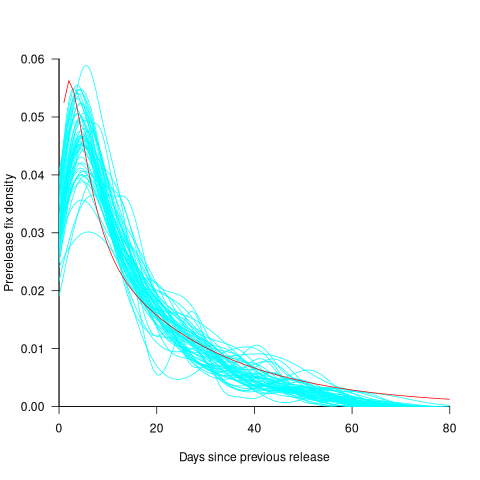
For all versions, the prior to release daily fix rate follows a consistent pattern: Most fixes occur in the first few days, with roughly an exponential decline to the release date.
The following analysis builds a broad brush model of cumulative fixes over time across 53 mainline kernel releases (the final 10 releases were not included because of their relatively short history).
The number of users of a new kernel takes time to increase as it percolates onto systems, e.g., adopted by Linux distributions and then installed by users, or installed by cloud providers. Eventually, code first included in a particular version will be running on most systems.
The post release daily fix rate is best modelled using the cumulative number of fixes, i.e., total number of fixes up to a given day since release. The models fitted below are based on dividing the post release cumulative fixes into before/after 200 days since release. The 200-day division is a round number (technically, a nearby value may provide a better fit) that supports the fitting of good quality before/after regression models. Averaged over all releases, 42% of fixes occurred within 200-days, and 58% after 200-days.
The plot below shows the cumulative number of post-release fixed faults, in red, for various kernel versions, with fitted regression lines in green and blue (grey line is at 200-days; code and data):

The equation fitted to the before 200-days fixes had the following form:
}")
where:  is a kernel version specific constant; see plot below.
is a kernel version specific constant; see plot below.
The equation fitted to the after 200-days fixes had the following form:

where:  is a kernel version specific constant; see plot below.
is a kernel version specific constant; see plot below.
Approximately, after release, the cumulative fix rate starts out quadratic in elapsed days, with the rate decreasing over time, until after 200-days the rate settles down to following the cube-root of days.
Comparing the number of post-release fixes across versions, there is a lot more variability in the first 200-days (i.e., the model fit to the data is sometimes very poor), relatively to after 200-days (where the model fit is consistently good).
Each kernel release has its own characteristics, parameterised by the values , and in the above equations. The plot below shows these values across versions, with red for , blue/green for , and grey line showing normalised LOC added/changed in the release (code and data):
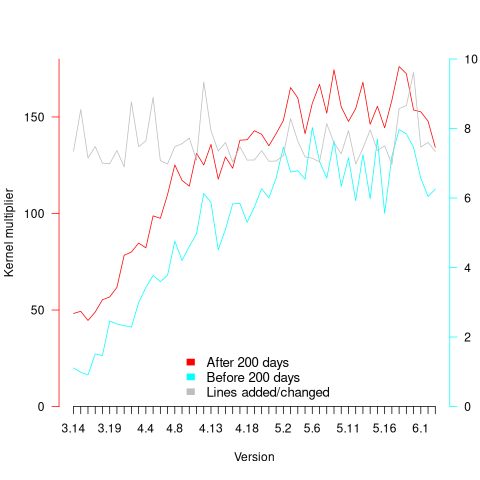
The plot clearly shows a large increase in the number of fixes between kernel version 3.14 and later versions. The before 200-days rate (blue/green) increase by a factor of seven, while the after 200-days rate increased by a factor of three.
Is this increase driven by some underlying factor in kernel development, or is it an external factor such as an increase in the number of users (more users leads to more faults reports), or the extensive post-release fuzz testing that is now common.
The number of lines of code added/changed, indicated by the grey line (shifted to fit plot axes) cannot be added to the fitted models because they exactly correlate with their respective version.
What is driving the long-term rate of fixes, i.e., cube-root of elapsed days?
Actually, what people are really want to know is what can be done to reduce the number of fixes required after release. When people ask me this, my usual reply is: “Spend more on testing”.
The probability of a coding mistake causing a fault report is decreasing: fixes reduce the number of remaining mistakes, and source added in one kernel version may be removed in a later version.
Perhaps the set of input behaviors is growing, producing the distinct conditions needed to trigger different coding mistakes, or the faults are occurring but are only reported when experienced by a small subset of users.
As always, more data is needed.
Very interesting work! Which are the two exponential processes to use biexponential: developer-centric discovery and user-centric discovery?
We have done some analyses using negative binomial. The idea was to use Poisson but we identified that the data was overdispersed due to Christmas or developers attending Linux Plumber or OSS.
@Imanol
It takes time for a new kernel to be adopted by lots of people. I interpret the first 200-days as the ramp up to widespread usage, hence two models. As you say, developers are probably looking for problems after the initial release, and less likely to be looking for problems after 200-days.
There is really only one model, but we don’t have any measurements on number of users. I picked 200-days because this value seemed to work across many releases.