Archive
The 2019 Huawei cyber security evaluation report
The UK’s Huawei cyber security evaluation centre oversight board has released it’s 2019 annual report.
The header and footer of every page contains the text “SECRET”“OFFICIAL”, which I assume is its UK government security classification. It lends an air of mystique to what is otherwise a meandering management report.
Needless to say, the report contains the usually puffery, e.g., “HCSEC continues to have world-class security researchers…”. World class at what? I hear they have some really good mathematicians, but have serious problems attracting good software engineers (such people can be paid a lot more, and get to do more interesting work, in industry; the industry demand for mathematicians, outside of finance, is weak).
The most interesting sentence appears on page 11: “The general requirement is that all staff must have Developed Vetting (DV) security clearance, …”. Developed Vetting, is the most detailed and comprehensive form of security clearance in UK government (to quote Wikipedia).
Why do the centre’s staff have to have this level of security clearance?
The Huawei source code is not that secret (it can probably be found online, lurking in the dark corners of various security bulletin boards).
Is the real purpose of this cyber security evaluation centre, to find vulnerabilities in the source code of Huawei products, that GCHQ can then use to spy on people?
Or perhaps, this centre is used for training purposes, with staff moving on to work within GCHQ, after they have learned their trade on Huawei products?
The high level of security clearance applied to the centre’s work is the perfect smoke-screen.
The report claims to have found “Several hundred vulnerabilities and issues…”; a meaningless statement, e.g., this could mean one minor vulnerability and several hundred spelling mistakes. There is no comparison of the number of vulnerabilities found per effort invested, no comparison with previous years, no classification of the seriousness of the problems found, no mention of Huawei’s response (i.e., did Huawei agree that there was a problem).
How many vulnerabilities did the centre find that were reported by other people, e.g., the National Vulnerability Database? This information would give some indication of how good a job the centre was doing. Did this evaluation centre find the Huawei vulnerability recently disclosed by Microsoft? If not, why not? And if they did, why isn’t it in the 2019 report?
What about comparing the number of vulnerabilities found in Huawei products against the number found in vendors from the US, e.g., CISCO? Obviously back-doors placed in US products, at the behest of the NSA, need not be counted.
There is some technical material, starting on page 15. The configuration and component lifecycle management issues raised, sound like good points, from a cyber security perspective. From a commercial perspective, Huawei want to quickly respond to customer demand and a dynamic market; corners are likely to be cut off good practices every now and again. I don’t understand why the use of an unnamed real-time operating system was flagged: did some techie gripe slip through management review? What is a C preprocessor macro definition doing on page 29? This smacks of an attempt to gain some hacker street-cred.
Reading between the lines, I get the feeling that Huawei has been ignoring the centre’s recommendations for changes to their software development practices. If I were on the receiving end, I would probably ignore them too. People employed to do security evaluation are hired for their ability to find problems, not for their ability to make things that work; also, I imagine many are recent graduates, with little or no practical experience, who are just repeating what they remember from their course work.
Huawei should leverage its funding of a GCHQ spy training centre, to get some positive publicity from the UK government. Huawei wants people to feel confident that they are not being spied on, when they use Huawei products. If the government refuses to play ball, Huawei should shift its funding to a non-government, open evaluation center. Employees would not need any security clearance and would be free to give their opinions about the presence of vulnerabilities and ‘spying code’ in the source code of Huawei products.
Describing software engineering in terms of a traditional science
If you were asked to describe the ‘building stuff’ side of software engineering, by comparing it with one of the traditional sciences, which science would you choose?
I think a lot of people would want to compare it with Physics. Yes, physics envy is not restricted to the softer sciences of humanities and liberal arts. Unlike physics, software engineering is not governed by a handful of simple ‘laws’, it’s a messy collection of stuff.
I used to think that biology had all the necessary important characteristics needed to explain software engineering: evolution (of code and products), species (e.g., of editors), lifespan, and creatures are built from a small set of components (i.e., DNA or language constructs).
Now I’m beginning to think that chemistry has aspects that are a better fit for some important characteristics of software engineering. Chemists can combine atoms of their choosing to create whatever molecule takes their fancy (subject to bonding constraints, a kind of syntax and semantics for chemistry), and the continuing existence of a molecule does not depend on anything outside of itself; biological creatures need to be able to extract some form of nutrient from the environment in which they live (which is also a requirement of commercial software products, but not non-commercial ones). Individuals can create molecules, but creating new creatures (apart from human babies) is still a ways off.
In chemistry and software engineering, it’s all about emergent behaviors (in biology, behavior is just too complicated to reliably say much about). In theory the properties of a molecule can be calculated from the known behavior of its constituent components (e.g., the electrons, protons and neutrons), but the equations are so complicated it’s impractical to do so (apart from the most simple of molecules; new properties of water, two atoms of hydrogen and one of oxygen, are still being discovered); the properties of programs could be deduced from the behavior its statements, but in practice it’s impractical.
What about the creative aspects of software engineering you ask? Again, chemistry is a much better fit than biology.
What about the craft aspect of software engineering? Again chemistry, or rather, alchemy.
Is there any characteristic that physics shares with software engineering? One that stands out is the ego of some of those involved. Describing, or creating, the universe nourishes large egos.
Altruistic innovation and the study of software economics
Recently, I have been reading rather a lot of papers that are ostensibly about the economics of markets where applications, licensed under an open source license, are readily available. I say ostensibly, because the authors have some very odd ideas about the activities of those involved in the production of open source.
Perhaps I am overly cynical, but I don’t think altruism is the primary motivation for developers writing open source. Yes, there is an altruistic component, but I would list enjoyment as the primary driver; developers enjoy solving problems that involve the production of software. On the commercial side, companies are involved with open source because of naked self-interest, e.g., commoditizing software that complements their products.
It may surprise you to learn that academic papers, written by economists, tend to be knee-deep in differential equations. As a physics/electronics undergraduate I got to spend lots of time studying various differential equations (each relating to some aspect of the workings of the Universe). Since graduating, I have rarely encountered them; that is, until I started reading economics papers (or at least trying to).
Using differential equations to model problems in economics sounds like a good idea, after all they have been used to do a really good job of modeling how the universe works. But the universe is governed by a few simple principles (or at least the bit we have access to is), and there is lots of experimental data about its behavior. Economic issues don’t appear to be governed by a few simple principles, and there is relatively little experimental data available.
Writing down a differential equation is easy, figuring out an analytic solution can be extremely difficult; the Navier-Stokes equations were written down 200-years ago, and we are still awaiting a general solution (solutions for a variety of special cases are known).
To keep their differential equations solvable, economists make lots of simplifying assumptions. Having obtained a solution to their equations, there is little or no evidence to compare it against. I cannot speak for economics in general, but those working on the economics of software are completely disconnected from reality.
What factors, other than altruism, do academic economists think are of major importance in open source? No, not constantly reinventing the wheel-barrow, but constantly innovating. Of course, everybody likes to think they are doing something new, but in practice it has probably been done before. Innovation is part of the business zeitgeist and academic economists are claiming to see it everywhere (and it does exist in their differential equations).
The economics of Linux vs. Microsoft Windows is a common comparison, i.e., open vs. close source; I have not seen any mention of other open source operating systems. How might an economic analysis of different open source operating systems be framed? How about: “An economic analysis of the relative enjoyment derived from writing an operating system, Linux vs BSD”? Or the joy of writing an editor, which must be lots of fun, given how many have text editors are available.
I have added the topics, altruism and innovation to my list of indicators of poor quality, used to judge whether its worth spending more than 10 seconds reading a paper.
Regression line fitted to noisy data? Ask to see confidence intervals
A little knowledge can be a dangerous thing. For instance, knowing how to fit a regression line to a set of points, but not knowing how to figure out whether the fitted line makes any sense. Fitting a regression line is trivial, with most modern data analysis packages; it’s difficult to find data that any of them fail to fit to a straight line (even randomly selected points usually contain enough bias on one direction, to enable the fitting algorithm to converge).
Two techniques for checking the goodness-of-fit, of a regression line, are plotting confidence intervals and listing the p-value. The confidence interval approach is a great way to visualize the goodness-of-fit, with the added advantage of not needing any technical knowledge. The p-value approach is great for blinding people with science, and a necessary technicality when dealing with multidimensional data (unless you happen to have a Tardis).
In 2016, the Nationwide Mutual Insurance Company won the IEEE Computer Society/Software Engineering Institute Watts S. Humphrey Software Process Achievement (SPA) Award, and there is a technical report, which reads like an infomercial, on the benefits Nationwide achieved from using SEI’s software improvement process. Thanks to Edward Weller for the link.
Figure 6 of the informercial technical report caught my eye. The fitted regression line shows delivered productivity going up over time, but the data looks very noisy. How good a fit is that regression line?
Thanks to WebPlotDigitizer, I quickly extracted the data (I’m a regular user, and WebPlotDigitizer just keeps getting better).
Below is the data plotted to look like Figure 6, with the fitted regression line in pink (code+data). The original did not include tick marks on the axis. For the x-axis I assumed each point was at a fixed 2-month interval (matching the axis labels), and for the y-axis I picked the point just below the zero to measure length (so my measurements may be off by a constant multiplier close to one; multiplying values by a constant will not have any influence on calculating goodness-of-fit).
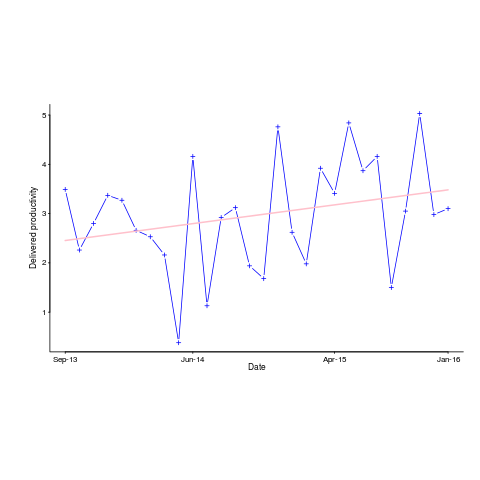
The p-value for the fitted line is 0.15; gee-wiz, you say. Plotting with confidence intervals (in red; the usual 95%) makes the situation clear:
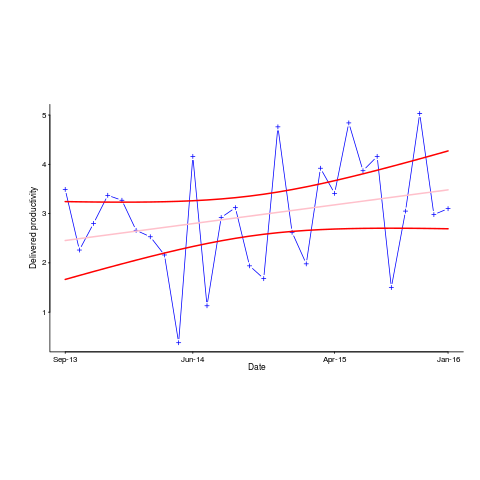
Ok, so the fitted model is fairly meaningless from a technical perspective; the line might actually go down, rather than up (there is too much noise in the data to tell). Think of the actual line likely appearing somewhere in the curved red tube.
Do Nationwide, IEEE or SEI care? The IEEE need a company to award the prize to, SEI want to promote their services, and Nationwide want to convince the rest of the world that their IT services are getting better.
Is there a company out there who feels hard done-by, because they did not receive the award? Perhaps there is, but are their numbers any better than Nationwide’s?
How much influence did the numbers in Figure 6 have on the award decision? Perhaps not a lot, the other plots look like they would tell a similar tail of wide confidence intervals on any fitted lines (readers might like to try their hand drawing confidence intervals for Figure 9). Perhaps Nationwide was the only company considered.
Who are the losers here? Other companies who decide to spend lots of money adopting the SEI software process? If evidence was available, perhaps something concrete could be figured out.
Polished human cognitive characteristics chapter
It has been just over two years since I release the first draft of the Human cognitive characteristics chapter of my evidence-based software engineering book. As new material was discovered, it got added where it seemed to belong (at the time), no effort was invested in maintaining any degree of coherence.
The plan was to find enough material to paint a coherence picture of the impact of human cognitive characteristics on software engineering. In practice, finishing the book in a reasonable time-frame requires that I stop looking for new material (assuming it exists), and go with what is currently available. There are a few datasets that have been promised, and having these would help fill some holes in the later sections.
The material has been reorganized into what is essentially a pass over what I think are the major issues, discussed via studies for which I have data (the rule of requiring data for a topic to be discussed, gets bent out of shape the most in this chapter), presented in almost a bullet point-like style. At least there are plenty of figures for people to look at, and they are in color.
I think the material will convince readers that human cognition is a crucial topic in software development; download the draft pdf.
Model building by cognitive psychologists is starting to become popular, with probabilistic languages, such as JAGS and Stan, becoming widely used. I was hoping to build models like this for software engineering tasks, but it would have taken too much time, and will have to wait until the book is done.
As always, if you know of any interesting software engineering data, please let me know.
Next, the cognitive capitalism chapter.
Recent Comments