Archive
Modelling time to next reported fault
After the arrival of a fault report for a program, what is the expected elapsed time until the next fault report arrives (assuming that the report relates to a coding mistake and is not a request for enhancement or something the user did wrong, and the number of active users remains the same and the program is not changed)? Here, elapsed time is a proxy for amount of program usage.
Measurements (here and here) show a consistent pattern in the elapsed time of duplicate reports of individual faults. Plotting the time elapsed between the first report and the n’th report of the same fault in the order they were reported produces an exponential line (there are often changes in the slope of this line). For example, the plot below shows 10 unique faults (different colors), the number of days between the first report and all subsequent reports of the same fault (plus character); note the log scale y-axis (discussed in this post; code+data):

The first person to report a fault may experience the same fault many times. However, they only get to submit one report. Also, some people may experience the fault and not submit a report.
If the first reporter had not submitted a report, then the time of first report would be later. Also, the time of first report could have been earlier, had somebody experienced it earlier and chosen to submit a report.
The subpopulation of users who both experience a fault and report it, decreases over time. An influx of new users is likely to cause a jump in the rate of submission of reports for previously reported faults.
It is possible to use the information on known reported faults to build a probability model for the elapsed time between the last reported known fault and the next reported known fault (time to next reported unknown fault is covered at the end of this post).
The arrival of reports for each distinct fault can be modelled as a Poisson process. The time between events in a Poisson process with rate  has an exponential distribution, with mean
has an exponential distribution, with mean  . The distribution of a sum of multiple Poisson processes is itself a Poisson process whose rate is the sum of the individual rates. The other key point is that this process is memoryless. That is, the elapsed time of any report has no impact on the elapsed time of any other report.
. The distribution of a sum of multiple Poisson processes is itself a Poisson process whose rate is the sum of the individual rates. The other key point is that this process is memoryless. That is, the elapsed time of any report has no impact on the elapsed time of any other report.
If there are  different faults whose fitted report time exponents are:
different faults whose fitted report time exponents are:  ,
,  …
…  , then summing the Poisson rates,
, then summing the Poisson rates,  , gives the mean
, gives the mean  , for a probability model of the estimated time to next any-known fault report.
, for a probability model of the estimated time to next any-known fault report.
To summarise. Given enough duplicate reports for each fault, it’s possible to build a probability model for the time to next known fault.
In practice, people are often most interested in the time to the first report of a previous unreported fault.
tl;dr Modelling time to next previously unreported fault has an analytic solution that depends on variables whose values have to be approximately approximated.
The method used to build a probability model of reports of known fault can be used extended to build a probability model of first reports of currently unknown faults. To build this model, good enough values for the following quantities are needed:
- the number of unknown faults,
 , remaining in the program. I have some ideas about estimating the number of unknown faults, , and will discuss them in another post,
, remaining in the program. I have some ideas about estimating the number of unknown faults, , and will discuss them in another post, - the time,
 , needed to have received at least one report for each of the unknown faults. In practice, this is the lifetime of the program, and there is data on software half-life. However, all coding mistakes could trigger a fault report, but not all coding mistakes will have done so during a program’s lifetime. This is a complication that needs some thought,
, needed to have received at least one report for each of the unknown faults. In practice, this is the lifetime of the program, and there is data on software half-life. However, all coding mistakes could trigger a fault report, but not all coding mistakes will have done so during a program’s lifetime. This is a complication that needs some thought, - the values of
 ,
,  …
…  for each of the unknown faults. There is some data suggesting that these values are drawn from an exponential distribution, or something close to one. Also, an equation can be fitted to the values of the known faults. The analysis below assumes that the
for each of the unknown faults. There is some data suggesting that these values are drawn from an exponential distribution, or something close to one. Also, an equation can be fitted to the values of the known faults. The analysis below assumes that the  for each unknown fault that might be reported is randomly drawn from an exponential distribution whose mean is .
for each unknown fault that might be reported is randomly drawn from an exponential distribution whose mean is .
This rate will be affected by program usage (i.e., number of users and the activities they perform), and source code characteristics such as the number of executions paths that are dependent on rarely true conditions.
Putting it all together, the following is the question I asked various LLMs (which uses  , rather than ):
, rather than ):
There are independent processes. Each process,  , transmits a signal, and the number of signals transmitted in a fixed time interval, , has a Poisson distribution with mean
, transmits a signal, and the number of signals transmitted in a fixed time interval, , has a Poisson distribution with mean  for
for  . The values are randomly drawn from the same exponential distribution. What is the cumulative distribution for the time between the successive first signals from the processes.
. The values are randomly drawn from the same exponential distribution. What is the cumulative distribution for the time between the successive first signals from the processes.
The cumulative distribution gives the probability that an event has occurred within a given amount of time, in this case the time since the last fault report.
The ChatGPT 5.2 Thinking response (Grok Thinking gives the same formula, but no chain of thought): The probability that the  unknown fault is reported within time
unknown fault is reported within time  of the previous report of an unknown fault,
of the previous report of an unknown fault, ") , is given by the following rather involved formula:
, is given by the following rather involved formula:
=1-(a/{a+t})^{N-k}{}_{2}F_1(N-k, k; N+1; t/{a+t})")
where: is the initial number of faults that have not been reported,  , and
, and  is the hypergeometric function.
is the hypergeometric function.
The important points to note are: the value  decreases as more unknown faults are reported, and the dominant contribution of the value .
decreases as more unknown faults are reported, and the dominant contribution of the value .
Deepseek’s response also makes complicated use of the same variables, and the analysis is very similar before making some simplifications that don’t look right (text of response). Kimi’s response is usually very good, but for this question failed to handle the consequences of .
Almost all published papers on fault prediction ignore the impact of number of users on reported faults, and that report time for each distinct fault has a distinct distribution, i.e., their analysis is not connected to reality.
Example of an initial analysis of some new NASA data
For the last 20 years, the bug report databases of Open source projects have been almost the exclusive supplier of fault reports to the research community. Which, if any, of the research results are applicable to commercial projects (given the volunteer nature of most Open source projects and that anybody can submit a report)?
The only way to find out if Open source patterns are present in closed source projects is to analyse fault reports from closed source projects.
The recent paper Software Defect Discovery and Resolution Modeling incorporating Severity by Nafreen, Shi and Fiondella caught my attention for several reasons. It does non-trivial statistical analysis (most software engineering research uses simplistic techniques), it is a recent dataset (i.e., might still be available), and the data is from a NASA project (I have long assumed that NASA is more likely than most to reliable track reported issues). Lance Fiondella kindly sent me a copy of the data (paper giving more details about the data)!
Over the years, researchers have emailed me several hundred datasets. This NASA data arrived at the start of the week, and this post is an example of the kind of initial analysis I do before emailing any questions to the authors (Lance offered to answer questions, and even included two former students in his email).
It’s only worth emailing for data when there looks to be a reasonable amount (tiny samples are rarely interesting) of a kind of data that I don’t already have lots of.
This data is fault reports on software produced by NASA, a very rare sample. The 1,934 reports were created during the development and testing of software for a space mission (which launched some time before 2016).
For Open source projects, it’s long been known that many (40%) reported faults are actually requests for enhancements. Is this a consequence of allowing anybody to submit a fault report? It appears not. In this NASA dataset, 63% of the fault reports are change requests.
This data does not include any information on the amount of runtime usage of the software, so it is not possible to estimate the reliability of the software.
Software development practices vary a lot between organizations, and organizational information is often embedded in the data. Ideally, somebody familiar with the work processes that produced the data is available to answer questions, e.g., the SiP estimation dataset.
Dates form the bulk of this data, i.e., the date on which the report entered a given phase (expressed in days since a nominal start date). Experienced developers could probably guess from the column names the work performed in each phase; see list below:
Date Created
Date Assigned
Date Build Integration
Date Canceled
Date Closed
Date Closed With Defect
Date In Test
Date In Work
Date on Hold
Date Ready For Closure
Date Ready For Test
Date Test Completed
Date Work Completed |
There are probably lots of details that somebody familiar with the process would know.
What might this date information tell us? The paper cited had fitted a Cox proportional hazard model to predict fault fix time. I might try to fit a multi-state survival model.
In a priority queue, task waiting times follow a power law, while randomly selecting an item from a non-prioritized queue produces exponential waiting times. The plot below shows the number of reports taking a given amount of time (days elapsed rounded to weeks) from being assigned to build-integration, for reports at three severity levels, with fitted exponential regression lines (code+data):
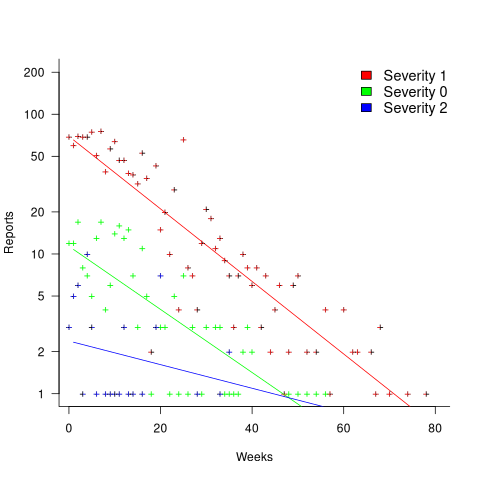
Fitting an exponential, rather than a power law, suggests that the report to handle next is effectively selected at random, i.e., reports are not in a priority queue. The number of severity 2 reports is not large enough for there to be a significant regression fit.
I now have some familiarity with the data and have spotted a pattern that may be of interest (or those involved are already aware of the random selection process).
As always, reader suggestions welcome.
Task backlog waiting times are power laws
Once it has been agreed to implement new functionality, how long do the associated tasks have to wait in the to-do queue?
An analysis of the SiP task data finds that waiting time has a power law distribution, i.e.,  , where
, where  is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
is the number of tasks waiting a given amount of time; the LSST:DM Sprint/Story-point/Story has the same distribution. Is this a coincidence, or does task waiting time always have this form?
Queueing theory analyses the properties of systems involving the arrival of tasks, one or more queues, and limited implementation resources.
A basic result of queueing theory is that task waiting time has an exponential distribution, i.e., not a power law. What software task implementation behavior is sufficiently different from basic queueing theory to cause its waiting time to have a power law?
As always, my first line of attack was to find data from other domains, hopefully with an accompanying analysis modelling the behavior. It’s possible that my two samples are just way outside the norm.
Eventually I found an analysis of the letter writing response time of Darwin, Einstein and Freud (my email asking for the data has not yet received a reply). Somebody writes to a famous scientist (the scientist has to be famous enough for people to want to create a collection of their papers and letters), the scientist decides to add this letter to the pile (i.e., queue) of letters to reply to, eventually a reply is written. What is the distribution of waiting times for replies? Yes, it’s a power law, but with an exponent of -1.5, rather than -1.
The change made to the basic queueing model is to assign priorities to tasks, and then choose the task with the highest priority (rather than a random task, or the one that has been waiting the longest). Provided the queue never becomes empty (i.e., there are always waiting tasks), the waiting time is a power law with exponent -1.5; this behavior is independent of queue length and distribution of priorities (simulations confirm this behavior).
However, the exponent for my software data, and other data, is not -1.5, it is -1. A 2008 paper by Albert-László Barabási (detailed analysis) showed how a modification to the task selection process produces the desired exponent of -1. Each of the tasks currently in the queue is assigned a probability of selection, this probability is proportional to the priority of the corresponding task (i.e., the sum of the priorities/probabilities of all the tasks in the queue is assumed to be constant); task selection is weighted by this probability.
So we have a queueing model whose task waiting time is a power law with an exponent of -1. How well does this model map to software task selection behavior?
One apparent difference between the queueing model and waiting software tasks is that software tasks are assigned to a small number of priorities (e.g., Critical, Major, Minor), while each task in the model queue has a unique priority (otherwise a tie-break rule would have to be specified). In practice, I think that the developers involved do assign unique priorities to tasks.
Why wouldn’t a developer simply select what they consider to be the highest priority task to work on next?
Perhaps each developer does select what they consider to be the highest priority task, but different developers have different opinions about which task has the highest priority. The priority assigned to a task by different developers will have some probability distribution. If task priority assignment by developers is correlated, then the behavior is effectively the same as the queueing model, i.e., the probability component is supplied by different developers having different opinions and the correlation provides a clustering of priorities assigned to each task (i.e., not a uniform distribution).
If this mapping is correct, the task waiting time for a system implemented by one developer should have a power law exponent of -1.5, just like letter writing data.
The number of sprints that a story is assigned to, before being completely implemented, is a power law whose exponent varies around -3. An explanation of this behavior based on priority queues looks possible; we shall see…
The queueing models discussed above are a subset of the field known as bursty dynamics; see the review paper Bursty Human Dynamics for human behavior related aspects.
Recent Comments