Archive
Why is actual implementation time often reported in whole hours?
Estimates of the time needed to implement a software task are often given in whole hours (i.e., no minutes), with round numbers being preferred. Surprisingly, reported actual implementation times also share this ‘preference’ for whole hours and round numbers (around a third of short task estimates are accurate, so it is to be expected that around a third of actual implementation times will be some number of whole hours, at least for the small percentage of projects that record task implementation time).
Even for accurate estimates, some variation in minutes around the hour boundary is to be expected for the actual implementation time. Why are developers reporting integer hour values for actual time?
The following are some of the possible reasons, two at opposite ends of the spectrum, for developers to log actual time as an integer number of hours:
- Parkinson’s law, i.e., the task was completed earlier and the minutes before the whole hour were filled with other activities,
- striving to complete a task by the end of the hour, much like a marathon runner strives to complete a race on a preselected time boundary,
- performing short housekeeping tasks once the primary task is complete, where management is aware of this overhead accounting.
Is it possible to distinguish between these developer behaviors by analysing many task durations?
My thinking is that all three of these practices occur, with some developers having a preference for following Parkinson’s law, and a few developers always striving to get things done.
Given that Parkinson’s law is 70 years old and well known, there ought to be a trail of research papers analysing a variety of models.
Parkinson specified two ‘laws’. The less well known second law, specifies that the number of bureaucrats in an organization tends to grow, regardless of the amount of work to be done. Governments and large organizations publish employee statistics, and these have been used to check Parkinson’s second law.
With regard to Parkinson’s first law, there are papers whose titles suggest that something more than arm waving is to be found within. Sadly, I have yet to find a non-arm waving paper. Given the extreme difficulty of obtaining data on task durations, this lack of papers is not surprising.
Perhaps our LLM overlords, having been trained on the contents of the Internet, will succeed where traditional search engines have failed. The usual suspects (Grok, ChatGPT, Perplexity and Deepseek) suggested various techniques for fitting models to data, rather than listing existing models.
A new company, Kimi, launched their highly-rated model yesterday, and to try it out I asked: “Discuss mathematical models that analyse the impact of project staff following Parkinson’s law”. The quality of the reply was impressive (my registration has not yet been accepted, so I cannot obtain a link to Kimi’s response). A link to Grok 3’s evaluation of Kimi’s five suggested modelling techniques.
Having spent a some time studying the issues of integer hour actual times, I have not found a way to distinguish between the three possibilities listed above, using estimate/actual time data. Software development involves too many possible changeable activities to be amenable to Taylor’s scientific management approach.
Good luck trying to constrain what developers can do and when they can do it, or requiring excessive logging of activities, just to make it possible to model the development process.
Actual implementation times are often round numbers
To what extent do developers consciously influence the time taken to actually complete a task?
If the time estimated to complete a task is rather generous, a developer has the opportunity to follow Parkinson’s law (i.e., “work expands so as to fill the time available for its completion”), or if the time is slightly less than appears to be required, they might work harder to finish within the estimated time (like some marathon runners have a target time)?
The use of round numbers are a prominent pattern seen in task estimation times.
If round numbers appeared more often in the actual task completion time than would be expected by chance, it would suggest that developers are sometimes working to a target time. The following plot shows the number of tasks taking a given amount of actual time to complete, for project 615 in the CESAW dataset (similar patterns are present in the actual times of other projects; code+data):
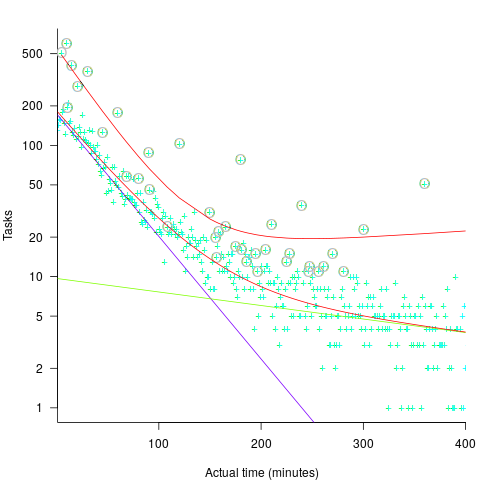
The red lines are a fitted bi-exponential distribution to the ‘spike’ (i.e., round numbers, circled in grey) and non-spike points (spikes automatically selected, see code for details), green and purple lines are the two components of the non-spike fit.
Tasks are not always started and completed in one continuous work session, work may be spread over multiple work sessions; the CESAW data includes the start/end time of every work session associated with each task (85% of tasks involve more than one work session, for project 615). The following plots are based on work sessions, rather than tasks, for tasks worked on over two (left) and three (right) sessions; colored lines denote session ordering within a task (code+data):
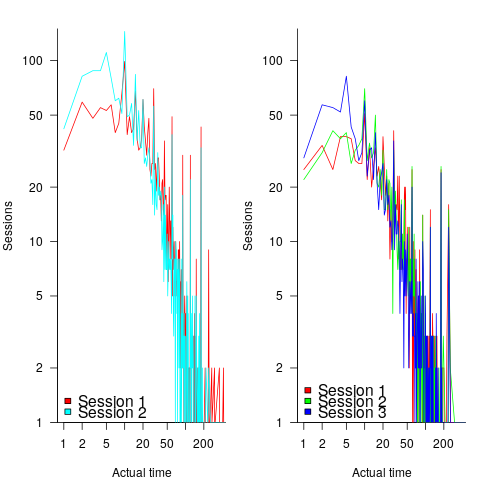
Shorter sessions dominate for the last session of task implementation, and spikes in the counts indicate the use of round numbers in all session positions (e.g., 180 minutes, which may be half a day).
Perhaps round number work session times are a consequence of developers using round number wall-clock times to start and end work sessions. The plot below shows (left) the number of work sessions starting at a given number of minutes past the hour, and (right) the number of work sessions ending at a given number of minutes past the hour; both for project 615 (code+data):

The arrow (green) shows the direction of the mean, and the almost invisible interior line shows that the length of the mean is almost zero. The five-minute points have slightly more session starts/ends than the surrounding minute values, but are more like bumps than spikes. The start of the hour, and 30-minutes, have prominent spikes, which might be caused by the start/end of the working day, and start/end of the lunch break.
Five-minutes is a convenient small rounding interval to either expand implementation time, or to target as a completion time. The following plot shows, for each of the 47 individuals working on project 615, the number of actual session times and the number exactly divisible by five. The green line shows the case where every actual is divisible by five, the purple line where 20% are divisible by five (expected for unbiased timing), the dashed purple lines show one standard deviation, the blue/green line is a fitted regression model ( ) (code+data):
) (code+data):
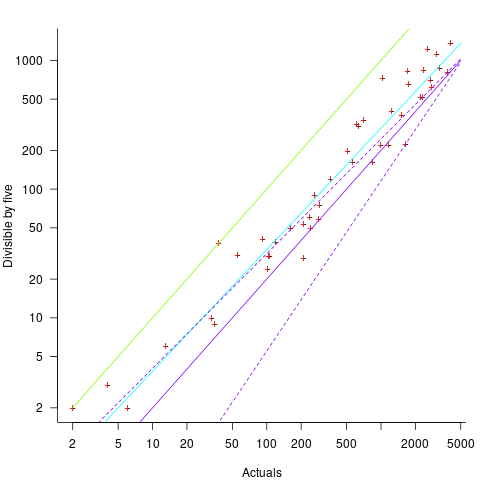
It appears that on average, five-minute session times occur twice as often as expected by chance; two individuals round all their actual session times (ok, it’s not that unlikely for the person with just two sessions).
Does it matter that some developers have a preference for using round numbers when recording time worked?
The use of round numbers in the recording of actual work sessions will inflate the total actual time for most tasks (because most tasks involve more than one session, and assuming that most rounding is not caused by developers striving to meet a target). The amount of error introduced is probably a lot less than the time variability caused by other implementation factors (I have yet to do the calculation).
I see the use of round numbers as a means of unpicking developer work habits.
Given the difficulty of getting developers to record anything, requiring them to record to minute-level accuracy appears at best optimistic. Would you work for a manager that required this level of effort detail (I know there is existing practice in other kinds of jobs)?
My new kitchen clock
After several decades of keeping up with the time, since November my kitchen clock has only been showing the correct time every 12-hours. Before I got to buy a new one, I was asked what I wanted to Christmas, and there was money to spend 🙂
Guess what Santa left for me:

The Hermle Ravensburg is a mechanical clock, driven by the pull of gravity on a cylindrical 1kg of Iron (I assume).
Setup requires installing the energy source (i.e., hang the cylinder on one end of a chain), attach clock to a wall where there is enough distance for the cylinder to slowly ‘fall’, set the time, add energy (i.e., pull the chain so the cylinder is at maximum height), and set the pendulum swinging.
The chain is long enough for eight days of running. However, for the clock to be visible from outside my kitchen I had to place it over a shelf, and running time is limited to 2.5 days before energy has to be added.
The swinging pendulum provides the reference beat for the running of the clock. The cycle time of a pendulum swing is proportional to the square root of the distance of the center of mass from the pivot point. There is an adjustment ring for fine-tuning the swing time (just visible below the circular gold disc of the pendulum).
I used my knowledge of physics to wind the center of mass closer to the pivot to reduce the swing time slightly, overlooking the fact that the thread on the adjustment ring moved a smaller bar running through its center (which moved in the opposite direction when I screwed the ring towards the pivot). Physics+mechanical knowledge got it right on the next iteration.
I have had the clock running 1-second per hour too slow, and 1-second per hour too fast. Current thinking is that the pendulum is being slowed slightly when the cylinder passes on its slow fall (by increased air resistance). Yes dear reader, I have not been resetting the initial conditions before making a calibration run 😐
What else remains to learn, before summer heat has to be adjusted for?
While the clock face and hands may be great for attracting buyers, it has serious usability issues when it comes to telling the time. It is difficult to tell the time without paying more attention than normal; without being a few feet from the clock it is not possible to tell the time by just glancing at it. The see though nature of the face, the black-on-black of the end of the hour/minute hands, and the extension of the minute hand in the opposite direction all combine to really confuse the viewer.
A wire cutter solved the minute hand extension issue, and yellow fluorescent paint solved the black-on-black issue. Ravensburg clock with improved user interface, framed by faded paint of its predecessor below:

There is a discrete ting at the end of every hour. This could be slightly louder, and I plan to add some weight to the bell hammer. Had the bell been attached slightly off center, fine volume adjustment would have been possible.
Time-to-fix when mistake discovered in a later project phase
Traditionally the management of software development projects divides them into phases, e.g., requirements, design, coding and testing. A mistake introduced in one phase may not be detected until a later phase. There is long-standing folklore that earlier mistakes detected in later phases are much much more costly to fix persists, despite the original source of this folklore being resoundingly debunked. Fixing a mistake later is likely to a bit more costly, but how much more costly? A lack of data prevents reliable analysis; this question also suffers from different projects having different cost-to-fix profiles.
This post addresses the time-to-fix question (cost involves all the resources needed to perform the fix). Does it take longer to correct mistakes when they are detected in phases that come after the one in which they were made?
The data comes from the paper: Composing Effective Software Security Assurance Workflows. The 35,367 (yes, thirty-five thousand) logged fixes, from 39 projects drawn from three organizations, contains information on: phases in which the mistake was made and fixed, time taken, person ID, project ID, date/time, plus other stuff 🙂
Every project has its own characteristics that affect time-to-fix. Project 615, avionics software developed by organization A, has the most fixes (7,503) and is analysed here.
Avionics software is safety critical, and each major phase included its own review and inspection. The major phases include: requirements gathering, requirements analysis, high level design, design, coding, and testing. When counting the number of phases between introduction/fix, should review and inspection each count as a phase?
The primary reason for doing a review and inspection is to check the correctness (i.e., lack of mistakes) in the corresponding phase. If there is a time-to-fix penalty for mistakes found in these symbiotic-phases, I suspect it will be different from the time-to-fix penalty between major phases (which for simplicity, I’m assuming is major-phase independent).
The time-to-fix has a resolution of 1-minute, and some fix times are listed as taking a minute; 72% of fixes are recorded as taking less than 10-minutes. What kind of mistakes require less than 10-minutes to fix? Typos and other minutiae.
The plot below shows time-to-fix for mistakes having a given ‘distance’ between introduction/fix phase, for fixes taking at least 1, 5 and 10-minutes (code+data):
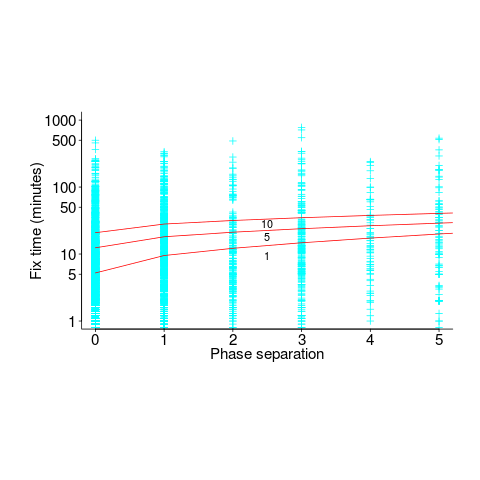
There is a huge variation in time-to-fix, and the regression lines (which have the form:  ) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
All but one of the 38 people who worked on the project made multiple fixes (30 made more than 20 fixes), and may have got faster with practice. Adding the number of previous fixes by people making more than 20 fixes to the model gives:  , and improves the model by less than 1-percent.
, and improves the model by less than 1-percent.
Fixing mistakes is a human activity, and individual performance often has a big impact on fitted models. Adding person ID to the model as a multiplication factor: i.e.,  , improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of
, improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of  varies between 0.66 and 1.4 (factor of two, human variation).
varies between 0.66 and 1.4 (factor of two, human variation).
The answer to the time-to-fix question posed earlier (for project 615), is that it does take slightly longer to fix a mistake detected in phases occurring after the one in which the mistake was introduced. The phase difference is tiny, with differences in human performance having a bigger impact.
A 1948 viewpoint on developer vs. computer time
For a long time now developer time has been a lot more expensive than computer time. The idea that developers should organize what they do, so as to maximize the efficiency of computer time rather than their own time, is considered to be an echo from a bygone age.
Until recently, I thought the transition from this bygone age, when computer time was considered more important than developer time, started in the late 1960s. Don’t ask me why I thought this, put it down to personal bias.
I was recently reading A Survey of Eniac Operations and Problems: 1946-1952, published in 1952, and what did I find:
“Early in 1948, R. F. Clippinger and some of his associates, in the course of coding the solution of …, were forced to adopt a different method of using the Eniac in order to fit their problem on the machine. …. The experience with this method (first discussed in reference 1), led J. von Neumann to suggest the use of a serial code for control of the Eniac. Such a code was devised and employed with the Eniac beginning in March 1948. Operation of the Eniac with this code was several times slower than either the original method of direct programming or the code for parallel operation. However, the resulting simplification of coding techniques and other advantages far outweighed this disadvantage.”
In other words, in 1948, the people using one of the few computers in the world, which clocked at 100KHz, considered developer time to be more important than computer time.
Recent Comments