Archive
Estimating variance when measuring source
Yesterday I finally delivered a paper on if/switch usage measurements to the ACCU magazine editor and today I read about a switch statement usage that, if common, would invalidate a chunk of my results. Does anything jump out at you in the following snippet?
switch (x) { case 1: { z++; ... break; } ... |
Yes, those { } delimiting the case-labeled statement sequence. A quick check of my C source benchmarks showed this usage occurring in around 1% of case-labels. Panic over.
What is the statistical significance, i.e., variance, of that 1%? Have I simply measured an unrepresentative sample, what would be a representative sample and what would be the expected variance within a representative sample?
I am interested in commercial software development, and so I have selected half a dozen or so largish code bases as my source benchmark, preferably written in a commercial environment even if currently available as Open source. I would prefer this benchmark to be an order of magnitude larger, and perhaps I will get around to adding more programs soon.
My if/switch measurements were aimed at finding usage characteristics that varied between the two kinds of selection statements. One characteristic measured was the number of equality tests in the associated controlling expression. For instance, in:
if (x == 1 || x == 2) z--; else if (x == 3) z++; |
the first controlling expression contains two equality tests, and the second one equality test.
Plotting the percentage of equality tests that occur in the controlling expressions of if-if/if-else-if sequences and switch statements, we get the following:
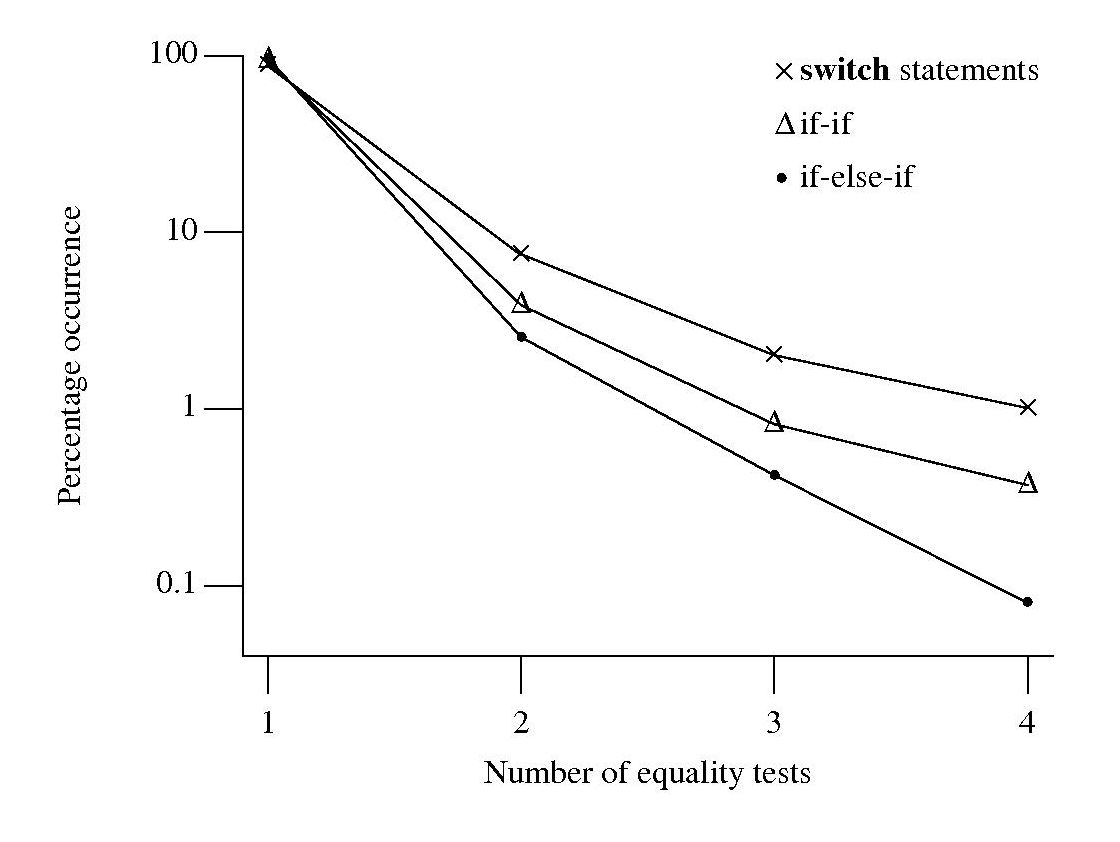
Do these results indicate that if-if/if-else-if sequences and switch statements differ in the number of equality tests contained in their controlling expressions? If I measured a completely different set of source code, would the results be very different?
To answer this question, a probability model is needed. Take as an example, the controlling expressions present in an if-if sequence. If each controlling expression is independent of the others, then the probability of two equality tests, for instance, occurring in any of these expressions is constant and thus given a large sample the distribution of two equality tests in the source has a binomial distribution. The same argument can be applied to other numbers of equality tests and other kinds of sequence.

For each measurement point in the above plot the associated error bars span the square-root of the variance of that point (assuming a binomial distribution, for a normal distribution the length of this span is known as the standard deviation). The error bars overlap, suggesting that the apparent difference in percentage of equality tests in each kind of sequence is not statistically significant.
The existence of some dependency between controlling expression equality tests would invalidate this simply analysis, or at least reduce its reliability. I did notice that in a sequence that containing two equality tests, the controlling expression that contained it tended to appear later in the sequence (the reverse of the example given above). Did I notice this because I tend to write this way? A question for another day.
Using Coccinelle to match if sequences
I have been using Coccinelle to obtain measurements of various properties of C if and switch statements. It is rare to find a tool that does exactly what is desired, but it is often possible to combine various tools to achieve the desired result.
I am interested in measuring sequences of if-else-if statements and one of the things I wanted to know was how many sequences of a given length occurred. Writing a pattern for each possible sequence was the obvious solution, but what is the longest sequence I should search for? A better solution is to use a pattern that matches short sequences and writes out the position (line/column number) where they occur in the code, as in the following Coccinelle pattern:
@ if_else_if_else @ expression E_1, E_2; statement S_1, S_2, S_3; position p_1, p_2; @@ if@p_1 (E_1) S_1 else if@p_2 (E_2) S_2 else S_3 @ script:python @ expr_1 << if_else_if_else.E_1; expr_2 << if_else_if_else.E_2; loc_1 << if_else_if_else.p_1; loc_2 << if_else_if_else.p_2; @@ print "--- ifelseifelse" print loc_1[0].line, " ", loc_1[0].column, " ", expr_1 print loc_2[0].line, " ", loc_2[0].column, " ", expr_2 |
noting that in a sequence of source such as:
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
the tokens if (x == 2) will be matched twice, the first setting the position metavariable p_2 and then setting p_1. An awk script was written to read the Coccinelle output and merge together adjacent pairs of matches that were part of a longer if-else-if sequence.
The first pattern did not concern itself with the form of the controlling expression, it simply wrote it out. A second set of patterns was used to match those forms of controlling expression I was interested in, but first I had to convert the output into syntactically correct C so that it could be processed by Coccinelle. Again awk came to the rescue, converting the output:
--- ifelseifelse 186 2 op == FFEBLD_opSUBRREF 191 7 op == FFEBLD_opFUNCREF --- ifelseifelse 1094 3 anynum && commit 1111 8 ( c [ colon + 1 ] == '*' ) && commit |
into a separate function for each matched sequence:
void f_1(void) { // --- ifelseifelse /* 186 2 */ op == FFEBLD_opSUBRREF ; /* 191 7 */ op == FFEBLD_opFUNCREF ; } void f_2(void) { // --- ifelseifelse /* 1094 3 */ anynum && commit ; /* 1111 8 */ ( c [ colon + 1 ] == '*' ) && commit ; } |
The Coccinelle pattern:
@ if_eq_1 @ expression E_1; constant C_1, C_2; position p_1, p_2; @@ E_1 == C_1@p_1 ; E_1 == C_2@p_2 ; @ script:python @ expr_1<< if_eq_1.E_1; const_1 << if_eq_1.C_1; const_2 << if_eq_1.C_2; loc_1 << if_eq_1.p_1; loc_2 << if_eq_1.p_2; @@ print loc_1[0].line, " ", loc_1[0].column, " 3 ", expr_1, " == ", const_1 print loc_2[0].line, " ", loc_2[0].column, " 2 ", expr_1, " == ", const_2 |
matches a sequence of two statements which consist of an expression being compared for equality against a constant, with the expression being identical in both statements. Again positions were written out for post-processing, i.e., joining together matched sequences.
I was interested in any sequence of if-else-if that could be converted to an equivalent switch-statement. Equality tests against a constant is just one form of controlling expression that meets this requirement, another is the between operation. Separate patterns could be written and run over the generated C source containing the extracted controlling expressions.
Breaking down the measuring process into smaller steps reduced the amount of time needed to get a final result (with Coccinelle 0.1.19 the first pattern takes round 70 minutes, thanks to Julia Lawall‘s work to speed things up, an overhead that only has to occur once) and allows the same controlling expression patterns to be run against the output of both the if-else-if and if-if patterns.
At the end of this process I ended up with a list information (line numbers in source code and form of controlling expression) on if-statement sequences that could be rewritten as a switch-statement.
To if-else-if or if-if, that is the question
I am currently measuring if-statements, occurring in visible source, that might be mapped to an equivalent switch-statement. The most obvious usage to look for is a sequence of if-else-if statements that all involve the same expression being tested against an integer constant, as in
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
Another possible sequence is:
if (x == 1) stmt_1; if (x == 2) stmt_2; if (x == 3) stmt_3; |
provided all but the last conditionally executed arms do not change the value of the common control variable (e.g., x).
I started to wonder about what would cause a developer to chose one of these forms over the other. Perhaps the if-if form would be used when it was obvious that the common conditional variable was not modified in the conditionally executed arm. This would imply that there would be more statements in the arms of if-else-if sequences than if-if sequences. The following plot of percentage occurrence (over all detected if-else-if/if-if forms) of line number difference between pars of associated if-statements (e.g., when the controlling expression occurs on line
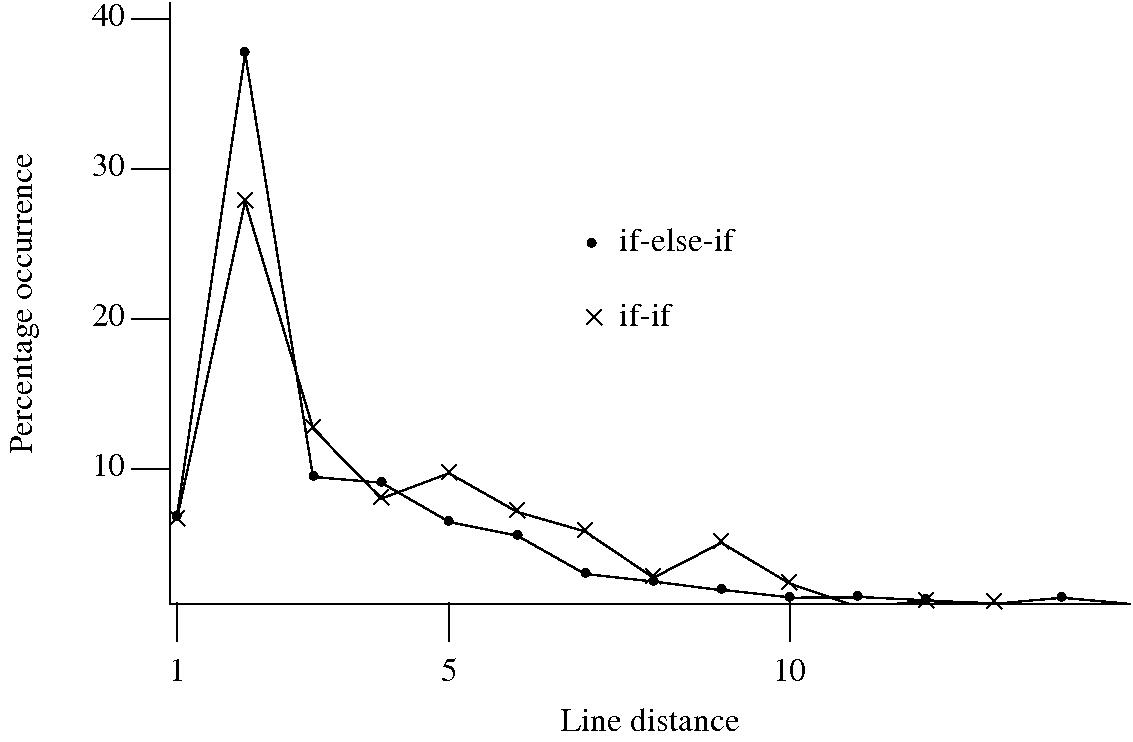
Just over a quarter of the arms contain a single statement (or to be exact the code is contained on a single line); this suggests that when using the if-else-if form most developers put the else and if on the same line. At the next distance along the percentage of if-else-if forms is twice as great as the if-if, probably because of else and if appearing on separate lines (as in the introductory example) in one case and less frequently a comment/blank line in the other. Next along, why the big increase in if-if forms? A comment + blank line, or perhaps no comment or blank line but the use of curly brackets (this is too off the track of where I am supposed to be going to investigate).
This morning I realized why the original plot did not look right, one of the data sets was a way off adding to 100%. An updated version has been uploaded.
It turns out that a single statement (or at least a single line) is more common in the if-else-if form, the opposite of what I had expected. At slightly larger distances there are still differences that can be attributed to else and if appearing on separate lines, curly brackets and a comment/blank line, but the effect is not as large as seen in the original, less accurate, plot.
I have a feeling that I ought to say something about the if-else-if form being preferred to the if-if form. One of the forms will have its behavior changed if the common control variable is modified in one of its arms. But is this an intended or unintended behavior? What is the typical characteristic usage of a common control variable, e.g., do they tend to be accessed but not modified in a given function definition? At the moment I see no obvious cost or benefit strongly favoring one usage over the other, so I will remain silent on the issue.
Finding the ‘minimum’ faulty program
A few weeks ago I received an inquiry about running a course/workshop on compiler writing. This does not does not happen very often and it reminded me that many years ago the ACCU asked if I would run a mentored group on compiler writing, I was busy writing a book at the time. The inquiry got me thinking it would be fun to run a compiler writing mentored group over a 6-9 month period and I emailed the general ACCU reflector asking if anybody was interested in joining such a group (any reader wanting to join the group has to be a member of the ACCU).
Over the weekend I had a brainwave for a project, automatic compiler test generation coupled with a program source code minimizer (I need a better name for this bit). Automatic test generation sounds great in theory but in practice whittling down the source code of those programs that result in a fault being exhibited, to create a usable sized test case that is practical for debugging purposes can be a major effort. What is needed is a tool to automatically do the whittling, i.e., a test case minimizer.
A simple algorithm for whittling down the source of a large test program is to continually throw away that half/third/quarter of the code that is not needed for the fault to manifest itself. A compiler project that took as input source code, removed half/third/quarter of the code and generated output that could be compiled and executed is realistic. The input/reduce/output process could be repeated until the generated source was considered to have reached some minima. Ok, this will soak up some cpu time, but computers are cheap and people are expensive.
Where does the test source code come from? Easy, it is generated from the same yacc grammar that the compiler, written by the mentored group member, uses to parse its input. Fortunately such a generation tool is available and ready to use.
The beauty is using the same grammar to generate tests and parse input. This means there is no need to worry about which language subset to use initially and support for additional language syntax can be added incrementally.
Experience shows that automatically generated test programs quickly uncover faults in production compilers, even when working with language subsets. Compiler implementors are loath to spend time cutting down a large program to find the statement/expression where the fault lies, this project will produce a tool that does the job for them.
So to recap, the mentored group is going to write one or more automatic source code generators that will be used to stress test compilers written by other people (e.g., gcc and Microsoft). Group members will also write their own compiler that reads in this automatically generated source code, throws some of it away and writes out syntactically/semantically correct source code. Various scripts will be be written to glue this all together.
Group members can pick the language they want to work with. The initial subset could just include supports for integer types, if-statements and binary operators.
If you had trouble making any sense all this, don’t join the group.
Using third party measurement data
Until today, to the best of my knowledge, all the source code analysis papers I have read were written by researchers who had control of the code analysis tools they used and had some form of localised access to the source. By control of the code analysis tools I mean that the researchers specified the tool options and had the ability to check the behavior of the tool, in many cases the source of the tool was available to them and often even written by them, and the localised access may have involved downloading lots of code from the web.
I have just been reading about a broad brush analysis of comment usage based on data provided by a commercial code repository that offers API access to some basic code metrics.
At first, I was very frustrated by the lack of depth to the analysis provided in the paper, but then I realised that the authors’ intent was to investigate a few broad ideas about comment usage in a large number of projects (around 10,000). The authors complained in their blog about some of the referees comments and having to submit a shorter paper. I can see where the referees are coming from, the papers are lacking in depth of analysis, but they do contain some interesting results.
I was very interested in Figure 2:
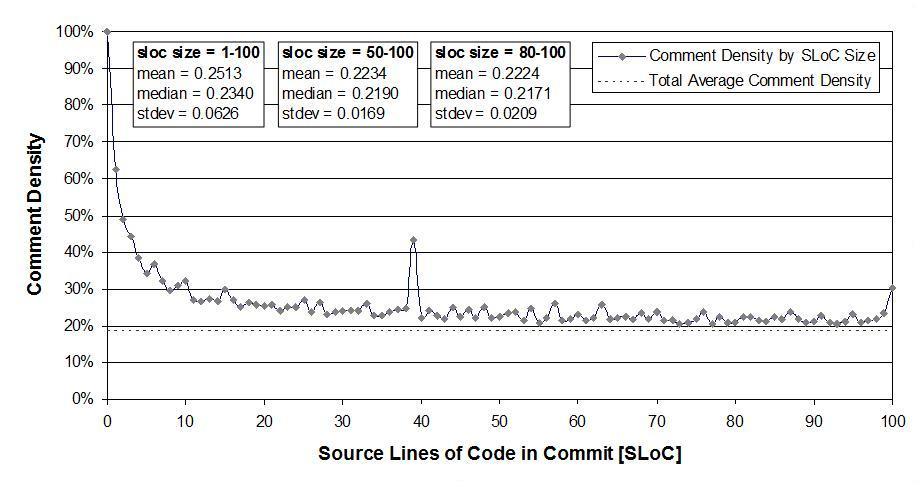
which plots the comment density of the lines in a source code commit. I would expect the ratio to be higher for small commits because a developer probably has a relatively fixed amount to say about updates involving a smallish number of lines (which probably fixes a problem). Larger commits are probably updated functionality and so would have a comment density similar to the ‘average’.
The problem with relying on third parties to supply the data is that obtaining the answers to follow up questions invariably involves lots of work, e.g., creating an environment to perform the measurements needed for the follow-up questions. However, the third party approach can significantly reduce the amount of work needed to get to a point where the interestingness of the results can be gauged.