Archive
Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
Hexadecimal usage in Google’s scanned books
After investigating programming language name usage in Google’s ngram viewer, I decided to try something more specific. Hexadecimal literals are an interesting subproblem in optical character recognition; a little uncertainty in an image can result in a character sequence being equally viable as a word or a hexadecimal literal.
I downloaded all the Google books 1-grams and started to experiment. I eventually considered any character sequence matching the pattern ^[0oO][xX][0-9a-fA-FoOl] for further analysis; that is ohh, Ohh and ell were treated as the corresponding digits.
This prefix matching reduced 473 million possibilities down to 89 thousand.
Next any character sequence containing a non-hex character (again ohh, Ohh and ell were treated as special cases) was removed, bringing the possibilities down to 20 thousand.
When did the first hexadecimal literal appear in print? I settled on a generous view of history, 1945; also the sequence oxo seemed surprisingly common and looking at a few of the contexts in which it occurred I decided that most of the usage related to chemical formula and removed all matches. The post-1945 and oxo checks removed a third of remaining character sequences.
It seems to me that if any hexadecimal literal appears in a book, at least one more is likely to occur. Google does not provide a breakdown of each character sequence by book; for a given character sequence, the total count for each year is given, along with the number of pages it occurred on in that year and the number of different books it appeared within in the year. If the number of occurrences of a character sequence in a given year equalled the number of different books I excluded the usage count; this reduced the number of matches from 13,729 to 7,292; with 319 unique character sequences.
Are the remaining of character sequences a reasonably accurate list of hexadecimal literals appearing in the books that Google has scanned? Is 0.15 hexadecimal literals per million words a reasonable value?
A while back, I did some analysis of C source usage that included checking whether integer literals followed Benford’s law. Extracting the first non-zero digit from the character sequences extracted from Google books and comparing them with the C source hexadecimal data we get:
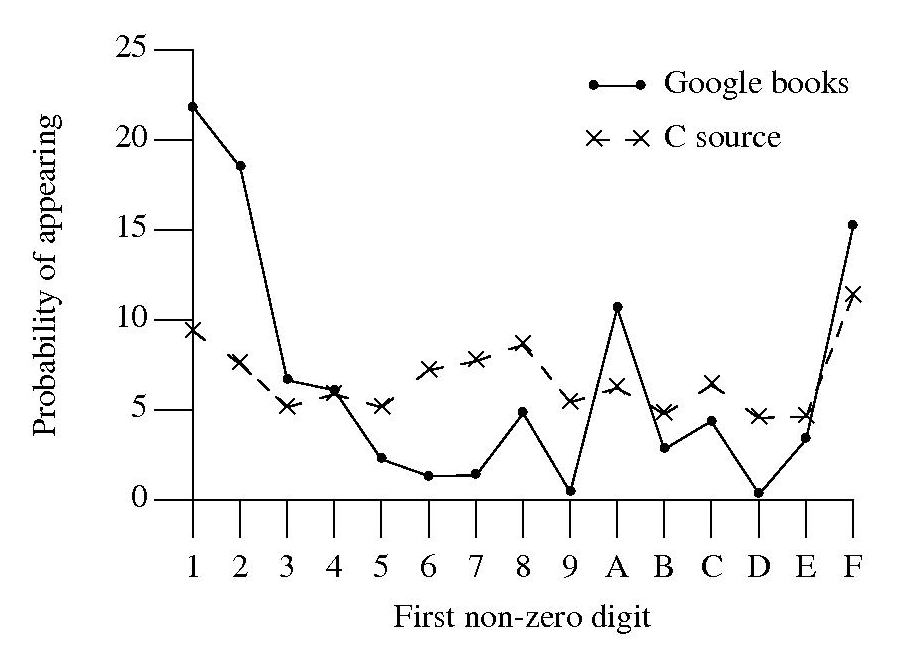
Both plots share ‘spikes’ at five values, but the pattern of relative sizes is different. Perhaps the pattern of hexadecimal literal usage in C source is slightly different from what occurs in other languages, or perhaps the relatively large percentage of 1 occurs because ell is accepted.
The context in which a character sequenced occurred would probably be a very good indicator of whether it was a hexadecimal literal or not. Google only provide a subset of their 2-grams and any analysis of these will have to wait for another time; however I did quickly check to see whether the OCR process had resulted in a single literal being split into two separate sequences, a manual check of the 95 possible sequences I found showed that most were not good candidates for a split literal.
The final list of ‘hexadecimal literal’s and their occurrence counts is available for download.
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Christmas book for 2010
I’m rather late with my list of Christmas books for 2010. While I do have a huge stack of books waiting to be read I don’t seem to have read many books this year (I have been reading lots of rather technical blogs this year, i.e., time/thought consuming ones) and there is only one book I would strongly recommend.
Anybody with even the slightest of interest in code readability needs to read
Reading in the Brain by Stanislaw Dehaene (the guy who wrote The Number Sense, another highly recommended book). The style of the book is half way between being populist and being an undergraduate text.
Most of the discussion centers around the hardware/software processing that takes place in what Dehaene refers to as the letterbox area of the brain (in the left occipito-temporal cortex). The hardware being neurons in the human brain and software being the connections between them (part genetically hardwired and part selectively learned as the brain’s owner goes through childhood; Dehaene is not a software developer and does not use this hardware/software metaphor).
{kind=link}
As any engineer knows, knowledge of the functional characteristics of a system are essential when designing other systems to work with it. Reading this book will help people separate out the plausible from the functionally implausible in discussions about code readability.
Time and again the reading process has co-opted brain functionality that appears to have been designed to perform other activities. During the evolution of writing there also seems to have been some adaptation to existing processes in the brain; a lesson here for people designing code visualizations tools.
{kind=link}
{kind=link}
In my C book I tried to provide an overview of the reading process but skipped discussing what went on in the brain, partly through ignorance on my part and also a belief that we were a long way from having an accurate model. Dehaene’s book clearly shows that a good model of what goes on in the brain during reading is now available.
SEC wants prospectus source code to be published
The US Securities and Exchange Commission are proposing new rules involving the prospectuses for public offerings of asset-backed securities including publishing the source code used to calculate the contractual cash flow provisions.
Requiring that the source code used to perform the financial modeling for a prospectus be made available is an excellent idea. A prospectus document contains a huge number of technical details and more importantly for anybody trying to understand the thinking behind it, a lots of assumption. Writing a program requires that all necessary details be enumerated and appropriately connected together and more importantly creating code that can be meaningfully executed usually means making explicit any assumptions that were previously implicit.
There are parallels here with having access to the source code and data used to make climate predictions.
The authors of the proposals are naive to think that simply requiring source to be written in a language for which there is an open source implementation (i.e., Python) is all they need to specify for others to duplicate the program output generated by the proposer (I have submitted some suggestions to the SEC about the issues that need to be addressed). The suggestions that a formally defined language be used is equally naive.
The availability of this source code opens up some interesting commercial prospects. No, not selling analysis tools to financial institutions but selling them program fault information, e.g., under circumstance X the program incorrectly predicts A will happen when in fact B will actually happen. Of course companies know this will happen and will put a lot more effort into ensuring that their models/code is correct.
Will these disclosure rules change the characteristics of financial software? One characteristic that I’m sure will change is the percentage of swear words in the comments and identifiers.
The changing shape of code in the next decade
I think there are two forces that will have a major impact on the shape of code in the next decade:
- Asian developers. China and India each have a population that is more than twice as large as Europe and the US combined, and software development has been kick-started in these countries by a significant amount of IT out sourcing. I have one comparative data point for software developers who might be of the hacker ilk. A discussion of my C book on a Chinese blog resulted in a download volume that was 50% of the size of the one that occurred when the book appeared as a news item on Slashdot.
- Scripting languages. Software is written to solve a problem, and there are only so many packaged applications (COTS or bespoke) that can profitably be supported. Scripting languages are generally designed to operate within one application domain, e.g., Bash, numerical analysis languages such as R and graphical plotting languages such as gnuplot.
While markup languages are very widely used they tend to be read and written by programs not people.
Having to read code containing non-alphabetic characters is always a shock the first time. Simply having to compare two sequences of symbols for equality is hard work. My first experience of having to do this in real time was checking train station names once I had travelled outside central Tokyo and the names were no longer also given in Romaji.
其中,ul分别是bootmap_size(bit map的size),start_pfn(开始的页框) max_low_pfn(被内核直接映射的最后一个页框的页框号) ; |
Developers based in China and India have many different cultural conventions compared to the West (and each other) and I suspect that these will affect the code they write (my favorite potential effect involves treating time vertically rather than horizontally). Many coding conventions used by a given programming language community exist because of the habits adopted by early users of that language, these being passed on to subsequent users. How many Chinese and Indian developers are being taught to use these conventions, are the influential teachers spreading different conventions? I don’t have a problem with different conventions being adopted, other than that having different communities using different conventions increases the cost for one community to adopt another community’s source.
Programs written in a scripting language tend to be much shorter (often being contained within a single file) and make use of much more application knowledge than programs written in general purpose languages. Their data flow tends to be relatively simple (e.g., some values are read/calculated and passed to a function that has some external effect), while the relative complexity of the control flow seems to depend on the language (I only have a few data points for both assertions).
Because of their specialized nature, most scripting languages will not have enough users to support any kind of third party support tool market, e.g., testing tools. Does this mean that programs written in a scripting language will contain proportionally more faults? Perhaps their small size means that only a small number of execution paths are possible, and these are quickly exercised by everyday usage (I don’t know of any research on this topic).
Information content of expressions
Software developers read source code to obtain information. How might the information content of source code be quantified?
Both of the following functions assign the same value to x and if that is the only information a reader of that code is interested in, then the information content of both assignment statements could be said to be the same.
int foo(void) { x = 5; ... } int bar(void) { x = 2 + 3; ... |
A reader seeking deeper understanding of the above code would ask why the value 5 is built from two values in bar. One reason might be that the author of the function wanted to explicitly call out background information about how the value 5 was derived (this is often done using symbolic names, but the use of literals themselves is sometimes encountered). Perhaps the author of foo did not see the need to expose this information or perhaps the shared value is purely coincidental.
If the two representations denote the same quantity doesn’t the second have a greater information content for a reader seeking deeper understanding?
In the following example:
... x + y & z ... ... ... num_red + num_white & lower_bits ... |
an experienced developer with a knowledge of English is likely to interpret the expression as adding the number of occurrences of two quantities and using bit-wise AND to extract the lower bits. For some readers the second expression has a higher information content. Would use of the names number_of_red further increase the information content?
In the following example the first expression has not added any information that was not already present in the first expression above (except perhaps that the author was not certain of the precedence or perhaps did not expect subsequent readers to be certain).
... ( x + y ) & z ... ... ... x + ( y & z ) ... |
The second expression uses parenthesis to achieve an operand/operator binding that is different from the default. Has this changed the information content of the expression?
There is experimental evidence that developers extract information from the names of variables to help them make decisions about operator precedence. To me the name all_32_bits_one suggests a sequence of bits and I would expect such a representation to be associated with the bit-wise AND operator, not binary plus. With no knowledge of the relative precedence of the two operators in the following expression the name of the middle operand would cause me to misinterpret the code. Does this change the information content of the expression? Does knowledge of the experimental evidence and the correct operator precedence change the information content (i.e., there is a potential fault in the code because the author may have assumed the incorrect precedence)?
... num_red + all_32_bits_one & sign_bit ... |
There is experimental evidence that people use the amount of whitespace appearing between operands and their operators to visually highlight operator precedence
The relative quantities of whitespace used in the following two expressions appear to tell very different stories. Do the two expressions have a different information content?
... x + y & z ... ... ... x + y & z ... |
The idea of measuring the information content of source code is very enticing. However, an accurate measure requires knowledge of the kind of information a reader is trying to obtain and of information that already exists in their brain.
Another question is the easy with which information can be extracted from code. Something that might be labeled as readability, except that readability has connotations of there being an abundant supply of information to extract.
Software maintenance via genetic programming
Genetic algorithms have been used to find solution to a wide variety of problems, including compiler optimizations. It was only a matter of time before somebody applied these techniques to fixing faults in source code.
When I first skimmed the paper “A Genetic Programming Approach to Automated Software Repair” I was surprised at how successful the genetic algorithm was, using as it did such a relatively small amount of cpu resources. A more careful reading of the paper located one very useful technique for reducing the size of the search space; the automated software repair system started by profiling the code to find out which parts of it were executed by the test cases and only considered statements that were executed by these tests for mutation operations (they give a much higher weighting to statements only executed by the failing test case than to statements executed by the other tests; I am a bit surprised that this weighting difference is worthwhile). I hate to think of the amount of time I have wasted trying to fix a bug by looking at code that was not executed by the test case I was running.
I learned more about this very interesting system from one of the authors when he gave the keynote at a workshop organized by people associated with a source code analysis group I was a member of.
The search space was further constrained by only performing mutations at the statement level (i.e., expressions and declarations were not touched) and restricting the set of candidate statements for insertion into the code to those statements already contained within the code, such as if (x != NULL) (i.e., new statements were not randomly created and existing statements were not modified in any way). As measurements of existing code show most uses of a construct are covered by a few simple cases and most statements are constructed from a small number of commonly used constructs. It is no surprise that restricting the candidate insertion set to existing code works so well. Of course no fault fix that depends on using a statement not contained within the source will ever be found.
There is ongoing work looking at genetic modifications at the expression level. This
work shares a problem with GA driven test coverage algorithms; how to find ‘magic numbers’ (in the case of test coverage the magic numbers are those that will cause a controlling expression to be true or false). Literals in source code, like those on the web, tend to follow a power’ish law but the fit to Benford’s law is not good.
Once mutated source that correctly processes the previously failing test case, plus continuing to pass the other test cases, has been generated the code is passed to the final phase of the automated software repair system. Many mutations have no effect on program behavior (the DNA term intron is sometimes applied to them) and the final phase removes any of the added statements that have no effect on test suite output (Westley Weimer said that a reduction from 50 statements to 10 statements is common).
Might the ideas behind this very interesting research system end up being used in ‘live’ software? I think so. There are systems that operate 24/7 where faults cost money. One can imagine a fault being encountered late at night, a genetic based system fixing the fault which then updates the live system, the human developers being informed and deciding what to do later. It does not take much imagination to see the cost advantages driving expensive human input out of the loop in some cases.
An on-going research topic is the extent to which a good quality test suite is needed to ensure that mutated fault fixes don’t introduce new faults. Human written software is known to often be remarkably tolerant to the presence of faults. Perhaps ensuring that software has this characteristic is something that should be investigated.
Compiler writing: The career path to World domination
Compiler writing is not usually thought of as a career path that leads to becoming Ruler of the World. Perhaps this is because compiler writing is a relatively new profession and us compiler writers are still toiling in obscurity awaiting the new dawn.
What might be a workable plan for a compiler writer to become Ruler of the World? One possibility is to write a compiler for the language in which most of the World’s critical software is written (i.e., C) and for that compiler to become the one that the vendors of this critical software all use (i.e., gcc). This compiler needs to do more that just compile the source code it is feed, it also needs to generate code that creates a backdoor in important programs (e.g., the login program).
But, you say, this cannot happen with gcc because its source is available for everybody to read (and spot any backdoor generator). In his 1984 Turing acceptance lecture Ken Thompson showed how a compiler could contain a backdoor that was not visible in its source. The idea is for the compiler writer to modify a compiler to detect when it is being used to compile itself and to insert the backdoor generating code into its own executable. This modified compiler is then used to compile itself and the resulting executable made the default compiler; the backdoor modifications are then removed from the compiler source, they are no longer needed because the previously compiled compiler will spot when it is being used to compile its own source and generate the code necessary to propagate the backdoor code into the executable it creates.
How would the world counter the appearance of such a modified gcc? Obviously critical programs would need to be recompiled by a version of gcc that did not contain the backdoor. Today there are several companies and many amateur groups that distribute their own Linux distributions which they build from source. It should be relatively easy to obtain a usable executable of gcc from 10 years ago; remember what is needed is a version capable of compiling the latest gcc sources.
The ideal time to create a backdoor’ed version of gcc is while its development was under the control of one person, so early in the development history that all versions available anywhere are very likely to be derived from it. How can we prove that the original author of gcc did not do just this?
It could be argued that the very substantial changes to the gcc sources (most of the source has probably been rewritten several times) mean that the coding patterns searched for by the executable to detect that it is compiling itself have long gone and at some point the backdoor failed to propagate itself to the next executable.
Compilers other than gcc might also include backdoors that propagate themselves. However, the method of propagation is likely to be different. Compiling the gcc sources with a non-gcc compiler creates an executable that should exhibit the same behavior as a gcc-compiled executable. Differences in the behavior of these independently built executables is a cause for concern (one difference might be caused by differences in the conversion of floating-point literals, a recent PhD thesis provides more detail).
The problem with compiling the gcc sources is that they make use of language extensions that few, if any, other compilers support. I know IBM added modified one of their C compilers to support those gcc extensions needed to compile the Linux kernel, but I don’t know if this compiler is capable of compiling the gcc sources. The LLVM project intended to support many gcc extensions but I don’t know if they aim to be able to compile the gcc sources.
Another option is to compare the assembler generated when gcc compiles itself against the corresponding source code. A very expensive task for source code measured in hundreds of thousands of lines. Adding the necessary language extension support to another compiler would probably be cheaper and also create a tool that could be used to check future releases of gcc.
Does the Climategate code produce reliable output?
The source of several rather important commercial programs have been made public recently, or to be more exact programs whose output is important (i.e., the Sequoia voting system and code and data from the Climate Research Unit at University of East Anglia the so called ‘Climategate’ leak). While many technical commentators have expressed amazement at how amateurish the programming appears to be, apparently written with little knowledge of good software engineering practices or knowledge of the programming language being used, those who work on commercial projects know that low levels of software engineering/programming competence is the norm.
The emails included in the Climategate leak provide another vivid example, if one were needed, of why scientific data should be made publicly available; scientists are human and are sometimes willing to hide data that does not fit their pet theory or even fails to validate their theory at all.
The Climategate source has only only recently become available and existing technical commentary has been derived from embarassing comments and the usual complaint about not using the right programming language (Fortran is actually a good choice of language for this problem, it is widely used by climatology researchers and a non-professional programmer is probably makes best of their time by using the one language they know tolerably well rather than attempting to use a new language that nobody else in the research group knows).
An important quality indicator of the leaked software was what was not there, test cases (at least I could not find any). How do we know that a program’s output is correct? One way to gain some confidence in a program’s correctness is to process data for which the correct output is known. This blindness to the importance of program level correctness testing is something that I often encounter in people who are subject area experts rather than professional programmers; they believe that if the output has the form they are expecting it must be correct and will sometimes add ‘faults’ to ‘fix’ output that deviates from what they are expecting.
A quick visual scan through the source showed a tale of two worlds, one of single letter identifier names and liberal use of goto, and the other of what looks like meaningful names, structured code and a non-trivial number of comments. The individuals who have contributed to the code base obviously have very different levels of coding ability. Not having written any Fortran in anger for over 15 years my ability to estimate the impact of more subtle coding practices has atrophied.
What kind of faults might a code review look for in these programs? Common coding errors such as using uninitialized variables and incorrect argument passing are obvious choices and their are tools available to check for these kinds of error. A much more insidious kind of error, which requires people with the mathematical expertise to spot, is created by the approximate nature of floating-point arithmetic.
The source is not huge, but not small either, consisting of around 64,000 lines of Fortran and 16,000 lines of IDL (a language designed for interactive data analysis which to my untrained eye looks a lot like MATLAB). There was no obvious support for building the source included within the leaked files (e.g., no makefiles) and my attempt to manually compile using the GNU Fortran compiler failed miserably. So I cannot say anything reliable about the compiler output warnings.
To me the complete lack of test cases implies that the Climategate code does not produce reliable output. Comments in the code such as
***** APPLIES A VERY ARTIFICIAL CORRECTION FOR DECLINE*********suggests that the authors were willing to patch the code to produce output that matched their expectations; this is the mentality of somebody for whom code correctness is not an important issue and if they don’t believe their code is correct then I don’t either.Source code in itself is rarely that important, although it might have been expensive to create. The real important information in the leaked files is the climate data. Now that this is available others can apply their analysis skills to provide an interpretation to what, if anything statistically reliable, it is telling us.