Archive
Occurrence of binary operator overloading in C++
Operator overloading, like many programming language constructs, was first supported in the 1960s (Algol 68 also provided a means to specify a precedence for the operator). C++ is perhaps the most widely used language supporting operator overloading; but not redefining their precedence.
I have always thought that operator overloading was more talked about than actually used (despite its long history, I have not been able to find any published usage information). A previous post noted that the CodeQL databases hosted by GitHub provides the data needed to measure usage, and having wrestled with the documentation (ql scripts used), C++ operator overload usage data is available.
The table below shows the total uses of overloaded and ‘usual’ binary operators in the source code (excluding headers) of 77 C++ repositories on GitHub (the 100 repositories C/C+ MRVA). The table is ordered by total occurrences of overloads, with the Percentage column showing the percentage use of overloaded operators against the total for the respective operator (i.e.,  ; code and data):
; code and data):
Binary Overload Usual Total Percentage << 103,855 20,463 124,318 83.5 == 21,845 118,037 139,882 15.6 != 14,749 69,273 84,022 17.6 * 12,849 57,906 70,755 18.2 + 10,928 103,072 114,000 9.6 && 8,183 64,148 72,331 11.3 - 5,064 77,775 82,839 6.1 <= 3,960 18,344 22,304 17.8 & 3,320 27,388 30,708 10.8 < 1,351 93,393 94,744 1.4 >> 1,082 11,038 12,120 8.9 / 1,062 29,023 30,085 3.5 > 537 44,556 45,093 1.2 >= 473 27,738 28,211 1.7 | 293 13,959 14,252 2.0 ^ 71 1,248 1,319 5.4 <=> 13 12 25 52.0 % 11 9,338 9,349 0.1 || 9 53,829 53,838 0.017 |
Use of the overloaded << operator is driven by standard library I/O, rather than left shifting.
There are seven operators where 10-20% of the usage is overloaded, which is a lot higher than I was expecting (not that I am a C++ expert).
How much does overloaded binary operator usage vary across projects? In the plot below, each vertical colored violin plot shows the distribution of overload usage for one operator across all 77 projects (the central black lines denote the range of the central 50% of the points; code and data):

While there is some variation between these 77 projects, in most cases a non-trivial percentage of an operator's usage is overloaded.
Best tool for measuring lots of source code
Human written source code contains various common usage patterns. This blog has analysed a variety of these patterns, and in a few cases built models of processes that replicate these patterns. The data for this analysis has primarily comes from programs written in C and Java, because these are the languages that researchers most often study (tool availability and herd mentality).
Do these common usage patterns occur in other languages, or at least other C/Java like languages? I think so, and have set out to collect the necessary data. Obtaining this data requires large quantities of code written in many languages, and the ability to analyse code written in these languages.
GitHub contains huge quantities of code. There are two freely available source code analysis tools supporting many languages: Opengrep (the Open source version of semgrep) and CodeQL.
CodeQL’s method of operation had previously put me off trying it. The method is a two stage process: First a database of information is created by extracting information during a project’s build process (e.g., running existing makefiles and host compilers), followed by querying this database using a declarative language (think minimalist SQL with lots of built-in functions). This approach has the huge advantage of not having to worry about handling compiler dialects/options, however, I’m an ingrained user of tools that process individual files.
From the research perspective, CodeQL has a major feature that is not available with other tools. GitHub, who now owns CodeQL, host thousands of project databases and GitHub Actions allows third-parties to scan up to 1,000 databases of the most popular projects. Access to existing CodeQL databases removes the need to download repo/build project/store database locally.
CodeQL, like other static analysis tools, was designed to find issues/problems in code, and so might not support the kind of functionality I needed to extract source code measurements. The best way to find out if the data of interest could be extracted is to try and do it.
In the best developer tradition, I downloaded a prebuilt release (available for Linux, Windows and Mac; called CodeQL Bundles), skimmed the documentation, ran a simple QL script and spent an hour or two trying to figure out why I was getting Java runtime errors, e.g., “no String-argument constructor/factory method to deserialize from String value“.
Progress would have been faster if I had used Visual Studio Code, available free from the owners of GitHub, rather than the command line. The documentation is not command line oriented. Visual Studio handles details like creating a qlpack.yml file (whose necessary existence I eventually found out about). Also, the harmless looking metadata appearing in comments is necessary and had better match the output parameters of the query. How hard is it to warn that a file could not be found, or that metadata is missing?
The code databases are queried using the declarative language QL, which is a kind of minimal SQL (with the select appearing last, rather than first). The import statement specifies the language, or rather the name of a library module.
The imported library contains classes for each language construct (e.g., BlockStmt, Function, ArrayExpr, etc). In the query below, the line “from LocalScopeVariable lv” extracts all local scope variables, which can subsequently be referred to via the name lv. The where line lists conditions that must be met (in this example, not be a parameter and not be accessed; testing for unused variables). The select line invokes methods that return various kinds of information about the class, e.g., the name of the variable, and location within the source.
/** * @id compound-stmt * @kind problem * @problem.severity warning */ import cpp from LocalScopeVariable lv where not lv instanceof Parameter and not exists(lv.getAnAccess()) select "", ""+lv.getName()+ ","+lv.getLocation().getStartLine()+ ","+lv.getLocation().getEndLine()+ ","+lv.getEnclosingFunction()+","+bs.getFile() |
The output generated is driven by the select, whose number/kind of arguments must match that specified by the metadata.
Developers can write and call functions, such as this one:
predicate header_suffix(string fstr) { fstr = "h" or fstr = "H" or fstr = "hpp" } |
The QL language is a declarative logical query language with roots in Datalog (subset of Prolog). The claim that it is an object-oriented language is technically correct, in that it groups functions into things called classes and supports various constructs usually found in object-oriented languages. The language has the feel of an academic project that happened to be used in a tool that was in the right place at the right time. Using host compilers to enable the tool to support many languages must have been very attractive to GitHub.
Coding in a declarative logic language requires a major mindset change. There are no loops, if statements or assignments. The query is one, potentially very long and complicated, predicate. A mindset change is necessary, but not sufficient, some fluency with the library of functions available is also needed. For instance, the isSideEffectFree predicate is true/false, but does not return a value (so there is nothing to print). I wanted to output 0/1, depending on whether a function was side effect free or not. When asked, all the LLMs questioned insisted that QL supported if-statements and assignment, just like other languages. After lots of dead-ends, an LLM claimed that “CodeQL automatically treats boolean expressions in count as 1/0″, and a test run showed this to be the case:
count(int dummy | dummy = 1 and func.isSideEffectFree() | dummy) |
The QL scripts needed to extract all the data of immediate interest to me were easily implemented. Looking at existing scripts has given me some ideas for more patterns I might measure. CodeQL currently supports 10 languages, and their classes appear to be slightly different (my initial focus is C, C++, Java and Python).
Visual Studio Code is required to run multi-repository variant analysis, i.e., scan up to 1,000 project databases on GitHub. It was after installing the CodeQL extension that I discovered how much smoother the process is within this IDE, compared to the command line (and off course the output is slightly different). There may be alternatives to Visual Studio, but I’m sticking with what the official documentation says.
Stepping back, is CodeQL a useful tool?
For me it is currently very useful, because of the large number of project databases. Some practice is needed to achieve some fluency in the use of a declarative logic language, not a major hurdle.
The need to run queries against a project database may be a major inconvenience for some developers, depending on working practices. Those practicing continuous integration should be ok.
Distribution of integer literals in text/speech and source code
Numeric values are an integral to communication between people. What is the distribution of integer values in text/speech, and does the use of integer literals in source code have a similar distribution?
- The paper Numbers in Context: Cardinals, Ordinals, and Nominals in American English by Greg Woodin, and Bodo Winter studied the 9+ million numbers contained in the Corpus of Contemporary American English (7,744,038 integer values). The plot below shows the number of occurrences of the smaller integer values, and a fitted regression line for values in the range 1..50 (code+data):

The frequency of integer values in this corpus is proportional to:
 .
. - The paper Frequency of occurrence of numbers in the World Wide Web by Dorogovtsev, Mendes, and Gama Oliveira found that the number of web pages containing a given integer value declines as the value increases, with the decline for non-round numbers being roughly proportional to
 (round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives
(round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives  (for values up to
(for values up to  ).
).
Programs are an implementation of a sliver of the world in which people live, and it is to be expected that the frequency of numeric literal values in source code is highly correlated with real world frequency. Numeric values also appear in the algorithms and mathematical expressions used to create implementations. I am not aware of any studies looking at the frequency of use of numeric constants in algorithms and mathematics. As an aside, the frequency of occurrence of mathematical expressions containing a given number of operators is similar to that in C source
What are the usage characteristics of integer literals in source code (floating-point literal use is very rare outside of particular application domains)?
The plot below shows occurrences of decimal (green) and hexadecimal (blue) literals in C source (data from fig 825.1 from my C book) with a regression line fitted to values 1..50 of the decimal data (code+data):

The frequency of decimal literal values in C source is proportional to: . Adding the hexadecimal values to the model has little effect.
The paper What do developers consider magic literals? A smalltalk perspective by Anquetil, Delplanque, Ducasse, Zaitsev, Fuhrman, and Guéhéneuc studied the use of literals in Smalltalk. The plot below shows the number of occurrences of all kinds of integer literals and a fitted regression line (code+data):

The frequency of integer literal values in Smalltalk source is proportional to:  .
.
The distribution of integer literals in both human communication and source code is well-fitted by a power law. Smalltalk appears to be the outlier, with an exponent of 1.7 vs 1.3-1.4. Perhaps it’s a sample size issue; 14,054 integer literals for Smalltalk and a million+ for the other datasets.
I had expected source code to contain a lot more zeroes/ones, relative to other values, than human communication. Zero/one are such common values that there are implicit short-cuts that people can use to express them; removing the effort/cost needed to explicitly specify them. Some programming languages specify default 0/1 values for common idioms, but C-like languages generally require explicit specification of values.
Quantity of source in a given language
How much source code exists in a particular language?
Traditionally, indicators of the quantity of source in a language is the number of people making a living working on software written in the language. Job adverts are a proxy for the number of people employed to write/support programs implemented in a language (i.e., number of times a language is specified in the text of an advert), another proxy used to be the financial wellbeing of compiler vendors (many years ago, Open source compilers drove most companies out of the business of selling compilers).
Current job adverts are a measure of the code that likely to be worked now and in the near future. While Cobol dominated the job adverts decades ago, it is only occasionally seen today, suggesting that a lot of Cobol source is no longer actively used.
There now exists a huge quantity of Open source, and it has permeated into all the major, and many minor, software ecosystems. As a measure of all existing source code, how representative is Open source?
The Software Heritage’s mission statement “… is to collect, preserve, and share all software that is publicly available in source code form.” With over  files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
To be representative of all existing source code, the Stack v2 would need to contain a representative sample of source written in all the languages that have been used to implement a non-trivial quantity of code. The plot below shows the number of source files assumed to be from a given year, storage by the Software Heritage; green lines are fitted exponentials (code+data):
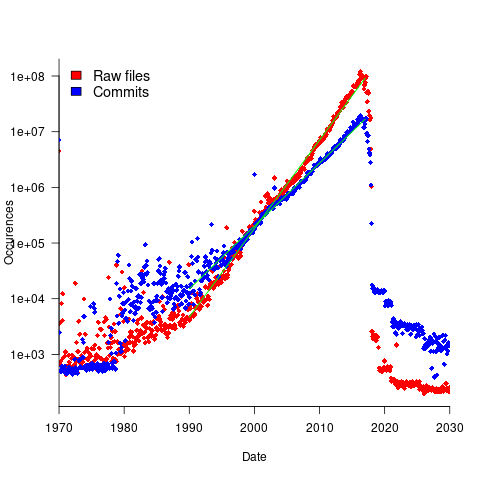
Less Open source was written in years gone by because there were fewer developers writing code, and code tends to get lost.
The Wikipedia list of programming languages currently contains links to articles on 682 languages, although some entries do appear to stretch the definition of programming language, e.g., Geometric Description Language. The Stack v2 contains code in 658 languages. However, even the broadest definition of programming language would not include some of the entries, e.g., Vim Help File. There are 176 language names shared between lists (around 27%; code+data).
Wikipedia languages not contained in Stack v2 include dialects of Basic, C, Lisp, Pascal, and shell, along with languages I recognised. Stack v2 languages not contained in the Wikipedia list include a variety of build and configuration files, names I did not recognise and what looked like documentation and data files.
Stack v2 has a broad brush approach to language classification. There is only one Pascal (perhaps the most widely used language in the early days of the IBM PC, Turbo Pascal, does not get a mention, and neither does UCSD Pascal), and assembler languages can vary a lot between cpus (Stack v2 lists: Assembly, Motorola 68K Assembly, Parrot Assembly, WebAssembly, Unix Assembly).
The Online Historical Encyclopaedia of Programming Languages lists information on 8,945 languages. Most of these probably got no further than being implemented in themselves by the language designer (often for a PhD thesis).
The Stack v2’s definition of a non-trivial quantity is at least 1,000 files having a given filename suffix, e.g., .cpp denoting C++ source. I can understand that this limit might exclude some niche languages from long ago (e.g., Coral 66), but why isn’t there any Algol 60 source?
I suspect that many ‘earlier’ languages are not included because the automated source submission process requires that the code be accessible via one of five version control systems. A lot of older source is stored in tar/zip files, accessed via ftp directories or personal web pages. Software Heritage’s Collect and Curate Legacy Code does not yet appear to provide a process for submitting source available in these forms.
While I think that Open source code has the same language usage characteristics as Closed source, I continue to meet people who question this assumption. I doubt that the question will ever get a definitive answer, not least because of an unwillingness to invest the resources needed to do a large sample comparison.
I would expect there to be at least 100 times as much Closed source as Open source, if only because there are a lot more people writing Closed source.
Obtaining source code for training LLMs
Training a large language model to be a coding assistant requires huge amounts of source code.
Github is a very well known publicly available repository of code, and various sites have created substantial collections of GitHub repos, e.g., GitTorrent, and Google’s BigQuery. Since 2017 the Software Heritage has been amassing the world’s source code, and now looks like it will become the default site for those seeking LLM source code training data. The benefits of using the Software_Heritage, include:
- deduplication at the file level for free. Files are organized using a cryptographic hash of their contents (i.e., a Merkle tree), which is user visible. GitHub may deduplicate internally, but the user visible data structure is based on individual repositories. One study found that 70% of code on GitHub are clones. Deduplication has been a major housekeeping task when creating a source code training dataset.
A single space character or newline is enough to cause a cryptographic hash to change and a file to be treated as different. Studies of file contents has found them differing by the presence/absence of a license at the start of the file, and other non-consequential differences. The LLM training dataset “The Stack v2” has further deduplicated the Software Heritage dataset, removing over 50% of files,
- accessed using AWS. The 11TiB of data can be bulk downloaded from the S3 bucket s3://softwareheritage/graph/. An Amazon Athena hosted version of the dataset can be queried using the Presto distributed SQL engine (filename suffix could be used to extract files likely to contain source in particular languages). Amazon also have an Azure Databricks hosted version.
Suggestions for the best way of accessing this data, for LLM training, welcome,
- Software_Heritage hosts more code than GitHub, although measurements from late 2021 suggests that at the time, over 95% originated on GitHub.
StarCoder2, released at the end of February, is an open weights model trained in partnership with the Software Heritage (a year ago, version 1 of StarCoder was trained using an order of magnitude less source).
How much source is available via the Software Heritage?
As of July 2023 the site hosted files.
Let’s assume 64 lines per file, and 26 non-whitespace characters per line, giving  non-whitespace characters. How many tokens is this?
non-whitespace characters. How many tokens is this?
The most common statement is assignment, which typically contains 4 language tokens (e.g., a = b ; ). There is an exponential decline in language tokens per line (Fig 770.17). The question is how many LLM tokens per computer language identifier, which tend to be abbreviated; I have no idea how these map to LLM tokens.
Assuming 10 LLM tokens per line, we get:  LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
The Stack v2 Hugging Face page lists the deduplicated dataset as containing  tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is
tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is  , with the deduped training dataset containing
, with the deduped training dataset containing  files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
My calculation probably overestimated the number of tokens on a line. LLM’s specifically trained on source code have tokenisers optimized for the characteristics of code, e.g., allowing tokens to span whitespace to allow for idioms such as import numpy as np to be treated as single tokens.
Given the exponential growth of files available on the Software Heritage, it is possible that several orders of magnitude more tokens will eventually become available.
Licensing, in the form of the GPL, is a complication that hangs over the use of some public source code (maybe 25%). An ongoing class-action suit will likely take years to resolve, and it’s possible that model training will have improved to the extent that any loss of GPL’d code will not seriously impact model performance:
- When source is licensed under the GNU General Public License, do models that use it during training have themselves to be released under a GPL license? In November 2022 a class-action lawsuit was filed, challenging the legality of GitHub Copilot and related OpenAI products. This case has yet to reach jury trial, and after that there will no doubt be appeals. The resolution is years in the future,
- if the plaintiffs win, with models trained using GPL’d code required to release the weights under a GPL license. The different source files used to build a project sometimes have different, incompatible, Open source licenses. LLM training does not require complete sets of project source files, so the presence of GPL’d source is not contagious within a project. If the same file appears with different licenses, one of which is the GPL, the simplest option may be to exclude it. One study found the GPL-3 license present under 2,871 different filenames.
Given that around 50% of GitHub repos don’t specify any license, and around 30% specify an MIT license, not using GPL’d code for training does not look like it will affect the training of general coding models. However, these models will have problems dealing with issues that require interfacing to GPL’d code.
Cost-effectiveness decision for fixing a known coding mistake
If a mistake is spotted in the source code of a shipping software system, is it more cost-effective to fix the mistake, or to wait for a customer to report a fault whose root cause turns out to be that particular coding mistake?
The naive answer is don’t wait for a customer fault report, based on the following simplistic argument:  .
.
where:  is the cost of fixing the mistake in the code (including testing etc), and
is the cost of fixing the mistake in the code (including testing etc), and  is the cost of finding the mistake in the code based on a customer fault report (i.e., the sum on the right is the total cost of fixing a fault reported by a customer).
is the cost of finding the mistake in the code based on a customer fault report (i.e., the sum on the right is the total cost of fixing a fault reported by a customer).
If the mistake is spotted in the code for ‘free’, then  , e.g., a developer reading the code for another reason, or flagged by a static analysis tool.
, e.g., a developer reading the code for another reason, or flagged by a static analysis tool.
This answer is naive because it fails to take into account the possibility that the code containing the mistake is deleted/modified before any customers experience a fault caused by the mistake; let  be the likelihood that the coding mistake ceases to exist in the next unit of time.
be the likelihood that the coding mistake ceases to exist in the next unit of time.
The more often the software is used, the more likely a fault experience based on the coding mistake occurs; let  be the likelihood that a fault is reported in the next time unit.
be the likelihood that a fault is reported in the next time unit.
A more realistic analysis takes into account both the likelihood of the coding mistake disappearing and a corresponding fault being reported, modifying the relationship to: *{F_{experience}/M_{gone}}")
Software systems are eventually retired from service; the likelihood that the software is maintained during the next unit of time,  , is slightly less than one.
, is slightly less than one.
Giving the relationship: *{F_{experience}/M_{gone}}*S_{maintained}")
which simplifies to: *{F_{experience}/M_{gone}}*S_{maintained}")
What is the likely range of values for the ratio:  ?
?
I have no find/fix cost data, although detailed total time is available, i.e., find+fix time (with time probably being a good proxy for cost). My personal experience of find often taking a lot longer than fix probably suffers from survival of memorable cases; I can think of cases where the opposite was true.
The two values in the ratio  are likely to change as a system evolves, e.g., high code turnover during early releases that slows as the system matures. The value of should decrease over time, but increase with a large influx of new users.
are likely to change as a system evolves, e.g., high code turnover during early releases that slows as the system matures. The value of should decrease over time, but increase with a large influx of new users.
A study by Penta, Cerulo and Aversano investigated the lifetime of coding mistakes (detected by several tools), tracking them over three years from creation to possible removal (either fixed because of a fault report, or simply a change to the code).
Of the 2,388 coding mistakes detected in code developed over 3-years, 41 were removed as reported faults and 416 disappeared through changes to the code: 
The plot below shows the survival curve for memory related coding mistakes detected in Samba, based on reported faults (red) and all other changes to the code (blue/green, code+data):
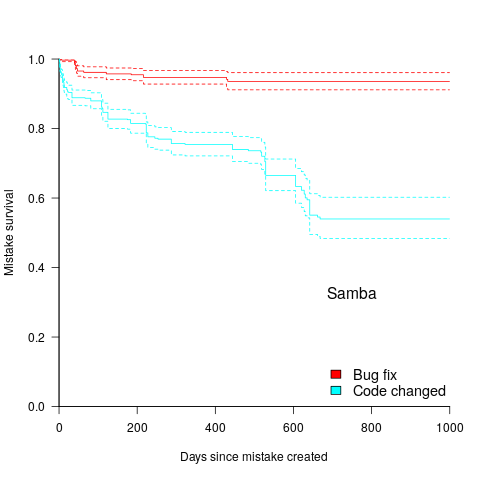
Coding mistakes are obviously being removed much more rapidly due to changes to the source, compared to customer fault reports.
For it to be cost-effective to fix coding mistakes in Samba, flagged by the tools used in this study ( is essentially one), requires:  .
.
Meeting this requirement does not look that implausible to me, but obviously data is needed.
semgrep: the future of static analysis tools
When searching for a pattern that might be present in source code contained in multiple files, what is the best tool to use?
The obvious answer is grep, and grep is great for character-based pattern searches. But patterns that are token based, or include information on language semantics, fall outside grep‘s model of pattern recognition (which does not stop people trying to cobble something together, perhaps with the help of complicated sed scripts).
Those searching source code written in C have the luxury of being able to use Coccinelle, an industrial strength C language aware pattern matching tool. It is widely used by the Linux kernel maintainers and people researching complicated source code patterns.
Over the 15+ years that Coccinelle has been available, there has been a lot of talk about supporting other languages, but nothing ever materialized.
About six months ago, I noticed semgrep and thought it interesting enough to add to my list of tool bookmarks. Then, a few days ago, I read a brief blog post that was interesting enough for me to check out other posts at that site, and this one by Yoann Padioleau really caught my attention. Yoann worked on Coccinelle, and we had an interesting email exchange some 13-years ago, when I was analyzing if-statement usage, and had subsequently worked on various static analysis tools, and was now working on semgrep. Most static analysis tools are created by somebody spending a year or so working on the implementation, making all the usual mistakes, before abandoning it to go off and do other things. High quality tools come from people with experience, who have invested lots of time learning their trade.
The documentation contains lots of examples, and working on the assumption that things would be a lot like using Coccinelle, I jumped straight in.
The pattern I choose to search for, using semgrep, involved counting the number of clauses contained in Python if-statement conditionals, e.g., the condition in: if a==1 and b==2: contains two clauses (i.e., a==1, b==2). My interest in this usage comes from ideas about if-statement nesting depth and clause complexity. The intended use case of semgrep is security researchers checking for vulnerabilities in code, but I’m sure those developing it are happy for source code researchers to use it.
As always, I first tried building the source on the Github repo, (note: the Makefile expects a git clone install, not an unzipped directory), but got fed up with having to incrementally discover and install lots of dependencies (like Coccinelle, the code is written on OCaml {93k+ lines} and Python {13k+ lines}). I joined the unwashed masses and used pip install.
The pattern rules have a yaml structure, specifying the rule name, language(s), message to output when a match is found, and the pattern to search for.
After sorting out various finger problems, writing C rather than Python, and misunderstanding the semgrep output (some of which feels like internal developer output, rather than tool user developer output), I had a set of working patterns.
The following two patterns match if-statements containing a single clause (if.subexpr-1), and two clauses (if.subexpr-2). The option commutative_boolop is set to true to allow the matching process to treat Python’s or/and as commutative, which they are not, but it reduces the number of rules that need to be written to handle all the cases when ordering of these operators is not relevant (rules+test).
rules: - id: if.subexpr-1 languages: [python] message: if-cond1 patterns: - pattern: | if $COND1: # we found an if statement $BODY - pattern-not: | if $COND2 or $COND3: # must not contain more than one condition $BODY - pattern-not: | if $COND2 and $COND3: $BODY severity: INFO - id: if.subexpr-2 languages: [python] options: commutative_boolop: true # Reduce combinatorial explosion of rules message: if-cond2 pattern-either: - patterns: - pattern: | if $COND1 or $COND2: # if statement containing two conditions $BODY - pattern-not: | if $COND3 or $COND4 or $COND5: # must not contain more than two conditions $BODY - pattern-not: | if $COND3 or $COND4 and $COND5: $BODY - patterns: - pattern: | if $COND1 and $COND2: $BODY - pattern-not: | if $COND3 and $COND4 and $COND5: $BODY - pattern-not: | if $COND3 and $COND4 or $COND5: $BODY severity: INFO |
The rules would be simpler if it were possible for a pattern to not be applied to code that earlier matched another pattern (in my example, one containing more clauses). This functionality is supported by Coccinelle, and I’m sure it will eventually appear in semgrep.
This tool has lots of rough edges, and is still rapidly evolving, I’m using version 0.82, released four days ago. What’s exciting is the support for multiple languages (ten are listed, with experimental support for twelve more, and three in beta). Roughly what happens is that source code is mapped to an abstract syntax tree that is common to all supported languages, which is then pattern matched. Supporting a new language involves writing code to perform the mapping to this common AST.
It’s not too difficult to map different languages to a common AST that contains just tokens, e.g., identifiers and their spelling, literals and their value, and keywords. Many languages use the same operator precedence and associativity as C, plus their own extras, and they tend to share the same kinds of statements; however, declarations can be very diverse, which makes life difficult for supporting a generic AST.
An awful lot of useful things can be done with a tool that is aware of expression/statement syntax and matches at the token level. More refined semantic information (e.g., a variable’s type) can be added in later versions. The extent to which an investment is made to support the various subtleties of a particular language will depend on its economic importance to those involved in supporting semgrep (Return to Corp is a VC backed company).
Outside of a few languages that have established tools doing deep semantic analysis (i.e., C and C++), semgrep has the potential to become the go-to static analysis tool for source code. It will benefit from the network effects of contributions from lots of people each working in one or more languages, taking their semgrep skills and rules from one project to another (with source code language ceasing to be a major issue). Developers using niche languages with poor or no static analysis tool support will add semgrep support for their language because it will be the lowest cost path to accessing an industrial strength tool.
How are the VC backers going to make money from funding the semgrep team? The traditional financial exit for static analysis companies is selling to a much larger company. Why would a large company buy them, when they could just fork the code (other company sales have involved closed-source tools)? Perhaps those involved think they can make money by selling services (assuming semgrep becomes the go-to tool). I have a terrible track record for making business predictions, so I will stick to the technical stuff.
Update
Parts of the semgrep source have changed from an Open source license to a commercial one.
Opengrep is an Open source fork of semgrep.
Academic recognition for creating and supporting software
A scientific paper is supposed to contain enough information that somebody skilled in the field can perform the experiment(s) described therein (issues around the money needed to obtain access to the necessary equipment tend to be side stepped). In addition to the skills generally taught within a field, every niche has its specific skill set, which for leading edge research may only be available in one lab.
Bespoke software has become an essential component of many research projects, and the ability to reimplement the necessary software is rarely considered to be a necessary skill. Some researchers consider software to be “just code” whose creation is not really a skill that is worth investing in acquiring.
There is a widespread belief in academic circles that the solution to the issues created by bespoke software is for researchers to release the source code of the software they create.
Experienced developers will laugh at the idea that once the source code is available, running it is straight forward. Figuring out how to run somebody else’s code can be a very time-consuming process, particularly when the person who wrote it is relatively inexperienced.
This post is about the social issues around the bespoke research code being made available, and not the technical issues likely to be encountered in building it on another researcher’s computer.
Lots of researchers do make their code available, without being asked, and some researchers actively promote the software they have written. In a few cases, active software ecosystems have sprung up around a research topic, e.g., Astropy and SunPy.
However, a lot of code never gets released. Based on my own experience of asking for code (in the last 10 years, most of my requests have been for data), reasons given by researchers for not making the code they have written available to others, include:
- not replying to email requests for the code,
- not sure that they still have the all code, which is taken as a reason for not sending what they have. This may also be a cover story for another reason they don’t want to admit to,
- they don’t want the hassle of supporting other users of the code. Having received some clueless requests for help on software I have released, I have sympathy for this position. Sometimes pointing out that I am an experienced developer who does not need support, works, other times it just changes the reason given,
- they think the code is poorly written, and that this poor of quality will make them look bad. Pointing out that research code is leading edge (rare true, it’s an attempt to stroke their ego), and not supposed to be polished, rarely works for me. Some people are just perfectionists, with a strong aversion to showing others anything that has not been polished to death,
- a large investment was made to create the software, and they want to reap all the benefits. I have a lot of sympathy with this position. Some research fields are very competitive, or sometimes the researcher just wants to believe that they really will get another grant to work on the subject.
Researchers who create and support research software complain that they don’t get any formal recognition for this work; which begs the question: why are you working on this software when you know that you are unlikely to receive any recognition?
How might researchers receive recognition for writing, supporting and releasing code?
Citations to published papers are a commonly used technique for measuring the worth of the work done by a researcher (this metric is used when evaluating people for promotion, awarding grants, and evaluating departments), and various organizations are promoting the use of citations for software.
Some software provides enough benefits that the authors can write a conventional paper about it, e.g., a paper on Astropy (which does not cite any of the third-party packages used in its own implementation). But a lot of research software does not have sufficient general appeal to warrant a paper.
Are citations for software a good idea?
An important characteristic of any evaluation metric is how hard it is to fake a good score.
Research papers are rated by the journal in which they are published, with each journal having its own rating (a short-term metric), and the number of times the paper is cited (a longer-term metric). Papers are reviewed, with many failing to be accepted (at least by the higher quality journals; there are so-called predatory journals that will publish anything for a fee).
While there are a few journals where source code may be an integral component of a paper, most research software is published on sites having minimal acceptance criteria, e.g., Github.
Will citations to software become as commonplace as citations to other papers?
I regularly read software papers that cites software packages, but this practice is a long way from being common.
Will those awarding job promotions and grants start to include software creation as having a status comparable to published papers? We will have to wait and see.
Will the lure of recognition via citations increase the quantity of source being released?
I don’t think it will have any impact until the benefits of software citations are seen to be worthwhile (which may be many years away).
Two failed software development projects in the High Court
When submitting a bid, to be awarded the contract to develop a software system, companies have to provide information on costs and delivery dates. If the costs are significantly underestimated, and/or the delivery dates woefully optimistic, one or more of the companies involved may resort to legal action.
Searching the British and Irish Legal Information Institute‘s Technology and Construction Court Decisions throws up two interesting cases (when searching on “source code”; I have not been able to figure out the patterns in the results that were not returned by their search engine {when I expected some cases to be returned}).
The estimation and implementation activities described in the judgements for these two cases could apply to many software projects, both successful and unsuccessful. Claiming that the system will be ready by the go-live date specified by the customer is an essential component of winning a bid, the huge uncertainties in the likely effort required comes as standard in the software industry environment, and discovering lots of unforeseen work after signing the contract (because the minimum was spent on the bid estimate) is not software specific.
The first case is huge (BSkyB/Sky won the case and EDS had to pay £200+ million): (1) BSkyB Limited (2) Sky Subscribers Services Limited: Claimants – and (1) HP Enterprise Services UK Limited (formerly Electronic Data Systems Limited) (2) Electronic Data systems LLC (Formerly Electronic Data Systems Corporation: Defendants. The amount bid was a lot less than £200 million (paragraph 729 “The total EDS “Sell Price” was £54,195,013 which represented an overall margin of 27% over the EDS Price of £39.4 million.” see paragraph 90 for a breakdown).
What can be learned from the judgement for this case (the letter of Intent was subsequently signed on 9 August 2000, and the High Court decision was handed down on 26 January 2010)?
- If you have not been involved in putting together a bid for a large project, paragraphs 58-92 provides a good description of the kinds of activities involved. Paragraphs 697-755 discuss costing details, and paragraphs 773-804 manpower and timing details,
- if you have never seen a software development contract, paragraphs 93-105 illustrate some of the ways in which delivery/payments milestones are broken down and connected. Paragraph 803 will sound familiar to developers who have worked on large projects: “… I conclude that much of Joe Galloway’s evidence in relation to planning at the bid stage was false and was created to cover up the inadequacies of this aspect of the bidding process in which he took the central role.” The difference here is that the money involved was large enough to make it worthwhile investing in a court case, and Sky obviously believed that they could only be blamed for minor implementation problems,
- don’t have the manager in charge of the project give perjured evidence (paragraph 195 “… Joe Galloway’s credibility was completely destroyed by his perjured evidence over a prolonged period.”). Bringing the law of deceit and negligent misrepresentation into a case can substantially increase/decrease the size of the final bill,
- successfully completing an implementation plan requires people with the necessary skills to do the work, and good people are a scarce resource. Projects fail if they cannot attract and keep the right people; see paragraphs 1262-1267.
A consequence of the judge’s finding of misrepresentation by EDS is a requirement to consider the financial consequences. One item of particular interest is the need to calculate the likely effort and time needed by alternative suppliers to implement the CRM System.
The only way to estimate, with any degree of confidence, the likely cost of implementing the required CRM system is to use a conventional estimation process, i.e., a group of people with the relevant domain knowledge work together for some months to figure out an implementation plan, and then cost it. This approach costs a lot of money, and ties up scarce expertise for long periods of time; is there a cheaper method?
Management at the claimant/defence companies will have appreciated that the original cost estimate is likely to be as good as any, apart from being tainted by the perjury of the lead manager. So they all signed up to using Tasseography, e.g., they get their respective experts to estimate the amount of code that needs to be produce to implement the system, calculate how long it would take to write this code and multiply by the hourly rate for a developer. I would loved to have been a fly on the wall when the respective IT experts, all experienced in provided expert testimony, were briefed. Surely the experts all knew that the ballpark figure was that of the original EDS estimate, and that their job was to come up with a lower/high figure?
What other interpretation could there be for such a bone headed approach to cost estimation?
The EDS expert based his calculation on the debunked COCOMO model (ok, my debunking occurred over six years later, but others have done it much earlier).
The Sky expert based his calculation on the use of function points, i.e., estimation function points rather than lines of code, and then multiply by average cost per function point.
The legal teams point out the flaws in the opposing team’s approach, and the judge does a good job of understanding the issues and reaching a compromise.
There may be interesting points tucked away in the many paragraphs covering various legal issues. I barely skimmed these.
The second case is not as large (the judgement contains a third the number of paragraphs, and the judgement handed down on 19 February 2021 required IBM to pay £13+ million): SCIS GENERAL INSURANCE LIMITED: Claimant – and – IBM UNITED KINGDOM LIMITED: Defendant.
Again there is lots to learn about how projects are planned, estimated and payments/deliveries structured. There are staffing issues; paragraph 104 highlights how the client’s subject matter experts are stuck in their ways, e.g., configuring the new system for how things used to work and not attending workshops to learn about the new way of doing things.
Every IT case needs claimant/defendant experts and their collection of magic spells. The IBM expert calculated that the software contained technical debt to the tune of 4,000 man hours of work (paragraph 154).
If you find any other legal software development cases with the text of the judgement publicly available, please let me know (two other interesting cases with decisions on the British and Irish Legal Information Institute).
Electronic Evidence and Electronic Signatures: book
Electronic Evidence and Electronic Signatures by Stephen Mason and Daniel Seng is not the sort of book that I would normally glance at twice (based on its title). However, at this start of the year I had an interesting email conversation with the first author, a commentator who worked for the defence team on the Horizon IT project case, and he emailed with the news that the fifth edition was now available (there’s a free pdf version, so why not have a look; sorry Stephen).
Regular readers of this blog will be interested in chapter 4 (“Software code as the witness”) and chapter 5 (“The presumption that computers are ‘reliable'”).
Legal arguments are based on precedent, i.e., decisions made by judges in earlier cases. The one thing that stands from these two chapters is how few cases have involved source code and/or reliability, and how simplistic the software issues have been (compared to issues that could have been involved). Perhaps the cases involving complicated software issues get simplified by the lawyers, or they look like they will be so difficult/expensive to litigate that the case don’t make it to court.
Chapter 4 provided various definitions of source code, all based around the concept of imperative programming, i.e., the code tells the computer what to do. No mention of declarative programming, where the code specifies the information required and the computer has to figure out how to obtain it (SQL being a widely used language based on this approach). The current Wikipedia article on source code is based on imperative programming, but the programming language article is not so narrowly focused (thanks to some work by several editors many years ago 😉
There is an interesting discussion around the idea of source code as hearsay, with a discussion of cases (see 4.34) where the person who wrote the code had to give evidence so that the program output could be admitted as evidence. I don’t know how often the person who wrote the code has to give evidence, but these days code often has multiple authors, and their identity is not always known (e.g., author details have been lost, or the submission effectively came via an anonymous email).
Chapter 5 considers the common law presumption in the law of England and Wales that ‘In the absence of evidence to the contrary, the courts will presume that mechanical instruments were in order. Yikes! The fact that this is presumption is nonsense, at least for computers, was discussed in an earlier post.
There is plenty of case law discussion around the accuracy of devices used to breath-test motorists for their alcohol level, and defendants being refused access to the devices and associated software. Now, I’m sure that the software contained in these devices contains coding mistakes, but was a particular positive the result of a coding mistake? Without replicating the exact conditions occurring during the original test, it could be very difficult to say. The prosecution and Judges make the common mistake of assuming that because the science behind the test had been validated, the device must produce correct results; ignoring the fact that the implementation of the science in software may contain implementation mistakes. I have lost count of the number of times that scientist/programmers have told me that because the science behind their code is correct, the program output must be correct. My retort that there are typos in the scientific papers they write, therefore there may be typos in their code, usually fails to change their mind; they are so fixated on the correctness of the science that possible mistakes elsewhere are brushed aside.
The naivety of some judges is astonishing. In one case (see 5.44) a professor who was an expert in mathematics, physics and computers, who had read the user manual for an application, but had not seen its source code, was considered qualified to give evidence about the operation of the software!
Much of chapter 5 is essentially an overview of software reliability, written by a barrister for legal professionals, i.e., it is not always a discussion of case law. A barristers’ explanation of how software works can be entertainingly inaccurate, but the material here is correct in a broad brush sense (and I did not spot any entertainingly inaccuracies).
Other than breath-testing, the defence asking for source code is rather like a dog chasing a car. The software for breath-testing devices is likely to be small enough that one person might do a decent job of figuring out how it works; many software systems are not only much, much larger, but are dependent on an ecosystem of hardware/software to run. Figuring out how they work will take multiple (expensive expert) people a lot of time.
Legal precedents are set when both sides spend the money needed to see a court case through to the end. It’s understandable why the case law discussed in this book is so sparse and deals with relatively simple software issues. The costs of fighting a case involving the complexity of modern software is going to be astronomical.
Recent Comments