Archive
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
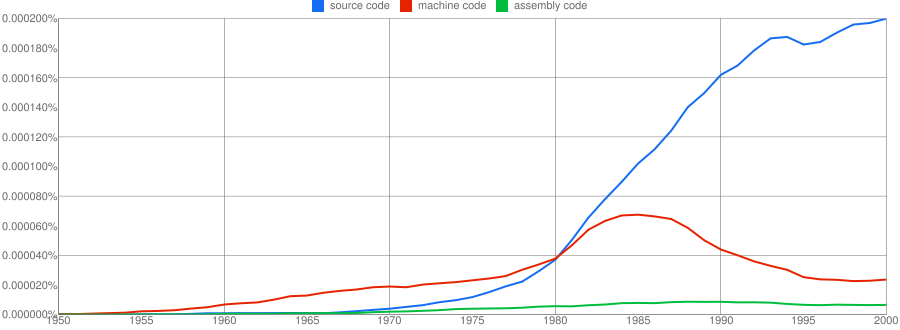
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
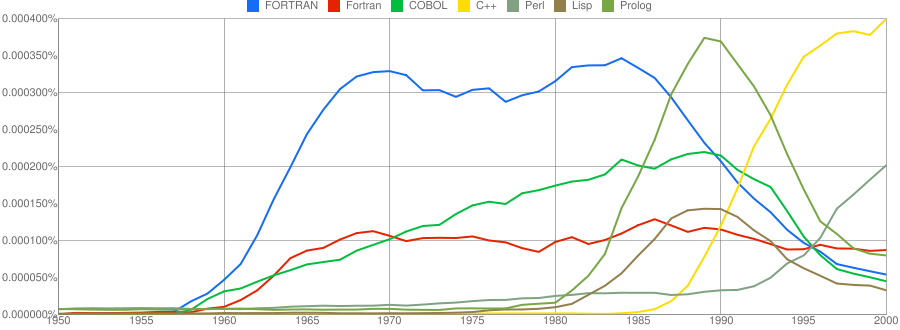
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
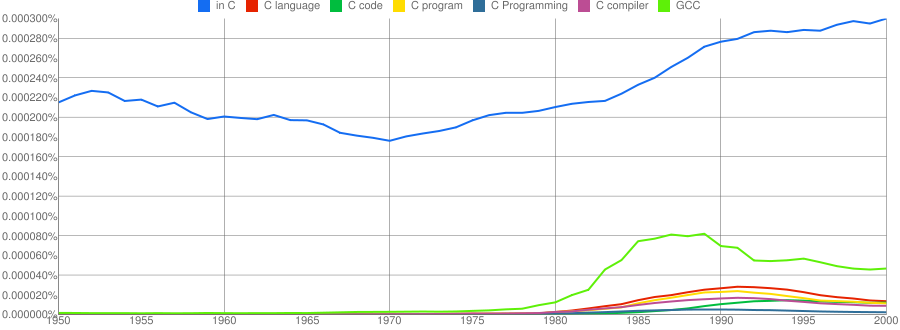
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
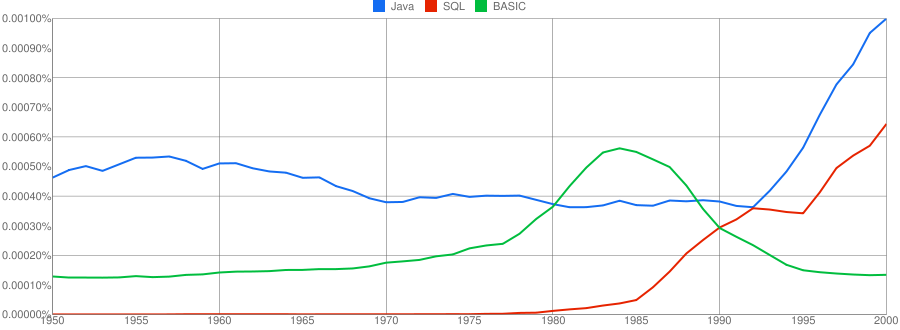
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
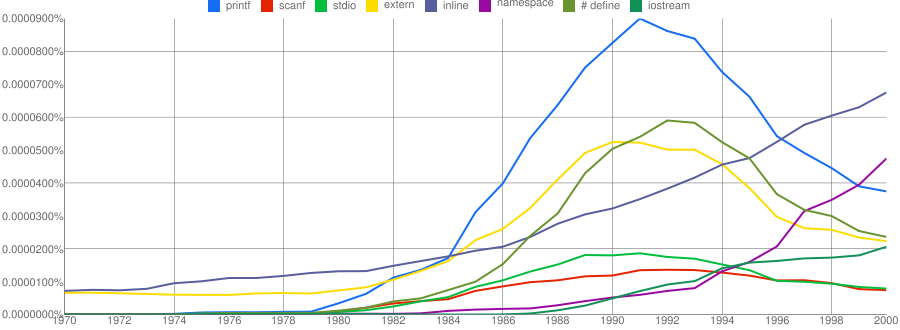
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Recent Comments