Archive
Half-life of Open source research software projects
The evidence for applications having a half-life continues to spread across domains. The first published data covered IBM mainframe applications up to 1992 (half-life of at least 5-years), and was mostly ignored. Then, the data collected by Killed by Google up to 2018, showed a half-life of at least 3-years for Google apps. More recently, the data collected by Killed by Microsoft up to 2025, showed a half-life of at least 7-years for Microsoft apps (perhaps reflecting the maturity of the company’s product line).
The half-life of source code, independent of the lifetime of the application it implements, is a separate topic.
Scientific software created to support researchers is an ecosystem whose incentives and means of production can be very different from commercial software. Does researcher oriented software die when the grant money runs out, or the researcher moves on to the next fashionable topic, or does it live on as the field expands?
The paper Scientific Open-Source Software Is Less Likely to Become Abandoned Than One Might Think! Lessons from Curating a Catalog of Maintained Scientific Software by Thakur, Milewicz, Jahanshahi, Paganini, Vasilescu, and Mockus analysed 14,418 scientific software systems written in Python (53%), C/C++ (25%), R (12%), Java (8%) or Fortran (2%). The first half of the paper describes how World of Code‘s 209 million repos were filtered down to 350,308 projects containing README files, these READMEs were processed by LLMs to extract information and further filter out projects.
The authors collected the usual information about each Open source project, e.g., number of core developers, number of commits, programming language, etc. They also collected information about the research domain, e.g., scientific field (biology, chemistry, mathematics, etc.), funding, academic/government associations, etc. A Cox proportional hazards model was fitted to this data, with project lifetime being the response variable. A project was deemed to have been abandoned when no changes had been made to the code for at least six consecutive months (we can argue over whether this is long enough).
Including all the different factors created a Cox model that did a good job of explaining the variance in project survival rate. No one factor dominated, and there was a lot of overlap in the confidence bounds of the components of each factor, e.g., different research domains. I have always said that programming language has no impact on project lifetime; the language factor of the fitted model was not statistically significant (two of the languages just sneaked in under the 5% bar), which can be interpreted as being consistent with my opinion.
Each project was categorised as one of: Scientific Domain-specific code (73.5%), Scientific infrastructure (16.5%), or Publication-Specific code (10%). The plot below shows the Kaplan-Meier survival curve for these three categories (note: y-axis is logarithmic), with faint grey lines showing a fitted exponential for each survival curve (only 3% of projects are abandoned in the first year, and the exponential fits are to the data after the first year; code+data):
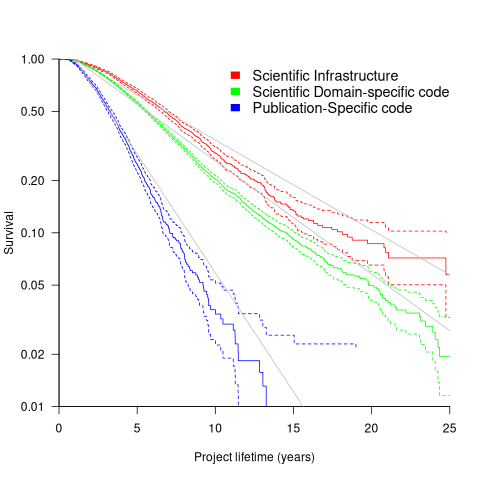
Readers familiar with academic publishing will not be surprised that projects associated with published papers have the lowest survival rate (half-life just over 2-years). Infrastructure projects are likely to be depended on by many people, who all have an interest in them surviving (half-life around 6-years). The Domain-specific half-life is around 4.5-years.
The results of this study show software systems in various research ecosystems having a range of half-lives in the same range as three major commercial software ecosystems.
Unfortunately, my experience of discussing application half-life with developers is that they believe in an imagined future where software never dies. That is, they are unwilling to consider a world where software has a high probability of being abandoned, because it requires that they consider the return on investment before spending time polishing their code.
Academic recognition for creating and supporting software
A scientific paper is supposed to contain enough information that somebody skilled in the field can perform the experiment(s) described therein (issues around the money needed to obtain access to the necessary equipment tend to be side stepped). In addition to the skills generally taught within a field, every niche has its specific skill set, which for leading edge research may only be available in one lab.
Bespoke software has become an essential component of many research projects, and the ability to reimplement the necessary software is rarely considered to be a necessary skill. Some researchers consider software to be “just code” whose creation is not really a skill that is worth investing in acquiring.
There is a widespread belief in academic circles that the solution to the issues created by bespoke software is for researchers to release the source code of the software they create.
Experienced developers will laugh at the idea that once the source code is available, running it is straight forward. Figuring out how to run somebody else’s code can be a very time-consuming process, particularly when the person who wrote it is relatively inexperienced.
This post is about the social issues around the bespoke research code being made available, and not the technical issues likely to be encountered in building it on another researcher’s computer.
Lots of researchers do make their code available, without being asked, and some researchers actively promote the software they have written. In a few cases, active software ecosystems have sprung up around a research topic, e.g., Astropy and SunPy.
However, a lot of code never gets released. Based on my own experience of asking for code (in the last 10 years, most of my requests have been for data), reasons given by researchers for not making the code they have written available to others, include:
- not replying to email requests for the code,
- not sure that they still have the all code, which is taken as a reason for not sending what they have. This may also be a cover story for another reason they don’t want to admit to,
- they don’t want the hassle of supporting other users of the code. Having received some clueless requests for help on software I have released, I have sympathy for this position. Sometimes pointing out that I am an experienced developer who does not need support, works, other times it just changes the reason given,
- they think the code is poorly written, and that this poor of quality will make them look bad. Pointing out that research code is leading edge (rare true, it’s an attempt to stroke their ego), and not supposed to be polished, rarely works for me. Some people are just perfectionists, with a strong aversion to showing others anything that has not been polished to death,
- a large investment was made to create the software, and they want to reap all the benefits. I have a lot of sympathy with this position. Some research fields are very competitive, or sometimes the researcher just wants to believe that they really will get another grant to work on the subject.
Researchers who create and support research software complain that they don’t get any formal recognition for this work; which begs the question: why are you working on this software when you know that you are unlikely to receive any recognition?
How might researchers receive recognition for writing, supporting and releasing code?
Citations to published papers are a commonly used technique for measuring the worth of the work done by a researcher (this metric is used when evaluating people for promotion, awarding grants, and evaluating departments), and various organizations are promoting the use of citations for software.
Some software provides enough benefits that the authors can write a conventional paper about it, e.g., a paper on Astropy (which does not cite any of the third-party packages used in its own implementation). But a lot of research software does not have sufficient general appeal to warrant a paper.
Are citations for software a good idea?
An important characteristic of any evaluation metric is how hard it is to fake a good score.
Research papers are rated by the journal in which they are published, with each journal having its own rating (a short-term metric), and the number of times the paper is cited (a longer-term metric). Papers are reviewed, with many failing to be accepted (at least by the higher quality journals; there are so-called predatory journals that will publish anything for a fee).
While there are a few journals where source code may be an integral component of a paper, most research software is published on sites having minimal acceptance criteria, e.g., Github.
Will citations to software become as commonplace as citations to other papers?
I regularly read software papers that cites software packages, but this practice is a long way from being common.
Will those awarding job promotions and grants start to include software creation as having a status comparable to published papers? We will have to wait and see.
Will the lure of recognition via citations increase the quantity of source being released?
I don’t think it will have any impact until the benefits of software citations are seen to be worthwhile (which may be many years away).
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Recent Comments