Archive
The probability of encountering a given variable
If I am reading through the body of a function, what is the probability of a particular variable being the next one I encounter? A good approximation can be calculated as follows: Count the number of occurrences of all variables in the function definition up to the current point and work out the percentage occurrence for each of them, the probability of a particular variable being seen next is approximately equal to its previously seen percentage. The following graph is the evidence I give for this approximation.
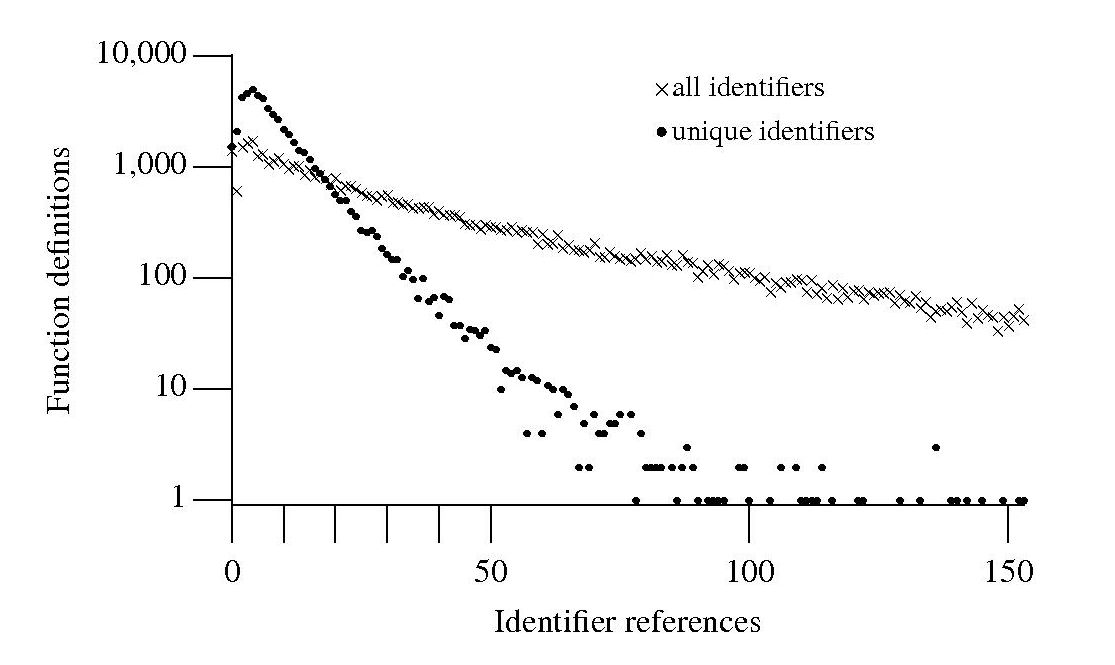
The graph shows a count of the number of C function definitions containing identifiers that are referenced a given number of times, e.g., if the identifier x is referenced five times in one function definition and ten times in another the function definition counts for five and ten are both incremented by one. That one axis is logarithmic and the bullets and crosses form almost straight lines hints that a Zipf-like distribution is involved.
There are many processes that will generate a Zipf distribution, but the one that interests me here is the process where the probability of the next occurrence of an event occurring is proportional to the probability of it having previously occurred (this includes some probability of a new event occurring; follow the link to Simon’s 1955 paper).
One can think of the value (i.e., information) held in a variable as having a given importance and it is to be expected that more important information is more likely to be operated on than less important information. This model appeals to me. Another process that will generate this distribution is that of Monkeys typing away on keyboards and while I think source code contains lots of random elements I don’t think it is that random.
The important concept here is operated on. In x := x + 1; variable x is incremented and the language used requires (or allowed) that the identifier x occur twice. In C this operation would only require one occurrence of x when expressed using the common idiom x++;. The number of occurrences of a variable needed to perform an operation on it, in a given languages, will influence the shape of the graph based on an occurrence count.
One graph does not provide conclusive evidence, but other measurements also produce straightish lines. The fact that the first few entries do not form part of an upward trend is not a problem, these variables are only accessed a few times and so might be expected to have a large deviation.
More sophisticated measurements are needed to count operations on a variable, as opposed to occurrences of it. For instance, few languages (any?) contain an indirection assignment operator (e.g., writing x ->= next; instead of x = x -> next;) and this would need to be adjusted for in a more sophisticated counting algorithm. It will also be necessary to separate out the effects of global variables, function calls and the multiple components involved in a member selection, etc.
Update: A more detailed analysis is now available.
Recent Comments