Archive
Distribution of method chains in Java and Python
Some languages support three different ways of organizing a sequence of functions/methods, with calls taking as their first argument the value returned by the immediately prior call. For instance, Java supports the following possibilities:
r1=f1(val); r2=f2(r1); r3=f3(r2); // Sequential calls r3=f3(f2(f1(val))); // Nested calls, read right to left r3=val.f1().f2().f3(); // Method chain, read left to right |
Simula 67 was the first language to support the dot-call syntax used to code method chains. Ten years later Smalltalk-76 supported sending a message to the result of a prior send, which could be seen as a method chain rather than a nested call (because it is read left to right; Smalltalk makes minimal use of punctuator characters, so the syntax is not distinguishable).
How common are method chains in source code, and what is the distribution of chain length? Two studies have investigated this question: An Empirical Study of Method Chaining in Java by Nakamaru (PhD thesis), Matsunaga, Akiyama, Yamazaki, and Chiba, and Method Chaining Redux: An Empirical Study of Method Chaining in Java, Kotlin, and Python by Keshk, and Dyer.
The plot below shows the number of Java method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2018, based on a model fitted to the complete dataset (code and data):
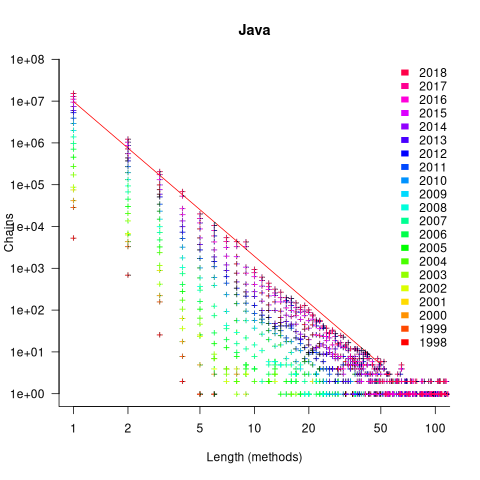
The fitted regression model is:

Why is the number of chains of all lengths growing by around 46% per year? I think this growth is driven by the growth in the amount of source measured. Measurements show that the percentage of source lines containing a method call is roughly constant. In the plot above, the number of unchained methods (i.e., chains of length one) increases in-step with the growth of chained methods. All chain lengths will grow at the same rate, if the source that contains them is growing.
What is responsible for the step change in the number of chains at around 10 methods? Nakamaru classified a random sample of 280 chains, and found that roughly 80% of chains longer than eight methods built an object, e.g., the following chain:
MoreObjects.toStringHelper(this) .add("iLine" , iLine) .add("lastK" , lastK) .add("spacesPending", spacesPending) .add("newlinesPending", newlinesPending) .add("blankLines", blankLines) .add("super", super.toString()) .toString() |
Are these chain usage patterns present in Python? The plot below shows the number of Python method chains having a given length, for code available in a given year. The red line is a fitted regression line for 2020, based on a model fitted to the complete dataset (code and data):

The fitted regression model is:

While this model is almost identical to the model fitted to the Java data (the annual growth rate is 39%), the above plot shows a large step change after chains of length two. Keshk’s paper focuses on replicating Nakamaru’s Java results, and then briefly discusses Python. I have an assortment of explanations, but nothing stands out.
Within code, how are method calls split between single calls and a chain of two or more calls?
The fractions in the plot below are calculated as the ratio of chains of length one (i.e., single method call) against chains containing two or more methods. The “j” shows Java ratios, and “p” Python ratios. The red lines show the fraction based on the total number of method calls, and the blue/green lines are based on occurrences of chains, i.e., chain of one vs chain of many (code and data):

The ratio of Java chains containing two or more methods vs one method, grew by around 6% a year between 2006 and 2018, which is only a small part of the overall 46% annual Java growth.
Method chaining is three times more common in Java than Python. In 2020 around a quarter of all method calls were in a chain of two or more, and single method calls were around ten times more common than multi-call chains.
In Python, the use of method chains has roughly remained unchanged over 15 years, with around 5% of all method calls appearing in a chain.
I don’t have a good idea for why method chains are three times more common in Java than Python. Are nested calls the more common usage in Python, or do developers use a sequence of calls communicating using temporary variables?
What of languages that don’t support method chaining, e.g., C. Is the distribution of the number of nested calls (or sequence of calls using temporaries) a power law with an exponent close to 3.7?
Suggestions and pointers to more data welcome.
Procedure nesting a once common idiom
Structured programming was a popular program design methodology that many developers/managers claimed to be using in the 1970s and 1980s. Like all popular methodologies, everybody had/has their own idea about what it involves, and as always, consultancies sprang up to promote their take on things. The 1972 book Structured programming provides a taste of the times.
The idea underpinning structured programming is that it’s possible to map real world problems to some hierarchical structure, such as in the image below. This hierarchy model also provided a comforting metaphor for those seeking to understand software and its development.

The disadvantages of the Structured programming approach (i.e., real world problems often have important connections that cannot be implemented using a hierarchy) become very apparent as programs get larger. However, in the 1970s the installed memory capacity of most computers was measured in kilobytes, and a program containing 25K lines of code was considered large (because it was enough to consume a large percentage of the memory available). A major program usually involved running multiple, smaller, programs in sequence, each reading the output from the previous program. It was not until the mid-1980s…
At the coding level, doing structured programming involves laying out source code to give it a visible structure. Code blocks are indented to show if/for/while nesting and where possible procedure/functions are nested within the calling procedures (before C became widespread, functions that did not return a value were called procedures; Fortran has always called them subroutines).
Extensive nesting of procedures/functions was once very common, at least in languages that supported it, e.g., Algol 60 and Pascal, but not Fortran or Cobol. The spread of C, and then C++ and later Java, which did not support nesting (supported by gcc as an extension, nested classes are available in C++/Java, and later via lambda functions), erased nesting from coding consideration. I started life coding mostly in Fortran, moved to Pascal and made extensive use of nesting, then had to use C and not being able to nest functions took some getting used to. Even when using languages that support nesting (e.g., Python), I have not reestablished by previous habit of using nesting.
A common rationale for not supporting nested functions/methods is that it complicate the language specification and its implementation. A rather self-centered language designer point of view.
The following Pascal example illustrates a benefit of being able to nest procedures/functions:
procedure p1; var db :array[db_size] of char; procedure p2(offset :integer); function p3 :integer; begin (* ... *) return db[offset]; end; begin var off_val :char; off_val=p3; (* ... *) end; begin (* ... *) p2(3) end; |
The benefit of using nesting is in not forcing the developer to have to either define db at global scope, or pass it as an argument along the call chain. Nesting procedures is also a method of information hiding, a topic that took off in the 1970s.
To what extent did Algol/Pascal developers use nested procedures? A 1979 report by G. Benyon-Tinker and M. M. Lehman contains the only data I am aware of. The authors analysed the evolution of procedure usage within a banking application, from 1973 to 1978. The Algol 60 source grew from 35,845 to 63,843 LOC (657 procedures to 967 procedures). A large application for the time, but a small dataset by today’s standards.
The plot below shows the number of procedures/functions having a particular lexical nesting level, with nesting level 1 is the outermost level (i.e., globally visible procedures), and distinct colors denoting successive releases (code+data):
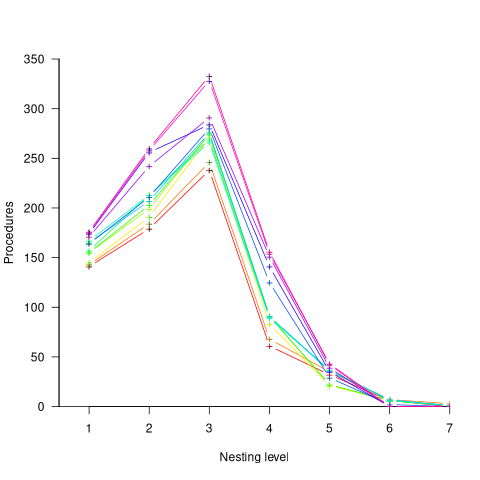
Just over 78% of procedures are nested within at least one other procedure. It’s tempting to think that nesting has a Poisson distribution, however, the distribution peaks at three rather than two. Perhaps it’s possible to fit an over-dispersed, but this feels like creating a just-so story.
What is the distribution of nested functions/methods in more recently written source? A study of 35 Python projects found 6.5% of functions nested and over twice as many (14.2%) of classed nested.
Are there worthwhile benefits to using nested functions/methods where possible, or is this once common usage mostly fashion driven with occasional benefits?
Like most questions involving cost/benefit analysis of language usage, it’s probably not sufficiently interesting for somebody to invest the effort required to run a reliable study.
Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
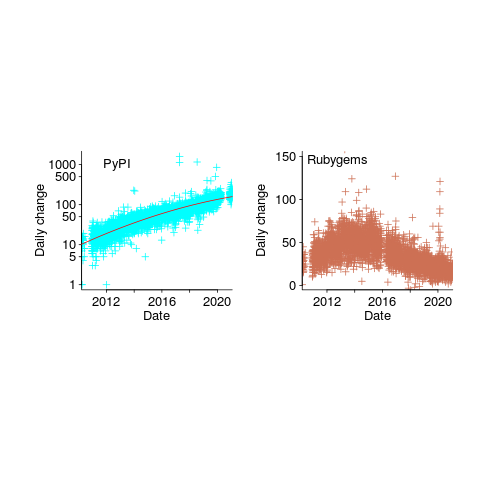
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
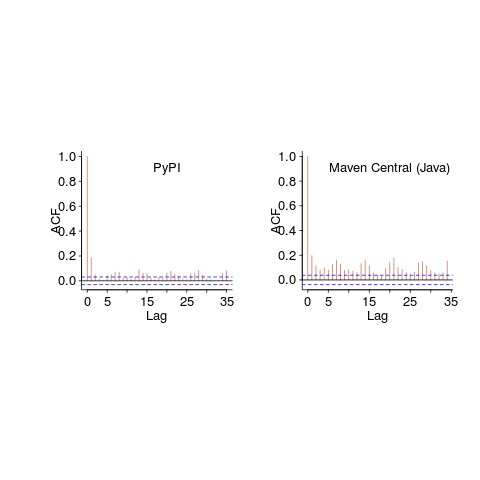
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Exercises in Programming Style: the python way
Exercises in Programming Style by Cristina Lopes is an interesting little book.
The books I have previously read on programming style pick a language, and then write various programs in that language using different styles, idioms, or just following quirky rules, e.g., no explicit loops, must use sets, etc. “Algorithms in Snobol 4” by James F. Gimpel is a fascinating read, but something of an acquired taste.
EPS does pick a language, Python, but the bulk of the book is really a series of example programs illustrating a language feature/concept that is central to a particular kind of language, e.g., continuation-passing style, publish-subscribe architecture, and reflection. All the programs implement the same problem: counting the number of occurrences of each word in a text file (Jane Austin’s Pride and Prejudice is used).
The 33 chapters are each about six or seven pages long, and contain a page or two or code. Everything is very succinct, and does a good job of illustrating one main idea.
While the first example does not ring true, things quickly pick up and there are lots of interesting insights to be had. The first example is based on limited storage (1,024 bytes), and just does not make efficient use of the available bits (e.g., upper case letters can be represented using 5-bits, leaving three unused bits or 37% of available storage; a developer limited to 1K would not waste such a large amount of storage).
Solving the same problem in each example removes the overhead of having to learn what is essentially housekeeping material. It also makes it easy to compare the solutions created using different ideas. The downside is that there is not always a good fit between the idea being illustrated and the problem being solved.
There is one major omission. Unstructured programming; back in the day it was just called programming, but then structured programming came along, and want went before was called unstructured. Structured programming allowed a conditional statement to apply to multiple statements, an obviously simple idea once somebody tells you.
When an if-statement can only be followed by a single statement, that statement has to be a goto; an if/else is implemented as (using Fortran, I wrote lots of code like this during my first few years of programming):
IF (I .EQ. J) GOTO 100 Z=1 GOTO 200 100 Z=2 200 |
Based on the EPS code in chapter 3, Monolithic, an unstructured Python example might look like (if Python supported goto):
for line in open(sys.argv[1]): start_char = None i = 0 for c in line: if start_char != None: goto L0100 if not c.isalnum(): goto L0300 # We found the start of a word start_char = i goto L0300 L0100: if c.isalnum(): goto L0300 # We found the end of a word. Process it found = False word = line[start_char:i].lower() # Ignore stop words if word in stop_words: goto L0280 pair_index = 0 # Let's see if it already exists for pair in word_freqs: if word != pair[0]: goto L0210 pair[1] += 1 found = True goto L0220 L0210: pair_index += 1 L0220: if found: goto L0230 word_freqs.append([word, 1]) goto L0300 L0230: if len(word_freqs) <= 1: goto L0300: # We may need to reorder for n in reversed(range(pair_index)): if word_freqs[pair_index][1] <= word_freqs[n][1]: goto L0240 # swap word_freqs[n], word_freqs[pair_index] = word_freqs[pair_index], word_freqs[n] pair_index = n L0240: goto L0300 L0280: # Let's reset start_char = None L0300: i += 1 |
If you do feel a yearning for the good ol days, a goto package is available, enabling developers to write code such as:
from goto import with_goto @with_goto def range(start, stop): i = start result = [] label .begin if i == stop: goto .end result.append(i) i += 1 goto .begin label .end return result |
Student projects for 2019/2020
It’s that time of year when students are looking for an interesting idea for a project (it might be a bit late for this year’s students, but I have been mulling over these ideas for a while, and might forget them by next year). A few years ago I listed some suggestions for student projects, as far as I know none got used, so let’s try again…
Checking the correctness of the Python compilers/interpreters. Lots of work has been done checking C compilers (e.g., Csmith), but I cannot find any serious work that has done the same for Python. There are multiple Python implementations, so it would be possible to do differential testing, another possibility is to fuzz test one or more compiler/interpreter and see how many crashes occur (the likely number of remaining fault producing crashes can be estimated from this data).
Talking to the Python people at the Open Source hackathon yesterday, testing of the compiler/interpreter was something they did not spend much time thinking about (yes, they run regression tests, but that seemed to be it).
Finding faults in published papers. There are tools that scan source code for use of suspect constructs, and there are various ways in which the contents of a published paper could be checked.
Possible checks include (apart from grammar checking):
- incorrect or inaccurate numeric literals.
Checking whether the suspect formula is used is another possibility, provided the formula involved contains known constants.
- inconsistent statistics reported (e.g., “8 subjects aged between 18-25, average age 21.3″ may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average), and various tools are available (e.g., GRIMMER).
Citation errors are relatively common, but hard to check automatically without a good database (I have found that a failure of a Google search to return any results is a very good indicator that the reference does not exist).
There are lots of tools available for taking pdf files apart; I use pdfgrep a lot
Number extraction. Numbers are some of the most easily checked quantities, and anybody interested in fact checking needs a quick way of extracting numeric values from a document. Sometimes numeric values appear as numeric words, and dates can appear as a mixture of words and numbers. Extracting numeric values, and their possible types (e.g., date, time, miles, kilograms, lines of code). Something way more sophisticated than pattern matching on sequences of digit characters is needed.
spaCy is my tool of choice for this sort of text processing task.
The 520’th post
This is the 520’th post on this blog, which will be 10-years old tomorrow. Regular readers may have noticed an increase in the rate of posting over the last few months; at the start of this month I needed to write 10 posts to hit my one-post a week target (which has depleted the list of things I keep meaning to write about).
What has happened in the last 10-years?
- I no longer visit libraries, which are becoming coffee shops+wifi hot-spots where people who have librarian in their job title, hot desk; books, they are around here somewhere. I used to regularly visit libraries, particularly while working on my C book. No libraries have so far needed to be visited, for the writing of my evidence-based software engineering book,
- many old manuals, reports, books and magazines became freely available for download, via sites like the Internet Archive, Bitsavers and the Defense Technical Information Center; for second hand books there is AbeBooks. Site like Research Gate, Semantic Scholar and Google Scholar are fantastic sources for more recent work; for new books there is Amazon,
- Github became the place to make source code+stuff available,
- researchers in software engineering started to become interested in evidence-based research. In the UK the CREST Open Workshops were a fantastic series of events; I went to about a third of them, and there were often a couple of gold nuggets per event (a change of funding means running future events will require a lot more work),
- smart phones became the last, next, major software consumer ecosystem (capturing a large percentage of the world’s population means there is no room left for something bigger), and the cloud started on its path to being 99% of the commercial software ecosystem,
- Python joined the short-list to become the world’s primary programming language (assuming that people still run programs outside of the browser). The decline of PERL became very obvious, and work on adding new features to Cobol stopped (work on adding features to Fortran is still going strong),
- known faults are now being automatically fixed by modifying the source code (using genetic programming). This has yet to move out of research, but we all know where it’s going,
- whole program optimization of systems containing millions of lines of code became a viable option for commercial developers (a topic of late night discussion for compiler writers in the 1980s, and perhaps earlier decades, when having more than 64K of memory was treated as nirvana),
- after 20-years of being the only major open source compiler tool-chain, gcc got some serious competition. I originally predicted that llvm would disappear, failing to recognize that Apple were supporting it for licensing reasons,
- the death throes of Moore’s law went from subtle to, isn’t it dead yet?
I probably missed several major events hiding in plain sight, either because I am too close to them or blinkered.
What did not happen in the last 10 years?
- No major new languages. These require major new hardware ecosystems; in the smartphone market Android used Java and iOS made use of existing languages. There were the usual selection of fashion/vanity driven wannabes, e.g., Julia, Rust, and Go. The R language started to get noticed, but it has been around since 1995, and Python looks set to eventually kill it off,
- no accident killing 100+ people has been attributed to faults in software. Until this happens, software engineering has a dead bodies problem,
- the creation of new software did not slow down from its break-neck speed,
- in the first few years of this blog I used to make yearly predictions, which did not happen (most of the time).
Now I can relax for 9.5 years, before scurrying to complete 1,040 posts, i.e., the rate of posting will now resume its previous, more sedate, pace.
StatsModels: the first nail in R’s coffin
In 2012, when I decided to write a book on evidence-based software engineering, R was the obvious system to use for data analysis. At the time, lots of new books had “using R” or “with R” added at the end of their titles; I chose “using R”.
When developers tell me they need to do some statistical analysis, and ask whether they should use Python or R, I tell them to use Python if statistics is a small part of the program, otherwise use R.
If I started work on the book today, I would till choose R. If I were starting five-years from now, I could be choosing Python.
To understand why I think Python will eventually take over the niche currently occupied by R, we need to understand the unique selling points of both systems.
R’s strengths are that it supports a way of thinking that is a good fit for doing data analysis and has an extensive collection of packages that simplify the task of applying a wide variety of analysis techniques to data.
Python also has packages supporting the commonly used data analysis techniques. But nearly all the Python packages provide a developer-mentality interface (i.e., they provide an API like any other package), R provides data-analysis-mentality interfaces. R supports a way of thinking that data analysts can identify with.
Python’s strengths, over R, are a much larger base of developers and language support for writing large programs (R is really a scripting language). Yes, Python has a package ecosystem supporting the full spectrum of application domains, this is not relevant for analysing a successful invasion of R’s niche market (but it is relevant for enticing new developers who are still making up their mind).
StatsModels is a Python package based around R’s data-analysis-mentality interface. When I discovered this package a few months ago, I realised the first nail had been hammered into R’s coffin.
Yes, today R has nearly all the best statistical analysis packages and a large chunk of the leading edge stuff. But packages can be reimplemented (C code can be copy-pasted, the R code mapped to Python); there is no magic involved. Leading edge has a short shelf life, and what proves to be useful can be duplicated; the market for leading edge code in a mature market (e.g., data analysis) is tiny.
A bunch of bright young academics looking to make a name for themselves will see the major trees in the R forest have been felled. The trees in the Python data-analysis-mentality forest are still standing; all it takes is a few people wanting to be known as the person who implemented the Python package that everybody uses for XYZ analysis.
A collection of packages supporting the commonly (and eventually not so commonly) used data analysis techniques, with a data-analysis-mentality interface, removes a major selling point for using R. Python is a bigger developer market with support for many other application domains.
The flow of developers starting out with R will slow down, casual R users will have nothing to lose from trying out another language when the right project comes along (another language on the CV looks good and Python is a bigger market). There will be groups where everybody uses R and will continue to use R because that is what everybody else in the group uses. Ten-Twenty years from now R, developers could be working in a ghost town.
Perl’s failure to grow and Python takes over
Perl, once the most widely used scripting language, has been in decline for many years; the decline now looks terminal (many decades from now, when its die-hard users have died), what happened?
Python is what happened. Why was this? Did Perl have a major fail, did Python acquire pixie dust that could not be replicated, or something else?
Some commentators point to the failure to produce a timely release of Perl 6; a major reworking of the language announced in 2000 with a stumbling release made available around 2015.
I think the real issue is a failure for Perl to take off outside its core use as a systems language. Perl is famous for its one-liners, but not for writing large programs (yes, it can be done, but would many developers would really want to?); a glance of the categories in its module library shows; those 174,970 modules (at the time of writing) are not widely spread over application domains (i.e., not catering to a wide audience).
Perl 5 was failing to grow outside its base before Perl 6 began its protracted failure to launch.
Language use is a winner take-all game, developers create more packages, support tools, and new users who combine to attract more developers. Continuing support for minority languages comes from die-hard users, existing software that is worth somebody paying to maintain and niche advantages.
These days, language success is founded on the associated package ecosystem (Go and Rust have minuscule package ecosystems, which is why they are living on borrowed time, other languages will eventually take away their sheen of trendiness). Developers use languages to build stuff, the days of writing the code for almost everything are long gone; interesting software is created by taking advantage of packages written by others. Python was in the right place, at the right time to acquire a wide variety of commercial grade packages.
It’s difficult to see Python being displaced as the lingua franca of software development. Its language features are almost irrelevant, its package ecosystem is everything. The winner will eventually take all.
I’m sure the cycle of languages becoming popular for a few years, before disappearing, will continue. There have always been, and will always be, fashionable languages.
Evolutionary pressures on C++, Java and Python
The future evolution of C++, Java and Python is being driven by very different interested parties, and it’s going to be interesting watching events unfold over the next 5-10 years.
I have previously written about how the C++ Standard’s committee is past its sell-by date, has taken off its ball and chain and is now in the hands of bored consultants.
Bjarne Stroustrup was once effectively treated as C++’s Benevolent Dictator For Life (during the production of the first C++ Standard some people were labeled as Bjarne groupees); things have moved on since then, but the ‘old-guard’ are trying to make a comeback. Suggesting that people ought to base their thinking on a book published almost 25-years ago (Stroustrup’s “The Design and Evolution of C++”; a very interesting book that is well worth reading) creates a rather backward looking image. Bored consultants are looking to work on exciting new ideas. The old-guard need to appear modern to attract followers (even if the ideas are old ideas with a fresh coat of paint).
The threat to C++ is from bored consultants, each adding their own pet idea to the language standard; a situation that Stroustrup thinks is starting to happen.
Java, the language, is owned by Oracle, the company (let’s not get too involved in exactly what they own, have copyright on, etc). Oracle are not shy about asking people for licensing fees. Java is now on a 6-month release cycle (at least the Oracle version, there are Open Source implementations) and the free support only applies to the current release; paying a license fee buys support for versions older than 6-months. In the short term, the cheapest solution is for companies to pay for support.
Oracle are always happy to send in the lawyers and if too many customers switch to non-Oracle implementations, I’m sure something can be found to introduce enough uncertainty to discourage work/distribution involving Open Source Java implementations.
Will Java survive Oracle’s licensing? It is not in their interest for Java to die; Oracle will adjust their terms to keep the money flowing in, but over the longer term I think willing Java developers are going to be hard to find.
Guido van Rossum recently removed himself from the post of Python’s Benevolent Dictator For Life. One of the jobs of a benevolent dictator is maintaining some degree of language coherence, which involves preventing people’s pet ideas from being added to the language. Does this mean that Python is slowly going to be become more and more bloated? Perhaps, but I think a more likely problem is a language fork, multiple implementations of slightly different (at first) languages all claiming to be Python.
These days, the strength of Python is its large collection of very useful, commercial grade, packages, and future language details may turn out to be irrelevant. There is a lot to learn from the Python 2/3 transition, but true believers like to think that things will turn out differently for them.
Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
Recent Comments