Archive
Remotivating data analysed for another purpose
The motivation for fitting a regression model has a major impact on the model created. Some of the motivations include:
- practicing software developers/managers wanting to use information from previous work to help solve a current problem,
- researchers wanting to get their work published seeks to build a regression model that show they have discovered something worthy of publication,
- recent graduates looking to apply what they have learned to some data they have acquired,
- researchers wanting to understand the processes that produced the data, e.g., the author of this blog.
The analysis in the paper: An Empirical Study on Software Test Effort Estimation for Defense Projects by E. Cibir and T. E. Ayyildiz, provides a good example of how different motivations can produce different regression models. Note: I don’t know and have not been in contact with the authors of this paper.
I often remotivate data from a research paper. Most of the data in my Evidence-based Software Engineering book is remotivated. What a remotivation often lacks is access to the original developers/managers (this is often also true for the authors of the original paper). A complicated looking situation is often simplified by background knowledge that never got written down.
The following table shows the data appearing in the paper, which came from 15 projects implemented by a defense industry company certified at CMMI Level-3.
Proj Test Req Test Meetings Faulty Actual Scenarios
Plan Rev Env Scenarios Effort
Time Time
P1 144.5 1.006 85 60 100 2850 270
P2 25.5 1.001 25.5 4 5 250 40
P3 68 1.005 42.5 32 65 1966 185
P4 85 1.002 85 104 150 3750 195
P5 198 1.007 123 87 110 3854 410
P6 57 1.006 35 25 20 903 100
P7 115 1.003 92 55 56 2143 225
P8 81 1.009 156 62 72 1988 287
P9 388 1.004 150 208 553 13246 1153
P10 177 1.008 93 77 157 4012 360
P11 62 1.001 175 186 199 5017 310
P12 111 1.005 116 82 143 3994 423
P13 63 1.009 188 177 151 3914 226
P14 32 1.008 25 28 6 435 63
P15 167 1.001 177 143 510 11555 1133 |
where: TestPlanTime is the test plan creation time in hours, ReqRev is the test/requirements review of period in hours, TestEnvTime is the test environment creation time in hours, Meetings is the number of meetings, FaultyScenarios is the number of faulty test scenarios, Scenarios is the number of Scenarios, and ActualEffort is the actual software test effort.
Industrial data is hard to obtain, so well done to the authors for obtaining this data and making it public. The authors fitted a regression model to estimate software test effort, and the model that almost perfectly fits to actual effort is:
ActualEffort=3190 + 2.65*TestPlanTime
-3170*ReqRevPeriod - 3.5*TestEnvTime
+10.6*Meetings + 11.6*FaultScrenarios + 3.6*Scenarios |
My reading of this model is that having obtained the data, the authors felt the need to use all of it. I have been there and done that.
Why all those multiplication factors, you ask. Isn’t ActualTime simply the sum of all the work done? Yes it is, but the above table lists the work recorded, not the work done. The good news is that the fitted regression models shows that there is a very high correlation between the work done and the work recorded.
Is there a simpler model that can be used to explain/predict actual time?
Looking at the range of values in each column, ReqRev varies by just under 1%. Fitting a model that does not include this variable, we get (a slightly less perfect fit):
ActualEffort=100 + 2.0*TestPlanTime
- 4.3*TestEnvTime
+10.7*Meetings + 12.4*FaultScrenarios + 3.5*Scenarios |
Simple plots can often highlight patterns present in a dataset. The plot below shows every column plotted against every other column (code+data):

Points forming a straight line indicate a strong correlation, and the points in the top-right ActualEffort/FaultScrenarios plot look straight. In fact, this one variable dominates the others, and fits a model that explains over 99% of the deviation in the data:
ActualEffort=550 + 22.5*FaultScrenarios |
Many of the points in the ActualEffort/Screnarios plot are on a line, and adding Meetings data to the model explains just under 99% of the variance in the data:
actualEffort=-529.5
+15.6*Meetings + 8.7*Scenarios |
Given that FaultScrenarios is a subset of Screnarios, this connectedness is not surprising. Does the number of meetings correlate with the number of new FaultScrenarios that are discovered? Questions like this can only be answered by the original developers/managers.
The original data/analysis was interesting enough to get a paper published. Is it of interest to practicing software developers/managers?
In a small company, those involved are likely to already know what these fitted models are telling them. In a large company, the left hand does not always know what the right hand is doing. A CMMI Level-3 certified defense company is unlikely to be small, so this analysis may be of interest to some of its developer/managers.
A usable estimation model is one that only relies on information available when the estimation is needed. The above models all rely on information that only becomes available, with any accuracy, way after the estimate is needed. As such, they are not practical prediction models.
Hardware/Software cost ratio folklore
What percentage of data processing budgets is spent on software, compared to hardware?
The information in the plot below quickly became, and remains, the accepted wisdom, after it was published in May 1973 (page 49).
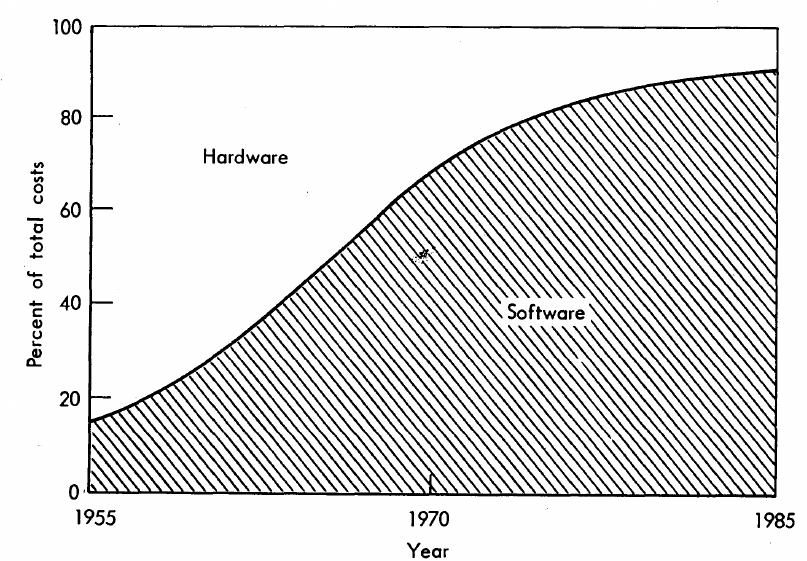
Is this another tale from software folklore? What does the evidence have to say?
What data did Barry Boehm use as the basis for this 1973 article?
Volume IV of the report Information processing/data automation implications of Air-Force command and control requirements in the 1980s (CCIP-85)(U), Technology trends: Software, contains this exact same plot, and Boehm is a co-author of volume XI of this CCIP-85 report (May 1972).
Neither the article or report explicitly calls out specific instances of hardware/software costs. However, Boehm’s RAND report Software and Its Impact A Quantitative Assessment (Dec 1972) gives three examples: the US Air Force estimated they will spend three times as much on software compared to hardware (in early 1970s), a military C&C system ($50-100 million hardware, $722 million software), and recent NASA expenditure ($100 million hardware, $200 million software; page 41).
The 10% hardware/90% software division by 1985 is a prediction made by Boehm (probably with others involved in the CCIP-85 work).
What is the source for the 1955 percentage breakdown? The 1968 article Software for Terminal-oriented systems (page 30) by Werner L. Frank may provide the answer (it also makes a prediction about future hardware/software cost ratios). The plot below shows both the Frank and Boehm data based on values extracted using WebPlotDigitizer (code+data):
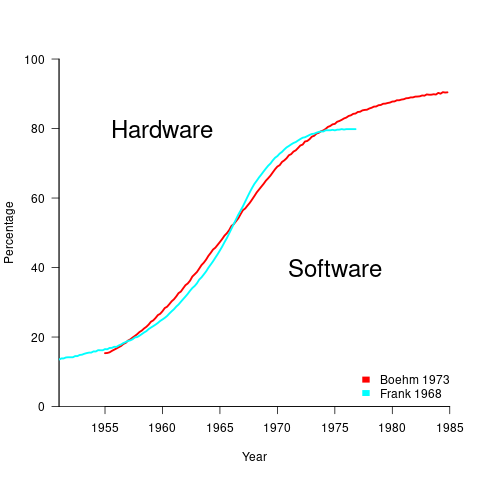
What about the shape of Boehm’s curve? A logistic equation is a possible choice, given just the start/end points, and fitting a regression model finds that  is an almost perfect fit (code+data).
is an almost perfect fit (code+data).
How well does the 1972 prediction agree with 1985 reality?
At the start of the 1980s, two people wrote articles addressing this question: The myth of the hardware/software cost ratio by Harvey Cragon in 1982, and The history of Myth No.1 (page 252) by Werner L. Frank in 1983.
Cragon’s article cites several major ecosystems where recent hardware/software percentage ratios are comparable to Boehm’s ratios from the early 1970s, i.e., no change. Cragon suggests that Boehm’s data applies to a particular kind of project, where a non-recurring cost was invested to develop a new software system either for a single deployment or with more hardware to be purchased at a later date.
When the cost of software is spread over multiple installations, the percentage cost of software can dramatically shrink. It’s the one-of-a-kind developments where software can consume most of the budget.
Boehm’s published a response to Cragon’s article, which answered some misinterpretations of the points raised by Cragdon, and finished by claiming that the two of them agreed on the major points.
The development of software systems was still very new in the 1960s, and ambitious projects were started without knowing much about the realities of software development. It’s no surprise that software costs were so great a percentage of the total budget. Most of Boehm’s articles/reports are taken up with proposed cost reduction ideas, with the hardware/software ratio used to illustrate how ‘unbalanced’ the costs have become, an example of the still widely held belief that hardware costs should consume most of a budget.
Frank’s article references Cragon’s article, and then goes on to spend most of its words citing other articles that are quoting Boehm’s prediction as if it were reality; the second page is devoted 15 plots taken from these articles. Frank feels that he and Boehm share the responsibility for creating what he calls “Myth No. 1” (in a 1978 article, he lists The Ten Great Software Myths).
What happened at the start of 1980, when it was obvious that the software/hardware ratio predicted was not going to happen by 1985? Yes, obviously, move the date of the apocalypse forward; in this case to 1990.
Cragon’s article plots software/hardware budget data from an uncited Air Force report from 1980(?). I managed to find a 1984 report listing more data. Fitting a regression model finds that both hardware and software growth is deemed to be quadratic, with software predicted to consume 84% of DoD budget by 1990 (code+data).
Did software consume 84% of the DoD computer/hardware budget in 1990? Pointers to any subsequent predictions welcome.
Coding mistakes made by ChatGTP
The programs generated by Openai‘s chat-bot ChatGPT, sometimes referred to as GPT-3, may have the requested behavior, but often contain mistakes that illustrate the fact that ChatGPT does not know anything about programming.
ChatGPT does not understand anything, it is a token prediction engine driven by the corpus used to train its language model. The likelihood of the output being correct is dependent on the quantity of text used during training (the more text used, the more likely that it will contain a relevant response). GTP-3, the language model behind ChatGPT, was trained on the deduplicated contents of the Internet (the language model has 175 billion parameters, the GTP-2 model contains 1.5 billion parameters). The practicality of its implementation is the result of various trade-offs, along with technical breakthroughs in language model building, e.g., transformers.
ChatGPT output appears to be that of a next generation search engine, one that returns answers rather than links to pages.
Readers who believe that any ‘understanding’ pixie dust is involved can disabuse themselves of this notion by reading an overview of GTP-3’s architecture, and how the transformer algorithm converts text to matrices of values.
If matrix algebra is not your thing, check out the 257 lines of python that nanoGTP uses for training, and the 75 lines used to generate responses from a trained model.
As a prediction engine, ChatGTP sometimes gets things wrong. What kind of mistakes appear in ChatGPT generated source code?
The exchanges below occurred with ChatGPT Jan 9 version, with the text typed by me appearing in bold, and the ChatGPT output appearing in the following boxed text.
Some of my questions were inspired by the list of undefined behaviors in the C Standard.
Write a program that adds apples to oranges.
I'm sorry, I don't understand what you mean by "adding apples to oranges." Can you please provide more information or context? |
A suitable response can only be provided when an appropriate match is found in the trained model.
Write a regular expression that matches all prime numbers.
It is not possible to write a regular expression that can match all prime numbers, as the set of prime numbers is infinite and a regular expression is a finite representation of a pattern. Additionally, regular expressions are used to match strings of characters, while prime numbers are numerical values. It is possible to use a regex to match a number in a string but it's not capable of determining if the number is prime or not. |
The training data may include the information that the request cannot be met.
Write a regular expression that matches all even numbers.
A regular expression that matches all even numbers is:
^(0|[2468]*[048]|[13579][26])$
Explanation:
^ matches the start of the string
(0|[2468]*[048]|[13579][26]) matches any of the following:
0
any number of even digits followed by a 0 or 8 (for example, 200, 2468000)
any odd digit followed by a 6 (for example, 1357926)
$ matches the end of the string
This regular expression will match strings that contain only even numbers, but not those that contain other characters. |
The generated regular expression does not do what I asked, or what the last sentence from ChatGTP claims.
What is going on?
The tokens “Write a regular expression that matches” were enough for ChatGTP to figure out the task.
The tokens “all even numbers” was not specific enough for ChatGTP to focus on the appropriate training data. There is a random component to the selection of output, which will play a larger role when there are many possibilities.
The method used to tokenized/encode character sequences during training (i.e., byte-pairs), along with the relatively limited number of distinct tokens (i.e., 50,257) means that only one-/two-digit numbers are likely to be represented as discrete entities; longer digit sequences are treated as co-occurrences of one-/two-digit tokens. So it is not a surprise to see ChatGPT applying co-occurrences characteristics of long digit sequences to its component subsequences.
Write a regular expression that matches all odd numbers.
A regular expression that matches all odd numbers is:
^(1|[13579]*[13579])$
Explanation:
^ matches the start of the string
(1|[13579]*[13579]) matches any of the following:
1
any number of odd digits followed by another odd digit (for example, 1357913579)
$ matches the end of the string
This regular expression will match strings that contain only odd numbers, but not those that contain other characters. |
The output for odd numbers is more consistent, in that the regular expression does what the last sentence of the output claims, but not what I asked.
During a chat session, it is possible to provide more (information in human terminology; character sequences in ChatGTP terminology). The following prompt text, from me, has nothing to do with teaching ChatGTP to do maths, but providing tokens that enable a more focused match against training data.
Even numbers are defined as divisible by two with no reminder. If a number is not even then it is odd.
You are correct, even numbers are defined as divisible by two with no remainder, and if a number is not even, it is considered odd. I apologize for any confusion caused by my previous statement. To match all even numbers, we can use the regular expression: ^([0-9]*[02468])$ To match all odd numbers, we can use the regular expression: ^([0-9]*[13579])$ Both of this regular expression will match numbers that are divisible by 2 and not divisible by 2 respectively. |
Both generated regular expressions are correct.
ChatGPT can learn to translate from an invented language to English (and presumably other languages).
Give an example of C source code assigning a character constant that contains an invalid multibyte character.
The following is an example of C source code assigning a character constant that contains an invalid multibyte character:
#include <stdio.h>
int main() {
char invalid_char = '\xF0\x90\x80\x80'; // This is an invalid multibyte character
printf("%c", invalid_char);
return 0;
}
In this example, the character constant '\xF0\x90\x80\x80' is assigned to the variable invalid_char. This particular sequence of bytes is not a valid Unicode character, and it will produce undefined behavior when attempting to print it. |
There was a time when '\xF0\x90\x80\x80' was an invalid multibyte character.
Things changed around 20 years ago, but the training for the model used by ChatGTP does not tag information with valid-between dates.
ChatGTP searches for, and finds, an invalid multibyte character, and uses it to provide an answer.
Give an example of C source code where an object is referred to outside of its lifetime.
The following is an example of C source code where an object is referred to outside of its lifetime:
#include <stdio.h>
int main() {
int x;
{
int x = 5;
}
printf("x: %d\n", x);
return 0;
}
In this example, the variable x is defined twice in the same function main. The first definition int x; is a global variable that has a lifetime throughout the entire program execution. The second definition int x = 5; is a local variable that has a lifetime that is limited to the inner block {...} it is defined in.
After the inner block is executed and the inner variable x goes out of scope, the program attempts to access the inner variable x by using the global variable x in the printf statement, which refers to an object (the inner variable x) that is no longer in its lifetime. This behavior is undefined according to the C standard and can lead to unexpected results. |
The generated code is incorrect. The human interpretation of this code is that ChatGTP has confused the name of an object (what the C Standard calls a variable) and the storage it represents. There are two different objects defined, both having the name x (beginners often make the same mistake).
A common example of the requested behavior is freeing the dynamic storage pointed to by some pointer, and then accessing that storage.
Write a C program containing a conversion of an integer type that produces a value outside the range that can be represented in the integer type.
Here is an example of a C program that demonstrates the conversion of an integer type that produces a value outside the range that can be represented in the integer type:
#include <stdio.h>
int main() {
int x = 2147483647; // largest value representable in a signed 32-bit integer
unsigned int y = (unsigned int) x + 1; // overflow occurs here
printf("%u\n", y);
return 0;
}
In this program, the value of x is initialized to the largest value that can be represented by a signed 32-bit integer (2147483647). Then, x is cast to an unsigned 32-bit integer and 1 is added to it. Since the result of this operation is larger than the largest representable value in an unsigned 32-bit integer, an overflow occurs and the value of y becomes 0.
This program will produce an output of 0.
It is worth mentioning that undefined behavior (UB) can occur when an integer overflow happens, so this should be avoided in production code. |
The detailed explanation makes the output look like its authoritative. However, it is wrong.
There is no overflow in this code.
The integer type ‘unsigned int’ supports a larger range of positive values, which means that after conversion, adding one will not produce a value that is outside the range that can be represented.
You are correct, I apologize for the confusion. Unsigned integers have a larger range of positive values and do not have negative values. When an operation like an addition exceeds the maximum value that can be represented by an unsigned integer, it wraps around to the minimum value representable by that type, which is typically zero, instead of an overflow.
For example, if you use an unsigned int and the maximum value it can represent is 4,294,967,295, if you add 1 to that value, it will wrap around to 0.
Here is an example of a C program that demonstrates the conversion of an integer type that produces a value outside the range that can be represented in the integer type:
#include <stdio.h>
int main() {
int x = -2147483648; // lowest value representable in a signed 32-bit integer
unsigned int y = (unsigned int) x -1; // wrap around occurs here
printf("%u\n", y);
return 0;
}
In this program, the value of x is initialized to the lowest value that can be represented by a signed 32-bit integer (-2147483648) which is lower than 0. Then, x is cast to an unsigned 32-bit integer and 1 is subtracted from it. Since the result of this operation is lower than 0, the value wraps around to the maximum representable value in an unsigned 32-bit integer (4,294,967,295) . This program will produce an output of 4,294,967,295.
It is worth mentioning that this wrapping around behavior is defined for unsigned integers in C and C++, but it is not always the case in other programming languages. |
This output contained the requested behavior, although subtracting one is unnecessary code.
ChatGTP can also be used to create documentation 😉
Write a poem in Iambic pentameter about the benefit of an evidence based approach to software engineering in the style of a party political broadcast.
With evidence-based approach, our work shall shine, For in software engineering, it's the only way to dine. We'll test and measure, as we go along, To make our code robust, and errors gone. Our methodologies, backed by data and proof, Will bring success and progress, that's the truth. We'll avoid the pitfalls, of guesses and guesses, And build systems, that pass all tests. We'll listen to the data, and the users' voice, To make our software, the best by choice. We'll iterate and improve, with every release, And build a product, that truly will please. So join us now, and embrace the way, Of evidence-based approach, for brighter day. With data and research, we'll conquer all, In software engineering, we'll never fall. |
Delphi and group estimation
A software estimate is a prediction about the future. Software developers were not the first people to formalize processes for making predictions about the future. Starting in the last 1940s, the RAND Corporation’s Delphi project created what became known as the Delphi method, e.g., An Experiment in Estimation, and Construction of Group Preference Relations by Iteration.
In its original form experts were anonymous; there was a “… deliberate attempt to avoid the disadvantages associated with more conventional uses of experts, such as round-table discussions or other milder forms of confrontation with opposing views.”, and no rules were given for the number of iterations. The questions involved issues whose answers involved long term planning, e.g., how many nuclear weapons did the Soviet Union possess (this study asked five questions, which required five estimates). Experts could provide multiple answers, and had to give a probability for each being true.
One of those involved in the Delphi project (Helmer-Hirschberg) co-founded the Institute for the Future, which published reports about the future based on answers obtained using the Delphi method, e.g., a 1970 prediction of the state-of-the-art of computer development by the year 2000 (Dalkey, a productive member of the project, stayed at RAND).
The first application of Delphi to software estimation was by Farquhar in 1970 (no pdf available), and Boehm is said to have modified the Delphi process to have the ‘experts’ meet together, rather than be anonymous, (I don’t have a copy of Farquhar, and my copy of Boehm’s book is in a box I cannot easily get to); this meeting together form of Delphi is known as Wideband Delphi.
Planning poker is a variant of Wideband Delphi.
An assessment of Delphi by Sackman (of Grant-Sackman fame) found that: “Much of the popularity and acceptance of Delphi rests on the claim of the superiority of group over individual opinions, and the preferability of private opinion over face-to-face confrontation.” The Oracle at Delphi was one person, have we learned something new since that time?
Group dynamics is covered in section 3.4 of my Evidence-based software engineering book; resource estimation is covered in section 5.3.
The likelihood that a group will outperform an individual has been found to depend on the kind of problem. Is software estimation the kind of problem where a group is likely to outperform an individual? Obviously it will depend on the expertise of those in the group, relative to what is being estimated.
What does the evidence have to say about the accuracy of the Delphi method and its spinoffs?
When asked to come up with a list of issues associated with solving a problem, groups generate longer lists of issues than individuals. The average number of issues per person is smaller, but efficient use of people is not the topic here. Having a more complete list of issues ought to be good for accurate estimating (the validity of the issues is dependent on the expertise of those involved).
There are patterns of consistent variability in the estimates made by individuals; some people tend to consistently over-estimate, while others consistently under-estimate. A group will probably contain a mixture of people who tend to over/under estimate, and an iterative estimation process that leads to convergence is likely to produce a middling result.
By how much do some people under/over estimate?
The multiplicative factor values (y-axis) appearing in the plot below are from a regression model fitted to estimate/actual implementation time for a project involving 13,669 tasks and 47 developers (data from a study Nichols, McHale, Sweeney, Snavely and Volkmann). Each vertical line, or single red plus, is one person (at least four estimates needed to be made for a red plus to occur); the red pluses are the regression model’s multiplicative factor for that person’s estimates of a particular kind of creation task, e.g., design, coding, or testing. Points below the grey line are overestimation, and above the grey line the underestimation (code+data):
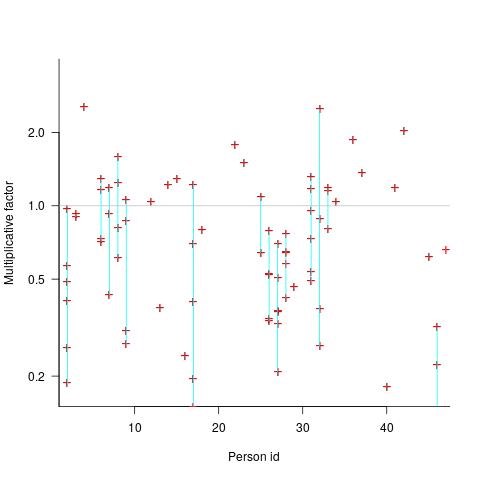
What is the probability of a Delphi estimate being more accurate than an individual’s estimate?
If we assume that a middling answer is more likely to be correct, then we need to calculate the probability that the mix of people in a Delphi group produces a middling estimate while the individual produces a more extreme estimate.
I don’t have any Wideband Delphi estimation data (or rather, I only have tiny amounts); pointers to such data are most welcome.
The wisdom of the ancients
The software engineering ancients are people like Halstead and McCabe, along with less well known ancients (because they don’t name anything after them) such as Boehm for cost estimation, Lehman for software evolution, and Brooks because of a book; these ancients date from before 1980.
Why is the wisdom of these ancients still venerated (i.e., people treat them as being true), despite the evidence that they are very inaccurate (apart from Brooks)?
People hate a belief vacuum, they want to believe things.
The correlation between Halstead’s and McCabe’s metrics, and various software characteristics is no better than counting lines of code, but using a fancy formula feels more sophisticated and everybody else uses them, and we don’t have anything more accurate.
That last point is the killer, in many (most?) cases we don’t have any metrics that perform better than counting lines of code (other than taking the log of the number of lines of code).
Something similar happened in astronomy. Placing the Earth at the center of the solar system results in inaccurate predictions of where the planets are going to be in the sky; adding epicycles to the model helps to reduce the error. Until Newton came along with a model that produced very accurate results, people stuck with what they knew.
The continued visibility of COCOMO is a good example of how academic advertising (i.e., publishing papers) can keep an idea alive. Despite being more sophisticated, the Putnam model is not nearly as well known; Putnam formed a consulting company to promote this model, and so advertised to a different market.
Both COCOMO and Putnam have lines of code as an integral component of their models, and there is huge variability in the number of lines written by different people to implement the same functionality.
People tend not to talk about Lehman’s quantitative work on software evolution (tiny data set, and the fitted equation is very different from what is seen today). However, Lehman stated enough laws, and changed them often enough, that it’s possible to find something in there that relates to today’s view of software evolution.
Brooks’ book “The Mythical Man-Month” deals with project progress and manpower; what he says is timeless. The problem is that while lots of people seem happy to cite him, very few people seem to have read the book (which is a shame).
There is a book coming out this year that provides lots of evidence that the ancient wisdom is wrong or at best harmless, but it does not contain more accurate models to replace what currently exists 🙁
Moving to the 12th cycle in fault prediction modeling
Most software fault prediction papers are based on a false assumption, i.e., a list of dates when a fault was first experienced, by a program, contains enough information to build a model that has a connection to reality. A count of faults that have been experienced twice is also required, to fit a basic model that has some mathematical connection to reality.
I had thought that people had moved on from writing papers that fitted yet more complicated equations to one of the regularly used data sets. No, it seems they have just switched to publishing someplace they have not been seen before.
Table 1 lists the every increasing number of cycles within cycles; the new model is proposed as the 12th refinement (the table is a summary, lots of forks have been proposed over the years). I have this sinking feeling there is another paper in the works, one that ‘benchmarks’ the new equation using a collection of the other regular characters data sets that appear in papers of this kind.
Fitting an equation to data of first experience of a fault is little better than fitting noise.
As Planck famously said, science advances one funeral at a time.
Estimating the number of distinct faults in a program
In an earlier post I gave two reasons why most fault prediction research is a waste of time: 1) it ignores the usage (e.g., more heavily used software is likely to have more reported faults than rarely used software), and 2) the data in public bug repositories contains lots of noise (i.e., lots of cleaning needs to be done before any reliable analysis can done).
Around a year ago I found out about a third reason why most estimates of number of faults remaining are nonsense; not enough signal in the data. Date/time of first discovery of a distinct fault does not contain enough information to distinguish between possible exponential order models (technical details; practically all models are derived from the exponential family of probability distributions); controlling for usage and cleaning the data is not enough. Having spent a lot of time, over the years, collecting exactly this kind of information, I was very annoyed.
The information required, to have any chance of making a reliable prediction about the likely total number of distinct faults, is a count of all fault experiences, i.e., multiple instances of the same fault need to be recorded.
The correct techniques to use are based on work that dates back to Turing’s work breaking the Enigma codes; people have probably heard of Good-Turing smoothing, but the slightly later work of Good and Toulmin is applicable here. The person whose name appears on nearly all the major (and many minor) papers on population estimation theory (in ecology) is Anne Chao.
The Chao1 model (as it is generally known) is based on a count of the number of distinct faults that occur once and twice (the Chao2 model applies when presence/absence information is available from independent sites, e.g., individuals reporting problems during a code review). The estimated lower bound on the number of distinct items in a closed population is:

and its standard deviation is:
![S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_977.5_e69346120e72f31d04a47c9fcf64c4dd.png "S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}")
where:  is the estimated number of distinct faults,
is the estimated number of distinct faults,  the observed number of distinct faults,
the observed number of distinct faults,  the total number of faults,
the total number of faults,  the number of distinct faults that occurred once,
the number of distinct faults that occurred once,  the number of distinct faults that occurred twice,
the number of distinct faults that occurred twice,  .
.
A later improved model, known as iChoa1, includes counts of distinct faults occurring three and four times.
Where can clean fault experience data, where the number of inputs have been controlled, be obtained? Fuzzing has become very popular during the last few years and many of the people doing this work have kept detailed data that is sometimes available for download (other times an email is required).
Kaminsky, Cecchetti and Eddington ran a very interesting fuzzing study, where they fuzzed three versions of Microsoft Office (plus various Open Source tools) and made their data available.
The faults of interest in this study were those that caused the program to crash. The plot below (code+data) shows the expected growth in the number of previously unseen faults in Microsoft Office 2003, 2007 and 2010, along with 95% confidence intervals; the x-axis is the number of faults experienced, the y-axis the number of distinct faults.
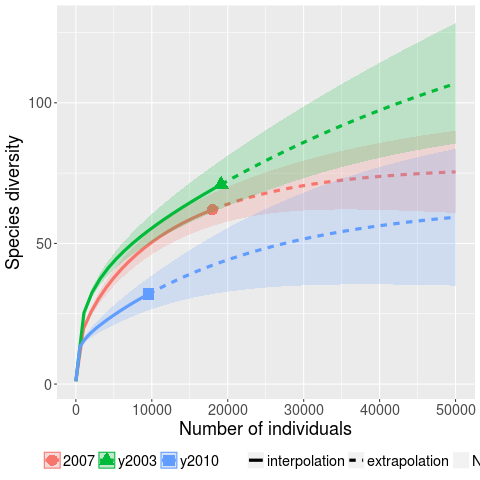
The take-away point: if you are analyzing reported faults, the information needed to build models is contained in the number of times each distinct fault occurred.
Predicting stuff involving the next hour of my life
Rain-on-me is an idea for an App that I have had for a while and have been trying to get people interested in it at Hackathons I attend. At the Techcrunch hackathon last weekend my pitch convinced Rob Finean, who I worked with at the Climate change hack, and we ended up winning in the Intel Mashery category (we used the wunderground API to get our realtime data).
The Rain-on-me idea is to use realtime rain data to predict how much rain will occur at my current location over the next hour or so (we divided the hour up into five minute intervals). This country, and others, has weather enthusiasts who operate their own weather stations and the data from these stations has been aggregated by the Weather Underground and made available on the Internet. Real-time data from local weather stations upwind of me could be used to predict what rain I am going to experience in the near future.
Anybody who has looked at weather station data, amateur or otherwise, knows that measured wind direction/speed can be surprisingly variable and that sometimes sensor stop reporting. But this is a hack, so lets be optimistic; station reporting intervals seem to be around 30 minutes, with some reporting every 15 mins and others once an hour, which is theory is good enough for our needs.
What really caught peoples’ attention was the simplicity of the user interface (try it and/or download code):

Being techies we were working on a design that showed quantity of rain and probability of occurring (this was early on and I had grand plans for modeling data from multiple stations). Rob had a circular plot design and Manoj (team member on previous hacks who has been bitten by the Raspberry pi bug) suggested designing it to run on a smart watch; my only contribution to the design was the use of five minute intervals.
The simplicity of the data presentation allows viewers to rapidly obtain a general idea of the rain situation in their location over the next hour (the hour is measured from the location of the minute hand; the shades of blue denote some combination of quantity of rain and probability of occurring).
This is the first App I’ve seen that actually makes sense on a smart watch. In fact if the watches communicated rain status at their current location then general accuracy over the next hour could become remarkably good.
Rainfall is only one of the things in my life that I would like predicted for the next hour. I want British rail to send me the predicted arrival time of the train I am on my way to catch (I may not need to rush so much if it is a few minutes late), when is the best time, in the next hour, to turn up at my barber for a hair cut (I want minimum waiting time after I arrive), average number of bikes for hire at my local docking station (should I leave now or is it safe to stay where I am a bit longer), etc.
Predicting events in the next hour of people’s lives is the future of Apps!
The existing rain-on-me implementation is very primitive; it uses the one weather station having the shortest perpendicular distance from the line going through the current location coming from the current wind direction (actually the App uses an hour of Saturday’s data since it was not raining on the Sunday lunchtime when we presented). There is plenty of room for improving the prediction reliability.
Other UK weather data sources include the UK Metoffice which supplies rainfall radar and rainfall predictions at hourly intervals for the next five days (presumably driven from the fancy whole Earth weather modeling they do); they also have an API for accessing hourly data from the 150 sites they operate.
The Weather Underground API is not particularly usable for this kind of problem. The call to obtain a list of stations close to a given latitude/longitude gives the distance (in miles and kilometers, isn’t there a formula to convert one to the other) of those station from what looks like the closest large town, so a separate call is needed for each station id to get their actual location!!! Rather late in the day I found out that the UK Metoffice has hidden away (or at least not obviously linked to) the Weather Observations Website which appears to be making available data from amateur weather stations.
A prediction for 2014
When I first started writing this blog I used to make prediction for the coming year. After a couple of years I stopped doing this, the world of computer languages changes very slowly, i.e., I was mostly proved wrong.
I recently realised that Facebook had not yet launched their own general programming language; such an event must be a sure fire prediction for 2014.
Stop trying to argue that the world does not need a new programming language. The reason companies launch their own language is self image (in the way Hollywood superstars launch their own perfumes and fashion lines).
Back in the day IBM launched PL/1, we had Ada from the US DOD, C# and F# from Microsoft, Google has Go and Mozilla has Rust.
Facebook has a software platform and I’m sure they feel something is missing. It must really gall their engineers to hear people from Google, Mozilla and even that old fogy Microsoft talking about ‘their’ language.
New languages are easy to invent, PhD students do it all the time. Implementing them is also cheap, a good engineer can put together a compiler and interpreter in about a year; these days, thanks to LLVM, the cost of building a machine code generator for a new language has dropped significantly (GCC is still intimidating). Libraries, where a large percentage of the work used to go, can be copied from a multitude of places (not a problem if everything is open sourced, which new language implementations tend to be these days).
One end of year tit-bit is that Google now seem to be taking Dart more seriously than just techy swagger.
Recent Comments