Archive
Decline in downloads of once popular packages
What happens to the popularity of Open source packages, measured in monthly downloads, once they cease to be updated or attract new users?
If the software does not have any competition within its domain, there is no reason why its popularity should decline. In practice, there are usually alternative packages offering the same or similar functionality. Even when alternatives are available, existing practice and sunk costs can slow migration. A year or so after I started using Asciidoc to write by Software Engineering book, the author announced that he was no longer going to update the software; initially there was no alternative, but the software did what I wanted, and I have been happily using it over the last 12 years.
The paper: Do All Software Projects Die When Not Maintained? Analyzing Developer Maintenance to Predict OSS Usage by Emily Nguyen measured the monthly downloads, commits and other characteristics of 38K GitHub packages having at least 10K downloads during any month between January 2015 and December 2020. The data made available (more here) is a subset, i.e., downloads for 1,583 projects starting in May 2015.
The author investigated the connection between various project characteristics (focusing on commits or lack thereof in particular) and downloads by fitting a Cox proportional hazards model.
The plot below shows the 67 monthly downloads for a selection of packages; the red line is a fitted local regression used to smooth the data (code and data):

Reasons for a decline from a peak number of downloads include: competition from alternative packages, change of fashion, and market saturation, or perhaps the peak was caused by a one-off event. Whatever the reason for a peak+decline, my interest is learning about patterns in the rate of decline.
Some of the monthly package downloads in the above plot have an obvious peak and decline, with others continually increasing, and others having multiple peaks. The following algorithm was used to select packages having a peak followed by a decline, based on the predicted values from a fitted loess model:
- find the month with the most downloads, this is the primary peak,
- if this month is within 10 months of the end of the measurement period, this is not a peak/decline package,
- does a secondary peak exist? A secondary peak is a month containing the most downloads from 10 months after the end of the primary peak, where the number of downloads is within 66% of the primary peak downloads,
- the secondary peak becomes the primary peak, provided it is not within 10 months of the end of the measurement period.
The final fraction of the primary peak is the average monthly download during the last three months divided by the peak month downloads.
The plot below shows the 693 packages whose final fraction of peak was below 0.6 against months from peak to the last month (at the end of 2020), with the red line showing a fitted regression of the form  (code and data):
(code and data):

As the above plot shows, there don’t appear to be any patterns in the decline of package downloads, and  is a poor predictor of fraction of peak.
is a poor predictor of fraction of peak.
Perhaps a more sophisticated peak+decline selection algorithm will uncover some patterns. Both ChatGPT (its generated python script failed) and Grok (very wrong answers) failed miserably at classifying the plots. Deepseek will only process images to extract text.
Half-life of Open source research software projects
The evidence for applications having a half-life continues to spread across domains. The first published data covered IBM mainframe applications up to 1992 (half-life of at least 5-years), and was mostly ignored. Then, the data collected by Killed by Google up to 2018, showed a half-life of at least 3-years for Google apps. More recently, the data collected by Killed by Microsoft up to 2025, showed a half-life of at least 7-years for Microsoft apps (perhaps reflecting the maturity of the company’s product line).
The half-life of source code, independent of the lifetime of the application it implements, is a separate topic.
Scientific software created to support researchers is an ecosystem whose incentives and means of production can be very different from commercial software. Does researcher oriented software die when the grant money runs out, or the researcher moves on to the next fashionable topic, or does it live on as the field expands?
The paper Scientific Open-Source Software Is Less Likely to Become Abandoned Than One Might Think! Lessons from Curating a Catalog of Maintained Scientific Software by Thakur, Milewicz, Jahanshahi, Paganini, Vasilescu, and Mockus analysed 14,418 scientific software systems written in Python (53%), C/C++ (25%), R (12%), Java (8%) or Fortran (2%). The first half of the paper describes how World of Code‘s 209 million repos were filtered down to 350,308 projects containing README files, these READMEs were processed by LLMs to extract information and further filter out projects.
The authors collected the usual information about each Open source project, e.g., number of core developers, number of commits, programming language, etc. They also collected information about the research domain, e.g., scientific field (biology, chemistry, mathematics, etc.), funding, academic/government associations, etc. A Cox proportional hazards model was fitted to this data, with project lifetime being the response variable. A project was deemed to have been abandoned when no changes had been made to the code for at least six consecutive months (we can argue over whether this is long enough).
Including all the different factors created a Cox model that did a good job of explaining the variance in project survival rate. No one factor dominated, and there was a lot of overlap in the confidence bounds of the components of each factor, e.g., different research domains. I have always said that programming language has no impact on project lifetime; the language factor of the fitted model was not statistically significant (two of the languages just sneaked in under the 5% bar), which can be interpreted as being consistent with my opinion.
Each project was categorised as one of: Scientific Domain-specific code (73.5%), Scientific infrastructure (16.5%), or Publication-Specific code (10%). The plot below shows the Kaplan-Meier survival curve for these three categories (note: y-axis is logarithmic), with faint grey lines showing a fitted exponential for each survival curve (only 3% of projects are abandoned in the first year, and the exponential fits are to the data after the first year; code+data):
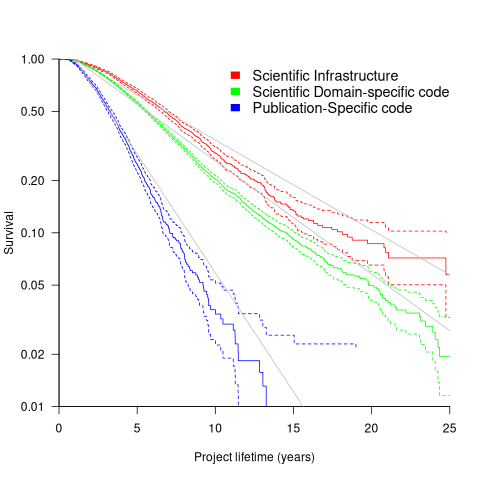
Readers familiar with academic publishing will not be surprised that projects associated with published papers have the lowest survival rate (half-life just over 2-years). Infrastructure projects are likely to be depended on by many people, who all have an interest in them surviving (half-life around 6-years). The Domain-specific half-life is around 4.5-years.
The results of this study show software systems in various research ecosystems having a range of half-lives in the same range as three major commercial software ecosystems.
Unfortunately, my experience of discussing application half-life with developers is that they believe in an imagined future where software never dies. That is, they are unwilling to consider a world where software has a high probability of being abandoned, because it requires that they consider the return on investment before spending time polishing their code.
A Wikihouse hackathon
I was at the Wikihouse hackathon on Wednesday. Wikihouse is an open-source project involving prefabricated house designs and building processes.
Why is a software guy attending what looks like a very non-software event? The event organizers listed software developer as one of the attendee skill sets. Also, I have been following the blog Construction Physics, where Brian Potter has been trying to work out why the efficiency of building construction has not significantly improved over many decades; the approach is wide-ranging, data driven and has parallels with my analysis of software engineering. I counted four software people at the event, out of 30’ish attendees; Sidd I knew from previous hacks.
Building construction shares some characteristics with software development. In particular, projects are bespoke, but constructed using subcomponents that are variations on those used in most other projects of the same kind of building, e.g., walls±window frames, floors/ceilings.
The Wikihouse design and build process is based around a collection of standardised, prefabricated subcomponents, called blocks; these are made from plywood, slotted together, and held in place using butterfly/bow-tie joints (wood has a negative carbon footprint). A library of blocks is available, with the page for each block including a DXF cutting file, assembly manual, 3-D model, and costing; there is a design kit for building a house, including a spreadsheet for costing, and a variety of How-Tos. All this is available under an open source license. The Open Systems Lab is implementing building design software and turning planning codes into code.
Not knowing anything about building construction, I have no way of judging the claims made during the hackathon introductory presentations, e.g., cost savings, speed of build, strength of building, expected lifetime, etc.
Constructing lots of buildings using Wikihouse blocks could produce an interesting dataset (provided those doing the construction take the time to record things). Questions such as: how does construction time vary by team composition (self-build is possible) and experience, and by number of rooms and their size spring to mind (no construction time/team data was recorded during the construction of the ‘beta test’ buildings).
The morning was taken up with what was essentially a product pitch, then we got shown around the ‘beta test’ buildings (they feel bigger on the inside), lunch and finally a few hours hacking. The help they wanted from software people was in connecting together some of the data/tools they had created, but with only a few hours available there was little that could be done (my input was some suggestions on construction learning curves and a few people/groups I knew doing construction data analysis)
Will an open source approach enable the Wikihouse project to succeed with its prefabricated approach to building construction, where closed source companies have failed when using this approach, e.g., Katerra?
Part of the reason that open source software succeeded was that it provided good enough functionality to startup projects/companies who could not afford to pay for software (in some cases the open source tools provided superior functionality). Some of these companies grew to be significant players, convincing others that open source was viable for production work. Source code availability allows developers to use it without needing to involve management, and plenty of managers have been surprised to find out how embedded open source software is within their group/organization.
Buildings are not like software, lots of people with some kind of power notice when a new building appears. Buildings need to be connected to services such as water, gas and electricity, and they have a rateable value which the local council is keen to collect. Land is needed to build on, and there are a whole host of permissions and certificates that need to be obtained before starting to build and eventually moving in. Doing it, and telling people later is not an option, at least in the UK.
Open source: the goody bag for software infrastructure
For 70 years there has been a continuing discovery of larger new ecosystems for new software to grow into, as well as many small ones. Before Open source became widely available, the software infrastructure (e.g., compilers, editors and libraries of algorithms) for these ecosystems had to be written by the pioneer developers who happened to find themselves in an unoccupied land.
Ecosystems may be hardware platforms (e.g., mainframes, minicomputers, microcomputers and mobile phones), software platforms (e.g., Microsoft Windows, and Android), or application domains (e.g., accounting and astronomy)
There are always a few developers building some infrastructure project out of interest, e.g., writing a compiler for their own or another language, or implementing an editor that suites them. When these projects are released, they have to compete against the established inhabitants of an ecosystem, along with other newly released software clamouring for attention.
New ecosystems have limited established software infrastructure, and may not yet have attracted many developers to work within them. In such ‘virgin’ ecosystems, something new and different faces less competition, giving it a higher probability of thriving and becoming established.
Building from scratch is time-consuming and expensive. Adapting existing software systems speeds things up and reduces costs; adaptation also has the benefit of significantly reducing the startup costs when recruiting developers, i.e., making it possible for experienced people to use the skills acquired while working in other ecosystems. By its general availability, Open source creates competition capable of reducing the likelihood that some newly created infrastructure software will become established in a ‘virgin’ ecosystem.
Open source not only reduces startup costs for those needing infrastructure for a new ecosystem, it also reduces ongoing maintenance costs (by spreading them over multiple ecosystems), and developer costs (by reducing the need to learn something different, which happened to be created by developers who built from scratch).
Some people will complain that Open source is reducing diversity (where diversity is viewed as unconditionally providing benefits). I would claim that reducing diversity in this case is a benefit. Inventing new ways of doing things based on the whims of those doing the invention is a vanity project. I have nothing against people investing their own resources on their own vanity projects, but let’s not pretend that the diversity generated by such projects is likely to provide benefits to others.
By providing the components needed to plug together a functioning infrastructure, Open source reduces the cost of ecosystem ‘invasion’ by software. The resources which might have been invested building infrastructure components can be directed to building higher level functionality.
OSI licenses: number and survival
There is a lot of source code available which is said to be open source. One definition of open source is software that has an associated open source license. Along with promoting open source, the Open Source Initiative (OSI) has a rigorous review process for open source licenses (so they say, I have no expertise in this area), and have become the major licensing brand in this area.
Analyzing the use of licenses in source files and packages has become a niche research topic. The majority of source files don’t contain any license information, and, depending on language, many packages don’t include a license either (see Understanding the Usage, Impact, and Adoption of Non-OSI Approved Licenses). There is some evolution in license usage, i.e., changes of license terms.
I knew that a fair-few open source licenses had been created, but how many, and how long have they been in use?
I don’t know of any other work in this area, and the fastest way to get lots of information on open source licenses was to scrape the brand leader’s licensing page, using the Wayback Machine to obtain historical data. Starting in mid-2007, the OSI licensing page kept to a fixed format, making automatic extraction possible (via an awk script); there were few pages archived for 2000, 2001, and 2002, and no pages available for 2003, 2004, or 2005 (if you have any OSI license lists for these years, please send me a copy).
What do I now know?
Over the years OSI have listed 110107 different open source licenses, and currently lists 81. The actual number of license names listed, since 2000, is 205; the ‘extra’ licenses are the result of naming differences, such as the use of dashes, inclusion of a bracketed acronym (or not), license vs License, etc.
Below is the Kaplan-Meier survival curve (with 95% confidence intervals) of licenses listed on the OSI licensing page (code+data):
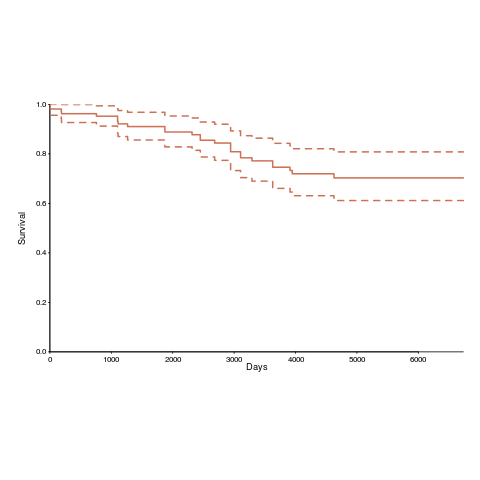
How many license proposals have been submitted for review, but not been approved by OSI?
Patrick Masson, from the OSI, kindly replied to my query on number of license submissions. OSI doesn’t maintain a count, and what counts as a submission might be difficult to determine (OSI recently changed the review process to give a definitive rejection; they have also started providing a monthly review status). If any reader is keen, there is an archive of mailing list discussions on license submissions; trawling these would make a good thesis project 🙂
Users of Open source software are either the product or are irrelevant
Users of software often believe that the people who produced it are interested in the views and opinions of their users.
In a commercial environment there are producers who are interested in what users have to say, because of the financial incentive, and some Open source software exists within this framework, e.g., companies selling support services for the code they have Open sourced.
Without a commercial framework why would any producer of Open source be interested in the views and opinions of users? Answers include:
- users are the product: I have met developers who are strongly motivated by the pleasure they get from being at the center of a community, i.e., the community of people using the software that they are actively involved in creating,
- users are irrelevant: other developers are more strongly motivated by the pleasure of building things and in particular building using what are considered to be the right tools and techniques, i.e., the good-enough approach is not considered to be good-enough.
How do these Open source dynamics play out in the evolution of software systems?
It is the business types who are user oriented or rather source of money oriented. They are the people who stop developers from upsetting customers by introducing incompatibilities with previous releases, in fact a lot of the time its the business types pushing developers to concentrate on fixing problems and not wasting time doing more interesting stuff.
Keeping existing customers happy often means that products change slowly and gradually ossify (unless the company involved has a dominant market position that forces users to take what they are given).
A project primarily fueled its developers’ desire for pleasure cannot stand still, it has to change. Users who complain that change has an impact on their immediate need for compatibility get told that today’s pain is necessary for a brighter future tomorrow.
An example of users as the product is gcc. Companies pay people to work on gcc because they want access to the huge amount of software written by ‘the product’ using gcc.
As example of users as irrelevant is llvm. Apple is paying for llvm to happen and what does this have to do with anybody else using it?
The users of Angular.js now know what camp they are in.
As Bob Dylan pointed out: “Just because you like my stuff doesn’t mean I owe you anything.”
undefined behavior: pay up or shut up
Academia recently discovered undefined behavior in C, twenty five years after industry tool vendors first started trying to help developers catch the problems it causes. Some of the tools that are now being written are doing stuff that we could only dream about back in the day.
The forces that morph occurrences of undefined behavior in source code to unwanted behavior during program execution have changed over the years.
- When developers paid for their compilers there was an incentive for compiler writers to try to be nice to developers by doing the right thing for undefined behaviors. Twenty five years ago there were lots of commercial compilers all having slightly different views about what the right thing might be; a lot of code was regularly ported to different compilers and got to encounter different compiler writer’s views.
- These days there is widespread use of open source compilers, which developers don’t pay for, removing the incentive for compilers writers to be nice to developers. Paying customers want support for new processors, enhancements to existing generated code quality and the sexy topic for PhDs is code optimization; what better climate for treating source containing undefined behavior as road kill. Now developers only need to upgrade to a later release of the compiler they are using to encounter an unexpected handling of undefined behavior.
A recent blog post, authored by some of the academics alluded to above, proposes adding a new option to gcc: -std=friendly-c. If developers feel that this kind of option needs to be supported then they should contribute to a crowdfunding campaign (none exists at the time of writing) to raise, say, $500,000 towards supporting the creation and ongoing support for the functionality behind this option. Of course one developer’s friendly is another developer’s unfriendly, so we could end up with multiple funds each promoting an option that supports a view of the world that is specific to one target environment.
At the moment, in response to user complaints, Open source compiler vendors lamely point out that the C standard permits them to handle source containing undefined behaviors the way they do; they stop short of telling people to quit complaining and that they are getting the compiler for free.
If this undefined behavior issue starts to gain substantial publicity, but insufficient funding, open source compiler vendors will need to start putting a positive spin on the decisions they make. Not being in marketing I might have a problem keeping a straight face when giving the following positive messages:
- We are helping to save the world: optimized programs use less power (ok, every now and again they can use more). Do you really want to stop us adding more optimizations just because you cannot find the time to fix a mistake in your code?
- We are helping your application gain market share. Applications that are not actively maintained are less and less likely to continue to work with every release of the compiler.
Heartbleed: Critical infrastructure open source needs government funding
Like most vulnerabilities the colorfully named Heartbleed vulnerability in OpenSSL is caused by an ‘obvious’ coding problem of the kind that has been occurring in practically all programs since homo sapiens first started writing software; the only thing remarkable about this vulnerability is its potential to generate huge amounts of financial damage. Some people might say that it is also remarkable that such a serious problem has not occurred in OpenSSL before, I don’t think anybody would describe OpenSSL as the most beautiful of code.
As always happens when a coding problem generates some publicity, there have been calls for:
- More/better training: Most faults are simple mistakes that developers already know all about; training does not stop people making mistakes.
- Switch to a better language: Several lifetimes could be spent discussing this one and a short coffee break would be enough to cover the inconclusive empirical evidence on ‘betterness’. Switching languages also implies rewriting lots of code and there is that annoying issue of newly written code being more likely to contain faults than code that has been heavily used for a long time.
The fact is that all software contains faults and the way to improve reliability is to actively search for and fix these faults. This will cost money and commercial companies have an incentive to spend money doing this; in whose interest is it to fix faults in open source tools such as OpenSSL? There are lots of organizations who would like these faults fixed, but getting money from these organizations to the people who could do the work is going to be complicated. The simple solution would be for some open source programs to be classified as critical infrastructure and have governments fund the active finding and fixing of the faults they contain.
Some people would claim that the solution is to rewrite the software to be more reliable. However, I suspect the economics will kill this proposal; apart from pathological cases it is invariably cheaper to fix what exists that start from scratch.
On behalf of the open source community can I ask that unless you have money to spend please go away and stop bothering us about these faults, we write this code for free because it is fun and fixing faults is boring.
Popularity of Open source Operating systems over time
Surveys of operating system usage trends are regularly published and we get to read about how the various Microsoft products are doing and the onward progress of mobile OSs; sometimes Linux gets an entry at the bottom of the list, sometimes it is just ‘others’ and sometimes it is both.
Operating systems are pervasive and a variety of groups actively track reported faults in order to issue warnings to the public; the volume of OS fault informations available makes it an obvious candidate for testing fault prediction models (e.g., how many faults will occur in a given period of time). A very interesting fault history analysis of OpenBSD in a paper by Ozment and Schechter recently caught my eye and I wondered if the fault time-line could be explained by the time-line of OpenBSD usage (e.g., more users more faults reported). While collecting OS usage information is not the primary goal for me I thought people would be interested in what I have found out and in particular to share the OS usage data I have managed to obtain.
How might operating system usage be measured? Analyzing web server logs is an obvious candidate method; when a web browser requests information many web servers write information about the request to a log file and this information sometimes includes the name of the operating system on which the browser is running.
Other sources of information include items sold (licenses in Microsoft’s case, CDs/DVD’s for Open source or perhaps books {but book sales tend not to be reported in the way programming language book sales are reported}) and job adverts.
For my time-line analysis I needed OpenBSD usage information between 1998 and 2005.
The best source of information I found, by far, of Open source OS usage derived from server logs (around 138 million Open source specific entries) is that provided by Distrowatch who count over 700 different distributions as far back as 2002. What is more Ladislav Bodnar the founder and executive editor of DistroWatch was happy to run a script I sent him to extract the count data I was interested in (I am not duplicating Distrowatch’s popularity lists here, just providing the 14 day totals for OS count data). Some analysis of this data below.
As luck would have it I recently read a paper by Diomidis Spinellis which had used server log data to estimate the adoption of Open Source within organizations. Diomidis researches Open source and was willing to run a script I wrote to extract the User Agent string from the 278 million records he had (unfortunately I cannot make this public because it might contain personal information such as email addresses, just the monthly totals for OS count data, tar file of all the scripts I used to process this raw log data; the script to try on your own logs is countos.sh).
My attempt to extract OS names from the list of User Agent strings Diomidis sent me (67% of of the original log entries did contain a User Agent string) provides some insight into the reliability of this approach to counting usage (getos.awk is the script to try on the strings extracted with the earlier script). There is no generally agreed standard for:
- what information should be present; 6% of UA strings contained no OS name that I knew (this excludes those entries that were obviously robots/crawlers/spiders/etc),
- the character string used to specify a given OS or a distribution; the only option is to match a known list of names (OS names used by Distrowatch,
missos.awkis the tar file script to print out any string not containing a specified list of OS names, the Wikipedia List of operating systems article), - quality assurance; some people cannot spell ‘windows’ correctly and even though the source is now available I don’t think anybody uses CP/M to access the web (at least 91 strings,
 %, would not have passed).
%, would not have passed).
Ladislav Bodnar thinks that log entries from the same IP addresses should only be counted once per day per OS name. I agree that this approach is much better than ignoring address information; why should a person who makes 10 accesses be counted 10 times, a person who makes one access is only counted once. It is possible that two or more separate machines running the same OS are accessing the Internet through a common gateway that results in them having the IP address from an external server’s point of view; this possibility means that the Distrowatch data undercounts the unique accesses (not a serious problem if most visitors have direct Internet access rather than through a corporate network).
The Distrowatch data includes counts for all IP address and from 13 May 2004 onwards unique IP address per day per OS. The mean ratio between these two values, summed over all OS counts within 14 day periods, is 1.9 (standard deviation 0.08) and the Pearson correlation coefficient between them is 0.987 (95% confidence interval is 0.984 to 0.990), i.e., almost perfect correlation.
The Spinellis data ignores IP address information (I got this dataset first, and have already spent too much time collecting to do more data extraction) and has 10 million UA strings containing Open source OS names (6% of all OS names matched).
How representative are the Distrowatch and Spinellis data? The data is as representative of the general OS population as the visitors recorded in the respective server logs are representative of OS usage. The plot below shows the percentage of visitors to Distrowatch that use Ubuntu, Suse, Redhat. Why does Redhat, a very large company in the Open source world, have such a low percentage compared to Ubuntu? I imagine because Redhat customers get their updates from Redhat and don’t see a need to visit sites such as Distrowatch; a similar argument can be applied to Suse. Perhaps the Distrowatch data underestimates those distributions that have well known websites and users who have no interest in other distributions. I have not done much analysis of the Spinellis data.
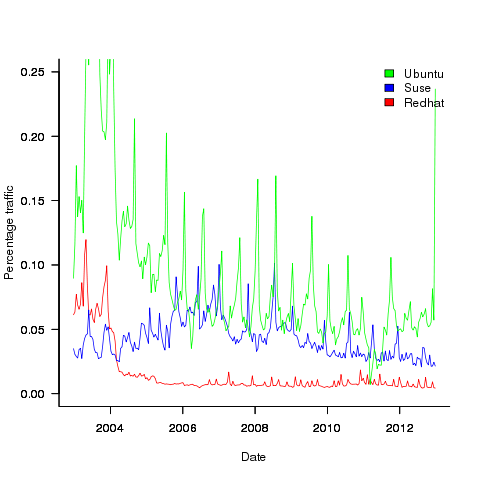
Presumably the spikes in usage occur around releases of new versions, I have not checked.
For my analysis I am interested in relative change over time, which means that representativeness and not knowing the absolute number of OSs in use is not a problem. Researchers interested in a representative sample or estimating the total number of OSs in use are going to need a wider selection of data; they might be interested in the following OS usage information I managed to find (yes I know about Netcraft, they charge money for detailed data and I have not checked what the Wayback Machine has on file):
- Wikimedia has OS count information back to 2009. Going forward this is a source of log data to rival Distrowatch’s, but the author of the scripts probably ought to update the list of OS names matched against,
- w3schools has good summary data for many months going back to 2003,
- statcounter has good summary data (daily, weekly, monthly) going back to 2008,
- TheCounter.com had data from 2000 to 2009 (csv file containing counts obtained from Wayback Machine).
If any reader has or knows anybody who has detailed OS usage data please consider sharing it with everybody.
Only compiler vendor customers, not its users, count
The hardest thing about working on compilers is getting somebody to pay you to do it (its a close run race against having the cpu instructions chop and change under you during initial development, but that’s another story). The major shift of compiler vendor business model from proprietary to open source has significant implications for users of compilers. Note I said user not customer, only one of them pays money. Under the commercial model there was usually a very direct connection between compiler user and customer (even in large organizations users rather than the manager who makes the purchase decision are often regarded by vendors as the customer), while under the Open source model most users are not customers (paying money for a distribution does not make you a customer of the people maintaining the compiler who probably don’t receive any of the money you spent).
Like all good businesses compiler vendors don’t want to make their customers unhappy. There is one way guaranteed to make all customers so unhappy that they will remember the experience for years; ship a new compiler release that breaks their existing code (this usually happens because their is a previously undetected bug in the code or because use is being made of an implemented defined/undefined part of the language {the compiler gets to decide what to do when it encounters such code}). Not breaking existing customer code is priority ONE in any commercial compiler development group.
Proprietary vendors have so many customers its almost impossible for them to know in advance what changes will break existing code and the only option is to be ultra conservative about adding new code optimizations (new optimizations can so easily change how source containing undefined behavior is processed). Ultra conservative is the polite term, management paranoia would be more accurate. There is another advantage to vendors for not breaking their customers’ code, they are protected against competition by new market entrants; a new vendor with a shiny go faster compiler doing all the optimizations the existing vendor was not willing to do in case it broke existing code will quickly find out that the performance improvements they offer are rarely big enough to tempt potential customers to switch compilers. Really, the only time companies switch compiler is when they have to port to a new platform to make a sale or their existing vendor goes bust.
Open source vendors (e.g., those commercially involved in support/maintenance of gcc or llvm) have relatively few customers (e.g., big companies paying them lots of money for specific reasons) and as always these customers want existing code to continue to work. If the customer is paying for a code generator for a previously unsupported processor then there probably isn’t any existing code for that processor; it is a fact of life that porting source to a new processor always involves work. Some Linux distributors (e.g., Suse and Redhat) are customers in the sense that they pay the salary of developers who spend a lot of their time in compiler maintenance/upgrades and presumably work to try and ensure that the code in their respective Linux distributions does not get broken.
Compiler users who are not customers don’t count on the code breakage front (well, count for very very little, if an update broke lots of different developers’ code and enough fuss was made there might well be an update than unbroke the previous one).
What can a user do if code that used to work ok is broken when compiled with a later version of the compiler? The obvious answer is to continue using the older version that produces the desired behavior, fixing the code causing the problem is a better answer (but might involve a lot of work). There is no point in flaming the compiler developers, you are not contributing towards their upkeep; Open source does not give users the consideration that a customer enjoys.
Recent Comments