Archive
Survival rate of WG21 meeting attendance
WG21, the C++ Standards committee, has a very active membership, with lots of people attending the regular meetings; there are three or four meetings a year, with an average meeting attendance of 67 (between 2004 and 2016).
The minutes of WG21 meetings list those who attend, and a while ago I downloaded these for meetings between 2004 and 2016. Last night I scraped the data and cleaned it up (or at least the attendee names).
WG21 had its first meeting in 1992, and continues to have meetings (eleven physical meetings at the time or writing). This means the data is both left and right censored; known as interval censored. Some people will have attended many meetings before the scraped data starts, and some people listed in the data may not have attended another meeting since.
What can we say about the survival rate of a person being a WG21 attendee in the future, e.g., what is the probability they will attend another meeting?
Most regular attendees are likely to miss a meeting every now and again (six people attended all 30 meetings in the dataset, with 22 attending more than 25), and I assumed that anybody who attended a meeting after 1 January 2015 was still attending. Various techniques are available to estimate the likelihood that known attendees were attending meetings prior to those in the dataset (I’m going with what ever R’s survival package does). The default behavior of R’s Surv function is to handle right censoring, the common case. Extra arguments are needed to handle interval censored data, and I think I got these right (I had to cast a logical argument to numeric for some reason; see code+data).
The survival curves in days since 1 Jan 2004, and meetings based on the first meeting in 2004, with 95% confidence bounds, look like this:
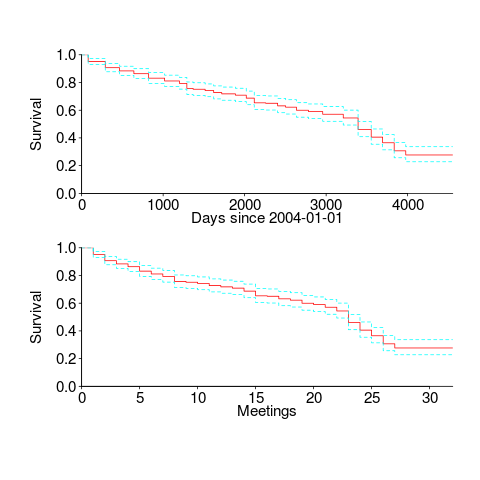
I was expecting a sharper initial reduction, and perhaps wider confidence bounds. Of the 374 people listed as attending a meeting, 177 (47%) only appear once and 36 (10%) appear twice; there is a long tail, with 1.6% appearing at every meeting. But what do I know, my experience of interval censored data is rather limited.
The half-life of attendance is 9 to 10 years, suspiciously close to the interval of the data. Perhaps a reader will scrape the minutes from earlier meetings 🙂
Within the time interval of the data, new revisions of the C++ standard occurred in 20072011 and 2014; there had also been a new release in 2003, and one was being worked on for 2017. I know some people stop attending meetings after a major milestone, such as a new standard being published. A fancier analysis would investigate the impact of standards being published on meeting attendance.
People also change jobs. Do WG21 attendees change jobs to ones that also require/allow them to attend WG21 meetings? The attendee’s company is often listed in the minutes (and is in the data). Something for intrepid readers to investigate.
C Standard meeting, April-May 2019
I was at the ISO C language committee meeting, WG14, in London this week (apart from the few hours on Friday morning, which was scheduled to be only slightly longer than my commute to the meeting would have been).
It has been three years since the committee last met in London (the meeting was planned for Germany, but there was a hosting issue, and Germany are hosting next year), and around 20 people attended, plus 2-5 people dialing in. Some regular attendees were not in the room because of schedule conflicts; nine of those present were in London three years ago, and I had met three of those present (this week) at WG14 meetings prior to the last London meeting. I had thought that Fred Tydeman was the longest serving member in the room, but talking to Fred I found out that I was involved a few years earlier than him (our convenor is also a long-time member); Fred has attended more meeting than me, since I stopped being a regular attender 10 years ago. Tom Plum, who dialed in, has been a member from the beginning, and Larry Jones, who dialed in, predates me. There are still original committee members active on the WG14 mailing list.
Having so many relatively new meeting attendees is a good thing, in that they are likely to be keen and willing to do things; it’s also a bad thing for exactly the same reason (i.e., if it not really broken, don’t fix it).
The bulk of committee time was spent discussing the proposals contains in papers that have been submitted (listed in the agenda). The C Standard is currently being revised, WG14 are working to produce C2X. If a person wants the next version of the C Standard to support particular functionality, then they have to submit a paper specifying the desired functionality; for any proposal to have any chance of success, the interested parties need to turn up at multiple meetings, and argue for it.
There were three common patterns in the proposals discussed (none of these patterns are unique to the London meeting):
- change existing wording, based on the idea that the change will stop compilers generating code that the person making the proposal considers to be undesirable behavior. Some proposals fitting this pattern were for niche uses, with alternative solutions available. If developers don’t have the funding needed to influence the behavior of open source compilers, submitting a proposal to WG14 offers a low cost route. Unless the proposal is a compelling use case, affecting lots of developers, WG14’s incentive is to not adopt the proposal (accepting too many proposals will only encourage trolls),
- change/add wording to be compatible with C++. There are cost advantages, for vendors who have to support C and C++ products, to having the two language be as mutually consistent as possible. Embedded systems are a major market for C, but this market is not nearly as large for C++ (because of the much larger overhead required to support C++). I pointed out that WG14 needs to be careful about alienating a significant user base, by slavishly following C++; the C language needs to maintain a separate identity, for long term survival,
- add a new function to the C library, based on its existence in another standard. Why add new functions to the C library? In the case of math functions, it’s to increase the likelihood that the implementation will be correct (maths functions often have dark corners that are difficult to get right), and for string functions it’s the hope that compilers will do magic to turn a function call directly into inline code. The alternative argument is not to add any new functions, because the common cases are already covered, and everything else is niche usage.
At the 2016 London meeting Peter Sewell gave a presentation on the Cerberus group’s work on a formal definition of C; this work has resulted in various papers questioning the interpretation of wording in the standard, i.e., possible ambiguities or inconsistencies. At this meeting the submitted papers focused on pointer provenance, and I was expecting to hear about the fancy optimizations this work would enable (which would be a major selling point of any proposal). No such luck, the aim of the work was stated as clearly specifying the behavior (a worthwhile aim), with no major new optimizations being claimed (formal methods researchers often oversell their claims, Peter is at the opposite end of the spectrum and could do with an injection of some positive advertising). Clarifying behavior is a worthwhile aim, but not at the cost of major changes to existing wording. I have had plenty of experience of asking WG14 for clarification of existing (what I thought to be ambiguous) wording, only to be told that the existing wording was clear and not ambiguous (to those reviewing my proposed defect). I wonder how many of the wording ambiguities that the Cerberus group claim to have found would be accepted by WG14 as a defect that required a wording change?
Winner of the best pub quiz question: Does the C Standard require an implementation to be able to exactly represent floating-point zero? No, but it is now required in C2X. Do any existing conforming implementations not support an exact representation for floating-point zero? There are processors that use a logarithmic representation for floating-point, but I don’t know if any conforming implementation exists for such systems; all implementations I know of support an exact representation for floating-point zero. Logarithmic representation could handle zero using a special bit pattern, with cpu instructions doing the right thing when operating on this bit pattern, e.g., 0.0+X == X, (I wonder how much code would break, if the compiler mapped the literal 0.0 to the representable value nearest to zero).
Winner of the best good intentions corrupted by the real world: intmax_t, an integer type capable of representing any value of any signed integer type (i.e., a largest representable integer type). The concept of a unique largest has issues in a world that embraces diversity.
Today’s C development environment is very different from 25 years ago, let alone 40 years ago. The number of compilers in active use has decreased by almost two orders of magnitude, the number of commonly encountered distinct processors has shrunk, the number of very distinct operating systems has shrunk. While it is not a monoculture, things appear to be heading in that direction.
The relevance of WG14 decreases, as the number of independent C compilers, in widespread use, decreases.
What is the purpose of a C Standard in today’s world? If it were not already a standard, I don’t think a committee would be set up to standardize the language today.
Is the role of WG14 now, the arbiter of useful common practice across widely used compilers? Documenting decisions in revisions of the C Standard.
Work on the Cobol Standard ran for almost 60-years; WG14 has to be active for another 20-years to equal this.
Gentleman scientists in software engineering
The Royal Society was formed in 1660 as a “College for the Promoting of Physico-Mathematical Experimental Learning”. A lot of very important research was done by members of this society, who were independently wealthy or held a university post.
For a while now, I have thought that the only way software engineering is going to advance to become a real engineering/scientific discipline is via gentleman scientists (unless industry really does need more clueless button pushers).
I was talking at the LondonR meeting on Tuesday (slides) and got chatting with familiar faces from hackathons. It seems that they had also had ideas for researching particular problems in software engineering, and liked the idea of a group of Gentleman scientists.
The problem we have is that none of us wants to do the organizing (a common problem). We must be able to do better than meeting in a pub.
I think the main qualifications for being a member of the group of Gentleman scientists for the “Promoting of Software Experimental Learning” would be something like:
- enjoying the pleasure of gaining knowledge about how the world works, i.e., no flights of fancy,
- interested in finding answers to questions whose answers are not yet known, i.e., doing real research, not personal learning,
- have the funds to support what you do, i.e., you want funding, you find it,
- being proficient in a necessary skill, i.e., you cannot be a beginner in all the required skills.
If the Danish Gentlemen scientists can send rockets into space, I’m sure the inhabitants of London and surrounds (no nationality restrictions here) can make major discoveries in software engineering (nobody has really found any yet, they are all waiting to be found).
Doing software research is not expensive, in monetary terms. It requires that those involved know something about real-life software issues and have the time and inclination to research possible solutions. People in industry are ideally placed to do the research. There are academic research groups doing interesting work in this area (they are in the minority). There are no groups we could join that are within easy traveling distance of London’ish based people (I would claim none in the UK).
The rationale for having a group of like-minded people meeting together include: it provides a structure and focus, sharing ideas is interesting and helps refine them, it’s an enjoyable night out, and a network is good for sharing/finding resources.
What might be the outputs of this group/network/society/asylum? Blog posts, talks, reports, books: the intent is to produce stuff that practicing software developers will find useful.
When the Royal Society started, Latin was the language of scholars. It’s motto ‘Nullius in verba’ catches the sentiment, but ‘take nobody’s word for it’ does not sound catchy. Something to work on.
I will keep readers posted on any progress (e.g., finding a venue and organizing a night). If any readers knows of an existing group like this, please let me know (not looking to build an empire).
Recent Comments