Archive
Source code has a brief and lonely existence
The majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person (i.e., 60%).
Literate programming is all well and good for code written to appear in a book that the author hopes will be read for many years, but this is a tiny sliver of the source code ecosystem. The majority of code is never modified, once written, and does not hang around for very long; an investment is source code futures will make a loss unless the returns are spectacular.
What evidence do I have for these claims?
There is lots of evidence for the code having a short lifespan, and not so much for the number of people modifying it (and none for the number of people reading it).
The lifespan evidence is derived from data in my evidence-based software engineering book, and blog posts on software system lifespans, and survival times of Linux distributions. Lifespan in short because Packages are updated, and third-parties change/delete APIs (things may settle down in the future).
People who think source code has a long lifespan are suffering from survivorship bias, i.e., there are a small percentage of programs that are actively used for many years.
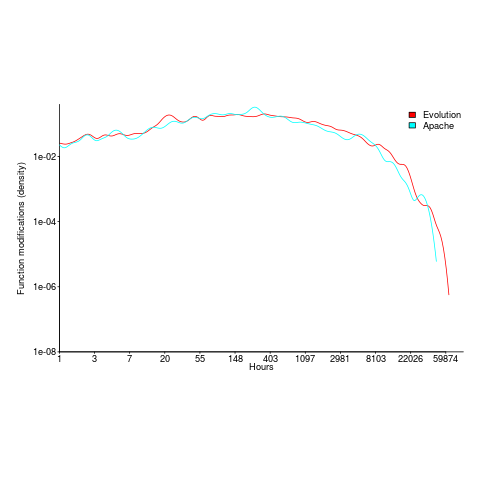
Around 60% of functions are only ever modified by one author; based on a study of the change history of functions in Evolution (114,485 changes to functions over 10 years), and Apache (14,072 changes over 12 years); a study investigating the number of people modifying files in Eclipse. Pointers to other studies that have welcome.
One consequence of the short life expectancy of source code is that, any investment made with the expectation of saving on future maintenance costs needs to return many multiples of the original investment. When many programs don’t live long enough to be maintained, those with a long lifespan have to pay the original investments made in all the source that quickly disappeared.
One benefit of short life expectancy is that most coding mistakes don’t live long enough to trigger a fault experience; the code containing the mistake is deleted or replaced before anybody notices the mistake.
Update: a few days later
I was remiss in not posting some plots for people to look at (code+data).
The plot below shows number of function, in Evolution, modified a given number of times (left), and functions modified by a given number of authors (right). The lines are a bi-exponential fit.

What is the interval (in hours) between between modifications of a function? The plot below has a logarithmic x-axis, and is sort-of flat over most of the range (you need to squint a bit). This is roughly saying that the probability of modification in hours 1-3 is the same as in hours 3-7, and hours, 7-15, etc (i.e., keep doubling the hour interval). At round 10,000 hours function modification probability drops like a stone.
Recent Comments