Archive
CPU power consumption and bit-similarity of input
Changing the state of a digital circuit (i.e., changing its value from zero to one, or from one to zero) requires more electrical power than leaving its state unchanged. During program execution, the power consumed by each instruction depends on the value of its operand(s). The plot below, from an earlier post, shows how the power consumed by an 8-bit multiply instruction varies with the values of its two operands:
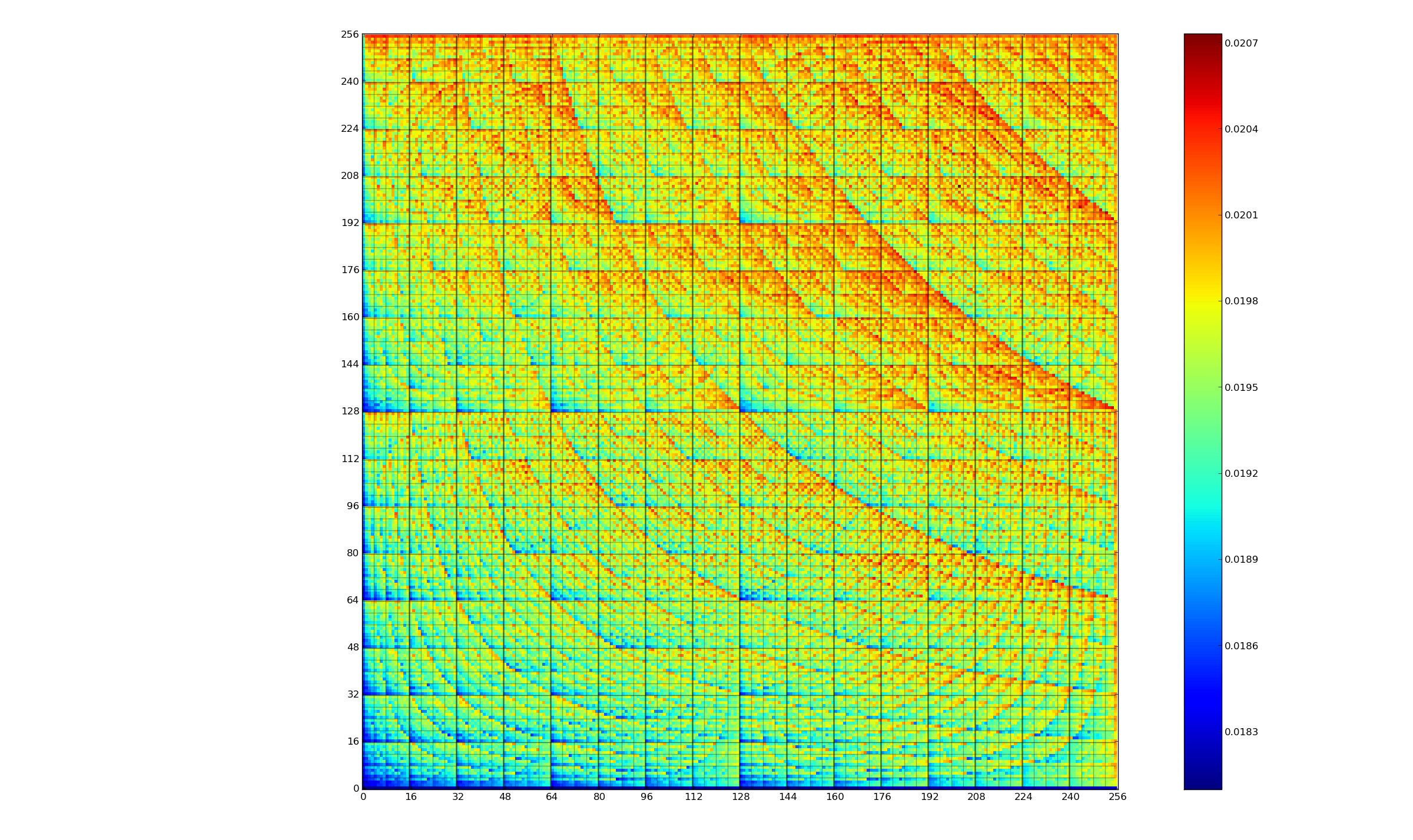
An increase in cpu power consumption produces an increase in its temperature. If the temperature gets too high, the cpu’s DVFS (dynamic voltage and frequency scaling) will slow down the processor to prevent it overheating.
When a calculation involves a huge number of values (e.g., an LLM size matrix multiply), how large an impact is variability of input values likely to have on the power consumed?
The 2022 paper: Understanding the Impact of Input Entropy on FPU, CPU, and GPU Power by S. Bhalachandra, B. Austin, S. Williams, and N. J. Wright, compared matrix multiple power consumption when all elements of the matrices had the same values (i.e., minimum entropy) and when all elements had different random values (i.e., maximum entropy).
The plot below shows the power consumed by an NVIDIA A100 Ampere GPU while multiplying two 16,384 by 16,384 matrices (performed 100 times). The GPU was power limited to 400W, so the random value performance was lower at 18.6 TFLOP/s, against 19.4 TFLOP/s for same values; (I don’t know why the startup times differ; code+data):
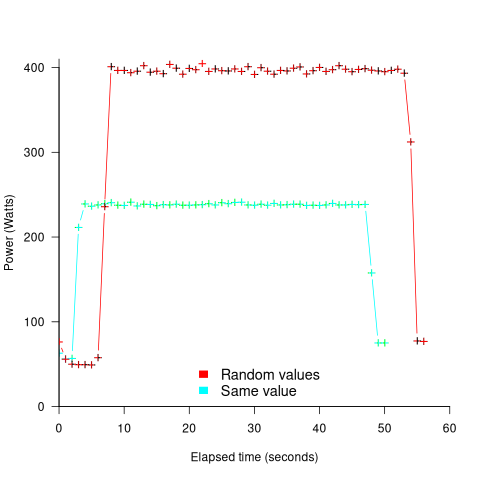
This 67% performance difference is more than an interesting factoid. Large computations are distributed over multiple GPUs, and the output from each GPU is sometimes feed as input to other GPUs. The flow of computations around a cluster of GPUs needs to be synchronised, and having compute time depend on the distribution of the input values makes life complicated.
Is it possible to organise a sequence of calculation to reduce the average power consumed?
The higher order bits of small integers are zero, but how many long calculations involve small integers? The bit pattern of floating-point values are more difficult to predict, but I’m sure there is a PhD thesis or two waiting to be written around this issue.
Comparing developer/LLM coding performance
Lots of claims are being made about how LLMs will soon outperform developers on coding tasks. Given the lack of any effective measure of developer performance, these claims are meaningless. At some point, lower costs will entice management to accept good enough LLM performance as a replacement for human developers, i.e., LLM don’t need to be technically better than developers.
The outperform claims are, currently, marketing puff, and I was not expecting anybody to make a serious attempt to compare developer/LLM performance. However, concerns about AI exceeding human capacity to control it (and maybe wiping out humans) has resulted in some well funded AI safety research groups. There is at least one group actively recruiting developers to “… establish human performance baselines on tasks related to software engineering, machine learning, and cybersecurity …”.
The most talked about AI threat scenarios all seem to start with recursive self-improvement, i.e., LLMs training themselves, exponentially improving with each iteration (the implied exponential always seems to be continuously up, rather than getting exponentially closer to a maximum).
Can current LLMs improve themselves faster than a developer can?
Implementing a new LLM is beyond the ability of today’s LLM, but they can implement some of the components used to build an LLM. How does LLM performance compare against developers, on the implementation of these components?
The paper RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts from METR (Model Evaluation & Threat Research) comes with code and “… anonymized human expert data coming soon.” for seven tasks. The baseline was derived from the performance of 61 human experts.
I’m always pleased to see researchers doing experiments with developers. I wish there were more groups doing this kind of thing.
However, I think that these researchers have made the common mistake of using very complicated subject tasks in their experiment. Most software development tasks are mundane, with the occasional complicated task (which can often be solved by using an appropriate package/library). The tasks may be representative of the harder tasks that need to be done, but they are not representative of the complete LLM implementation scenario.
A consequence of using complicated tasks is that most subjects only had enough time to complete one task (they were given 8 hours). With so few tasks (seven) the confidence intervals are going to be very wide on any general statement about human/LLM performance. With around ten subjects per task, the individual task confidence intervals are also going to be wide.
Task 7 made me laugh: “… that generates solutions to CodeContests problems in Rust, …”
Why Rust? Did they happen to have access to lots of Rust experts, or does the research group contain enthusiastic fans of Rust? I suspect the latter. There is a certain kind of highly intelligent developer who strongly believes that writing programs in a particular language imbues the code with magical properties (their rationale won’t be worded that way). For the last few years, Rust has been one of these pixie dust languages. Many decades ago, C had this charisma.
Perhaps each generation of ever more ‘intelligent’ LLMs will choose to design a new language to use to implement their ‘successor’.
There are a myriad of tasks related to software engineering. Solving GitHub issues is a thankless task, and having LLMs reliably close open issues would be of enormous benefit. A study published two months ago obtained a 1.96% solution rate (no explicit testing of developers).
Changing development culture and practices: LLM edition
The popular perception of creating software systems is that it mainly involves writing code. In the 1950s, management treated writing code as a clerical task that just mapped the detailed requirements specified by someone with knowledge of the problem to something a computer could execute. Job titles reflected this division of labour, e.g., coder/programmer, systems analyst (the Wikipedia entry lists implementation as part of the job, this eventually became true in theory and for many was probably true in practice since the early days).
Using Large Language Models to write code based on the requirements contained in a prompt appears to take software development back to the process mandated by the managers of early software projects.
A major economic incentive for the creation of software systems is enabling more efficient work processes, with the collateral damage of decimated employment in some work functions. This happened to clerical workers and non-software engineering workers. Now it’s happening to software developers.
Hardware designers did not cease to exist once Computer-aided design became available. Technical drawing skills (larger schools once had a room full of drawing boards for teaching young teenagers) has ceased to be a job requirement (image from Wikipedia).

Software developer will remain as a job category, perhaps with reduced numbers or with reduced average pay. But the use of LLMs will change the culture and practices of software development.
The shift from using assembly language to high level languages suggests a few ideas about the kinds of changes. Using assembly language requires being reasonably familiar with the cpu architecture, e.g., register names/widths/instruction-restrictions and instruction timings. General developer chat about cpu architectures was still a thing in the 1980s, less so in the 1990s, and very rarely today (people do blog about it). Several decades from now, what will no longer be a general topic of developer conversation? Data types, perhaps; like registers, bit pattern representation is a low level detail. Since most developers don’t know much about the languages they use, it may be difficult to measure the impact of LLM usage on language knowledge.
High-level languages increase developer productivity by reducing the number of details that need to be thought about, at the cost of less efficient code. But for many applications, machine time is cheaper than human time.
LLMs increase developer productivity by reducing the need to lookup details (e.g., spelling of method names and their parameters). As confidence grows in the accuracy of LLM suggested code, developers will start accepting, whatever. What counts is whether the code works, not whether the average developer would have written something faster/smaller/idiomatic.
The early languages have a straightforward mapping from statements/declarations to machine code. Over time, languages were created that allowed developers to think less and less about implementation details, at the cost of supporting constructs that could introduce lots of hidden overhead. I expect that customer demand will incentivize LLM functionality that reduces what developers need to think about.
A real danger of LLM usage is that it will, eventually, result in programs a lot more bloated than humans have managed to achieve. There are physical constraints restricting what hardware designers can do, and these constraints show up in patterns of behavior, e.g., Rent’s rule relating the number of external connections in a logic block to the number of logic gates in the block. There are common usage patterns in existing code, but no theory suggesting they are desirable, or not, in any sense. I await having enough LLM generated production code to make statistically significant measurements.
I suspect that these days most developers are writing glue code, or short programs, and in the near term I expect that most LLM code will fill this need. Unfortunately, there is very little research/measurement on glue code/short program, so there are no known developer usage patterns to compare LLMs against.
My 2024 in software engineering
Readers are unlikely to have noticed something that has not been happening during the last few years. The plot below shows, by year of publication, the number of papers cited (green) and datasets used (red) in my 2020 book Evidence-Based Software Engineering. The fitted red regression lines suggest that the 20s were going to be a period of abundant software engineering data; this has not (yet?) happened (the blue line is a local regression fit, i.e., loess). In 2020 COVID struck, and towards the end of 2022 Large Language Models appeared and sucked up all the attention in the software research ecosystem, and there is lots of funding; data gathering now looks worse than boring (code+data):
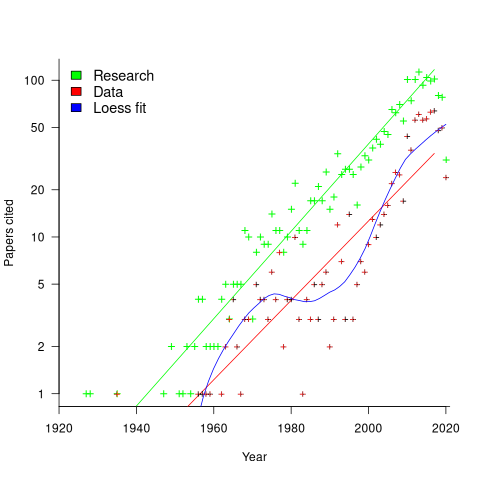
LLMs are showing great potential as research tools, but researchers are still playing with them in the sandpit.
How many AI startups are there in London? I thought maybe one/two hundred. A recruiter specializing in AI staffing told me that he would estimate around four hundred; this was around the middle of the year.
What did I learn/discover about software engineering this year?
Regular readers may have noticed a more than usual number of posts discussing papers/reports from the 1960s, 1970s and early 1980s. There is a night and day difference between software engineering papers from this start-up period and post mid-1980s papers. The start-up period papers address industry problems using sophisticated mathematical techniques, while post mid-1980s papers pay lip service to industrial interests, decorating papers with marketing speak, such as maintainability, readability, etc. Mathematical orgasms via the study of algorithms could be said to be the focus of post mid-1980s researchers. So-called software engineering departments ought to be renamed as Algorithms department.
Greg Wilson thinks that the shift happened in the 1980s because this was the decade during which the first generation of ‘trained in software’ people (i.e., emphasis on mathematics and abstract ideas) became influential academics. Prior generations had received a practical training in physics/engineering, and been taught the skills and problem-solving skills that those disciplines had refined over centuries.
My research is a continuation of the search for answers to the same industrial problems addressed by the start-up researchers.
In the second half of the year I discovered the mathematical abilities of LLMs, and started using them to work through the equations for various models I had in mind. Sometimes the final model turned out to be trivial, but at least going through the process cleared away the complications in my mind. According to reports, OpenAI’s next, as yet unreleased, model has super-power maths abilities. It will still need a human to specify the equations to solve, so I am not expecting to have nothing to blog about.
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other:
Small business programs: A dataset in the research void
Putnam’s software equation debunked (the book is non-committal).
if statement conditions, some basic measurements
Number of statement sequences possible using N if-statements; perhaps.
A new NASA software dataset from the 1970s
A surprising retrospective task estimation dataset
Average lines added/deleted by commits across languages
Census of general purpose computers installed in the 1960s
Some information on story point estimates for 16 projects
Agile and Waterfall as community norms
Median system cpu clock frequency over last 15 years
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
C compiler conformance testing: with ChatGPT assistance
How can developers check that a compiler correctly implements all the behavior requirements contained in the corresponding language specification?
An obvious approach is to write lots of test cases for each distinct behavior; such a collection of tests is known as a validation suite, when used by a standard’s organization to test compilers/OS interfaces/etc. The extent to which a compiler’s behavior, when fed these tests, matches that listed in the language specification is a measure of its conformance.
In a world of many compilers with significant differences in behavior (i.e., pre-Open source), it makes economic sense for governments to sponsor the creation of validation suites, and/or companies to offer such suites commercially (mainly for C and C++). The spread of Open source compilers decimated compiler diversity, and compiler validation is fading into history.
New features continue to be added to Cobol, Fortran, C, and C++ by their respective ISO Standard’s committee. If governments are no longer funding updates to validation suites and the cost of commercial suites is too high for non-vendors (my experience is that compiler vendors find them to be cost-effective), how can developers check that a compiler conforms to the behavior specified by the Standard?
How much effort is required to create some minimal set of compiler conformance tests?
C is the language whose requirements I am most familiar with. The C Standard specifies that a conforming compiler issue a diagnostic for a violation of a requirement appearing in a Constraint clause, e.g., “For addition, either both operands shall have arithmetic type, or …”
There are 80 such clauses, containing around 530 non-blank lines, in N3301, the June 2024 draft. Let’s say 300+ distinct requirements, requiring a minimum of one test each. Somebody very familiar with the C Standard might take, say, 10 minutes per test, which is 3,000 minutes, or 50 hours, or 6.7 days; somebody slightly less familiar might take, say, at least an hour, which is 300+ hours, or 40+ days.
Lots of developers are using LLMs to generate source code from a description of what is needed. Given Constraint requirements in the C Standard, can an LLM generate tests that do a good enough job checking a compiler’s conformance to the C Standard?
Simply feeding the 157 pages from the Language chapter of the C Standard into an LLM, and asking it to generate tests for each Constraint requirement does not seem practical with the current state of the art; I’m happy to be proved wrong. A more focused approach might produce the desired tests.
Negative tests are likely to be the most challenging for an LLM to generate, because most publicly available source deals with positive cases, i.e., it is syntactically/semantically correct. The wording of Constraints sometimes specifies what usage is not permitted (e.g., clause 6.4.5.3 “A floating suffix df, dd, dl, DF, DD, or DL shall not be used in a hexadecimal floating literal.”), other times specifies what usage is permitted (e.g., clause 6.5.3.4 “The first operand of the . operator shall have an atomic, qualified, or unqualified structure or union type, and the second operand shall name a member of that type.”), or simply specifies a requirement (e.g., clause 6.7.3.2 “A member declaration that does not declare an anonymous structure or anonymous union shall contain a member declarator list.”).
I took the text from the 80 Constraint clauses, removed footnote numbers and rejoined words split at line-breaks. The plan was to prefix the text of each Constraint with instructions on the code requires. After some experimentation, the instructions I settled on were:
Write a sequence of very short programs which tests that a C compiler correctly flags each violation of the requirements contained in the following excerpt from the latest draft of the C Standard: |
Initially, excerpt was incorrectly spelled as except, but this did not seem to have any effect. Perhaps this misspelling is sufficiently common in the training data, that LLM weights support the intended association.
Experiments using Grok and ChatGPT 4o showed that both generated technically correct tests, but Grok generated code that was intended to be run (and was verbose), while the ChatGPT 4o output was brief and to the point; it did such a good job that I did not try any other LLMs. For this extended test, use of the web interface proved to be an effective approach. Interfacing via the API is probably more practical for larger numbers of requirements.
After some experimentation, I submitted the text from 31 Constraint clauses (I picked the non-trivial ones). The complete text of the questions and ChatGPT 4o responses (text files).
ChatGPT sometimes did not generate tests for all the requirements, when these were presented as they appeared in the Constraint, but did generate tests when the containing sentence was presented in isolation from other requirement sentences. For instance, the following sentence from clause 6.5.5 Cast Operators:
Conversions that involve pointers, other than where permitted by the constraints of 6.5.17.2, shall be specified by means of an explicit cast. |
was ignored when included as part of the complete Constraint, but when presented in isolation, reasonable tests were generated.
The responses never contained more than 10 test cases. I am guessing that this is the result of limits on response cpu time/length. Dividing the text of longer Constraints should solve this issue.
Some assumptions made by ChatGPT 4o about the implementation can be deduced from its responses, e.g., it appears to treat the type short as containing fewer than 32-bits (it assumes that a bit-field defined as a short containing 32-bits will be treated as a Constraint violation). This is not surprising, given the volume of public C source targeting the Intel x86.
I was impressed by the quality of the 242 test cases generated by ChatGPT 4o, which often included multiple tests for the same requirement (text files).
While it sometimes failed to produce a test for a requirement, I did not spot any incorrect tests (as in, not correctly testing for a violation of a listed requirement); the subset of tests feed through behaved as claimed), and I eventually found a prompt that appears to be creating a downloadable zip file of all the tests (most prompts resulted in a zip file containing some collection of 10 tests); the creation process is currently waiting for available cpu time. I now know that downloading a zip file containing one file per test, after each user prompt, is the more reliable option.
Number of statement sequences possible using N if-statements
I recently read a post by Terence Tao describing how he experimented with using ChatGPT to solve a challenging mathematical problem. A few of my posts contain mathematical problems I could not solve; I assumed that solving them was beyond my maths pay grade. Perhaps ChatGPT could help me solve some of them.
To my surprise, a solution was found to the first problem I tried.
I simplified the original problem (involving Motzkin numbers, details below) down to something that was easier for me to explain to ChatGPT. Based on ChatGPT’s response, it appeared lost, so I asked what it knew about Motzkin numbers. I then reframed the question around the concepts in its response, and got a response that, while reasonable, was not a solution. My question was not precise enough, and a couple of question/answer iterations later, ChatGPT broke the problem down into a series of steps that I saw could solve the problem. While the equation it used in its answer was just wrong, I knew what the correct equation was. So while ChatGPT frequently went off in the wrong direction and got its maths wrong, it helped me refine my statement of the problem and ChatGPT eventually gave steps to a solution which were blindingly obvious to me when I read them.
The question I wanted to answer was: How many distinct statement sequences can be created using 
if-statements and  simple-statements (for a total of
simple-statements (for a total of  statements)?
statements)?
A simple-statement might be an assignment or function call, but not any kind of compound statement, such as a loop. Three sequences are possible using one if-statement and two simple-statements. The if-statement occupies two lines, i.e., the condition and termination curly-bracket, }, as follows:
s1; if (c1) { if (c1) { if (c1) { s1; s1; s2; s2; } } } s2; |
In a previous post I showed how a variant of this question, involving any number of if-statements, can be mapped to a combinatorial interpretation of Motzkin numbers and treating matching up/down diagonals along a path as an if-statement.

ChatGPT performed poorly when I phrased the problem in combinatorial terms (or perhaps my phrasing was poor), so I switched to using a lattice path approach. I asked: “How many lattice paths of length S containing exactly N occurrences of the step (1, 1) and N occurrences of the step (1, -1) are possible?”, and after reading the response I replied “Your analysis does not take into account the fact that the path cannot go below the x-axis. Rework your analysis to take this restriction into account.”
The following is my edited version of ChatGPT’s ‘solution’ response:
“Problem Restated:
We need to count the number of valid Dyck paths of length , where the path consists of:
Exactly upward steps (1,1).
Exactly downward steps (1,−1).
The remaining steps (which must be horizontal steps (1,0)).
These paths must never dip below the x-axis, and they must return to the x-axis at the end.
…
Step 2: Catalan Numbers for Balanced Paths
If we ignore the horizontal steps for the moment, the number of ways to place upward steps and downward steps such that the path does not go below the x-axis is given by the Catalan number  :
:
={(2*N)!}/{(N+1)!N!}")
This Catalan number counts the number of valid ways to arrange the upward steps and downward steps such that the path remains above or on the x-axis.
Step 3: Placing Horizontal Steps
Once the valid upward and downward steps have been arranged in a Catalan structure, we can freely place the horizontal steps (1,0) in the remaining positions of the path. Since there are  steps (upward and downward) and horizontal steps, there are
steps (upward and downward) and horizontal steps, there are  gaps (before, after, or between the upward/downward steps) where the horizontal steps can be placed.
gaps (before, after, or between the upward/downward steps) where the horizontal steps can be placed.
The number of ways to place horizontal steps in these positions is given by a binomial coefficient:”
For some reason, ChatGPT gives the wrong binomial coefficient. Calculating the number of ways of distributing  items into
items into  bins is a well known problem; when a bin can contain zero items, the solution is:
bins is a well known problem; when a bin can contain zero items, the solution is: ={(x+y-1)!}/{(y-1)!x!}") .
.
Combining the equations from the two steps gives the number of distinct statement sequences that can be created using if-statements and simple-statements as:
={(2*N)!}/{(N+1)!N!}{S!}/{(2*N)!(S-2*N)!}={S!}/{{(N+1)!N!}(S-2*N)!}")
The above answer is technically correct, however, it fails to take into account that in practice an if-statement body will always contain either another if-statement or a simple statement, i.e., the innermost if-statement of any nested sequence cannot be empty (the equation used for distributing items into bins assumes a bin can be empty).
Rather than distributing statements into gaps, we first need to insert one simple statement into each of the innermost if-statements. The number of ways of distributing the remaining statements are then counted as previously. How many innermost if-statements can be created using if-statements? I found the answer to this question in a StackExchange question, using traditional search.
The question can be phrased in terms of peaks in Dyck paths, and the answer is contained in the Narayana numbers (which I had never heard of before). The following example, from Wikipedia, shows the number of paths containing a given number of peaks, that can be produced by four if-statements:
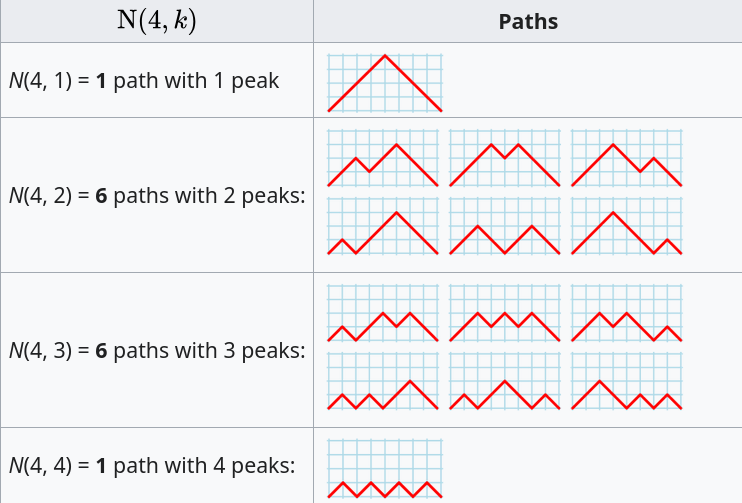
The sum of all these paths is the Catalan number for the given number of if-statements, e.g., using  to denote the Narayana number:
to denote the Narayana number: }=1 + 6 + 6 + 1 = 14=C_4") .
.
Adding at least one simple statement to each innermost if-statement changes the equation for the number of statement sequences from ") , to:
, to:
(matrix{2}{1}{{S-k*P(N, k)} 2*N})}")
The following table shows the number of distinct statement sequences for five-to-twenty statements containing one-to-five if-statements:
N if-statements
1 2 3 4 5
5 6 1
6 10 6
7 15 20 1
8 21 50 7
9 28 105 29 1
10 36 196 91 9
11 45 336 238 45 1
12 55 540 549 166 11
S 13 66 825 1,155 504 66
14 78 1,210 2,262 1,332 286
15 91 1,716 4,179 3,168 1,002
16 105 2,366 7,351 6,930 3,014
17 120 3,185 12,397 14,157 8,074
18 136 4,200 20,153 27,313 19,734
19 153 5,440 31,720 50,193 44,759
20 171 6,936 48,517 88,458 95,381 |
The following is an R implementation of the calculation:
Narayana=function(n, k) choose(n, k)*choose(n, k-1)/n
Catalan=function(n) choose(2*n, n)/(n+1)
if_stmt_possible=function(S, N)
{
return(Catalan(N)*choose(S, 2*N)) # allow empty innermost if-statement
}
if_stmt_cnt=function(S, N)
{
if (S <= 2*N)
return(0)
total=0
for (k in 1:N)
{
P=Narayana(N, k)
if (S-P*k >= 2*N)
total=total+P*choose(S-P*k, 2*N)
}
return(total)
}
isc=matrix(nrow=25, ncol=5)
for (S in 5:20)
for (N in 1:5)
isc[S, N]=if_stmt_cnt(S, N)
print(isc) |
Obtaining source code for training LLMs
Training a large language model to be a coding assistant requires huge amounts of source code.
Github is a very well known publicly available repository of code, and various sites have created substantial collections of GitHub repos, e.g., GitTorrent, and Google’s BigQuery. Since 2017 the Software Heritage has been amassing the world’s source code, and now looks like it will become the default site for those seeking LLM source code training data. The benefits of using the Software_Heritage, include:
- deduplication at the file level for free. Files are organized using a cryptographic hash of their contents (i.e., a Merkle tree), which is user visible. GitHub may deduplicate internally, but the user visible data structure is based on individual repositories. One study found that 70% of code on GitHub are clones. Deduplication has been a major housekeeping task when creating a source code training dataset.
A single space character or newline is enough to cause a cryptographic hash to change and a file to be treated as different. Studies of file contents has found them differing by the presence/absence of a license at the start of the file, and other non-consequential differences. The LLM training dataset “The Stack v2” has further deduplicated the Software Heritage dataset, removing over 50% of files,
- accessed using AWS. The 11TiB of data can be bulk downloaded from the S3 bucket s3://softwareheritage/graph/. An Amazon Athena hosted version of the dataset can be queried using the Presto distributed SQL engine (filename suffix could be used to extract files likely to contain source in particular languages). Amazon also have an Azure Databricks hosted version.
Suggestions for the best way of accessing this data, for LLM training, welcome,
- Software_Heritage hosts more code than GitHub, although measurements from late 2021 suggests that at the time, over 95% originated on GitHub.
StarCoder2, released at the end of February, is an open weights model trained in partnership with the Software Heritage (a year ago, version 1 of StarCoder was trained using an order of magnitude less source).
How much source is available via the Software Heritage?
As of July 2023 the site hosted  files.
files.
Let’s assume 64 lines per file, and 26 non-whitespace characters per line, giving  non-whitespace characters. How many tokens is this?
non-whitespace characters. How many tokens is this?
The most common statement is assignment, which typically contains 4 language tokens (e.g., a = b ; ). There is an exponential decline in language tokens per line (Fig 770.17). The question is how many LLM tokens per computer language identifier, which tend to be abbreviated; I have no idea how these map to LLM tokens.
Assuming 10 LLM tokens per line, we get:  LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
The Stack v2 Hugging Face page lists the deduplicated dataset as containing  tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is
tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is  , with the deduped training dataset containing
, with the deduped training dataset containing  files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
My calculation probably overestimated the number of tokens on a line. LLM’s specifically trained on source code have tokenisers optimized for the characteristics of code, e.g., allowing tokens to span whitespace to allow for idioms such as import numpy as np to be treated as single tokens.
Given the exponential growth of files available on the Software Heritage, it is possible that several orders of magnitude more tokens will eventually become available.
Licensing, in the form of the GPL, is a complication that hangs over the use of some public source code (maybe 25%). An ongoing class-action suit will likely take years to resolve, and it’s possible that model training will have improved to the extent that any loss of GPL’d code will not seriously impact model performance:
- When source is licensed under the GNU General Public License, do models that use it during training have themselves to be released under a GPL license? In November 2022 a class-action lawsuit was filed, challenging the legality of GitHub Copilot and related OpenAI products. This case has yet to reach jury trial, and after that there will no doubt be appeals. The resolution is years in the future,
- if the plaintiffs win, with models trained using GPL’d code required to release the weights under a GPL license. The different source files used to build a project sometimes have different, incompatible, Open source licenses. LLM training does not require complete sets of project source files, so the presence of GPL’d source is not contagious within a project. If the same file appears with different licenses, one of which is the GPL, the simplest option may be to exclude it. One study found the GPL-3 license present under 2,871 different filenames.
Given that around 50% of GitHub repos don’t specify any license, and around 30% specify an MIT license, not using GPL’d code for training does not look like it will affect the training of general coding models. However, these models will have problems dealing with issues that require interfacing to GPL’d code.
Survey papers: LLMs will restore some level of usefulness
Scientific papers are like soap operas, in that understanding them requires readers to have some degree of familiarity with the ongoing plot.
How can people new to an opera quickly get up to speed with the ongoing story lines, without reading hundreds of papers?
The survey paper is intended to be the answer to this question. Traditionally written by an established researcher in the field, the 100+ pages aim to be an authoritative overview of the progress and setbacks of research on a particular topic within the last 5/10/15 years (depending on the rate/lack of progress since the last major survey paper).
These days research papers are often written by PhD students, with the professor doing the supervising, and getting their name tacked on to the end of the list of authors (professors can spend more time writing grant applications than writing research papers). Writing a single 100+ page survey paper is not a cost-effective use of an experienced person’s time, given the pressure to pump out papers, even when the ACM Computing Surveys is one of the highest ranked journals in computing. The short lifecycle of fields driven by the next fashionable topic is another disincentive.
Given the incentives, why are survey papers still being published?
In software engineering there are now two kinds of survey papers: 1) the traditional kind, written by people who see it as a service, or are not on the publish/perish treadmill, or early stage researchers surveying a niche topic, 2) PhD students using what we now call a Large language model summary approach, soon to be replaced by real LLMs.
So-called survey papers (at least in software engineering) are now regularly being written by members of the intended audience of traditional survey papers, i.e., PhD students who are new to the field and want a map of the territory showing the routes to the frontiers.
How does a person who knows almost nothing about a field write a (20-40 page, rarely 100+) survey paper about it?
A survey is based on the list of all the appropriate papers. In theory, appropriate papers have to meet some quality criteria, e.g., be published in a reputable journal/conference/blog. In practice, the list is created by searching various academic publication search engines (e.g., web of science, or the ACM digital library) using a targeted regular expression; for instance:
(agile OR waterfall OR software OR "story points" OR "story point" OR "user stories" OR "function points" OR "planning poker" OR "pomodoros" OR "use case" OR "source code" OR "DORA metrics" OR scrum) (predict OR prediction OR quantify OR dataset OR schedule OR lifecycle OR "life cycle" OR estimate OR estimates OR estimating OR estimation OR estimated OR #noestimates OR "evidence" OR empirical OR evolution OR ecosystems OR cognitive OR economics OR reliability OR metrics OR experiment) |
The list of papers returned may be filtered further, depending on how many there are (a hundred or two does not look too lightweight, and does not require an excessive amount of work).
Next, what to say about these papers, and how many of them actually need to be read?
The bottom of the barrel, vacant ideas, survey paper tabulates easily calculated metrics (e.g., number of papers per year, number of authors per paper, clusters of keywords), and babble on about paper selection criteria, keyword growth and diversity, and more research is needed.
For a survey paper to appear in a layer above the vacant ideas level, the authors have to process some amount of the paper contents. The paper A Systematic Literature Review on Reasons and Approaches for Accurate Effort Estimations in Agile by Pasuksmit, Thongtanunam, and Karunasekera is a recent example of one such survey. The search criteria returned 519 papers, of which 82 were selected for inclusion, i.e., cited. The first 10, of the 42 pages, covered the selection process and the process used to answer the two research questions; RQ1: What are the discovered reasons for inaccurate estimations in Agile iterative development? and RQ2: What are the approaches proposed to improve effort estimation in Agile iterative development?
The main answers to the research questions appeared in: 1) tables which listed attributes relating to the question and the papers that had something to say about that attribute, and 2) sections containing a few paragraphs highlighting various points made by papers about some attribute.
My primary interest was Table 11, which listed the papers/dataset used. A few were new to me, but unfortunately all confidential.
A survey can only be as good as the papers it is based on. The regular expression approach can miss important papers and include unimportant papers. The Pasuksmit et al paper only included one paper by the leading researcher in Agile effort estimation, and included papers that I wouldn’t waste disk space on a pdf file.
I would not recommend these ‘LLM’ style surveys to newcomers to a field. They don’t connect the lines of research, call out the successes/failures, and they don’t provide a map of the territory.
The readership of these survey papers are the experienced researchers, who will scan the list of cited papers looking for anything they might have missed.
I’m not expecting LLMs to be capable of producing experienced professor level survey papers any time soon. In a year or two, LLMs will surely be doing a better job than PhD students.
Chinchilla Scaling: A replication using the pdf
The paper Chinchilla Scaling: A replication attempt by Besiroglu, Erdil, Barnett, and You caught my attention. Not only a replication, but on the first page there is the enticing heading of section 2, “Extracting data from Hoffmann et al.’s Figure 4”. Long time readers will know of my interest in extracting data from pdfs and images.
This replication found errors in the original analysis, and I, in turn, found errors in the replication’s data extraction.
Besiroglu et al extracted data from a plot by first converting the pdf to Scalable Vector Graphic (SVG) format, and then processing the SVG file. A quick look at their python code suggested that the process was simpler than extracting directly from an uncompressed pdf file.
Accessing the data in the plot is only possible because the original image was created as a pdf, which contains information on the coordinates of all elements within the plot, not as a png or jpeg (which contain information about the colors appearing at each point in the image).
I experimented with this pdf-> svg -> csv route and quickly concluded that Besiroglu et al got lucky. The output from tools used to read-pdf/write-svg appears visually the same, however, internally the structure of the svg tags is different from the structure of the original pdf. I found that the original pdf was usually easier to process on a line by line basis. Besiroglu et al were lucky in that the svg they generated was easy to process. I suspect that the authors did not realize that pdf files need to be decompressed for the internal operations to be visible in an editor.
I decided to replicate the data extraction process using the original pdf as my source, not an extracted svg image. The original plots are below, and I extracted Model size/Training size for each of the points in the left plot (code+data):

What makes this replication and data interesting?
Chinchilla is a family of large language models, and this paper aimed to replicate an experimental study of the optimal model size and number of tokens for training a transformer language model within a specified compute budget. Given the many millions of £/$ being spent on training models, there is a lot of interest in being able to estimate the optimal training regimes.
The loss model fitted by Besiroglu et al, to the data they extracted, was a little different from the model fitted in the original paper:
Original:  = 1.69+406.40/N^{0.34}+410.7/D^{0.28}")
Replication:  = 1.82+514.0/N^{0.35}+2115.2/D^{0.37}")
where: is the number of model parameters, and  is the number of training tokens.
is the number of training tokens.
If data extracted from the pdf is different in some way, then the replication model will need to be refitted.
The internal pdf operations specify the x/y coordinates of each colored circle within a defined rectangle. For this plot, the bottom left/top right coordinates of the rectangle are: (83.85625, 72.565625), (421.1918175642, 340.96202) respectively, as specified in the first line of the extracted pdf operations below. The three values before each rg operation specify the RGB color used to fill the circle (for some reason duplicated by the plotting tool), and on the next line the /P0 Do is essentially a function call to operations specified elsewhere (it draws a circle), the six function parameters precede the call, with the last two being the x/y coordinates (e.g., x=154.0359138125, y=299.7658568695), and on subsequent calls the x/y values are relative to the current circle coordinates (e.g., x=-2.4321790463 y=-34.8834544196).
Q Q q 83.85625 72.565625 421.1918175642 340.96202 re W n 0.98137749 0.92061729 0.86536915 rg 0 G 0.98137749 0.92061729 0.86536915 rg 1 0 0 1 154.0359138125 299.7658568695 cm /P0 Do 0.97071849 0.82151775 0.71987163 rg 0.97071849 0.82151775 0.71987163 rg 1 0 0 1 -2.4321790463 -34.8834544196 cm /P0 Do |
The internal pdf x/y values need to be mapped to the values appearing on the visible plot’s x/y axis. The values listed along a plot axis are usually accompanied by tick marks, and the pdf operation to draw these tick marks will contain x/y values that can be used to map internal pdf coordinates to visible plot coordinates.
This plot does not have axis tick marks. However, vertical dashed lines appear at known Training FLOP values, so their internal x/y values can be used to map to the visible x-axis. On the y-axis, there is a dashed line at the 40B size point and the plot cuts off at the 100B size (I assumed this, since they both intersect the label text in the middle); a mapping to the visible y-axis just needs two known internal axis positions.
Extracting the internal x/y coordinates, mapping them to the visible axis values, and comparing them against the Besiroglu et al values, finds that the x-axis values agreed to within five decimal places (the conversion tool they used rounded the 10-digit decimal places present in the pdf), while the y-axis values appeared to differ differed by about 10%.
I initially assumed that the difference was due to a mistake by me; the internal pdf values were so obviously correct that there had to be a simple incorrect assumption I made at some point. Eventually, an internal consistency check on constants appearing in Besiroglu et al’s svg->csv code found the mistake. Besiroglu et al calculate the internal y coordinate of some of the labels on the y-axis by, I assume, taking the internal svg value for the bottom left position of the text and adding an amount they estimated to be half the character height. The python code is:
y_tick_svg_coords = [26.872, 66.113, 124.290, 221.707, 319.125] y_tick_data_coords = [100e9, 40e9, 10e9, 1e9, 100e6] |
The internal pdf values I calculated are consistent with the internal svg values 26.872, and 66.113, corresponding to visible y-axis values 100B and 40B. I could not find an accurate means of calculating character heights, and it turns out that Besiroglu et al’s calculation was not accurate.
I published the original version of this article, and contacted the first two authors of the paper (Besiroglu and Erdil). A few days later, Besiroglu replied with details of why they thought that the 40B line I was using as a reference point was actually at either 39.5B or 39.6B (based on published values for the Gopher budget on the x-axis), but there was uncertainty.
What other information was available to resolve the uncertainty? Ah, the right plot has Model size on the x-axis and includes lines that appear to correspond with axis values. The minimum/maximum Model size values extracted from the right plot closely match those in the original paper, i.e., that ’40B’ line is actually at 39.554B (mapping this difference from a log scale is enough to create the 10% difference in the results I calculated).
My thanks to Tamay Besiroglu and Ege Erdil for taking the time to explain their rationale.
The y-axis uses a log scale, and the ratio of the distance between the 10B/100B virtual tick marks and the 40B/100B virtual tick marks should be -log(10)}/{log(100)-log(40)}") . The Besiroglu et al values are not consistent with this ratio; consistent values below (code+data):
. The Besiroglu et al values are not consistent with this ratio; consistent values below (code+data):
# y_tick_svg_coords = [26.872, 66.113, 124.290, 221.707, 319.125] y_tick_svg_coords = [26.872, 66.113, 125.4823, 224.0927, 322.703] |
When these new values are used in the python svg extraction code, the calculated y-axis values agree with my calculated y-axis values.
What is the equation fitted using these corrected Model size value? Answer below:
Replication:
Corrected size:  = 1.82+548.5/N^{0.35}+2113.2/D^{0.37}")
The replication paper also fitted the data using a bootstrap technique. The replication values (Table 1), and the corrected values are below (standard errors in brackets; code+data):
Parameter Replication Corrected
A 482.01 370.16
(124.58) (148.31)
B 2085.43 2398.85
(1293.23) (1151.75)
E 1.82 1.80
(0.03) (0.03)
α 0.35 0.33
(0.02) (0.02)
β 0.37 0.37
(0.02) (0.02) |
where the fitted equation is:  = E+A/N^{alpha}+B/D^{beta}")
What next?
The data contains 245 rows, which is a small sample. As always, more data would be good.
Extracting named entities from a change log using an LLM
The Change log of a long-lived software system contains many details about the system’s evolution. Two years ago I tried to track the evolution of Beeminder by extracting the named entities in its change log (named entities are the names of things, e.g., person, location, tool, organization). This project was pre-LLM, and encountered the usual problem of poor or non-existent appropriately trained models.
Large language models are now available, and these appear to excel at figuring out the syntactic structure of text. How well do LLMs perform, when asked to extract named entities from each entry in a software project’s change log?
For this analysis I’m using the publicly available Beeminder change log. Organizations may be worried about leaking information when sending confidential data to a commercially operated LLM, so I decided to investigate the performance of a couple of LLMs running on my desktop machine (code+data).
The LLMs I used were OpenAI’s ChatGPT plus (the $20 month service), and locally: Google’s Gemma (the ollama 7b model), a llava 7b model (llava-v1.5-7b-q4.llamafile), and a Mistral 7b model (mistral-7b-instruct-v0.2.Q8_0.llamafile). I used 7 billion parameter models locally because this is the size that is generally available for Open sourced models. There are a few models supporting the next step-up, at 13 billion parameters, and a few at 30 billion.
All the local models start a server at localhost:8080, and provide various endpoints. Mozilla’s llamafile based system is compatible with OpenAI’s python package openai. The documentation for the Gemma based system I installed uses the ollama package. In both cases, the coding required is trivial; just add a few statements to create a question based on command line input:
import openai import sys prefix='List the named entities in the following sentences: ' input_str=sys.argv[1] # change log entry from command line client = openai.OpenAI( base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port" api_key = "sk-no-key-required" ) stream = client.chat.completions.create( model="gpt-4", stream=True, temperature=0, seed=19, messages=[ {"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfilment via helping them with their requests."}, {"role": "user", 'content': prefix+ input_str } ] ) # Print response for chunk in stream: print(chunk.choices[0].delta.content or "", end="") print() |
How well did the models perform?
For rapid iteration, I used the web interface to ChatGPT. The responses started to appear within a few seconds and were displayed at a readable rate.
ChatGPT 3.5
When given a single change log entry, ChatGPT also provides a brief description of the named entity. In the following example, ‘twitter acct‘ and ‘blog posts‘ are not flagged as named entities:
User
print the named entities in the following quoted text "Created
this twitter acct to log user-visible improvements (UVIs) to
Beeminder. (Yes, this is a UVI. Everything counts no matter how
small!) Very first UVI! Back then this counted but nowadays we
don't count things that are too ancillary like making Twitter
accounts or writing blog posts. We did count a few UVIs for
creating this fancy changelog but decided that's too ancillary
now too."
ChatGPT
To identify named entities in the quoted text, we need to look for
proper nouns, which typically include names of specific people,
organizations, locations, and sometimes unique entities. In the
provided text, here are the named entities:
Beeminder - Refers to a specific service or product.
Twitter - Refers to a specific social media platform.
UVI (User-Visible Improvement) - Refers to a specific type of improvement.
changelog - Refers to a specific type of document or record. |
When asked to list the named entities in each of multiple lines, ChatGTP 3.5 performance drops. In the following response, the first line is identical to the example above; the response contains three, not four names entities. The second line contains named entities, but ChatGTP claims there are none. The response to the third line is accurate:
ChatGPT
Here are the named entities in each of the three lines:
"Created this twitter acct" line:
Twitter - Refers to a specific social media platform.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement.
Beeminder - Refers to a specific service or product.
"Added ridiculous dog-dressed-as-a-bee picture" line:
None
"Now suppressing reminder emails" line:
reminder emails - Refers to a specific type of communication.
bug fixes - Refers to a specific type of improvement aimed
at resolving software issues.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement. |
ChatGPT 4.0
ChatGPT 4.0 can handle multiple change log entries. The following is the response to the first three entries (the same three entries given the ChatGPT 3.5):
ChatGPT
To thoroughly identify the named entities within each line,
I'll systematically parse each one, focusing on extracting
specific types of entities such as organizations, people,
locations, dates, websites, and any other identifiable proper
nouns.
Beeminder, Twitter, UVI: Organizations or products.
dog-dressed-as-a-bee: Concept, not a proper noun but unique
enough to note.
reminder emails: Concept, referring to a feature. |
While it is possible to input 100 change log entries into the ChatGPT input box, the response contained no more than about 25 of them (there is a maximum limit on the number of input and output tokens).
Running locally
The machine I used locally contains 64G memory and an Intel Core i5-7600K running at 3.80GHz, with four cores. The OS is Linux Mint 21.1, running the kernel 5.15.0-76-generic. I don’t have any GPUs installed.
A GPU would probably significantly improve performance. On Amazon, the price of the NVIDIA Tesla A100 is now just under £7,000, an order of magnitude more than I am interested in paying (let alone the electricity costs). I have not seen any benchmarks comparing GPU performance on running LLMs locally, but then this is still a relatively new activity.
Overall, Gemma produced the best responses and was the fastest model. The llava model performed so poorly that I gave up trying to get it to produce reasonable responses (code+data). Mistral ran at about a third the speed of Gemma, and produced many incorrect named entities.
As a very rough approximation, Gemma might be useful. I look forward to trying out a larger Gemma model.
Gemma
Gemma took around 15 elapsed hours (keeping all four cores busy) to list named entities for 3,749 out of 3,839 change log entries (there were 121 “None” named entities given). Around 3.5 named entities per change log entry were generated. I suspect that many of the nonresponses were due to malformed options caused by input characters I failed to handle, e.g., escaping characters having special meaning to the command shell.
For around about 10% of cases, each named entity output was bracketed by “**”.
The table below shows the number of named entities containing a given number of ‘words’. The instances of more than around three ‘words’ are often clauses within the text, or even complete sentences:
# words 1 2 3 4 5 6 7 8 9 10 11 12 14 Occur 9149 4102 1077 210 69 22 10 9 3 1 3 5 4 |
A total of 14,676 named entities were produced, of which 6,494 were unique (ignoring case and stripping **).
Mistral
Mistral took 20 hours to process just over half of the change log entries (2,027 out of 3,839). It processed input at around 8 tokens per second and output at around 2.5 tokens per second.
When Mistral could not identify a named entity, it reported this using a variety of responses, e.g., “In the given …”, “There are no …”, “In this sentence …”.
Around 5.8 named entities per change log entry were generated. Many of the responses were obviously not named entities, and there were many instances of it listing clauses within the text, or even complete sentences. The table below shows the number of named entities containing a given number of ‘words’:
# words 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Occur 3274 1843 828 361 211 130 132 90 69 90 68 46 49 27 |
A total of 11,720 named entities were produced, of which 4,880 were unique (ignoring case).
Recent Comments