Archive
APIs can, for the time being, be copyrighted
There was an interesting turn of events in the Oracle vs. Google Java API lawsuit last friday. The original trial judge had ruled that an API are not copyrightable; last week the US federal Court of appeals reversed this decision, APIs are copyrightable. This legal battle is not over and the ruling can flip and flop its way up to the US supreme court, and not being a lawyer I’m happy to leave the legal discussion to others. Let’s assume that Oracle eventually win their Java API copyright claim, what does that mean for computer language usage and software developers?
If Oracle’s API copyright claim is upheld then they are potentially in line for a huge payout (Google might get to wiggle out of paying much via a fair use justification). I’m sure that some people will claim that this ‘win’ will kill off Java, even if this is true (I don’t think it is), what do the suits care? Give me a billion dollars and I will happily support the removal of any computer language from planet Earth.
In the early days of Android Google needed Java compatibility more than Java needed anything to do with Android. Now Android has such a commanding market share Google does not need to worry so much about Java compatibility. If Oracle had any interest in the future of Java they would be worried that this court case could result in Google switching the Android ecosystem to using a slightly incompatible Java-like language. In practice this court case is the only real opportunity for Oracle to make serious money from their Java intellectual property and they are not that excited about a steady stream of peanuts from future goings on.
What does Oracle winning the API copyright claim mean for developers?
If Google do launch a Java-like language then Java’s “write once run anywhere” mantra will be less true than it currently is (by avoiding a few traps and not straying too far from the well trodden path Java developers can create programs that are remarkable portable). In its market niche there is no other language that comes close to providing the kind of portability that Java offers, so existing users will be annoyed at having to worry about one more portability issue but are unlikely to jump ship.
The much more interesting question is the impact an Oracle win has on other companies producing products that include an API; they now have something to wave at competitors who have API-alike (I just made that word up) products. Any developer using an API that has its very own copyright discussion thread is likely to become a bit twitchy. The general result will be a cloud of uncertainty over some existing APIs from some providers.
Anybody introducing a new API will have to answer the ‘copyright’ question: “Do you claim copyright on your API?” In practice a very very small percentage of APIs ever get copied/cloned, because most fail or the competition comes up with what they think is a better API.
Would I care if a company claims copyright on its API and says it will sue anybody who copies/clones it? Obviously I have to use that API if it is the only way to get a job done, but what if I had a choice between it and a non-copyrighted API? I don’t think the question of copyright would be an issue for me, but I would be concerned if any company was being overly legalistic; do I really want to deal with a company more interested in legal matters than supporting developers? I think not.
Changes in the API/non-API method call ratio with program size
Amount of code is the fundamental metric of software engineering. How do things change as the amount of code changes and often just as interestingly what does not change with code size?
Most languages include some kind of base library functionality. Languages such as Java and C++ not only include a very large library but also a huge, widely used, collection of third-party libraries.
Let’s count every method call in lots of Java programs and for each program divide these calls into two groups, calls to methods in well-known libraries (call these the API methods) and all other method calls (i.e., calls to methods written by the developers who wrote each of the programs measured; call these the non-API methods).
I would expect the ratio of API to non-API method calls to be independent of program size.
Yes, the number of possible different API calls is fixed while the number of possible non-API calls increases with program size, but I don’t see why a changing ratio of unique calls should change the ratio of total calls.
Yes, larger programs are likely to contain more architectural stuff whose code is more likely to contain calls to non-API methods, but the percentage of architectural code is very small and unlikely to have much impact on the overall numbers.
The authors of the paper: Large-scale, AST-based API-usage analysis of open-source Java projects made their data available and so I got to check out my thinking 🙂
The plot below shows everything going to plan until around 10,000 method calls (about 50,000 lines of code). Why that sudden kink in the line (code and data)?
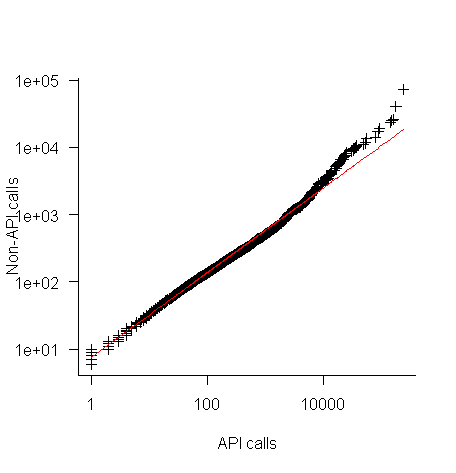
One possibility is that once a program gets to a size of around 50,000 lines the developers decide to invest in one or more wrapper packages which create a purpose built interface to an API (programs often have their own requirements and needs that existing an existing API interface does not quite meet); this would cause API calls to decrease and non-API calls to increase. If this pattern of usage occurred there would be a permanent change in the API/non-API ratio, and in practice the ratio change appears to be temporary.
I’m a bit stumped by this behavior. Suggestions on possible mechanisms welcome.
I wish I had the time to investigate, but I have a book to finish.
Agreement between code readability ratings given by students
I have previously written about how we know nothing about code readability and questioned how the information content of expressions might be calculated. Buse and Weimer ran a very interesting experiment that asked subjects to rate short code snippets for readability (somebody please rerun this experiment using professional software developers).
I’m interested in measuring how well different students subjects agree with each other (I have briefly written about this before).
Short answer: Very little agreement between individual pairs, good agreement between rankings aggregated by year.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome. R code and data here.
Readability
Source code is often said to have an attribute known as
A study by Buse and Weimer <book Buse_08> asked Computer Science students to rate short snippets of Java source code on a scale of 1 to 5. Buse and Weimer then searched for correlations between these ratings and various source code attributes they obtained by measuring the snippets.
Humans hold diverse opinions, have fragmented knowledge and beliefs about many topics and vary in their cognitive abilities. Any study involving human evaluation that uses an open ended problem on which subjects have had little experience is likely to see a wide range of responses.
Readability is a very nebulous term and students are unlikely to have had much experience working with source code. A wide range of responses is to be expected and the analysis performed here aims to check the degree of readability rating agreement between the subjects.
Data
The data made available by Buse and Weimer are the ratings, on a scale of 1 to 5, given by 121 students to 100 snippets of source code. The student subjects were drawn from those taking first, second and third/fourth year Computer Science degree courses and postgraduates at the researchers’ University (17, 65, 31 and 8 subjects respectively).
The postgraduate data was not used in this analysis because of the small number of subjects.
The source of the code snippets is also available but not used in this analysis.
Is the data believable?
The subjects were not given any instructions on how to rate the code snippets for readability. Also we don’t know what outcome they were trying to achieve when rating, e.g., where they rating on the basis of how readable they personally found the snippets to be, or rating on the basis of the answer they would expect to give if they were being tested in an exam.
The subjects were students who are learning about software development and many of them are unlikely to have had any significant development experience outside of the teaching environment. Experience shows that students vary significantly in their ability to read and write source code and a non-trivial percentage do not go on to become software developers.
Because the subjects are at an early stage of learning about code it is to be expected that their opinions about readability will change while they are rating the 100 snippets. The study did not include multiple copies of some snippets, this would have enabled the consistency of individual subject responses to be estimated.
The results of many studies <book Annett_02> has shown that most subject ratings are based on an ordinal scale (i.e., there is no fixed relationship between the difference between a rating of 2 and 3 and a rating of 3 and 4), that some subjects are be overly generous or miserly in their rating and that without strict rating guidelines different subjects apply different criteria when making their judgements (which can result a subject providing a list of ratings that is inconsistent with every other subject).
Readability is one of those terms that developers use without having much idea what they and others are really referring to. The data from this study can at most be regarded as treating readability to be whatever each subject judges it to be.
Predictions made in advance
Is the readability rating given to code snippets consistent between different students on a computer science course?
The hypothesis is that the between student consistency of the readability rating given to code snippets improves as students progress through the years of attending computer science courses.
Applicable techniques
There are a variety of techniques for estimating rater agreement. <Krippendorff’s alpha> can be applied to ordinal ratings given by two or more raters and is used here.
Subjects do not have to give the same rating to share some degree of consistent response. Two subjects may share a similar pattern of increasing/decreasing/stay the same ratings across snippets. The <Spearman rank correlation> coefficient can be used to measure the correlation between the rank (i.e., relative value within sequence) of two sequences.
Results
When creating the snippets the researchers had no method of estimating what rating subjects would give to them and so there is no reason to expect a uniform distribution of rating values or any other kind of distribution of rating values.
The figure below is a boxplot of the rating of the first 50 code snippets rated by second year students and suggests that many subject ratings are within ±1 of each other.
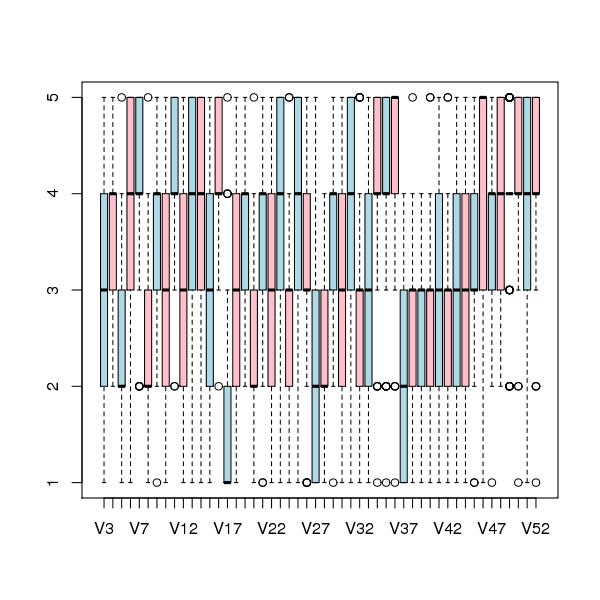
Figure 1. Boxplot of ratings given to snippets 1 to 50 by second year students (colors used to help distinguish boxplots for each snippet).
Between subject rating agreement
The Krippendorff alpha and mean Spearman rank correlation coefficient (the coefficient is calculated for every pair of subjects and the mean value taken) was obtained using the kripp.alpha and meanrho functions from the irr package (a <Jackknife> was used to obtain the following 95% confidence bounds):
Krippendorff's alpha cs1: 0.1225897 0.1483692 cs2: 0.2768906 0.2865904 cs4: 0.3245399 0.3405599 mean Spearman's rho cs1: 0.1844359 0.2167592 cs2: 0.3305273 0.3406769 cs4: 0.3651752 0.3813630 |
Taken as a whole there is a little of agreement. Perhaps there is greater consensus on the readability rating for a subset of the snippets. Recalculating using only using those snippets whose rated readability across all subjects, by year, has a standard deviation less than 1 (around 22, 51 and 62% of snippets respectively) shows some improvement in agreement:
Krippendorff's alpha cs1: 0.2139179 0.2493418 cs2: 0.3706919 0.3826060 cs4: 0.4386240 0.4542783 mean Spearman's rho cs1: 0.3033275 0.3485862 cs2: 0.4312944 0.4443740 cs4: 0.4868830 0.5034737 |
Between years comparison of ratings
The ratings from individual subjects is only available for one of their years at University. Aggregating the answers from all subjects in each year is one method of obtaining readability information that can be used to compare the opinions of students in different years.
How can subject ratings be aggregated to rank the 100 code snippets in order of what a combined group consider to be readability? The relatively large variation in mean value of the snippet ratings across subjects would result in wide confidence bounds for an aggregate based on ratings. Mapping each subject’s rating to a ranking removes the uncertainty caused by differences in mean subject ratings.
With 100 snippets assigned a rating between 1 and 5 by each subject there are going to be a lot of tied rankings. If, say, a subject gave 10 snippets a rating of 5 the procedure used is to assign them all the rank that is the mean of the ranks the 10 of them would have occupied if their ratings had been very slightly different, i.e., (1+2+3+4+5+6+7+8+9+10)/10 = 5.5. This process maps each students readability ratings to readability rankings, the next step is to aggregate these individual rankings.
The R_package[RankAggreg] package contains a variety of functions for aggregating a collection rankings to obtain a group ranking. However, these functions use the relative order of items in a vector to denote rank, and this form of data representations prevents them supporting ranked lists containing items having the same rank.
For this analysis a simple aggregate ranking algorithm using Borda’s method <book lin_10> was implemented. Borda’s method for creating an aggregate ranking operates on one item at a time, combining all of the subject ranks for that item into a single rank. Methods for combining ranks include taking their mean, their geometric mean and the square-root of the sum of their squares; the mean value was used for this analysis.
An aggregate ranking was created for subjects in years one, two and four and the plot below compares the ranking between 1st/2nd year students (left) and 2nd/4th year students (right). The order of the second year student snippet rankings have been sorted and the other year rankings for the snippets mapped to the corresponding position.
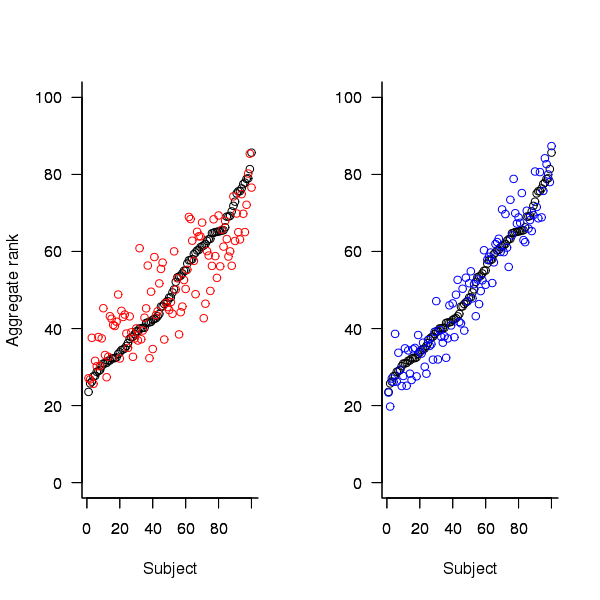
Figure 2. Aggregated ranking of snippets by subjects in years 1 and 2 (red and black) and years 2 and 4 (black and blue). Snippets have been sorted by year 2 ranking.
The above plot seems to show that at the aggregated year level there is much greater agreement between the 2nd/4th years than any other year pairing and measuring the correlation between each of the years using <Kendall’s tau>:
cs1.tau cs2.tau cs3.tau 0.6627602 0.6337914 0.8199636 |
confirms the greater agreement between this aggregate year pair.
Individual subject correlation to year aggregate ranking
To what extend to subject ratings correlate with their corresponding year aggregate? The following plot gives the correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
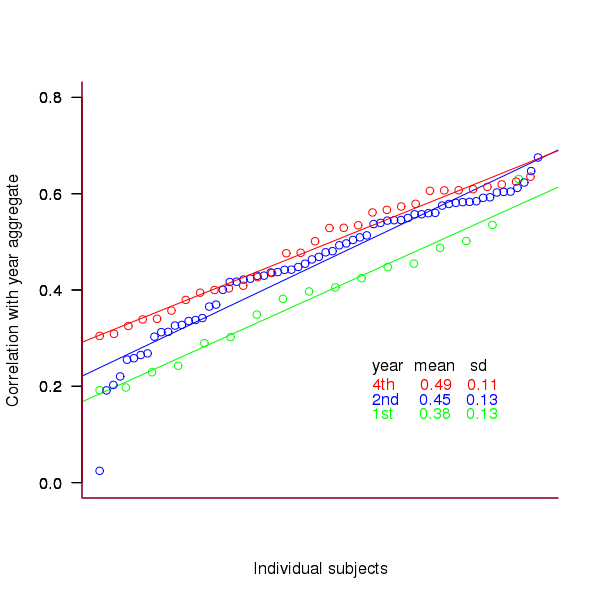
Figure 3. Correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
The least squares fit shows that the variation in correlation across subjects in any year is very similar (removal of outliers in year 2 would make the lines almost parallel); the mean again shows a correlation that increases with year.
Discussion
The extent to which this study’s calculated values of rater agreement and correlation are considered worthy of further attention depends on the use to which the results will be put.
- From the perspective of trained raters the subject agreement in this study is very low and the rating have no further use.
- From the research perspective the results show that the concept of readability in the computer science student population has some non-zero substance to it that might be worth further study.
- From an overall perspective this study provides empirical evidence for a general lack of consensus on what constitutes readability.
It is not surprising that there is little agreement between student subjects on their readability rating, they are unlikely to have had much experience reading code and have not had any training in rating code for readability.
Professional developers will have spent years working with code and this experience is likely to have resulted in the creation of stable opinions on code readability. While developers usually work with code that is much longer than the few lines contained in the snippets used by Buse and Weimer, this experiment format is easy to administer and supports a fine level of control, i.e., allows a small set of source attributes of interest to be presented while excluding those not of interest. Repeating this study using such people as subjects would show whether this experience results in convergence to general agreement on the readability rating of code.
Summary of findings
The agreement between students readability ratings, for short snippets of code, improves as the students progress through course years 1 to 4 of a computer science degree.
While there is very good aggregated group agreement on the relative ranking of the readability of code snippets there is very little agreement between pairs of individuals.
- Two students chosen at random from within a year will have a low Spearman rank correlation coefficient for their rating of code snippet readability.
- Taken as a yearly aggregate there is a high degree of agreement between years two and four and less, but still good agreement between year 1 and other years.
- There is a broad range of correlations, from poor to good, between year aggregates and student subjects in the corresponding year.
Undefined behavior is a design decision
Every few years or so some group of people in the C/C++ community start writing about the constructs specified as having undefined behavior in those languages. A topic that always seems to be skipped is why a language committee would choose to specify that the behavior in a particular case was undefined.
A quick refresher for readers on the definition of Undefined behavior, from the C Standard: “behavior, upon use of a nonportable or erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The two key features are that the behavior applies when an error has occurred and any behavior whatsoever is permitted after one of these errors occurs. Examples of constructs that have undefined behavior are divide by zero, the result of an arithmetic operation on a signed value not being representable in its type (i.e., overflowing) and indexing an array outside of its defined bounds.
The point to note about all undefined behaviors is that the C/C++ language committee could have chosen to specify the behavior that a conforming implementation is required to support. Some language specifications do attempt to explicitly define the behavior for all constructs, e.g., Java, while other languages have a smaller set of undefined behaviors (e.g., Ada, which uses the term Bounded error instead of undefined behavior; there are 35 of them in Ada 2005). To understand why languages take these different approaches we need to look at the language design aims.
The design aims of C included it being implementable for any processor and for the generated code to be efficient (I’m not sure to what extent these might still be major design aims for C++). Computing systems come in all shapes and sizes, some with hundreds of bytes of memory and others with gigabytes, some raise exceptions when certain operations occur while others set processor status flags and others don’t do anything special.
A willingness to accept whatever behavior happens to occur, in an error situation, is the price that has to be paid for efficient execution on a wide range of disparate processors. The C/C++ designers were willing to pay this price while while the Java designers were not, with the Ada designers willing to tolerate less variability than C/C++.
Undefined behavior need not be nasty behavior, an implementation could chose to generate a helpful message or try to recover from it.
There are C tools and compilers (when certain options are specified) that check, at runtime, for various kinds of undefined behavior. I am in the minority in having Boundschecker installed as my default C compiler (as the name suggests it checks that array and pointer accesses to an object are within the defined bounds); for reasons I don’t understand few C/C++ developers are willing to use tools like this. For production code I use a non-boundschecking compiler; I don’t know whether Ada programs are tested with the mandated bounds checking switched on and then have it switched off for the production version (this is what Pascal developers do, in my experience). Of course Java developers have no choice but to permanently live with checking turned on.
The number of companies that make a living selling runtime checking tools is a small percentage of the number of companies based on selling static analysis tools. There continues to be a steady stream of runtime checking tools appearing and quickly disappearing, but until a developers start being sent to jail for faults in their code I don’t foresee the market growing.
Optimizations to figure out when code need not be generated to perform a bounds check because the access is known to be within bounds is an active research area. These days the performance penalty is not so much executing the checking instructions but the disruption to the instruction pipeline caused by the branches that might be taken (if the bounds check fails).
The cost of all the checking required by Java is that the minimal permitted configuration requires at least 256K of memory (Oracle’s K virtual machine, used by the Java Micro Edition which is intended for embedded systems, also makes floating-point optional and allows implementations some freedom in how some constructs are handled). So the Java motto really out to be “Write once, run anywhere with at least 256K and don’t depend on floating-point”.
I have heard stories of Ada code being liberally scattered with various forms of unchecked (how the developer tells the compiler not to do any runtime checking) but have not seen any empirical analysis (a study of goto usage in Ada did not have any trouble finding plenty of uses to analyze).
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
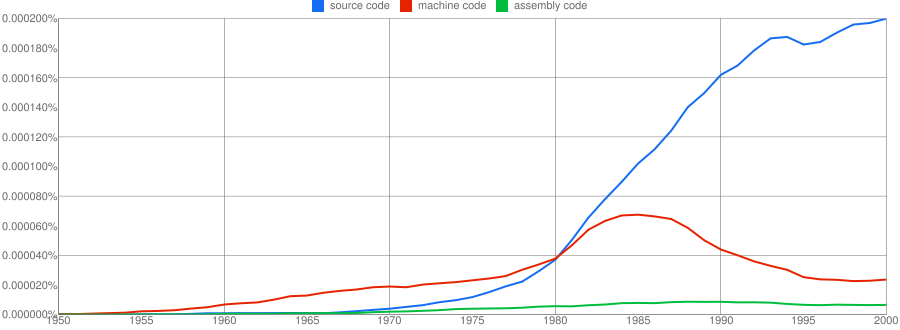
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
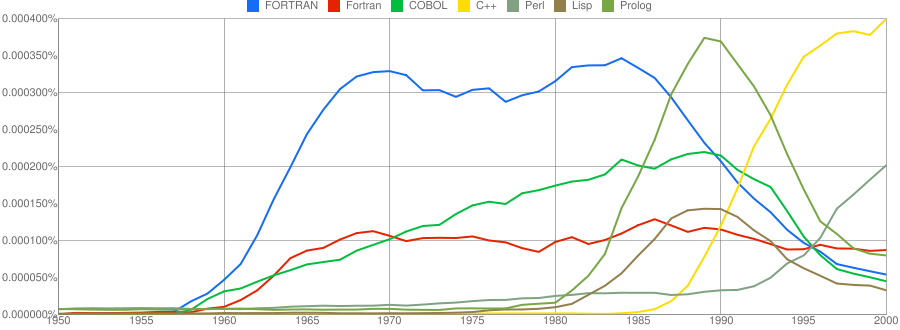
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
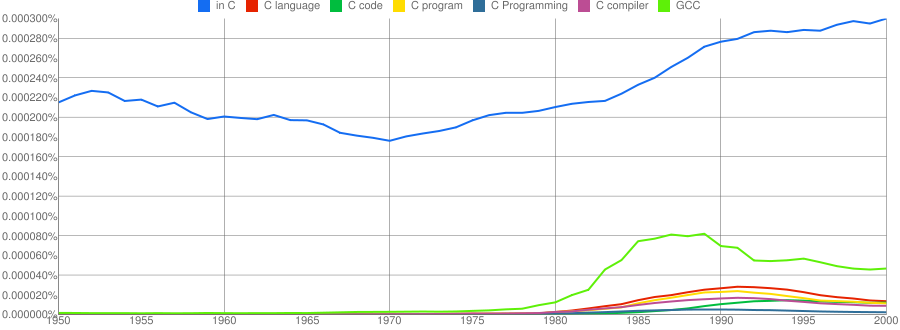
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
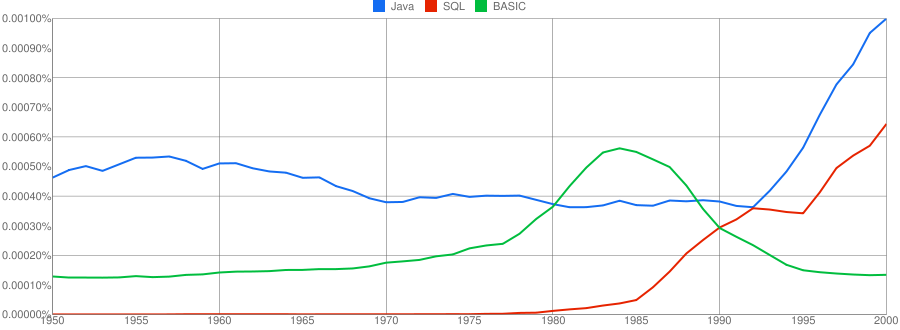
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
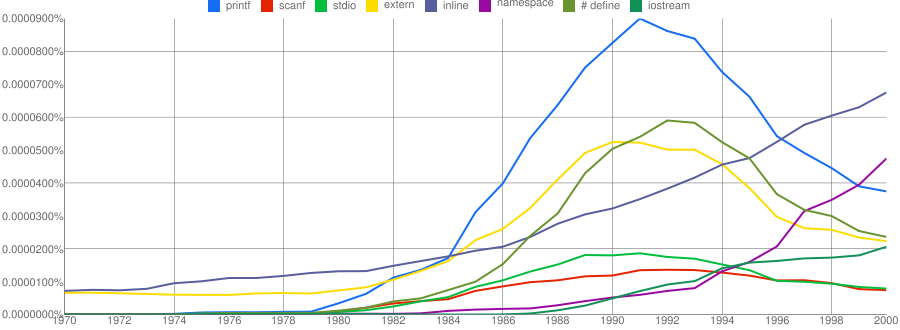
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Oracle/Google ‘Java’ patents lawsuit
At the technical level the Oracle ‘Java’ lawsuit against Google is not really about Java at all. The patents cited in the lawsuit (5,966,702, 6,061,520, 6,125,447, 6,192,476, RE38,104, 6,910,205 and 7,426,720) involve a variety of techniques that might be used in the implementation of a virtual machine supporting JIT compilation for software written in any language; Oracle does not get into the specifics of which parts of Android make use of these patented techniques (Google has not released the Dalvik source code). With regard to the claimed copyright infringement, I have no idea what Oracle claim has been copied; as I understand it Android uses Apache’s Harmony code for its Dalvik VM runtime library, but there is a possibility that it might have used some of Oracle’s gpl’ed code.
No doubt Google’s lawyers will be asking for specific details and once these are provided they have three options: 1) find prior art that invalidates the patent, 2) recode the implementation so it does not infringe the patent or 3) negotiate a license with Oracle.
My only experience in searching for prior art was as an adviser to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case; Microsoft’s existing patents were handled by a patent lawyer and I looked at some of the non-patented innovations being claimed by Microsoft.
The obvious tool to use in a search for prior art is Google and this worked well for me provided the information was created after the mid to late 1990s. The cut-off date for historical searches seemed to be around 1993 (this all happened before Google Books was released). Other sources of information included old books (I had not moved in 15 years and my book collection had not been culled), computer manuals and one advisor found what he was looking for in some old computer magazines bought on e-bay.
Some claimed innovations appeared so blindingly obvious that it was difficult to believe that anybody would bother mentioning it in a print. Oracle’s patent 6,910,205
“Interpreting functions utilizing a hybrid of virtual and native machine instructions” (actually a continuation of 6,513,156, filed five years earlier in 1997) describes an obvious method of handling the interface between interpreted and JIT compiled code.
My only implementation experience in this area does predate the Oracle patent (I wrote a native code generator for the UCSD Pascal p-code machine in the mid-80s) but the translation occurred before program execution and so is not appropriate prior art. Virtual machines fell out of favor in the late 80s and when they were revived by Java 10 years later I was no longer working on compilers
Fans of Lisp are always claiming that everything was first done by the Lisp community and there were certainly Lisp compilers around in the 1980s, but I’m not sure if any of them worked during program execution.
Of course Groklaw have started following this case. Kodak has shown that it is possible to win in court over Java related patents. The SunOracle/Microsoft Java lawsuit in the late 1990s was a contract dispute and not about patents/copyright, but still about money/control.
I’m not aware of any previous language implementation patent lawsuits that have gone to court. It will be interesting to see how much success Google have in finding prior art and whether it is possible to implement a JVM that does not make use of any of the techniques specified in the Oracle patents (I suspect that they have a few more that they have not yet cited).
What language was an executable originally written in?
Apple have recently added an unusual requirement to the iPhone developer agreement “Applications must be originally written in Objective-C, C, C++, or JavaScript …”. As has been pointed out elsewhere the real purpose is stop third party’s from acquiring any control over application development on Apple’s products; the banning of other languages is presumably regarded as acceptable collateral damage.
Is it possible to tell by analyzing an executable what language it was originally written in?
There are two ways in which executables contain source language ‘signatures’. Detecting these signatures requires knowledge of specific compiler behavior, i.e., a database of information about the behavior of compilers capable of creating the executables is needed.
Runtime library. Most compilers make use of a language specific runtime library, rather than generating inline code for some kinds of functionality. For instance, setjmp/longjmp in C and vtables in C++.
The presence of a known C runtime library does not guarantee that the application was originally written in C; it could have been written in Java and converted to C source.
The absence of a known C runtime library could mean that the source was compiled by a C compiler using a runtime system unknown to the analyzer.
The presence of a known Java, for instance, runtime library would suggest that the original source contained some Java. This kind of analysis would obviously require that the runtime library database not restrict itself to the ‘C’ languages.
Compiler behavior patterns. There is usually more than one way in which a source language construct can be translated to machine code and a compiler has to pick one of them. The perfect optimizing compiler would always make the optimal choice, but real compilers follow a fixed pattern of code generation for at least some language constructs (e.g., initialization of registers on function entry).
The presence of known code patterns in an executable is evidence that a particular compiler has been used; how much depends on the likelihood it could have been generated by other means and how many other patterns suggest the same compiler. In the case of the GNU Compiler Collection the source language might also be Fortran, Java or Ada; I don’t know enough about the behavior of GCC to provide an informed estimate of whether it is possible to recognize the source language from the translated form of constructs shared by several languages, I suspect not.
The fact that an executable can be decompiled to C is not a guarantee that it was originally written in C.
Some languages support source language constructs whose corresponding machine code is unlikely to ever be generated by source from another language. The Fortran computed goto allows constructs to be written that have no equivalent in the other languages supported by GCC (none of them allow statement labels appearing in a multi-way jump to appear before the jump test):
10 I=I+1 20 J=J+1 goto (10, 20, 30, 40) J 30 I=I+3 40 I=I*2 |
The presence of a compiled form of this kind of construct in the executable would be very suggestive of Fortran source.
Apple are famously paranoid and control freakery. It will be very interesting to see what level of compliance checking they decide to perform on executables submitted to the App Store.
On another note: What does “originally written” mean? For instance, many of the mathematical functions (e.g., sine, log, gamma, etc) contained in R were originally written in Fortran and translated to C for use in R; this C source is what is now maintained. Does this historical implementation decision mean that R cannot be legally ported to the iPhone?
Register vs. stack based VMs
Traditionally the virtual machine architecture of choice has been the stack machine; benefits include simplicity of VM implementation, ease of writing a compiler back-end (most VMs are originally designed to host a single language) and code density (i.e., executables for stack architectures are invariably smaller than executables for register architectures).
For a stack architecture to be an effective solution, two conditions need to be met:
- The generated code has to ensure that the top of stack is kept in sync with where the next instruction expects it to be. For instance, on its return a function cannot leave stuff lying around on the stack like it can leave values in registers (whose contents can simply be overwritten).
- Instruction execution needs to be generally free of state, so an add-two-integers instruction should not have to consult some state variable to find out the size of integers being added. When the value of such state variables have to be saved and restored around function calls, they effectively become VM registers.
Cobol is one language where it makes more sense to use a register based VM. I wrote one and designed two machine code generators for the MicroFocus Cobol VM and always find it difficult to explain to people what a very different kind of beast it is compared to the VMs usually encountered.
Parrot, the VM designed as the target for compiled PERL, is register based. A choice driven, I suspect, by the difficulty of ensuring a consistent top-of-stack and perhaps the dynamic typing of the language.
On register based cpus with 64k of storage, the code density benefits of a stack based VM are usually sufficient to cancel out the storage overhead of the VM interpreter and support a more feature rich application (provided speed of execution is not crucial).
If storage capacity is not a significant issue and a VM has to be used, what are the runtime performance differences between a register and stack based VM? Answering this question requires compiling and executing the same set of applications for the two kinds of VM. Something that until 2001 nobody had done, or at least not published the results.
A comparison of the Java (stack based) VM with a register VM (The Case for Virtual Register Machines) found that while the stack based code was more compact, fewer instructions needed to be executed on the register based VM.
Most VM instructions are very simple and take relatively little time to execute. When hosted on a pipelined processor the main execution time overhead of a VM is the instruction dispatch (Optimizing Indirect Branch Prediction Accuracy in Virtual Machine Interpreters) and reducing the number of VM instructions executed, even if they are larger and more complicated, can produce a worthwhile performance improvement.
Google has chosen a register based VM for its Android platform. While licensing issues may have been a consideration, there are a number of technical advantages to this decision:
- A register VM is likely to have an intrinsic performance advantage over a stack VM when hosted on a pipelined processor.
- Byte code verification is likely to be faster on a register VM (i.e., faster startup times) because stack height integrity checks will be greatly simplified.
- A register VM will be more forgiving of incorrect code (in the VM, generated by the compiler, code corrupted during program transmission or storage attacked by malware) than a stack VM.
Assuming compilers are clever enough (part 1)
Developers often assume the compiler they use will do all sorts of fancy stuff for them. Is this because they are lazy and happy to push responsibility for parts of the code they write on to the compiler, or do they actually believe that their compiler does all the clever stuff they assume?
An example of unmet assumptions about compiler performance is the use of const in C/C++, final in Java or readonly in other languages. These are often viewed as a checking mechanism, i.e., the developer wants the compiler to check that no attempt is made to, accidentally, change the value of some variable, perhaps via code added during maintenance.
The surprising thing about variables in source code is that approximately 50% of them don’t change once they have been assigned a value (A Theory of Type Qualifiers for C measurements and Automatic Inference of Stationary Fields for Java).
Developers don’t use const/final qualifiers nearly as often as they could. Most modern compilers can deduce if a locally defined variable is only assigned a value once and make use of this fact during optimization. It takes a lot more resources to deduce this information for non-local variables; developers want their compiler to be fast and so implementors don’t won’t them waiting around while whole program analysis is performed.
Why don’t developers make more use of const/final qualifiers? Is this usage, or lack of, an indicator that developers don’t have an accurate grasp of variable usage, or that they don’t see the benefit of using these qualifiers or perhaps they pass responsibility on to the compiler (program size seems to grow sufficiently fast that whole program optimization often consumes more memory than likely to be available; and when are motherboards going to break out of the 4G limit?)
Using local context to disambiguate source
Developers can often do a remarkably good job of figuring out what a snippet of code does without seeing (i.e., knowing anything about) most of the declarations of the identifiers involved. In a previous post I discussed how frequency of occurrence information could be used to help parse C without using a symbol table. Other information that could be used is the context in which particular identifiers occur. For instance, in:
f(x); y = (f)z; |
while the code f(x); is probably a function call, the use of f as the type in a cast means that f(x) is actually a definition an object x having type f.
A project investigating the analysis of partial Java programs uses this context information as its sole means of disambiguating Java source (while they do build a symbol table they do not analyze the source of any packages that might be imported). Compared to C Java parsers have it easy, but Java’s richer type system means that semantic analysis can be much more complicated.
On a set of benchmarks the researchers obtained a very reasonable 91.2% accuracy in deducing the type of identifiers.
There are other kinds of information that developers probably use to disambiguate source: the operation that the code is intended to perform and the identifier names. Figuring out the ‘high level’ operation that code performs is a very difficult problem, but the names of Java identifiers have been used to predict object lifetime and appear to be used to help deduce operator precedence. Parsing source by just looking at the identifiers (i.e., treating all punctuators and operators as whitespace) has been on my list of interesting project to do for some time, but projects that are likely to provide a more immediate interesting result keep getting in the way.
Recent Comments